01. Analysis Seoul CCTV
import pandas as pd
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv")
CCTV_Seoul.head()
CCTV_Seoul.columns[0]
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
CCTV_Seoul.head() Pandas 기초
- Python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈이다.
- 단일 프로세스에서 최대의 효율을 낸다.
- 코딩 가능하고 응용 가능한 엑셀
- 누군가 스테로이를 맞은 엑셀이라고도 한다.
- pandas는 통상 pd
- numpy는 통상 np
Series
index와value로이루어져 있다.- 한 가지 데이터 타입만 가질 수 있다.
import pandas as pd
import numpy as np
pd.Series([1, 2, 3, 4, 5, "hello"])0 1
1 2
2 3
3 4
4 5
5 hello
dtype: objectdata = pd.Series([1.2,3,4,5], dtype=np.float64)
data % 20 1.2
1 1.0
2 0.0
3 1.0
dtype: float64pd.Series({"key" : "value"})key value
dtype: object날짜 데이터
date_range("20230101", periods=6)- 날짜 데이터는 "문자"로
date = pd.date_range("20230101", periods=6)DataFrame
- pd.series()
- index, value
- pd.DataFrame()
- index, value, column
#표준 정규 분포에서 샘플링한 난수 추출
data = np.random.randn(6, 4)
dataarray([[-0.62742841, 0.72841265, 0.1747223 , 0.99887646],
[ 0.95905824, 0.93861376, -0.77302052, -2.40639897],
[ 0.1160a9446, 0.72788705, -0.11383177, 0.72457986],
[ 0.93933099, -1.04813121, 0.22793321, -1.5712901 ],
[-0.87442036, -1.31776168, -0.37008561, 0.29413542],
[-1.61986999, -1.19964403, 0.68513213, -1.60518514]])df = pd.DataFrame(data, index=date, columns=["A", "B", "C", "D"])
df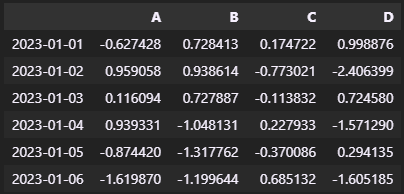
데이터 프레임 정보 탐색
-
df.head(),df.tail(): 메서드라서 괄호 필요 -
index,columns,value: 변수라서 괄호 불요 -
df.head(): 상위 5개값 추출
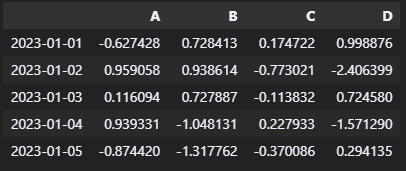
-
df.index: 인덱스 값 추출
DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06'],
dtype='datetime64[ns]', freq='D')
df.columns: column값만 추출
Index(['A', 'B', 'C', 'D'], dtype='object')df.info(): 데이터프레임 정보 추출
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 6 entries, 2023-01-01 to 2023-01-06
Freq: D
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 6 non-null float64
1 B 6 non-null float64
2 C 6 non-null float64
3 D 6 non-null float64
dtypes: float64(4)
memory usage: 240.0 bytesdf.describe(): 데이터 프레임의 기술 통계 정보 확인
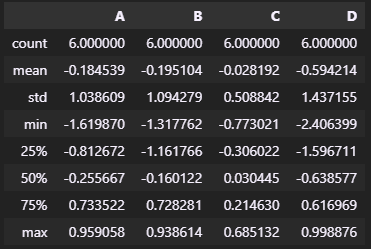
데이터 정렬
- sort_values() : 오름차순 정렬
- sort_values(by="", ascending = False)
- 특정 column(열)을 기준으로 데이터를 정렬
A B C D
2023-01-05 -0.874420 -1.317762 -0.370086 0.294135
2023-01-06 -1.619870 -1.199644 0.685132 -1.605185
2023-01-04 0.939331 -1.048131 0.227933 -1.571290
2023-01-03 0.116094 0.727887 -0.113832 0.724580
2023-01-01 -0.627428 0.728413 0.174722 0.998876
2023-01-02 0.959058 0.938614 -0.773021 -2.406399
A B C D
2023-01-02 0.959058 0.938614 -0.773021 -2.406399
2023-01-01 -0.627428 0.728413 0.174722 0.998876
2023-01-03 0.116094 0.727887 -0.113832 0.724580
2023-01-04 0.939331 -1.048131 0.227933 -1.571290
2023-01-06 -1.619870 -1.199644 0.685132 -1.605185
2023-01-05 -0.874420 -1.317762 -0.370086 0.294135
2023-01-02 0.959058
2023-01-01 -0.627428
2023-01-03 0.116094
2023-01-04 0.939331
2023-01-06 -1.619870
2023-01-05 -0.874420
Name: A, dtype: float64
2023-01-02 0.959058
2023-01-01 -0.627428
2023-01-03 0.116094
2023-01-04 0.939331
2023-01-06 -1.619870
2023-01-05 -0.874420
Name: A, dtype: float64
