이전 수업 내용 복습 및 정리
CS 기초 이론
Dram(main storage)(메모리)는 주기억장치 이다. HDD, SSD는 보조기억장치.
Sram은 빠르지만, 가격이 비싸 보통 메모리는 Dram으로 사용한다.
주기억장치 메모리에는 OS의 커널, 사용자 process들이 올라간다.
CPU와 메모리의 속도를 비교하면, CPU가 훨씬 빠르기 때문에 이를 메꾸기 위한 추가적인 부품이 CPU에 들어있다. 이 것이 L1캐시, L2캐시 이다.
L1캐시, L2캐시는 물리적인 소자는 Sram으로 되어있다. 그렇지만 Sram도 느리기 때문에, 실제 CPU의 연산자체는 레지스터가 하고 있다.
메모리와 비교해서 보조기억장치는 엄청 싸고, 엄청 느리다. 또, 메모리와의 차이는 보조기억장치는 반영구적이다라는 점이다. 메모리는 껐다켜면 데이터가 휘발된다.
프로그램의 모음과, process에서 사용하는 data들이 이 보조기억장치에 들어있다.
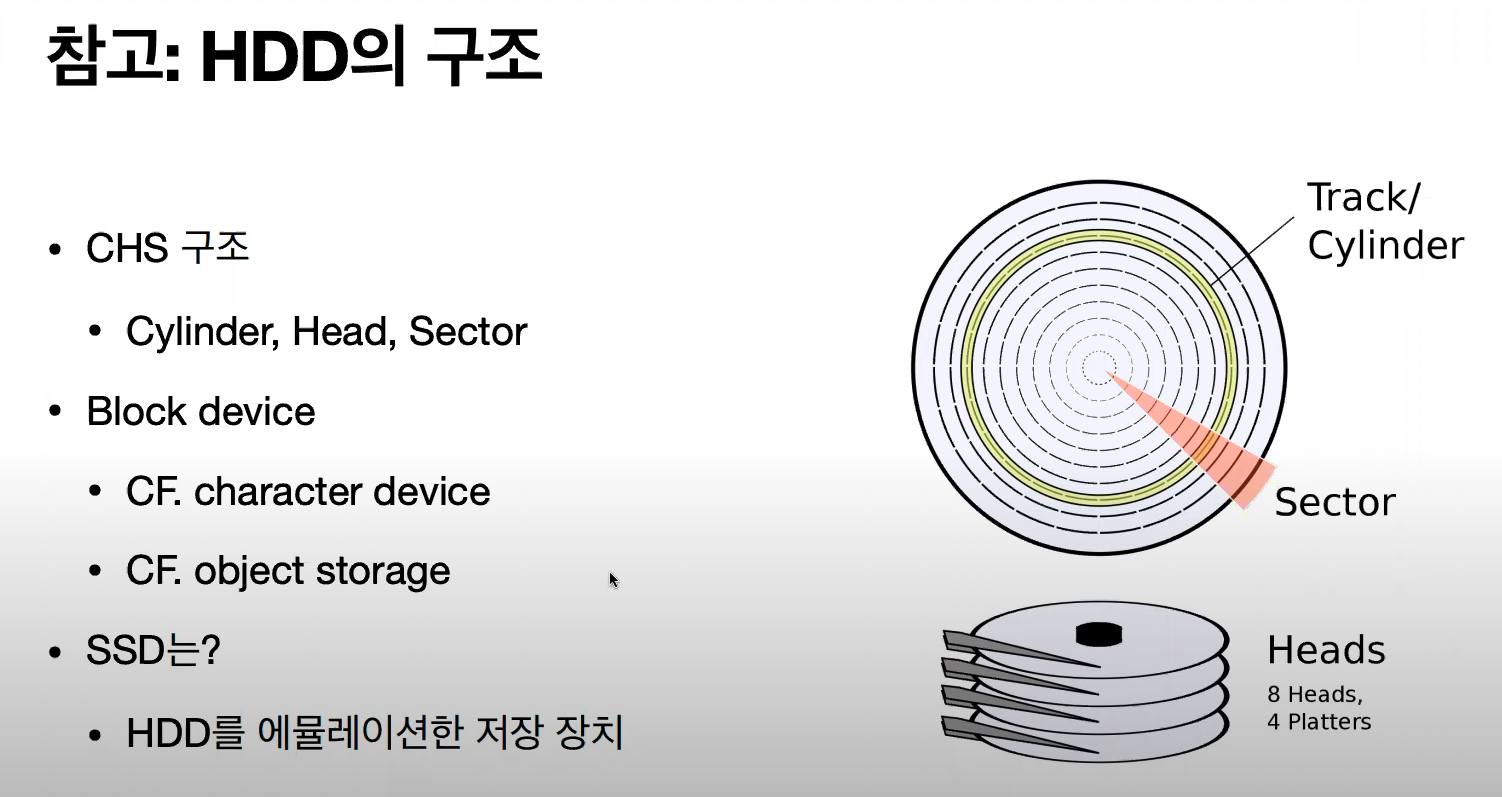
보조기억장치의 대표적인 장치인 HDD는 물리적인 저장 장치이다.
CHS 구조로, Cylinder(원통), Track(원 하나), Sector(트랙을 쪼갠 한 칸을 지칭).
HDD에서 데이터를 읽고 쓰는 단위는 Sector 단위이다. 그런데 우리가 프로그래밍 할 때 접근하는 HDD에 접근하는 최소 단위는 Byte 이다.
프로그램에서는 Byte 로 접근하지만, 실제 디스크에서는 1Byte 를 읽더라도, Sector 단위로 읽을 수 밖에 없다.
또한, Sector는 물리적으로 부를 때의 명칭이고, 이 물리적 단위에 해당하는 논리적 단위를 Block 이라고 부른다.
실제 HDD에 접근할 땐, 3번 Cylinder의, 3번 Header의, 5번 Sector 이런식으로 접근하지만, 이는 사람이 관리하기 매우 어렵기 때문에 우리는 I/O 를 할 때, LBA(Logical Block Address) 로 접근하는데, 이 조차도 어렵기 때문에 이 복잡한 구조와 상관없이 Disk I/O 를 할 땐 추상화가 잘 되어 있는 운영체제에서 제공되는 File System 을 사용하여 단순히 경로에 File 을 Write 하는 식으로 사용하는 것이다.
SSD 는 전기적인 장치이지만, 실제 인터페이스는 HDD 를 흉내내었기 때문에 HDD 대신 SSD 를 사용할 수 있다.
Head는 이를 나타내는 데,
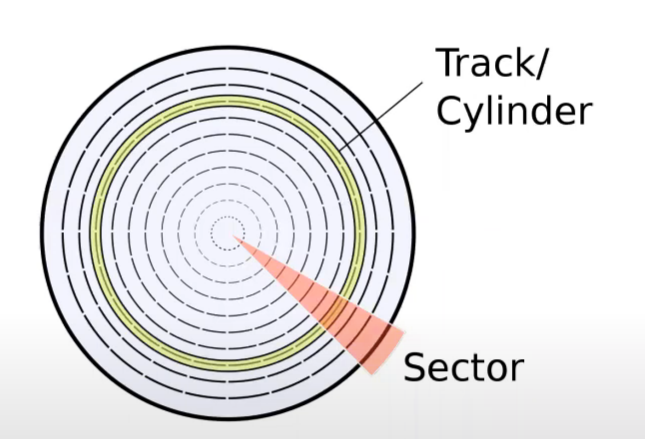
디스크의 원판에서 같은 Track 상에 data 가 모여있다면, 회전하며 쭉 읽으면 되지만, data 가 Track 에 모여있지 않고 퍼져있다면 Head가 왔다갔다 하며 읽어야 하는데, 이는 같은 Track 에 모여있는 것보다 속도가 매우 느리다. 그래서 옛날에 data 들을 같은 Track 에 모아주는 작업을 했던 것이 디스크 조각 모음 이다.
DB. 물리적 저장 구조
DataBase 에서 물리적인 최소 접근 단위는 Record 이다. 여기서 Record 는 Field 들의 집합인데, Field 하나만을 따로 읽어오는 방법은 존재하지 않는다.
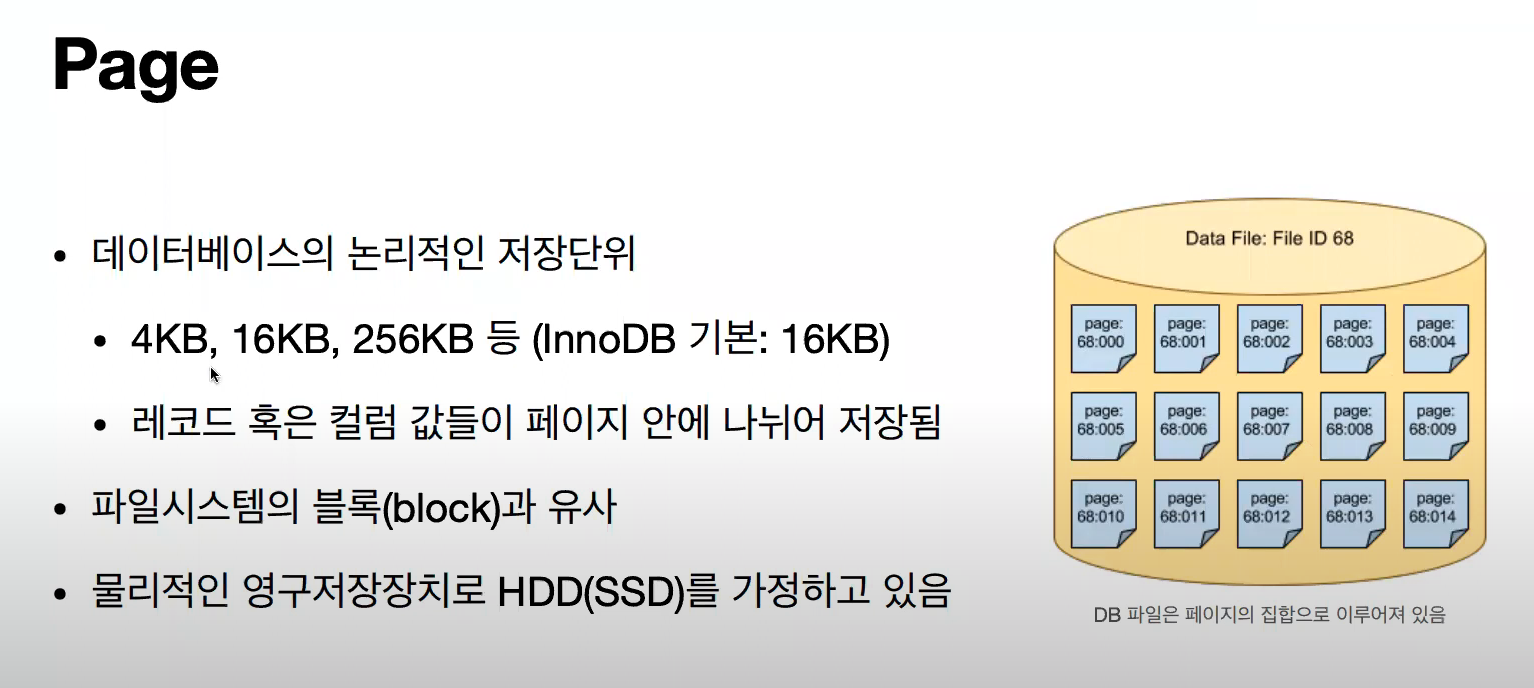
또, 이 Record 들의 집합, 논리적인 저장단위를 Page 라 한다. 위의 HDD 설명에서, Record(1Byte), Page(Sector(Block)) 이라 생각하면 된다.
Record 가 1Byte 라는 의미가 아니다. 개념적으로
1Byte 의 데이터를 읽어야할 때 HDD의 Sector(Block) 단위로 읽어야 하는 것과 같은 의미이다.
우리가 create database xxx; 하면, 하나의 File 이 만들어지게 된다. 이 것이 다시 16KB의 Page 로 쪼개지게 되고, 이 Page 안에 여러 개의 Record 가 모인 형태로 이루어져 있다.
학습 후 추가한 내용
HDD 의 물리적 단위는 Sector, 논리적 단위는 Byte 이지만, 1섹터는 512바이트 이기 때문에 Sector > Byte 이고,
DB 의 물리적 단위는 Record, 논리적 단위는 Page 이므로 Page > Record 가 된다.
DB가 1 Record 를 읽기 위한 과정은 아래와 같다.
- 물리적 단위인 Record에 접근하기 위해선, 프로그램 상에서 HDD 의 논리적 단위인 최소 1Byte 이상을 읽어와야 한다.
- HDD 의 1 Sector(Block)을 찾아 읽고 가져온 512 Byte 중 찾고자 하는 1 Byte 부분을 찾고, 1 Record 가 담겨있는 부분의 데이터를 찾아 읽는다.
데이터 베이스 파일은 운영체제에 의존적이다. OS의 File System 을 사용하기 때문이다.
우리는 HDD 를 구매하자마자 format 을 하는데, 이는 windows의 File System의 종류로. 즉 해당하는 운영체제에서 지원해주는 File System을 사용할 수 있게 해주는 준비작업인 것이다.
Windows, FAT32, NTFS
Linux, EXT1~4, Journaling file system
Mac, APFS
운영체제마다 사용하는 파일 시스템이 다르다.
Row store vs Column Store
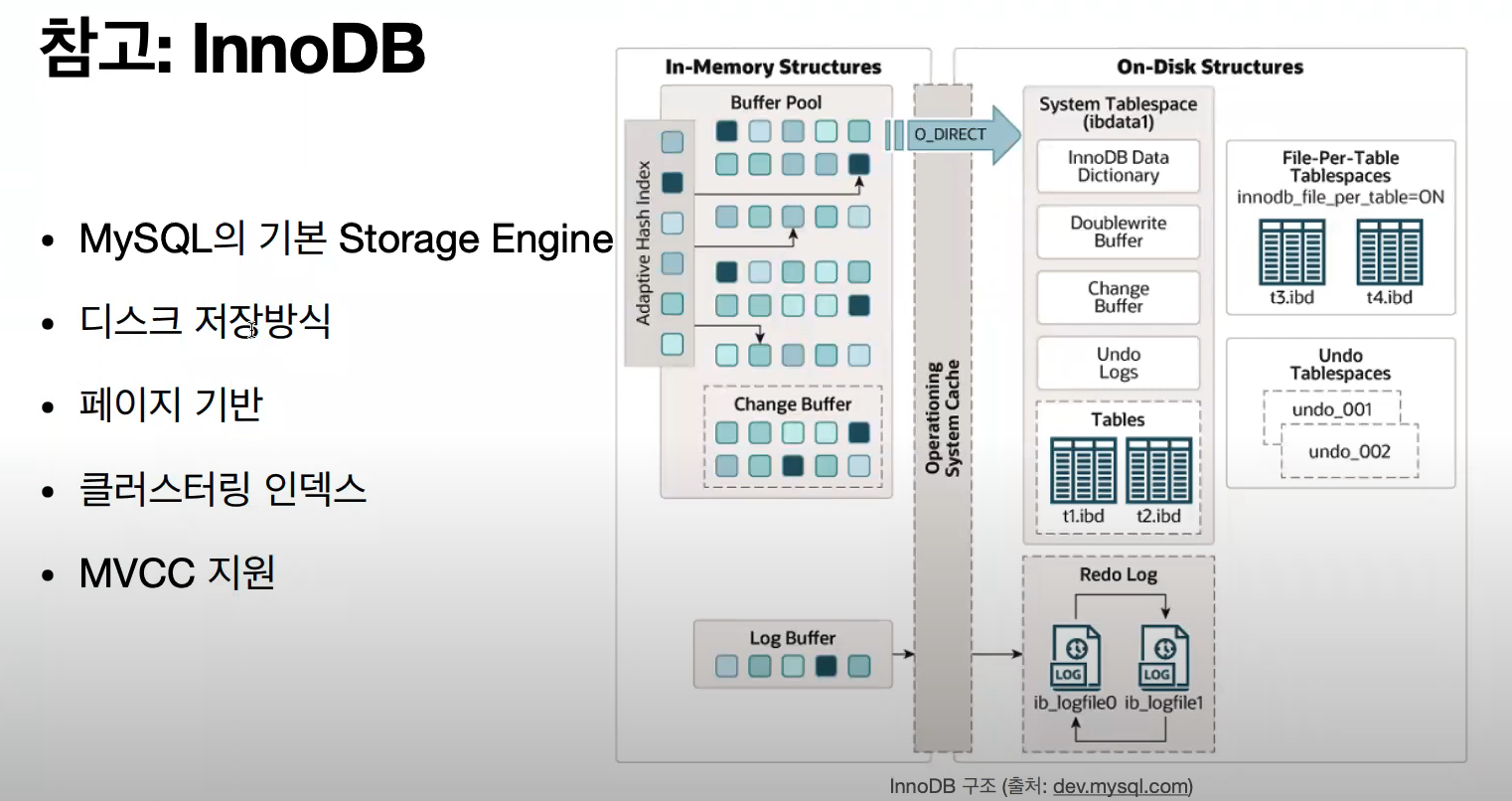
Mysql 의 기본 Storage Engine 은 InnoDB 이다. 이는 설정을 통해 바꿔줄 수 있지만, 기본적으로 InnoDB 가 transaction 도 지원되고 가장 무난하기 때문에 많이 사용한다.
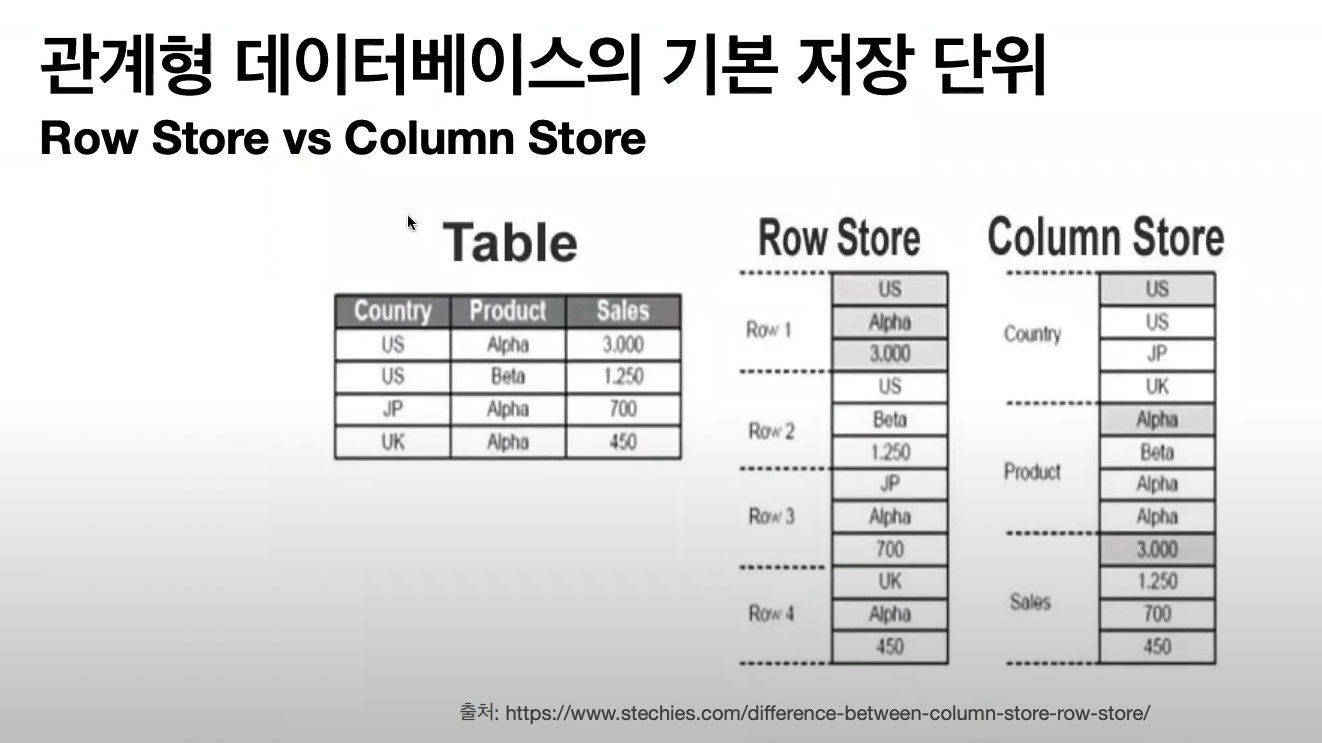
관계형 데이터 베이스에서 데이터를 저장할때, 데이터 베이스 File 을 만들고, 이를 Page 로 쪼개놓는 것 까진 공통적인데, 이 후 Record 를 저장할 때 방식이 2가지 이다.
-
Row Store
일정 갯수의 Page 에 각 행의 레코드가 한 줄씩, 들어간다. -
Column Store
컬럼 하나가 하나의 Page 가 되고, 모든 데이터가 들어간다.
일반적으로 관계형 데이터 베이스는 Row Store 방식으로 저장하는데, 데이터 중에 index 값이 25번째인 데이터를 읽어야한다고 가정 했을 때, Row Store 방식의 경우, 특정 Page 에 존재하는 25번 데이터를 한번 읽으면 끝이다.
하지만 Column Store 방식으로 저장했을 경우, Country Page의 25번째, Product Page의 25번째 ..... 등으로 컬럼의 수 만큼 Page를 조회해야 한다.
- Column Store 가 유리한 경우?
통계 낼 때. Row Store의 경우 전체 DB를 조회해야 한다. 하지만 Column Store의 경우 특정 컬럼만 읽으면 되므로 훨씬 빠르다.
그러므로 OLAP(Online Analytical Processing)에는 (ex. 빅데이터 분석) Column Store를,
OLTP(Online Transaction Processing)에는 (ex. 전자상거래, 게시판 등..) Row Store 방식을 사용하면 유리하다.
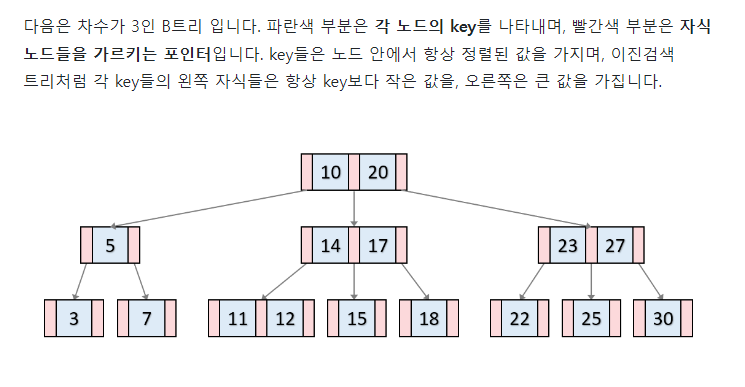
B Tree, B+ Tree
B Tree
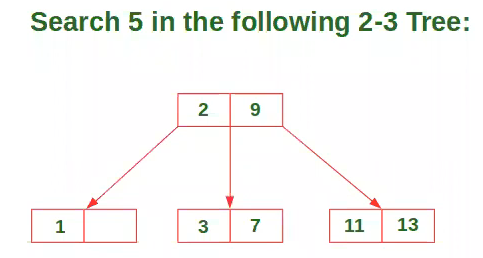
-
B Tree 는 하나의 Node 안에 값이 여러개이다.
-
B Tree 는, 메모리가 아니라 Disk 에 저장하는 용도이다.
-
Key Value 자료구조 이다. 주어진 Key 값으로 Value(Record) 를 찾는다.
-
Node의 Size는? Page 단위(일반적으로 16Kb)로 지정한다. DB의 데이터를 읽어오는 단위가 Page 단위이기 때문이다.
예를 들어, 이진트리로 100만개의 데이터를 저장한다 해보자.
이진 트리로 구현하게 되면 depth가 20이기 때문에, Page를 뒤져가며 찾게 되고 랜덤 access가 20번, I/O 가 20번이 일어나게 된다. HDD가 이를 수행하려면, Head 가 요기조기 읽으며 속도가 매우 느리다.
하지만 이를 B Tree 로 구현하면, 하나의 Node 에 데이터가 많이 들어있기 때문에 depth 는 3 혹은 4 이다. 이는 Random I/O 가 3~4번만 하면 된다는 소리이다.
그렇다면 B+ Tree 는 무엇일까?
B+ Tree
B Tree의 각 노드는 디스크의 블록과 같기 때문에 노드 하나를 접근하는 것은 디스크를 한번 더 접근하는 것을 의미한다. 그러므로 보다 적은 수의 노드를 생성하는 것이 색인구조의 성능을 높일 수 있다. 생성되는 노드의 수를 줄이기 위해 B Tree의 변형으로 B+ 트리가 나오게 되었다.
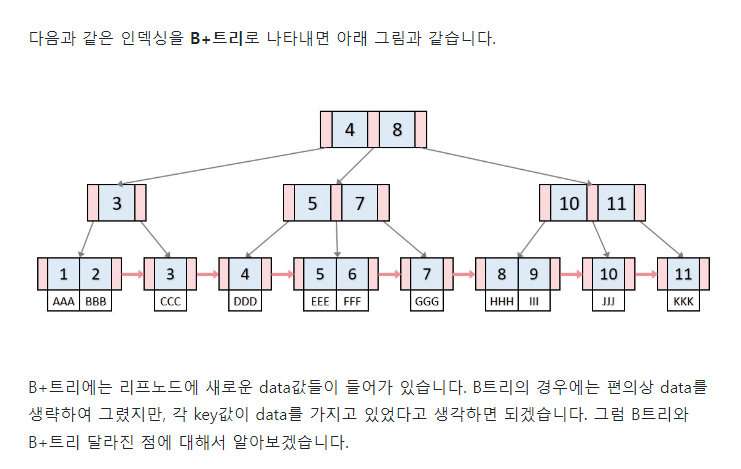
B Tree 는 Node 의 각각의 Key 들이 Data Page 에 대한 참조를 가지고 있다. 각 Node 에 Data Page 에 대한 참조가 있어서 이를 통해 Data 에 접근할 수 있다.
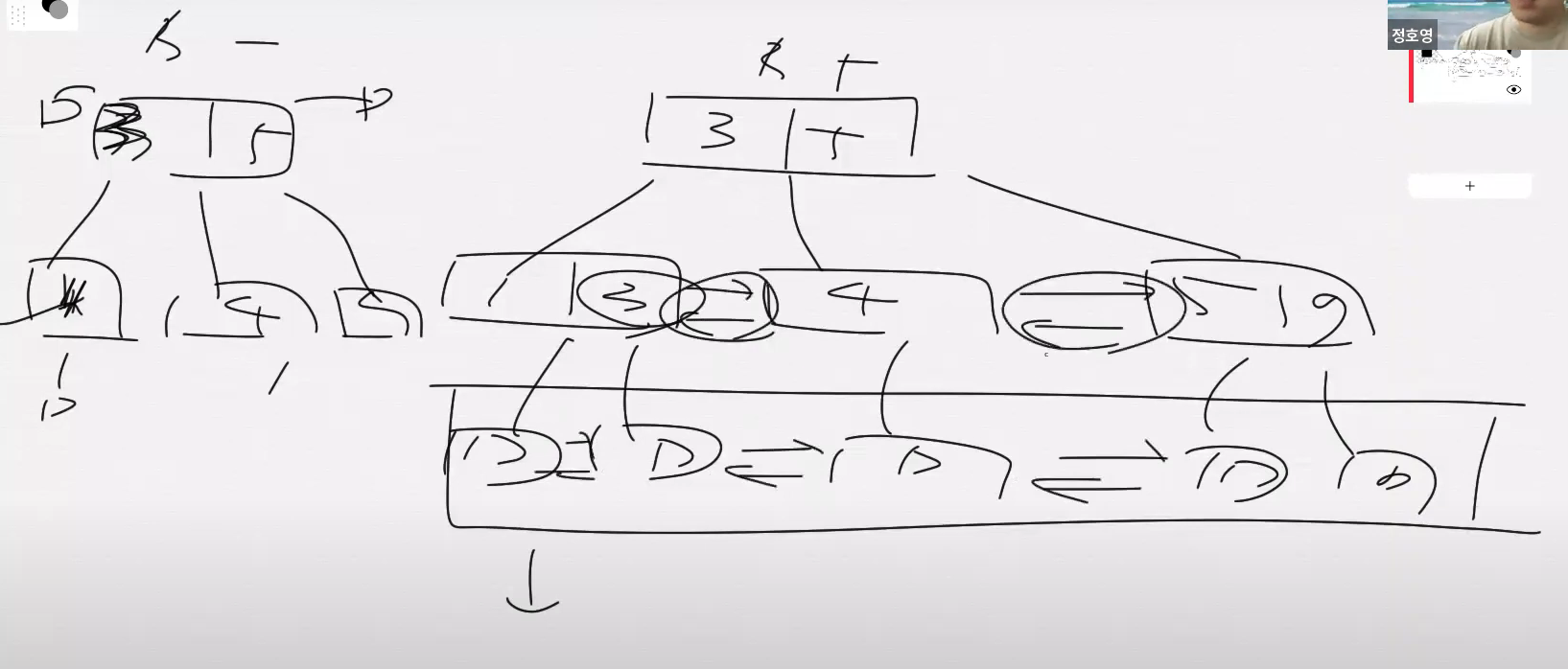
왼쪽 그림이 B Tree, 오른쪽 그림이 B+ Tree 이다.
B Tree 는 각각의 Key 값이 Data Page 에 대한 참조를 갖고 있지만, B+ Tree 는, leaf node 에만 Data Page 가 존재한다.
또, 이 left node 간에는 Sibling node 에 대한 양방향 포인터가 있는 것이 가장 큰 특징이다. 이는, 우리가 빈번하게 사용하는 쿼리 하나에 압도적으로 유리한데, 바로 범위 검색이다. 이 때문에 B+ Tree 가 1등 index가 된 이유이다.
우리가 평소에 얘기하는 B Tree 는 그냥 무조건 B+ Tree 라고 생각하면 된다.
참고하면 좋을 포스트 : https://wangin9.tistory.com/entry/B-tree-B-tree
Clustered Index

Index 라는 명칭을 가지고 있지만, 인덱스가 아니다.
자료구조를 일컫는다. Index를 어떤 방식으로 저장하는가? 의 차이라고 생각하면 된다.
관계형 데이터 베이스에서 데이터를 저장하는 방식 그 자체를 의미하는 것이다.

-
테이블을 만들면, PK 값으로 B+ Tree 를 하나 만들게 된다. 그리고 B+ Tree 의 leaf node 에 Data page 가 함께 존재하여, leaf node 그 자체가 데이터를 가지고 있다.
-
Data Page를 가리키는 Data Pointer 는 (중간에 절대) 존재하지 않는다.
-
leaf node 에 존재하는 Data 들은 PK 기준으로 정렬이 되어있다.
이 3가지 특징 전체를 통 틀어서 구성 된 자료구조를 Clustered Index 라고 부르고, InnoDB 의 자료구조가 이렇게 구성되어 있다.
추가로, Data Page 에 존재하는 Data 들은 Disk 에 Track 을 따라 저장되기 때문에 읽을 때도 순차 Access 를 하게 된다. 그렇기 때문에 Clustered Index 를 사용하는 것이다.
B+ Tree, Clustered Index 이런 것들은 즉, Disk 에서 Data 를 빨리 읽기 위해서 고안되고 만들어진 자료구조 이다.
추가로 참고하면 좋을 자료 : https://velog.io/@gillog/SQL-Clustered-Index-Non-Clustered-Index
