Gradient
어떤 미분에 대해서 gradient 라고 한다. 해당 경우에는 일반적인 scalar의 미분과는 다르다
vector → scalar의 경우 미분을 gradient라고 한다.
f:Rn→R
∇f:Rn→Rn → Dimension이 동일함 (vector → vector)
X∈R2
f(X)=XTX
f(x1,x2)=x12+x22
∇f(x1,x2)=[∂x1∂f(X)∂x2∂f(X)]
각 결과를 합쳐서 vector 하나로 만든다
∵ Gradient의 결과는 vector이어야 한다
ex) f(x)=f(x1,x2,x3)=x12+x1x2+x2x3+x33
해당 함수의 gradient ∇f(x)는 다음과 같다
∇f(X)=⎣⎢⎡2x1+x2x1+x3x2+3x32⎦⎥⎤이고, R3→R이다.
즉, 3차원 vector에서 3차원 vector가 된다.
Gradient Descent
f(x1,x2)=x12+x22, R2→R
∇f(x1,x2)=[2x1 2x2]T으로 어떤 지점의 gradient vector을 구할 수 있다.
f(X) 가 최소가 되는 min을 (근사적이고, iterative 하게) 찾는 여정을 gradient descent라고 할 수 있다.
Xn+1=Xn−η∇f(Xn)
η 값을 조정하면서 하강법을 실행한다.
η: learning rate
ex) f(x)=f(x1,x2,x3)=x12+x1x2+x2x3+x33이고, η=0.1일 때, 주어진 초기 위치 [1 1 1]T에서 한 번 갱신한 후의 위치 x′를 구하라
∇f(x)=⎣⎢⎡2x1+x2x1+x3x2+3x32⎦⎥⎤이고, ∇f(⎣⎢⎡111⎦⎥⎤)=⎣⎢⎡324⎦⎥⎤이다.
따라서 x′=x−η∇f(x)=[1 1 1]T−0.1[3 2 4]T=⎣⎢⎡0.70.80.6⎦⎥⎤이다.
Gradient Decent는 다음과 같은 특징이 존재한다.
- 미분이 가능해야 한다.
- global minimum은 보장하지 못한다 → local minimum에 빠질 수 있다
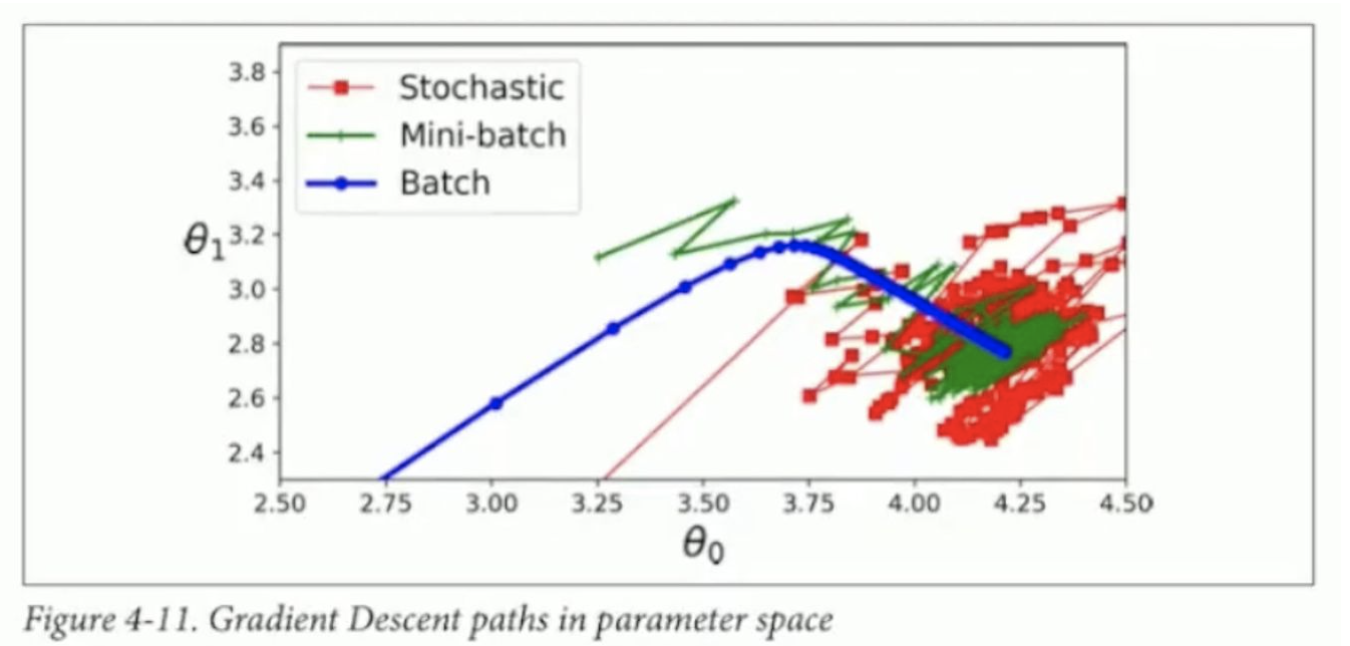
Batch Gradient Descent
Linear regression model y^=Xθ가 존재한다고 하자.
y^=Xθ ← 모든 sample에 대한 기술이 존재한다
즉, batch learning은 모든 sample에 대해서 학습을 시키는 방법이다 → parameter을 1번만 update한다
J(θ)=SSE(θ)=∥y−Xθ∥2=∑(y(n)−θTX(n))2
이때, J:Rn→R 이다.
∇θJ(θ)=∂θ∂J(θ)=2XT(Xθ−y)
Batch gradient decent에서 ∂θ∂J(θ)=2XT(Xθ−y)를 전개하면 다음과 같다
2[x(1) x(2) ... x(m)]⎣⎢⎢⎢⎡θTx(1)−y(1)θTx(2)−y(2)...θTx(m)−y(m)⎦⎥⎥⎥⎤=2∑i=1mx(i)(θTx(i)−y(i))
그러므로 해당 gradient vector의 j번째 component는
∂θj∂J(θ)=2∑i=1mxj(i)(θTx(i)−y(i))이다
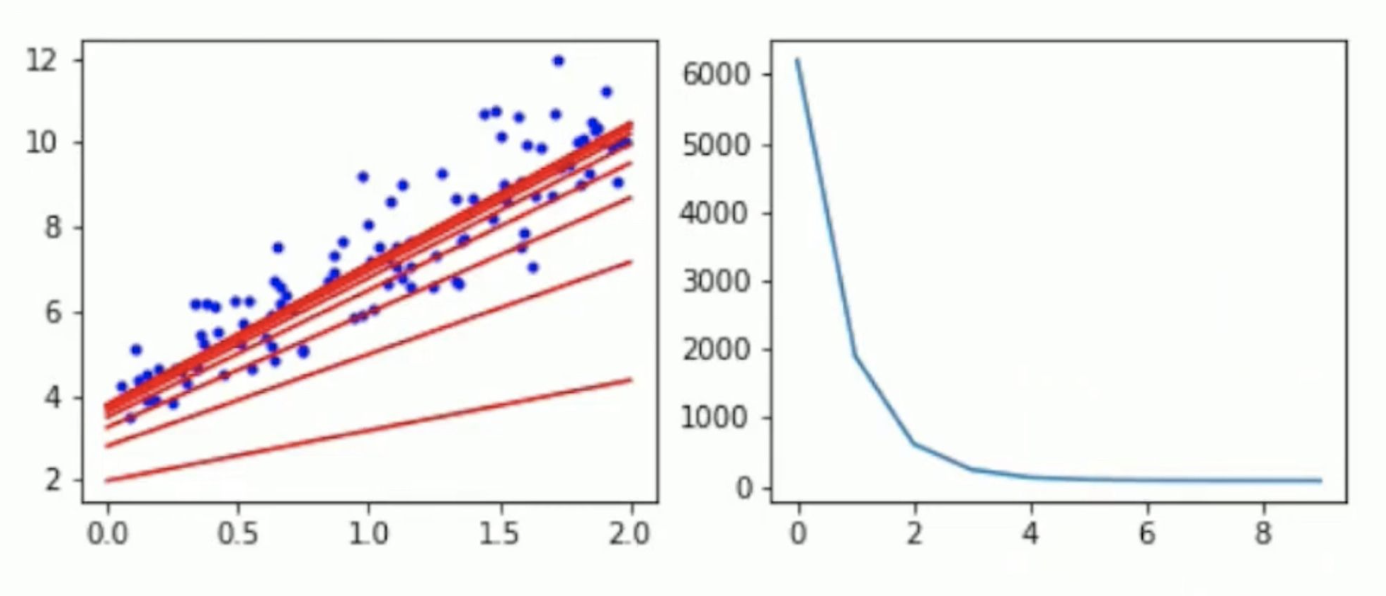
θ0부터 cost를 측정함, 해당 gradient를 통해 θ를 업데이트함
parameter을 한 번 업데이트 할 경우 batch 전체에 대한 계산이 필요함. 따라서 dataset이 커지면 속도가 느려짐
Learning rate η (hyperparameter) → 우리가 지정해야 하는 parameter
- η가 너무 작은 경우 시간이 오래 걸림
- η가 너무 큰 경우 최적해를 지나쳐 해를 찾지 못할 수도 있음
Learning schedule
Constant learning rate
- 보통 0.1, 0.01부터 시작하여 여러 가지 값으로 시험해보며 범위를 좁혀나감
Time-based decay
η=(1+kt)η0
η0: 학습률 초기값, k: hyperparameter, t: iteration
학습을 진행할 수록 η는 줄어드는 경항을 보임
Step decay
- 정해진 epoch마다 학습률을 줄이는 방법
- 5 epoch마다 반으로, 20 epoch마다 1/10으로
- Epoch: 훈련 데이터셋 전체를 모두 사용할 때 → 한 Epoch
Exponential decay
η=η0e−kt
η0: 학습률 초기값, k: hyperparameter, t: iteration
Stochastic Gradient Descent
J(θ)=SSE(θ)=i=1∑m(y(i)−θTx(i))2=i=1∑mJi(θ)θt+1=θt−2η((θt)Tx(t)−y(t))x(t)
무작위로 선택한 하나의 sample에 대해서 gradient를 계산해서 parameter를 update한다
대규모 데이터셋을 처리하는데 유리하며, 선택하는 사례의 무작위성으로 움직임이 불규칙적이다
Batch Gradient Descent에 비해 local optimum에서 쉽게 빠져나올 수 있다
최적해에 도달하지만 지속적으로 요동치며, Batch Gradient Descent와 마찬가지로 global optimum이라는 보장은 없다
Mini-batches Gradient Descent
훈련 데이터셋을 작은 크기의 무작위 부분 집합으로 나눠서 gradient를 구하는 방법
ex) 100,000개의 데이터 → (mini-batch size 100) x (1,000 mini-batches)
- 이 때의 epoch는 1,000당 1 epoch
Batch gradient descent와 Stochastic gradient descent의 절충안
Stochastic gradient descent보다 불규칙한 움직임이 덜하고, local minimum에서 빠져나오기가 상대적으로 어려움

