Abstract
1. Introduction
2. Approach
2.1. Training Dataset
2.2. Input Representation
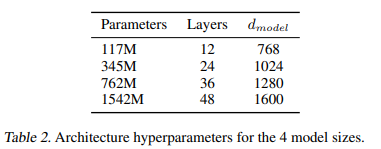
2.3. Model
3. Experiments
3.1. Language Modeling
3.2. Children’s Book Test
3.3. LAMBADA
3.4. Winograd Schema Challenge
3.5. Reading Comprehension
3.6. Summarization
3.7. Translation
3.8. Question Answering
4. Generalization vs Memorization
5. Related Work
6. Discussion
7. Conclusion
Acknowledgements
Self Q&A
Opinion
Abstract
- question answering, machine translation, reading comprehension, summarization와 같은 자연어 처리 task는, 일반적으로 task별 specific datasets에 대한 지도학습에 의해 이루어졌다.
- GPT-2는, 언어모델이 어떠한 명시적인 supervision없이 learning을 시작할 수 있다는 것을 일명 'WebText'라고 불리는 millions of webpages의 새로운 데이터셋을 학습시킴을 통해 입증했다.
- GPT-2는 CoQA dataset에 대해 'document'와 'questions'이 주어졌을 때, 55의 F1 score에 해당하는 'answers'을 생성했다(127,000+개의 training examples을 사용하지 않고도, 기존 baseline systems들 중 3/4보다 성능이 비슷하거나 능가한 수치).
- 언어모델의 capacity(용량)은 zero-shot task transfer의 성공에 필수적이며, 이를 개선하면으로써 task 전반에 대해 그 성능이 log-linearfashion(로그 선형적)으로 향상된다.
- GPT-2는 1.5B parameter를 가진 Transformer로, 제로샷 설정으로 SOTA의 language modeling datasets 8개 중에서 7개에서 최첨단 결과를 달성했지만, 여전히 WebText에서는 underfits이 있었다(fine tuning이 필요하다는 의미로 보임).
- 결과 샘플은 이러한 개선 사항이 반영되어, 결과가 coherent paragraphs(내용의 흐름에 이상이 없고, 같은 주제에 대해 이야기. 자연스러운 문장이라는 의미)으로 이루어져 있다.
- GPT-2는 자연적으로 발생하는 demonstrations에서 작업을 수행하는 방법을 학습하는 언어 처리 시스템 구축에 대한 유망한 방향을 제시한다.
1. Introduction
- 기존 머신러닝 시스템은 combination of large datasets, high-capacity models, supervised learning에서 좋은 성능을 보였지만, slight changes in the data distribution, task specification에 있어 약점이 있었다(범용성이 떨어진다는 의미).
- GPT-2는 궁극적으로 datasets을 manually create하거나나 labeling없이, 여러 task를 수행할 수 있는 일반적인 시스템으로 나아가고자한다.
- 단일 도메인 datasets에 대한 단일 task 훈련은, 일반화를 하는데 어려움을 주는 주요 원인으로 꼽힌다.
- 일반화 성능을 갖춘 시스템으로 발전하기 위해서는, 광범위한 도메인과 task에 대한 훈련과 성능 측정이 필요하고, 최근 이에 대해서 GLUE, decaNLP와 같은 benchmarks가 제안되었다.
- Multitask learning은 성능을 일반화하는데 유망한 framework이지만, NLP 영역에서는 아직 초기단계이다.
- 최근 연구에서 하나의 모델에 대해 10개와 17개의(dataset,objective) 쌍으로 학습을 시킨 바가 있다(McCann et al., 2018, Bowman et al.,
2018). - 그러나 meta-learning 관점에서, (dataset,objective)쌍은 datasets과 objectives의 분포로부터 샘플링한 단일 훈련 예제에 불과하다.
- 현재 ML시스템은 일반화되는 함수를 위해 수백, 수천개의 샘플이 필요한 것을 고려하면, 현재 접근방식으로 효과적인 multitask training을 실현하기 위해서는 그만큼 많은 훈련쌍이 필요하다.
- 현재 기술로는 그만큼의 훈련쌍을 만드는 것은 어려우므로, multitask learning을 수행하기 위해 추가적인 setups을 탐색해야할 필요가 있다(결국 다른 방법을 찾아야 한다는 의미).
- 현재 Language task에서 가장 우수한 성능을 내는 시스템은 pre-training과 supervised fine-tuning을 결합해 활용하는 접근이다(큰 규모의 종합적인 데이터로 모델을 사전 학습시킨 후, 풀고자 하는 downstream task에 관한 비교적 적은 데이터에 추가적으로 학습하는 방식).
- 이는 세 가지 형태를 거쳐 발전되어왔다. (2010년대 초반)단어별로 그 의미를 수치화한 벡터를 사전 학습한 후, task에 맞게 설계된 새로운 모델의 입력으로 사용하는 방식(word vectors were learned and used as inputs to task-specific architectures (Mikolov et al., 2013) (Collobert et al., 2011))
- (2010년대 중반)RNN과 같은 recurrent 네트워크를 이용하여 문장 단위로 특징을 추출하는 방식의 사전 학습을 하고, 추출된 문장 특징을 다른 모델에 사용(the contextual representations of recurrent networks were transferred (Dai & Le, 2015) (Peters et al., 2018))
- (2010년대 후반)attention 기반의 transformer 모델을 사전 학습한 후, 동일한 모델을 task에 추가적으로 학습 (fine-tune)하는 방식(recent work suggests that task-specific architectures are no longer necessary and transferring many self-attention blocks is sufficient (Radford et al., 2018) (Devlin et al., 2018))
- 그러나 이러한 방법들은 여전히 지도학습이 필요하다. 최근 언어모델에서 supervised data가 적거나 없는 경우에 대해, specific tasks에서 성능을 입증한 commonsense reasoning (Schwartz et al., 2017)과 sentiment analysis (Radford et al., 2017) 사례가 있다.
- GPT-2는 이 2가지 방법을 연결하고, Transformer의 트렌드를 이어갔다. 이를 통해 매개변수 조정이나 구조 변경과 같은 작업이 없는 zero-shot setting에서 down-stream tasks를 이어갈 수 있음을 입증했다.
- 이러한 접근은 언어모델이 zero-shot setting으로 광범위한 task에서 잠재성을 가질 수 있음을 입증했으며, SOTA에서도 유망하고 경쟁력 있는 결과를 달성했다.
2. Approach
- GPT-2에서 제시하는 핵심 접근방법은 'language modeling'이다.
- language modeling은 가변길이 symbols 시퀀스(s1, s2, ..., sn)로 구성된 예제 집합(x1, x2, ..., xn)으로부터 unsupervised 분포를 추정하는 방식으로 이루어진다(즉, 문장의 일부를 보고 다음 단어를 예측하는 것).
- 언어는 자연스러운 sequential이나 ordering이 있기때문에, 다음과 같이 symbols 간 결합 확률을 조건부 확률의 곱으로 인수분해 할 수 있다.
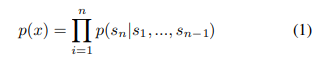
- 이 접근방식은 이전까지의 문장(symbols의 결합결과)을 바탕으로 다음에 올 symbols을 예측하는 모델링이다.
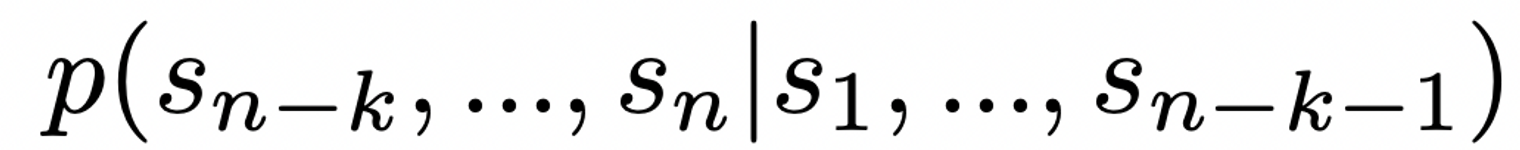
- 이러한 모델을 활용하면 다음과 같은 확률도 구할 수 있다. 즉, 이전까지의 문장이 주어졌을 때(1 ~ n-k-1), 다음(n-k ~ n)에 어떤 symbols이 올 확률을 구하고, 이를 바탕으로 문장을 완성할 수 있다.
- 최근 Transformer와 같은 self-attention architectures는 이러한 조건부 확률을 계산할 수 있는 모델의 표현력이 크게 향상시켰다.
- 하나의 task을 수행하기 위해서는 p(output|input)의 구조로, 같은 input에 대해 같은 out을 갖도록 해야하지만, 같은 input만으로 다양한 task에 대한 일반화를 위해서는, input뿐에 대한 조건 뿐만 아니라 task에 대한 조건도 설정해야 한다.
- 즉 , p(output|input, task)와 같은 형태가 되어야 한다.
- language는 tasks, inputs, outputs을 모두 sequence of symbols로 지정하는 flexible한 방법을 제공해야 한다. 예를 들어 영어 문장을 프랑스어로 번역하고자 한다면 (task, input, output)의 형태로, (translate to french, english text, french text)와 같이 입력해야 한다.
- 마찬가지로 reading comprehension을 훈련시키기 위해서, (answer the question, document, question, answer)의 형태로 입력해야 한다.
- Language modeling은 원칙적으로 어떠한 명시적인 supervision없이 다음 symbols을 예측하는 것이 가능해야 한다.
- 지도 학습 objective은 비지도 학습 objective과 동일하지만 시퀀스의 subset에 대해서만 평가되므로, 비지도 학습 objective의 전역 최솟값은 지도 학습 objective의 전역 최솟값과 동일하다. (중요한 내용같지만 이해 못해서 적어놓았습니다.)
2.1 Training Dataset
- 대부분의 선행 연구의 language models은 뉴스기사, 위키피디아, 소설책과 같은 single domain 텍스트에 대해서 학습을 진행했다.
- GPT-2는 다양한 자연스러운 demonstrations을 수집하기 위해 가장한 다양한 tasks와 domains에서 dataset를 구축했다.
- 기존에 인터넷 전체를 크롤링해서 얻은 Common Crawl 데이터셋은 범용적인 규모가 크지만, 데이터 퀄리티가 떨어진다는 문제가 있다.
- GPT-2는 조금 더 높은 퀄리티를 가진 데이터셋인 'WebText(GPT-2에서 사용할 데이터셋)'를 제시하기 위해, Reddit에서 Karma(좋아요)를 받은 글에 포함된 모든 외부 링크를 타고 들어가 해당 페이지를 크롤링하는 방식을 사용했다(수동으로 필터링 하는데는 데에는 cost가 너무 들어가기 때문).

- GPT-2는 2017년 12월 이후 생성된 링크를 포함하지 않으며, 중복 데이터를 제거하고 heuristic한 정리 작업을 통해 전체 40GB 텍스트 용량으로부터 약 800만 장의 문서를 사용했다.
- 다른 datasets의 common 데이터 소스이며, 학습 및 검증 과정에서의 중복을 최소한으로 하기 위해, WebText에서 Wikipedia 문서를 제거했다.
2.2 Input Representation
- general language model (LM)은 어떠한 문자열에 대해서도 확률을 계산할 수 있어야 한다. 따라서 대소문자구분, out-of-vocabulary(사전에 없는 단어)토큰화와 같은 전처리 과정을 필수적으로 거쳐야 한다.
- GPT-2는 Byte Pair Encoding(BPE) 방법을 사용하여 텍스트가 저장된 바이트 정보를 그대로 보존하는 방식을 사용했다.
- BPE는 subword 기반의 인코딩 방법으로 문자 단위로 단어를 분해하여 Vocabulary를 생성하고, 반복을 통해 빈도수가 높은 문자 쌍을 지속적으로 Vocabulary에 추가하는 방법이다(BPE 설명은 자세한건 찾아봐야하겠지만, 대략적으로 설명하면 자주 쓰이는 character에 대한 확률을 높이는 개념으로 이해하면 될 것)
- 이는 특수 기호도 학습이 가능하게 하며, 학습 데이터에 등장하지 않은 단어도 처리할 수 있는 등 다양한 장점을 가진다.
2.3 Model
- GPT-2는 Transformer 기반 아키텍처를 사용한다. 이 모델은 OpenAI GPT model(GPT-1)의 세부사항을 따른다.
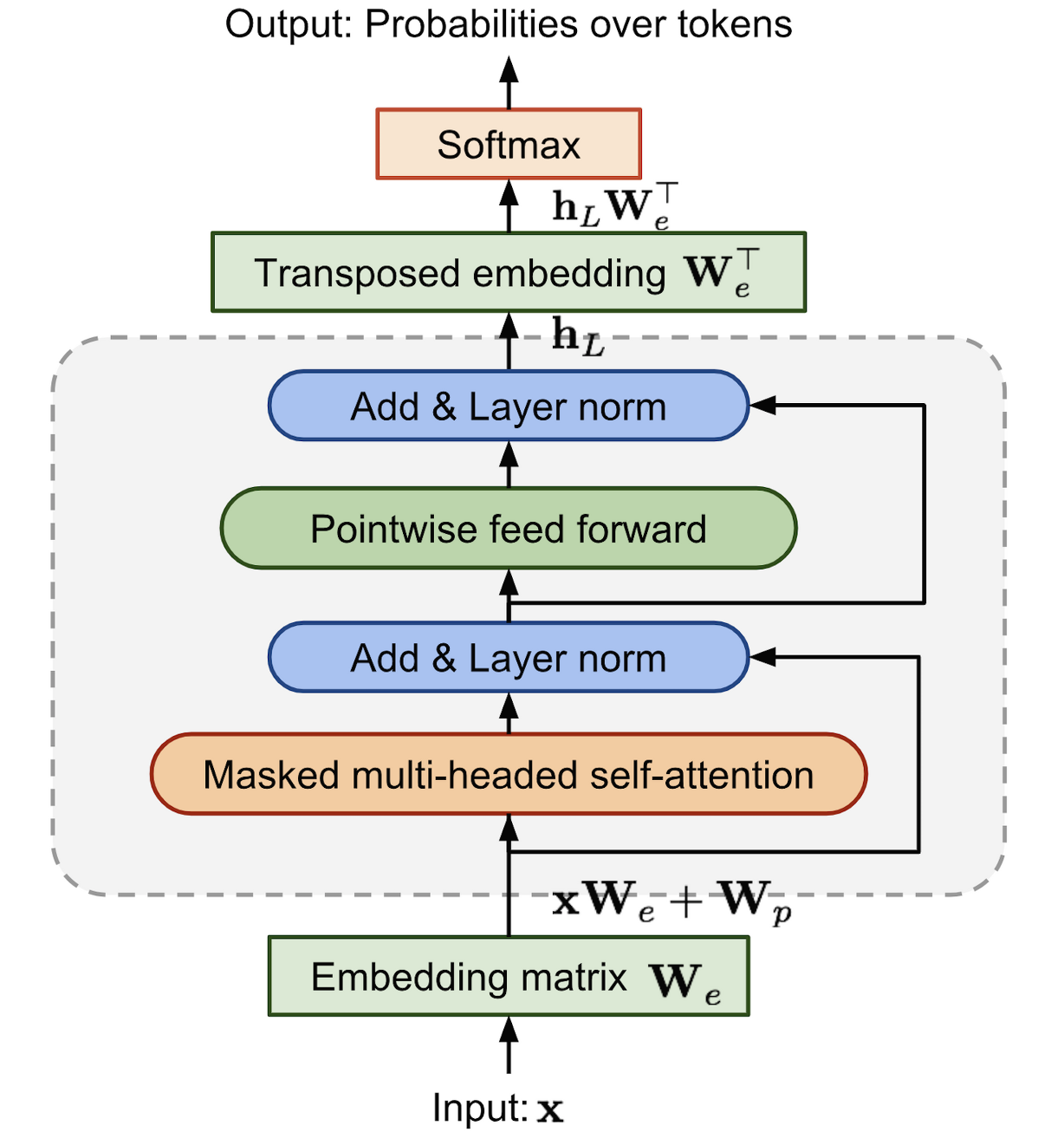
(GPT-1 decoder block)
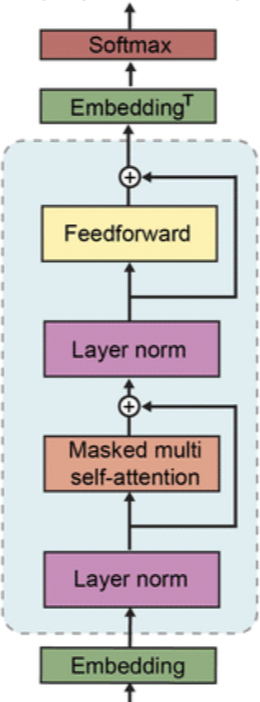
(GPT-2 decoder block) - GPT-1과의 수정사항은 Layer normalization이 sub block의 input 부분으로 옮겼다는 것이다. 또한 마지막 self-attention block 이후에는 추가적인 layer normalization이 존재한다.
- 또 하나의 변경점은 residual layer의 누적에 따른 initialization의 변화이다. residual layer의 깊이 N에 따라 1/√N * weights 를 사용하여 residual layer의 가중치를 설정 하였다.
- 또한 vocabulary의 크기가 50,257개로 증가하였으며, 한번에 입력가능한 context size 또한 512 에서 1024로 증가하였다.
-> 결론적으로 구조적인 차이는 크게 없으며, WebText라는 datasets을 구성하여 접근 한 것이 핵심이라는 것 같음(GPT-1을 공부해야..)
3. Experiments
3.1 Language Modeling
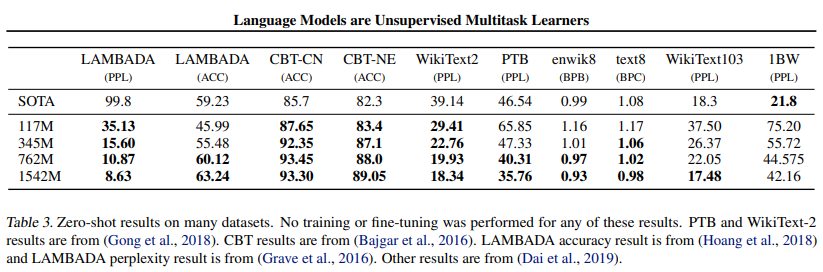
- GPT-2 는 byte 시퀀스에 BPE를 적용하기 때문에 기존에 존재하는 벤치마크 데이터셋에 자유롭게 적용이 가능하다.
- 다양한 벤치마크 데이터셋에 Zero-shot 환경에서 성능비교를 진행한 결과과, Fine-tuning을 진행하지 않은 Zero-shot 환경임에도 불구하고 8개의 데이터셋중 7개에서 SOTA를 달성하였다.
- 특히 크기가 작은 데이터셋인 PTB, wikiText-2에 대해서는 그 효과가 주목할만 하다.
3.2 Children’s Book Test
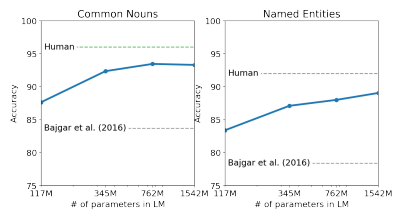
- CBT(Children's Book Test) 데이터셋은 품사에 따른 성능 비교를 위한 벤치마크 데이터셋
- 모델 크기에 따라 성능이 급격하게 증가하여 기존의 SOTA 모델을 능가하였으며, 가장 큰 모델의 경우 인간의 능력에 필적하는 결과를 보였다.
3.3 LAMBADA
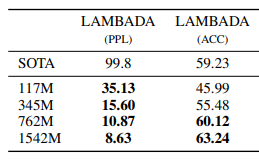
- LAMBADA 데이터셋은 언어모델의 long-term dependency를 측정할 수 있는 벤치마크 데이터셋
- LAMBADA 데이터셋에서도 perplexity를 99.8에서 8.6으로 개선시켰으며, Accuracy 또한 19%에서 52.66%로 향상시키며 SOTA를 달성
- 뛰어난 성과를 보였다는 점에서 Long-term dependency를 포착할 수 있는 능력 또한 기존의 모델에 비해 우수함을 알 수 있었다.
3.4 Winograd Schema Challenge
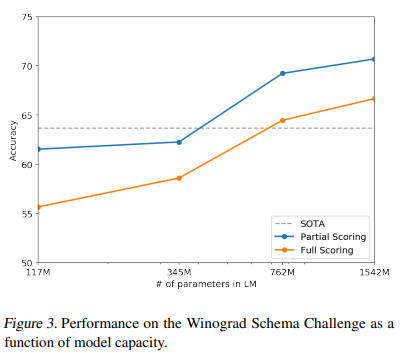
- Winograd Schema Challenge는 Text의 모호성(ambiguity)을 푸는 작업을 통해 언어모델의 추론능력을 평가하는 작업이다.
- GPT-2는 기존의 SOTA 모델보다 7% 높은 정확도로 훌륭한 추론능력을 보여줬다.
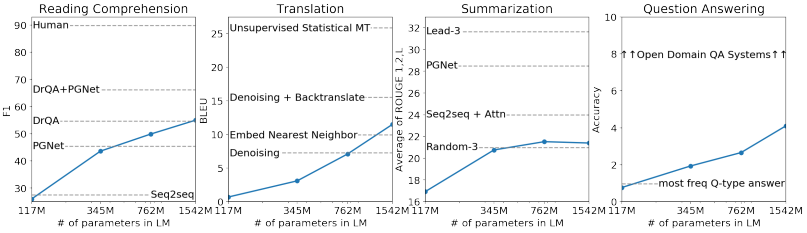
3.5 Reading Comprehension
- Conversation Question Answering dataset(CoQA)는 7개 도메인의 문서에 대한 Q,A 를 포함하고 있는 데이터셋(CoQA는 언어모델의 문서 이해능력과 Q,A 능력을 동시에 평가 가능)
- SOTA 모델인 BERT에는 미치지 못했지만, GPT-2 는 fine-tuning 없이 55의 F1 score로 좋은 성능(GPT-2가 127,000개의 지도학습 데이터를 사용하지 않은 결과이기 때문에 더 고무적이라고 판단)
3.6 Summarization
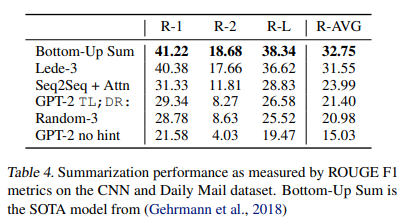
- CNN,Daily Mail dataset 사용
(이해 어려움)
3.7 Translation
- 번역 성능에 대한 실험은 WMT-14 English-French dataset을 활용하여, 영어-불어, 불어-영어 두가지 경우에서 비교를 진행하였다.
- 번역 성능은 다른 Task에 비해 좋지 상대적으로 좋지 못했습니다. 불어-영어의 경우에는 SOTA를 달성하지는 못하였지만 기존의 모델보다는 좋은 성능을 보여준 데에 비해(BLEU = 11.5),영어-불어의 경우 word by word로 번역하는 모델보다도 좋지 못한 성능을 보여주었습니다. (BLEU = 5)
3.8 Question Answering
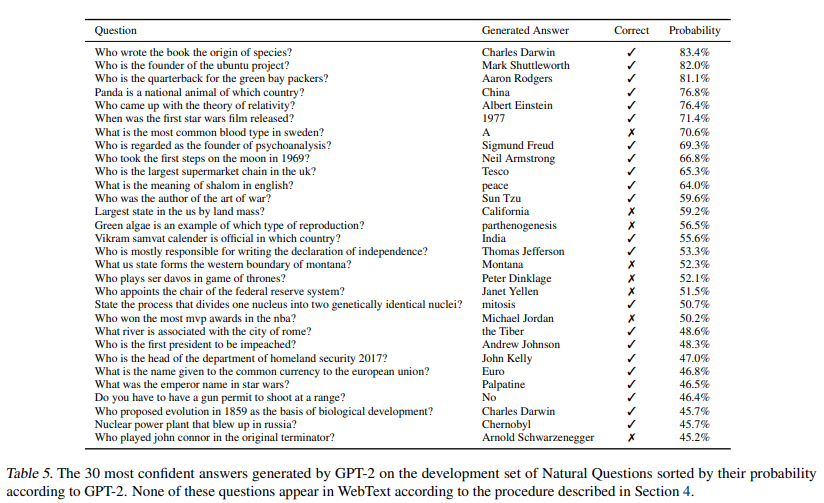
- QA task에서 일반적으로 사용하는 '정확히 일치 하는지' 여부(exact match metric)를 지표로 비교하였을 때에는 4.1%의 정확도로 기존의 모델들보다 5.3배 높은 정확도
- 매우 작은 모델들은 대체로 1%를 넘지 못하는 성능을 보였는데, 아직까지는 모델의 크기가 QA에 있어서 매우 중요한 요인이라는 것을 확인할 수 있었다.
- GPT-2는 가장 자신있던 질문 1%에 대해 평균 63% 정도의 정확도
4. Generalization vs Memorization
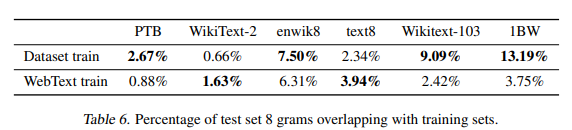
- Train set과 Test set의 과도한 중복(Overlap)은 모델의 Memorization을 유도하고 Generalization 성능을 왜곡하여 나타낼 수다.
- WebText 데이터셋과 기존 데이터셋이 크지 않은 overlap을 보였지만, 어느정도 영향이 있었음을 확인할 수 있다.
- 하지만 이는 기존 데이터셋이 Train,Test set 간에 가지고 있던 overlap에 비해서는 특별히 크지 않았으므로, 성능 향상의 효과가 있었다면, 연구에 대한 성과를 인정할 수 있다.
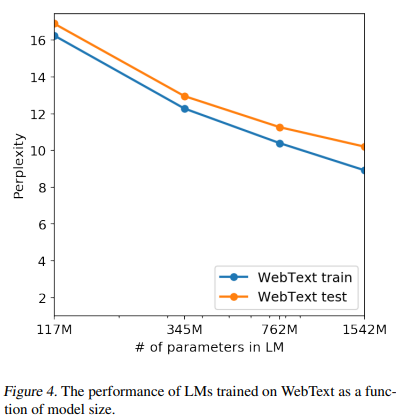
- Memorization의 정도는 hold-out set과의 성능비교를 통해서도 확인해 볼 수 있다.
- 아래의 그래프에서 Test set과 Train set의 성능은 거의 비슷하며, 또한 모델 크기에 따라서 동시에 성능이 증가하는 것을 볼 수 있다.
- 이는 Memorization이 모델 성능개선에 큰 요인이 아니었으며, 모델이 아직 underfitting 되어 더 개선될 여지가 있음을 보여준다.
5. Related Work
6. Discussion
7. Conclusion
- GPT-2는 GPT-1 모델을 기반으로 하여 Unsupervised pre-training 작업을 극대화 시킨 pretrained language model
- GPT-2는 기존의 pretrained language model과는 다르게 Fine-tuning을 필요로 하지 않는다.
- 전체적인 구조는 GPT-1을 계승
- Dataset의 overlap으로 Memorization에 의한 요인을 확인한 실험에서 모델의 Generization 성능에 대한 새로운 관점을 얻을 수 있었다.
- 모델과 데이터셋의 크기가 성능에 큰 요인이 되긴 하였지만, FIne-tuning을 제외하고도 매우좋은 성능을 보였다는 점에서 언어모델 연구에 잇어 중요한 기여
- 평가에 사용된 8개의 task 중에서 7개에서 최첨단 성능을 zero-shot 방식으로 얻을 수 있었다
