Abstract
1. Introduction
2. Related Work
3. Methodology
3.1. Architecture
3.2. Training
3.2.1 Ground Truth Label Generation
3.2.2 Weakly-Supervised Learning
3.3. Inference
4. Experiment
4.1. Datasets
4.2. Training strategy
4.3. Experimental Results
4.4 Discussions
5. Conclusion
Self Q&A
Opinion
Abstract
- 최근(당시 2019년 4월) 딥러닝 기반 Scene text detection가 등장하여 유망한 결과를 보여주고 있다.
- 이전에 사용되던 rigid word-level bounding
boxes(단어단위 검출) 방법은 임의의 영역(불규칙적인 영역을 의미 하는 것으로 보임)을 표현하는데 제한이 있었다. - 본 연구에서는 character와 character간의 선호도를 기반으로 효과적으로 텍스트영역을 검출했다(word-level이 아닌 character-level의 연구를 했다는 의미로 보임).
- character-level annotations 부족 문제를 극복하기 위해(벤치마크 데이터 셋을 의미하는 것으로 보임), 합성이미지의 annotations과 실제이미지의 annotations 모두 사용했습니다(외부 데이터로 character-level train시킨 모델을 함께 사용했다는 의미로 추정).
- 자연 이미지에 곡선 형태의 텍스트를 포함하는 데이터셋인 TotalText와 CTW-1500를 비롯한 6개의 벤치마크에서, CRAFT의 character-level text detection은 기존(당시)의 state-of-the-art detectors(SOTA)보다 크게 향상된 성능을 보였다.
- 임의의 방향을 가지는, 곡선형태의, 변형된 텍스트와 같은 scene text images에서도 detecting 결과를 보장한다.
1. Introduction
- Scene text detection의 목적은 word-level bounding boxes를 찾는 것이다. 그러나 word-level 검출은 곡선, 변형, 하나의 박스로 묶기 어려울 정도로 긴 경우에 어려움이 있었다.
- 반면 character-level 검출은 연속적인 문자(chracter)를 상향식방법으로 연결하여 까다로운 텍스트를 처리 할 때 장점이 있지만, 대부분의 existing 데이터셋은 character-level annotations을 제공하지 않으며, character-level annotations이 된 데이터를 얻기에 너무 많은 비용이 든다.
- 논문에서는 individual character 영역을 찾아내는 것과, 찾아낸 individual character 영역을 연결하여 text instance를 검출하는 방법을 제안한다.
- CRAFT는 character region score와 affinity score를 제공하는 CNN(convolutional neural network)으로 설계되었다.
- region score는 이미지로부터 개별문자(character)를 찾아내기 위해, affinity score는 각각의 문자(character)를 하나의 text instance로 그루핑하기 위해 사용됐다.
- character-level annotations 부족문제를 보정하기 위해, weakly-supervised 학습 방법을 이용했다. (다른 word-level datasets의 character-level의 추정값(ground truths)으로 평가)
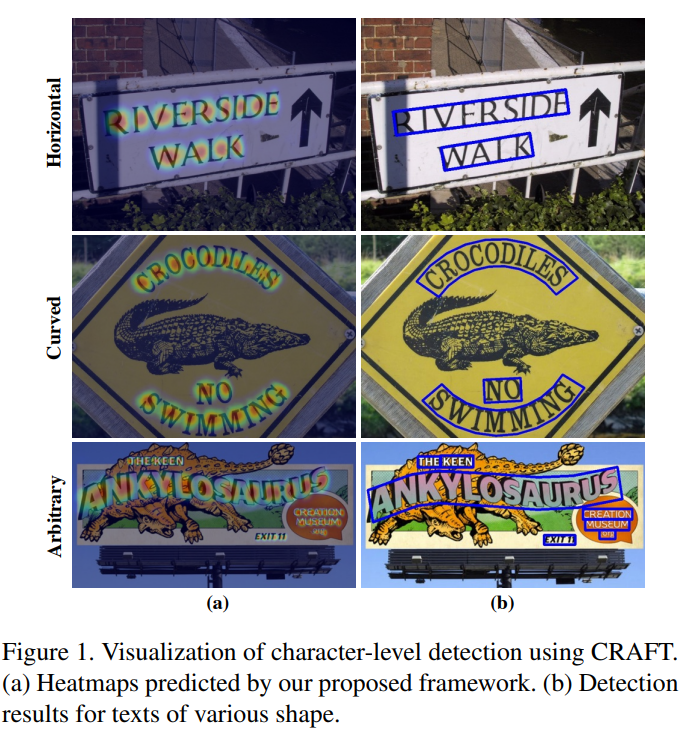 (CRAFT 결과 예시. ICDAR datasets의 기존 SOTA보다 우수한 점수. 다른 데이터셋에서도 long, curved, and/or arbitrarily shaped texts를 검출함에 있어 좋은 성능)
(CRAFT 결과 예시. ICDAR datasets의 기존 SOTA보다 우수한 점수. 다른 데이터셋에서도 long, curved, and/or arbitrarily shaped texts를 검출함에 있어 좋은 성능)
2. Related Work
-
딥러닝 이전 텍스트 검출 주요 트렌드는 MSER, SWT와 같은 수작업을 통한 상향식 검출방법
-
최근에는 Faster R-CNN, FCN와 같이 object detection/segmentation 방법을 채택하는 딥러닝 기반 텍스트 검출이 대중화되었다.
-
Regression-based text detectors
-
Segmentation-based text detectors
-
End-to-end text detectors
-
Character-level text detectors
3. Methodology
- CRAFT의 목표는, 자연이미지 속에서 개별문자(individual character)의 정확한 위치를 찾아내는 것이다.
- 이를 위해 딥러닝 기술을 이용해 문자영역(character regions)을 검출하고 문자 간 affinity(관계성)를 예측하도록 했다.
3.1 Architecture
- CRAFT는 batch normalization(배치정규화: 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것)을 사용하는 VGG-16기반 FCN을 토대로 채택했다.
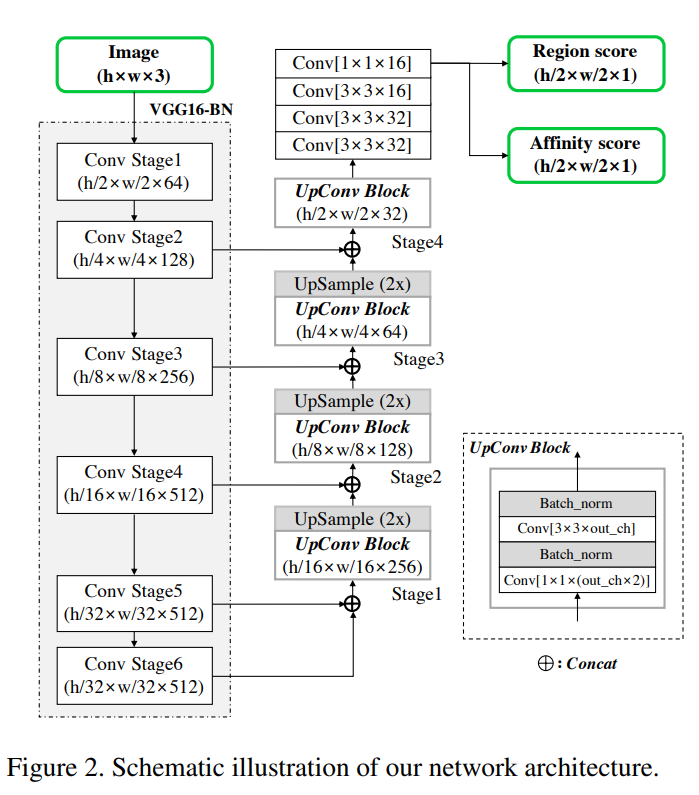
3.2 Training
3.2.1 Ground Truth Label Generation
(Ground Truth: 기상학에서 유래한 용어로, 지상 실측 정보모델는 '목표값'으로 해석하면 된다. 우리의 모델이 예측해주기를 원하는 답으로, Label와 의미가 유사하지만 다르다.)
-
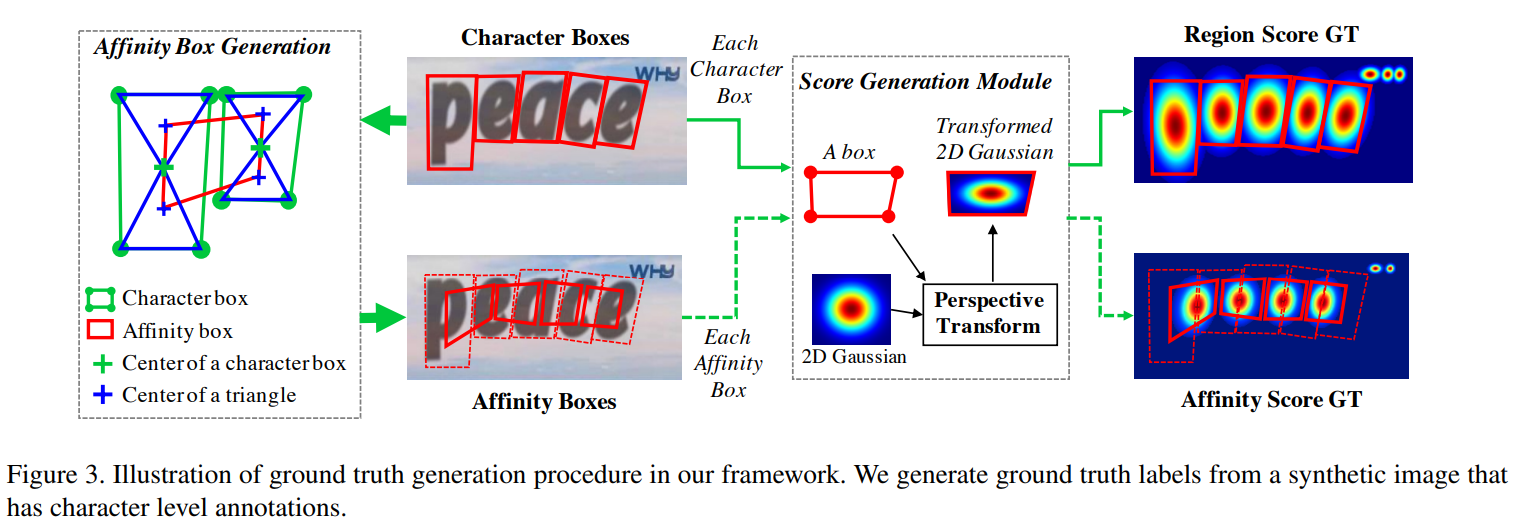
character-level bounding boxes의 region score와 affinity score를 구하기 위한 작업
-
region score는 픽셀이 문자의 중앙인 확률을 의미
-
affinity score는 픽셀이 문자와 인접한 문자 사이의 중앙인 확률을 의미
-
1) prepare a 2-dimensional isotropic Gaussian map(2차원의 등분성(isotropic) Gaussian map 생성).
-
2) compute perspective transform between the Gaussian map region and each character box.
-
3) warp Gaussian map to the box area.

->
- 정사각형 형태의 임의의 가우시안 히트맵 생성
- Character annotation에 맞춰 box를 늘리기(원형변환. Region score)
- 박스의 중심점틀 위 아래로 긋고, 다른 글자와 연결, 이 박스를 기준으로 다시 affinity score계산
3.2.2 Weakly-Supervised Learning
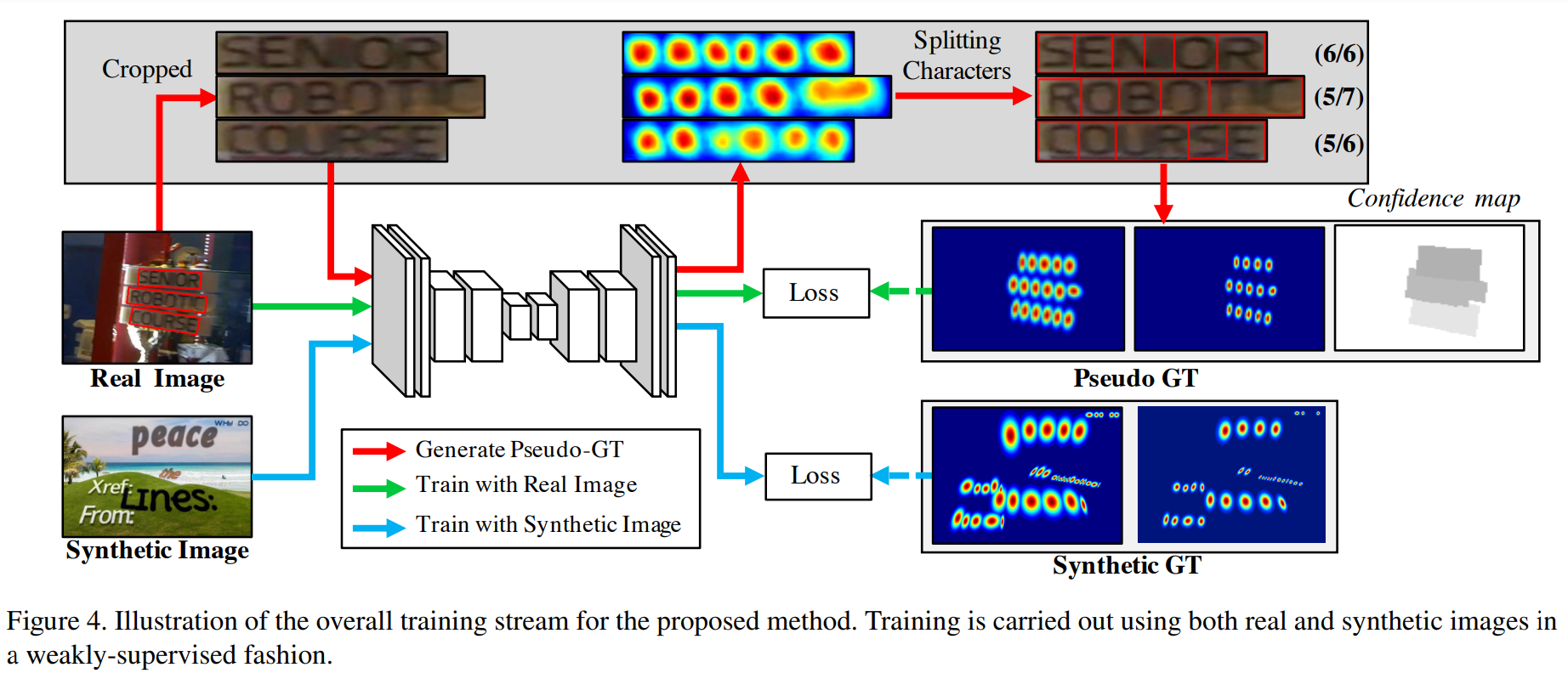
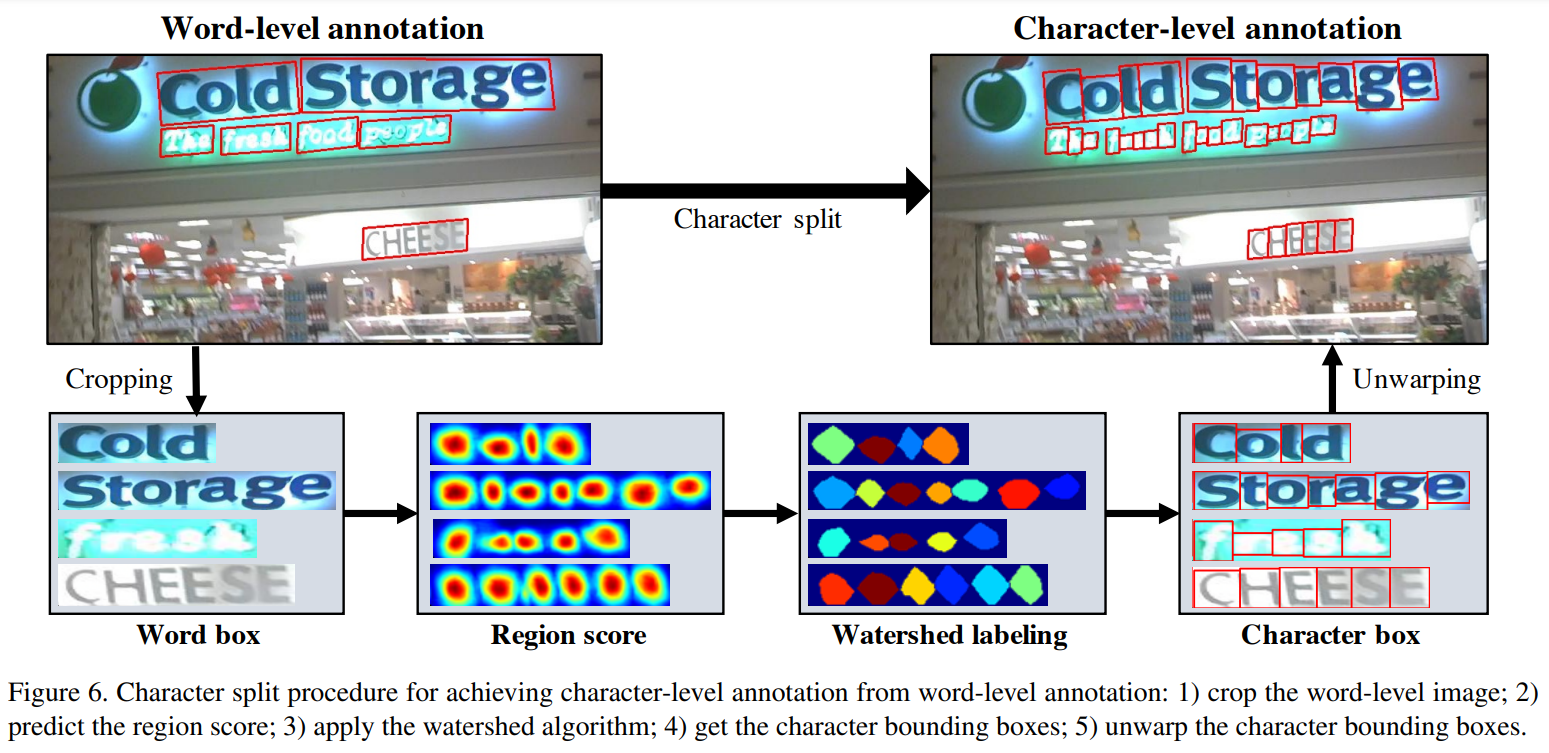
- Scean text detection는 어렵지만, 일반 텍스트 이미지로부터 추출은 어렵지않다.
- Wordlevel로 추출한 이미지를 crop(scean이미지를 여러개의 일반이미지로)하여 이 이미지를 characterlevel로 검출
- 이는 official한 annotation값이 아니므로, 이에 대한 신뢰도 기준을 정해서 계산했다는 내용이다
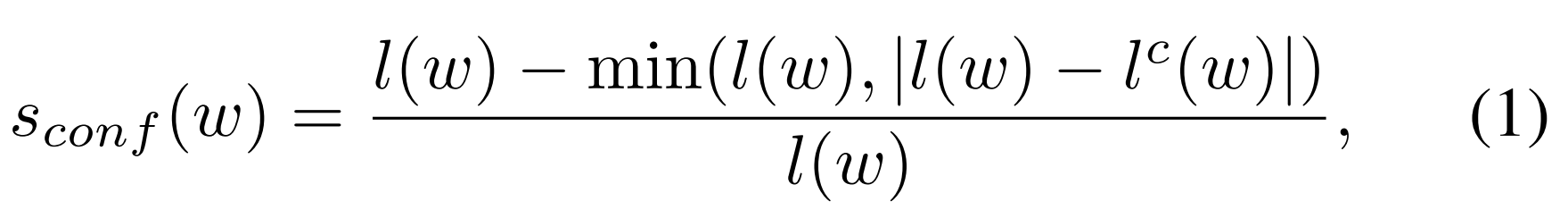
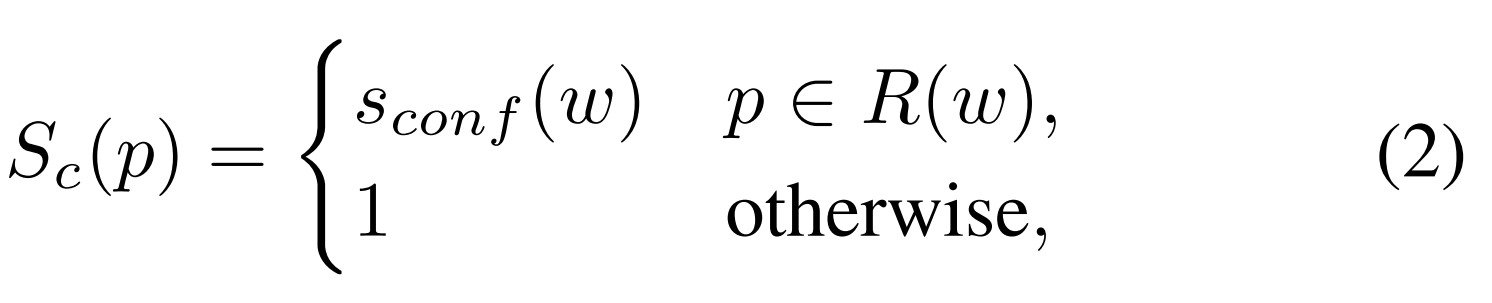
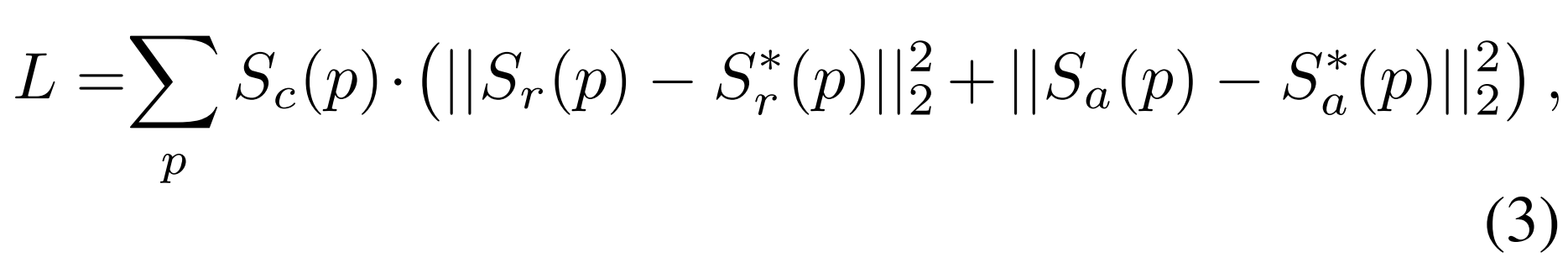
3.3 Inference
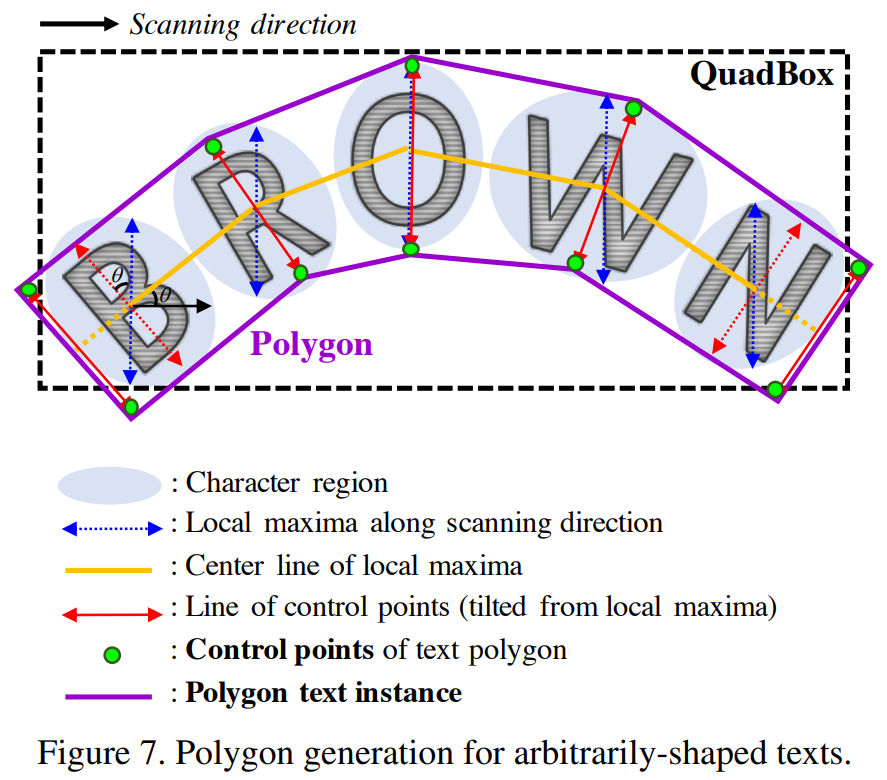
- Score가 임계치를 넘긴 값만 필터링
- 가장 긴 문자의 길이를 기준으로 모두 blue 긋기
이 중심점을 yellow로 연결 - Yellow와 수직이 되도록 blue 회전시켜 red로
- 양 끝 red를 포함하는 문자에 그대로 red 이동
이를 이어서 폴리곤으로
4. Experiment
4.1 Datasets
4.2 Training strategy
- 훈련은 2단계로 구성. SynthText 데이터셋으로 50k iterations 진행한 다음, 각 벤치마크 데이터셋을 채택하여 모델을 미세조정하였다.
- ICDAR 2015와 ICDAR 2017 datasets의 “DO NOT CARE” text regions은 sconf (w)을 0으로 설정하는 것으로 무시되었다.
- 모든 훈련과정에 ADAM optimizer 사용
- (뒤는 생략)
- Weakly-supervised training은 2종류의 데이터가 필요. quadrilateral annotations for cropping word images(단어 이미지를 자르기 위한 사각형 주석)과
transcriptions for calculating word length(단어 길이 계산을 위한 복사본?)
4.3 Experimental Results
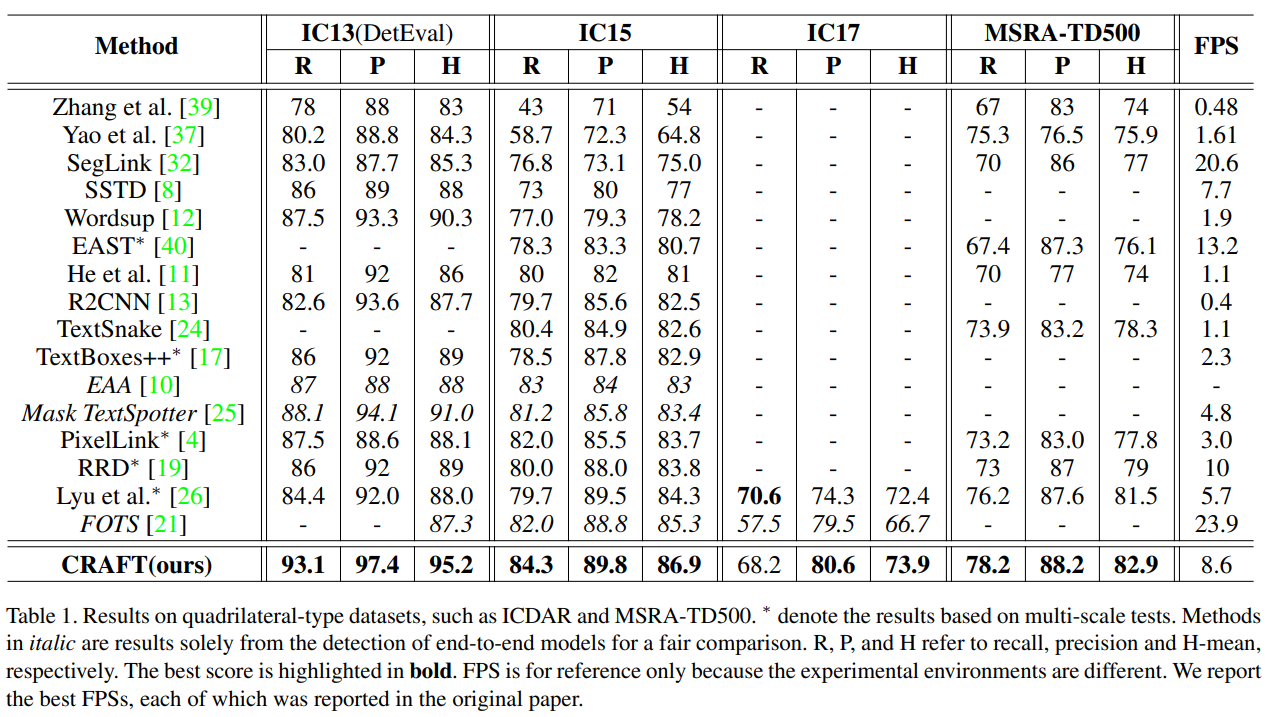
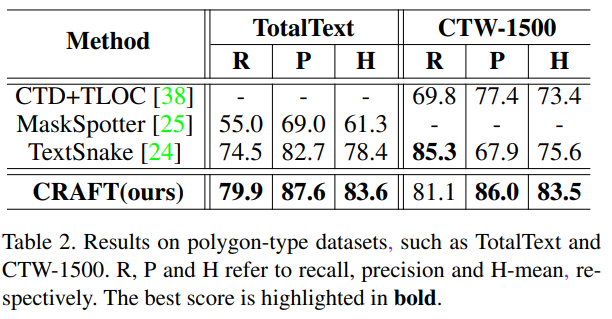

4.4 Discussions
-
Robustness to Scale Variance
-
텍스트의 크기가 다양함에도, 모든 데이터 셋에 대해 single-scale 실험만을 수행했다. 이는 multi-scale에 의존하는 대부분의 다른 방법과 차별화되는 점이다.
-
이러한 장점은 전체 텍스트가 아닌 개별문자의 위치를 찾는 특성에서 비롯된다.
-
상대적으로 작은 receptive field는 큰 이미지에서 단일 문자를 찾아내기에 충분했고, 이는 CRAFT가 변형된 문자를 잘 검출하도록 했다.
-
Multi-language issue
-
IC17데이터셋에 포함된 방글라데시 문자와 아랍어 문자는 필기체 문제로 쓰여있기에 개별적으로 구분하지 못했다.
-
동아시아 문자의 경우 일정한 폭으로 쉽게 구분할 수 있어 조금의 train만으로도 고성능의 모델을 만들 수 있었다.
-
Comparison with End-to-end methods
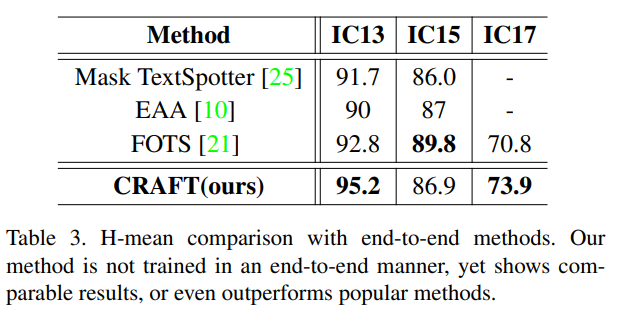
-
CRAFT는 detection 기능만 훈련. 다른 End-to-end methods(recognition이 포함된 OCR모델을 의미)와 비교했을 때, 실패 사례를 분석한 결과, 시각적 단서가 아닌 의미적으로 구분된 단어의 recognition에서 이점을 얻을 수 있을 것으로 보인다(무슨 말인지 이해 못하겠네요.. 반대 아닐까요?).
-
Generalization ability
-
추가적인 fine-tuning 없이 3개의 데이터셋에서 SOTA를 달성했다.
-
이는 CRAFT가 특정 데이터셋에 대해 과적합시키는 것보다는, text의 일반적인 특성을 검출하는데 적합하는 것을 의미한다.
5. Conclusion
- 우리가 제안한 CRAFT는 characterlevel annotations없이 individual characters를 잘 검출해낸다.
- CRAFT는 character의 region score와 character의 affinity score를 함께 이용하여, 상향식방법(기존 detection모델들)의 문제였던 다양한 형태의 텍스트를 검출하지 못하는 문제를 해결했다.
- character-level annotations이 제공되는 데이터셋은 드물기 때문에, interim(임시)모델로부터 pseudo-ground truthes(가상의 목표값)을 생성하는 weakly-supervised learning 방법을 제안한다.
- CRAFT는 대부분의 대중적인 SOTA 데이터셋에서 최고 성능을 보여줬고, 이러한 성능은 fine-tuning없이 이루어졌기 때문에 일반화능력을 입증했다.
- 향후 연구에서, recognition을 훈련하여 end-to-end 양식(fashion)을 구축해, CRAFT의 성능(performance), 견고성(robustness), 일반화능력(generalizability)을 a better scene text spotting system으로 전환시켜 더 일반적인 환경에서 적용하고자한다.
