주요 개념
1. 강화학습의 개념
: "어떤 환경에서 어떤 행동을 했을 때 그것이 잘된 행동인지 잘못된 행동인지를 판단하고 보상/벌칙을 주는 과정을 반복해서 스스로 학습하게 하는 분야"
-
환경: 에이전트가 관측할 수 있는 정보
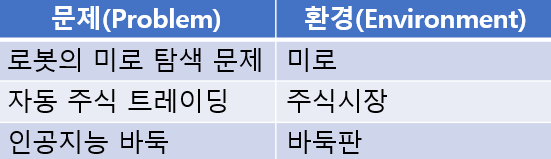
-
에이전트: 환경에서의 행동주체. 에이전트는 환경에 대해 여러가지 행동을 반복하면서 최적의 행동을 학습
2. 강화학습의 목표
: 환경과 상호작용하는 에이전트를 학습시키는 것. 에이전트는 상태(State)라고하는 다양한 상황 안에서 행동(Action)을 취하며, 학습을 진행한다. 에이전트의 행동에 대한 응답으로 보상(Reward)를 돌려받는다.
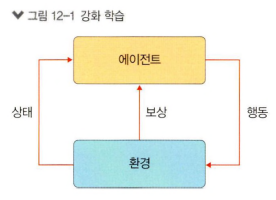
-
상태(State): 에이전트가 가질 수 있는 모든 상태의 집합(S). 개별 요소(s)는 에이전트가 위치하거나 위치할 수 있는 상태를 의미
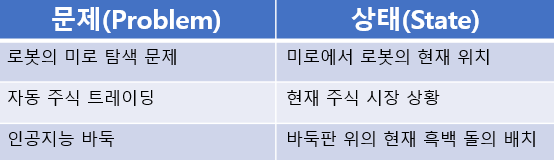
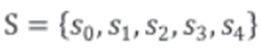
-
행동(Action): 에이전트가 위치하고 있는 상태(St)에서 가능한 행동의 집합(A). 개별 요소는 특정 시점에서 특정 행동(a)을 하는 것을 의미
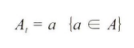
(시간): 상태나 행동에 대한 시점정보. 현재상태를 나타낼 때 St로 표현, 현재시점에서 가능한 행동을 At로 표현
마르코프 결정과정
0. 마르코프 성질
: 미래상태는 현재상태로만 결정되며, 현재상태까지의 과정(과거상태)은 고려할 필요가 없다. 정확하게는 과거와 현재상태를 모두 고려했을 때와, 현재상태만 고려했을때에 대해 '미래 상태가 나타날 확률'이 동일하다는 의미.

(아래는 자체적으로 정리한 내용. 명시된 내용은 아님.)
(필요X이지, 영향X가 아니다) ('영향'이 '필요'보다 더 큰 개념이라고 생각. 예를 들어 체스판에서 상대가 수를 둔 상태에서, 나는 상대가 s-1, s-2번 상황에서 무엇을 놨는지와 관계없이 지금 놓인상태에서 최적의 수를 찾아야하는 것이지, s-1,s-2번째 수의 영향을 받지않는 것이 아님.)
(영향O여도 필요X 상태로 만들면 마르코프 상태로 만들 수 있다. 즉, 과거 정보를 알아야한다면(필요O) 마르코프하지않지만, 같은 상황이여도 과거 정보를 아는 상태(필요X)로 만들어주면 마르코프상태가 될 수 있음)
-마르코프O 예시 체스게임
: 과거의 행동정보 필요X. 이미 놓인 판으로 내가 모든 알기 때문에 현재 상황에서의 최선의 수 탐색가능 (알기 때문에 필요X)

-마르코프X 예시 사진만으로 된 운전자의 상황
: 과거의 행동 정보 필요O. 속도, 방향과 같은 추가 벡터 정보없이는(혹은 1~2초 전 사진), 운전자가 엑셀을 밝아야할지, 브레이크를 밝아야할지 판단할 수 없음. (운전자는 과거 행동의 영향을 받지만(항상 영향O), 필요O 상황이라면 마르코프하지않고, 필요X 상황이면 마르코프하다(영향과 필요의 개념 분리).

= (필요X라는 말은, 이미 알기때문에 필요가 없다는 의미로도 볼 수 있다. 즉, 과거 정보가 없는 상황(필요O) -> 아는 상황(필요X)로 만들어주는 것을 통해 환경을 마르코프한 상태로 설계해 강화학습을 진행할 수 있다.)
- 예를들어 내가 샤워를 하고있는 환경에서 '샴프'가 없다. 현재환경에서는 샴프가 필요한 상황이지만, 샴프가 있는 샤워환경이라면? 샴프가 더이상 필요하지 않다. 이처럼 정보가 없는 상황(필요O. 마르코프X. 샴프없음)에서 정보가 있는(필요X. 마르코프O. 샴프제공)상황으로 만들어준다면, 마르코프하지 않은 상황도 마르코프하게 만들 수 있으므로, 1차원적으로 '운전상황은 마르코프하지않음!, 체스는 마르코프한 상황!'과 같이 생각하는 것은 옳지않다(체스도 판의 일부가 가려져 있으면 마르코프하지않아질 수 있음).
1. MP(Markov Process)
: 미리 정의된 어떤 확률 분포를 따라서 상태와 상태 사이를 이동(전이)하는 프로세스(확률, 상태)
- 구성요소: S(상태의 집합),P(전이확률행렬)
- 전이(transition): 시간에 따른 상태 변화(이동). 마르코프 프로세스에서는 상태간 이동을 확률로 표현하는데, 이를 상태전이 확률이라고 하며, 현재상태에서 다음상태가 될 상태전이확률을 다음과 같이 표현할 수 있다.
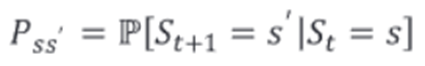
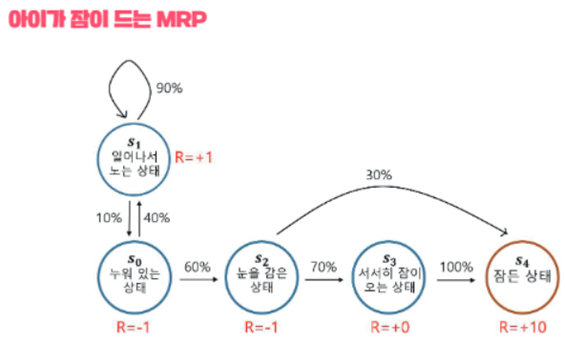
-예시
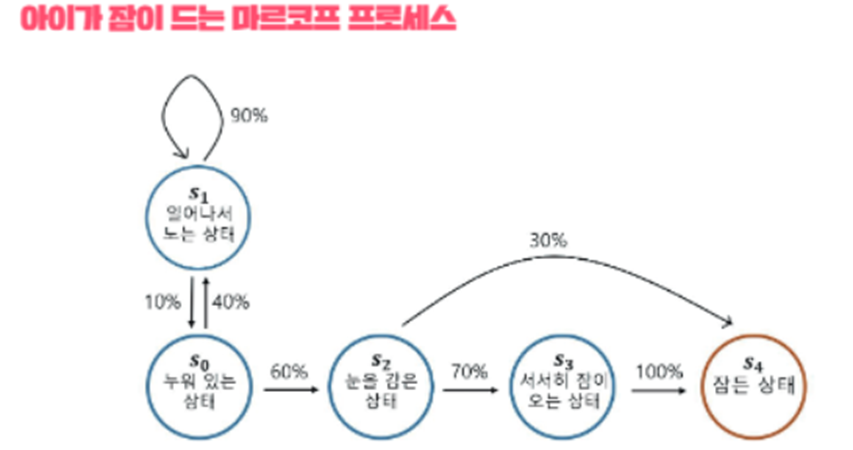
-아이가 취할 수 있는 상태(state)는 5가지(S0~S4)
-1분마다 상태에서부터 다음 상태로 상태전이(state transition)되는 것으로 가정
-최초의 상태는 S0(누워있는 상태)
-S0에서 S1로 갈 확률은 40%, S2로 갈 확률은 60% (확률의 합은 항상 1)
-S4에 도달하는 순간 마르코프 프로세스는 끝
2. MRP
: Markov Process에서 Reward개념이 추가된 프로세스. 즉, 각 상태마다 '좋고 나쁜 정도'가 추가된 확률모델
- 구성요소: S(상태의 집합),P(전이확률행렬),R(보상),γ(감쇠인자)
- 보상(Reward): 현재상태(St)가 특정상태(S)가 됐을 때 얻는 보상(Rt)의 기대값. 즉, 현재상태로의 전이 결과에 대한 좋고 나쁜 정보.

- 감쇠인자(γ): 0~1사이의 값으로, 미래에 얻는 보상에 비해 당장 얻는 보상을 얼마나 중요하게 여길지 여부. 미래에 얻을 보상의 값(R)에 γ를 곱하면서 그 값을 작게 만드는 역할(상태의 정확한 가치를 구하기 위해서는, 어느 시점에 보상을 받을지가 중요). 감쇠인자가 없다면, 시간적 요소를 고려하지 않기때문에 근시안적인 행동만 하게될 것.
- 보상의 합(Return, G): (감쇠인자가 적용된) 보상(Reward)의 합.
G로 표기한다.
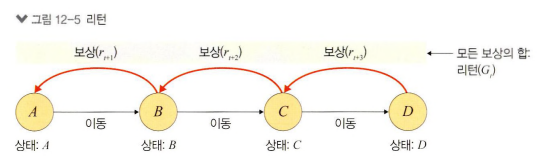
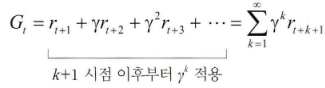 -> 강화학습의 목표는 바로 이 ‘Gt(보상의 합)‘을 최대화 하는 것.
-> 강화학습의 목표는 바로 이 ‘Gt(보상의 합)‘을 최대화 하는 것.
-가치함수(v): 현재상태가 s일때, 앞으로 발생할 것으로 기대되는(E) 모든 보상의 합. 모든 경우의 수를 계산하기 어려우므로, 샘플 에피소드를 추출해서 평균값을 계산하는 방법 등을 사용

- 예시
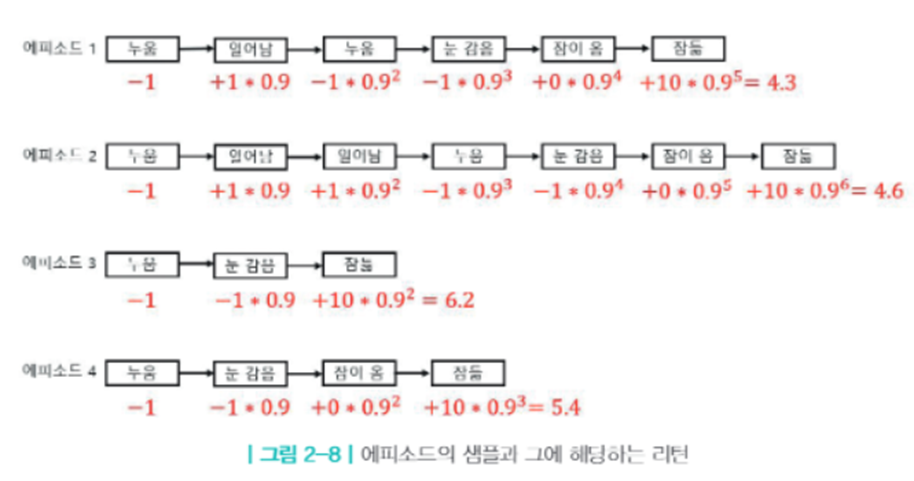
-s0~s4의 Gt는 각각 4.3,4.6,6.2,5.4. 기대값은 모든 경우(샘플로 대체)의 평균이므로, v(s0)은 5.1 (γ는 0.9로 전제)
-Gt가 가장 높은 에피소드3이 가장 이상적인 에피소드
3. MDP
: Markov Reward Process에서 Action개념이 추가된 프로세스. 즉 에이전트의 '의사결정'이 추가된 확률모델
- 구성요소: S(상태의 집합),A(행동의 집합),P(전이확률행렬),R(보상),γ(감쇠인자)
-정책(policy, 𝝅): 각각의 상태마다 행동분포(특정 행동을 할 확률)을 표현하는 함수. 𝝅은 주어진 상태 s에 대한 행동 분포(A)를 표현한 것

- MDP에서는 Action개념이 추가되면서, 기존 MP, MRP에서의 P(전이확률행렬)와 R(보상)의 개념이 변화
(P: S상태에서 S’상태가 될 확률 -> S상태에서 에이전트가 a를 선택(행동)했을 때 S’상태가 될 확률)

(R: 보상도 마찬가지로, 왼쪽 '조건'부분에 At=a가 추가. 즉, 액션(A)을 선택하는 것에 따라 보상이 달라짐)
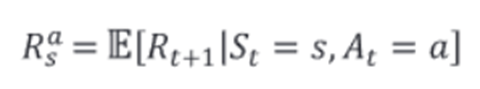
- 예시
(Action): 바람이 부는 징검다리(환경) 첫번째 칸(S0)에서 '제자리에 있는다(a1)'와 '다음칸으로 이동(a2)'이 주어졌을 때, a1을 선택한다면 S0에서 벗어날 수 없고, a2를 선택했을 때만 두번째 칸(S1)으로 가거나 넘어지는(S2)경우의 수(확률)가 발생.(‘바람이 부는’환경은 바꿀 수 없지만, 제자리에 있을지(a0), 다음칸으로 이동할지(a1)를 선택하는 것에 따라,다음상태가 어떤 상태가 되느냐S(s0,s1,s2)의 확률이 달라진다.)
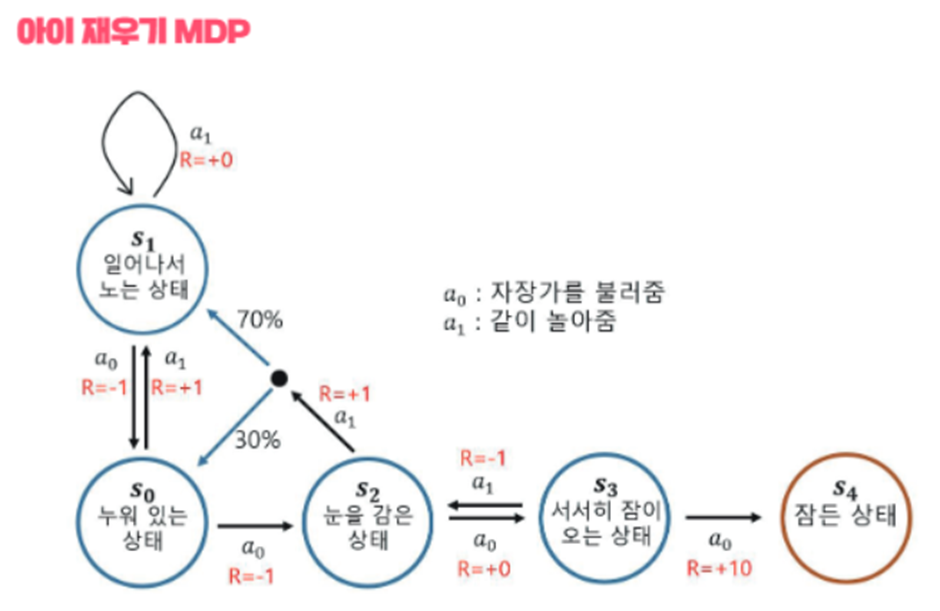
(아이재우기)
-누워있는 상태 (S0)에서, 자장가를 불러 줄 경우(a0)와, 같이 놀아줄 경우(a1)에 따라 S0t+1이 무엇이 될지에 대한 확률이 달라짐.
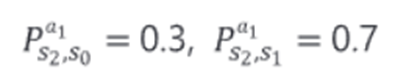
-(S2인 눈을 감은상태에서, Action에 따른 전이 확률 비교) s2에서 a1을 했을 때 s0이 될 확률은 0.3, s1이 될 확률은 0.7
-액션과 관련하여 눈여겨 볼 점은, 눈을 감은 상태(S2)에서, a0, a1를 선택하는 것에 따라 특정 상태로 전이 할 확률뿐만 아니라, 전이 가능한 경우의 수 자체가 달라진다. (이해를 돕기 위한 말일뿐, 엄밀히 말하면 행렬이므로, 경우의 수가 달라진지는 것이 아닌 확률이 0인 항목이 바뀌는 것이긴 하다. 모든 상태로의 변화에 0%의 화살표가 있으며, 0%인 화살표는 생략된 것으로 이해하면 편함(마찬가지로, s0에서 a1을 선택했을 때 S1으로 갈 확률 100%도 생략 -> 전부 생략된 상태))
- γ복습: S0에서 S2로 가는 것(=a1을 선택)은 근시점에서는 -1이라는 음의 보상이지만, S4를 빠르게 도달하기 위해서는 S1보다 좋을 수 있다. 강화학습의 목표는 G를 최대화하는 것이기때문에, 기대값 계산을 통해 G(리턴의 합)이 최대가 되는 정책(policy, 𝝅)을 찾는 것.
정책선택
1. 상태가치함수(v𝝅(s))
: 에이전트가 놓인 상태 가치를 표현한 함수. 상태(s) 에서 얻을 수 있는 리턴(G)의 기대값. 즉각적보상(①)과 잠재적 보상의 합(②)
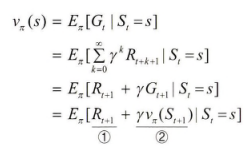
2. 행동가치함수(q𝝅(s,a))
(문제해결방안-DP,몬테카를로,시간차,함수)
: 행동에 대한 가치를 표현한 함수. 상태(s)에서 특정 행동(a)을 취했을 때 얻을 수 있는 리턴(G)의 기대값.
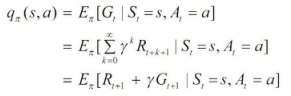
3. 가치함수 계산
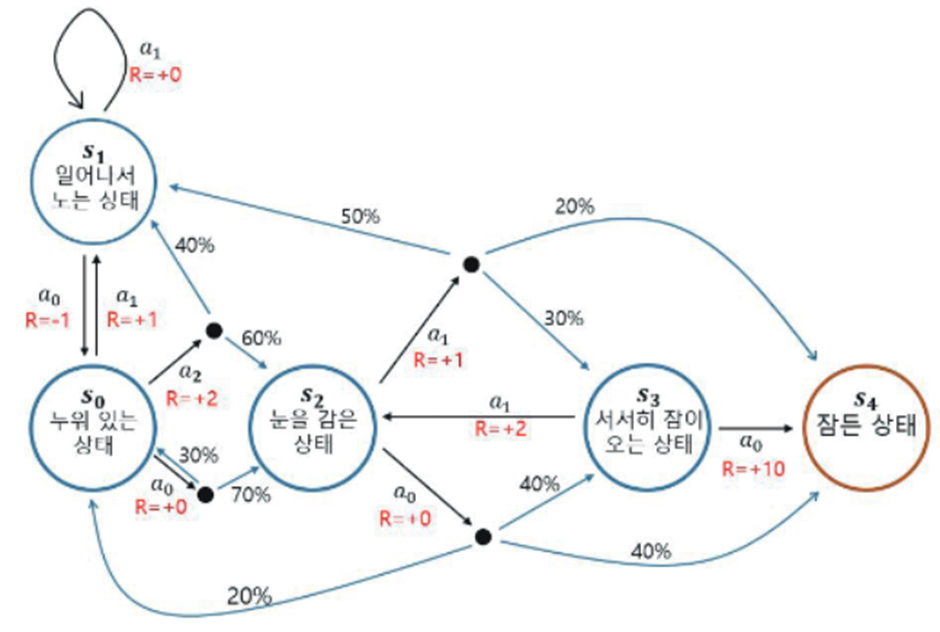
-a2가 추가되어 늘어, A가 2개에서 3개가 되는 것만으로도 에피소드 샘플이 복잡해지고, 가능한 경우의 수가 늘어난다(S가 느는 것도 마찬가지).
-이처럼 가치함수를 계산하는 방법은 O(N^3)의 시간복잡도가 필요하기 때문에, 상태, 액션 수가 많아질수록 복잡해진다. 가치함수를 계산하는 대표적인 방법은 아래 4가지가 있다. (딥러닝의 SGD, 배치, 미니배치와 비슷한 역할로 이해)
- 1) 다이나믹 프로그래밍: 상태와 행동이 많지않고, 모든 상태와 전이확률을 알고 있을 때, 다이나믹 프로그래밍 방식으로 각 상태의 가치와 최적의 행동을 찾을 수 있다. 하지만 대부분의 강화학습문제는 경우의 수가 많으므로 실질적으로 적용이 어려움.
- 2) 몬테카를로: 전체 상태 중 일부 구간만 방문하여 근사적으로 가치를 추정하는 방법. 초기상태에서 시작하여 중간상태들을 경우해서 최종상태까지 간 후 최종보상을 측정하고 방문했던 상태들의 가치를 업데이트.
- 3) 시간 차 학습: 몬테카를로와 다르게, 최종상태에 도달하기 전에 방문한 상태의 가치를 업데이트. DP와 몬테카를로의 중간적 특성.
- 4) 함수적 접근 학습: 연속적인 상태를 학습하고자 상태와 관련된 특성벡터를 도입. 특성의 가중치를 업데이트하여 가치의 근사치를 탐색.
벨만 방정식
: 상태-가치함수와 행동-가치 함수의 관계를 나타내는 방정식
1.벨만기대방정식
: 가치함수(v)는 특정 상태(s)에서의 미래 보상을 포함한 가치를 나타낸다. 이때, 어떤 정책에 따라 행동하는 것이 보상의 합(G)을 높일 수 있을지를 고려한 다음상태로의 이동이 벨만 기대방정식.
-
MDP의 상태가치함수 도출

-현재 시점에서 미래에 기대되는 보상들의 총합
-St+1에 대한 기대값을 더하는 재귀적 형태 -
벨만기대방정식

-
0단계: 다음단계의 Reward(즉각적보상)과, 감쇠인자를 곱한 다음상태의 상태가치함수를 더함. 행동가치함수도 같은 맥락
-
1단계:
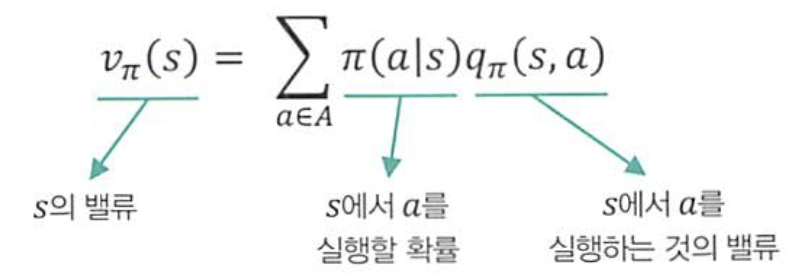 ->현재상태(s)에서
->현재상태(s)에서 어떤 행동을 선택할 확률에, 각 행동(a)에 대한 행동가치함수를 곱한 값의 합
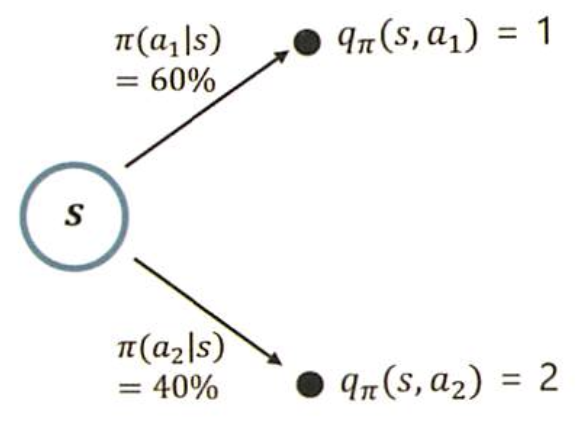
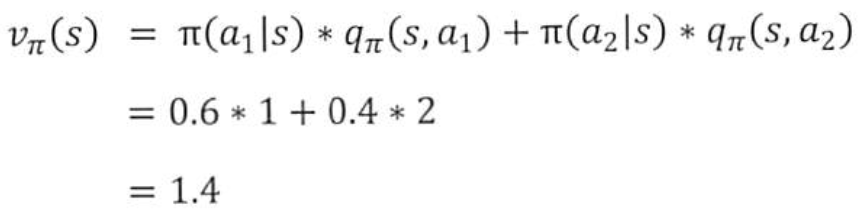 ->a1을 선택할 확률이 0.6, a2를 선택할 확률이 0.4이고, a1에 대한 행동가치함수의 값이 1, a2에 대한 행동가치 함수의 값이 2일때의 '상태가치함수'
->a1을 선택할 확률이 0.6, a2를 선택할 확률이 0.4이고, a1에 대한 행동가치함수의 값이 1, a2에 대한 행동가치 함수의 값이 2일때의 '상태가치함수'
 ->행동가치 함수는 같은 매커니즘에서,
->행동가치 함수는 같은 매커니즘에서, 어떤 행동을 선택할지 확률대신어떤 행동을 했을 때 어떤 상태로 전이될 확률과 상태가치함수를 곱한 값의 합.
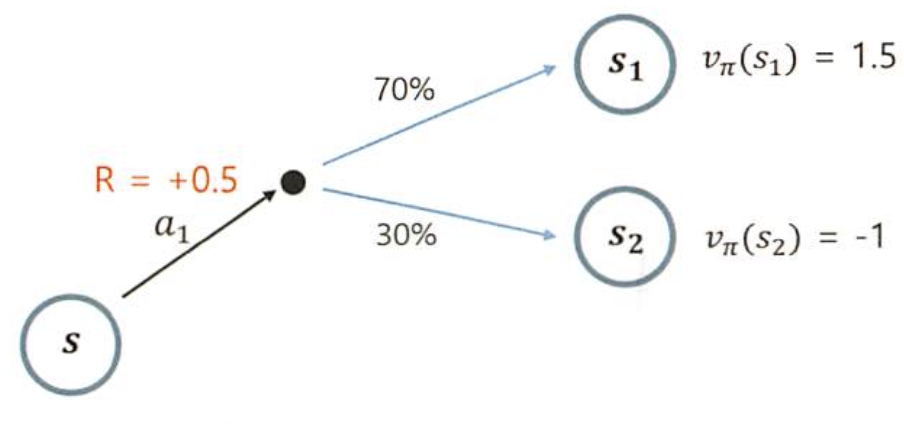
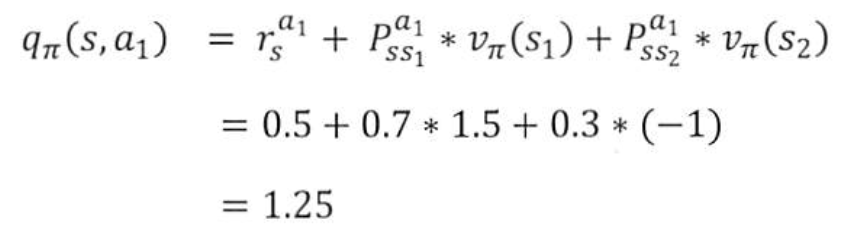 ->a1을 선택했을 때 s에서 s1으로 갈 확률이 0.7, s2로 갈 확률이 0.3이고, s1에 대한 상태가치함수의 값이 1.5, s2에 대한 상태가치함수의 값이 -1일때의 '행동가치함수'
->a1을 선택했을 때 s에서 s1으로 갈 확률이 0.7, s2로 갈 확률이 0.3이고, s1에 대한 상태가치함수의 값이 1.5, s2에 대한 상태가치함수의 값이 -1일때의 '행동가치함수' -
2단계:
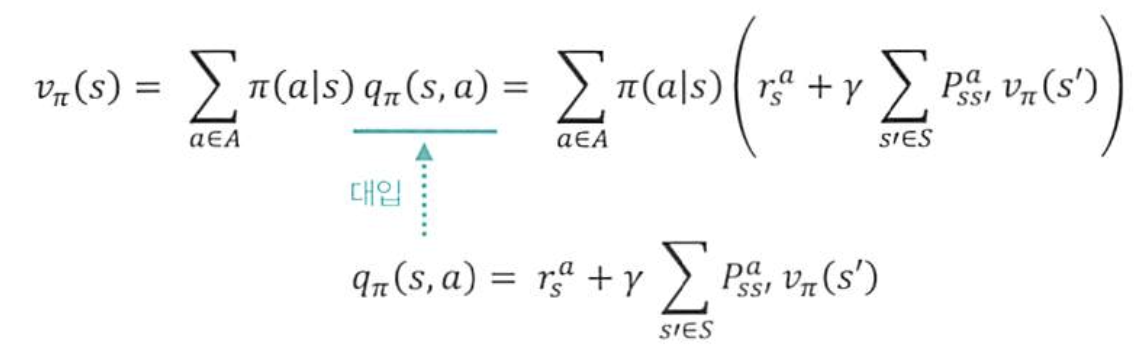 ->상태가치함수: 각 행동에 대한 행동가치함수 값을 대입
->상태가치함수: 각 행동에 대한 행동가치함수 값을 대입
 ->행동가치함수: 다음 상태에 대한 상태가치함수 값을 대입
->행동가치함수: 다음 상태에 대한 상태가치함수 값을 대입
2.벨만최적방정식
: 강화학습에서 추구하고자하는 목표는 최적의 가치함수 값을 찾는 것이 아닌, '최대의 보상을 얻는 정책을 찾는 것'이다. 즉, 최대희 보상을 얻기 위한 정책을 찾기 위해 최적의 가치함수(가치 함수 값이 가장 큰 값)를 찾는 것이다.
- 최적의가치함수
: 최대의 보상을 갖는 가치함수. 상태-가치함수는 어떤 상태가 더 많은 보상을 받을 수 있는지 알려주며, 행동-가치함수는 어떤 상태에서 어떤 행동을 취해야 더 많은 보상을 받을 수 있는지 알려준다. 따라서 모든 상태에 대해 상태-가치함수를 계산할 수 있다면, 모든 상태에 대해 최적의 행동을 선택할 수 있다.
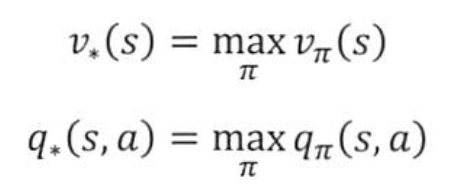 -> 최적의 상태-가치 함수, 최적의 행동-가치 함수
-> 최적의 상태-가치 함수, 최적의 행동-가치 함수
 -> 즉, MDP안에 존재하는 모든 정책함수(𝝅) 중, 가장 좋은 정책함수를 선택하여 계산한 값이 최적의 값이 된다.
-> 즉, MDP안에 존재하는 모든 정책함수(𝝅) 중, 가장 좋은 정책함수를 선택하여 계산한 값이 최적의 값이 된다.
큐러닝, 몬테카를로 트리 탐색에 대한 내용은 실습 내용이므로, 내용 읽으면서 코드 실행해보면 이해하기 어렵지 않으실 겁니다.
