k8s 클러스터를 좀 더 안정적으로 운영하고 디버깅하기 위해서는 모니터링툴과 로깅 아키텍처가 필요하다. 이번 포스팅에서는 EKS의 모니터링과 로깅에 대해서 다뤄보겠다. 스터디에서 제공해 준 yaml파일로 클러스터를 설치했다. EKS 원클릭배포 이번 실습에서는 리소스가 좀 더 많이 소모 되므로 노드 스펙을 t3.xlarge 로 바꿔서 배포했다.
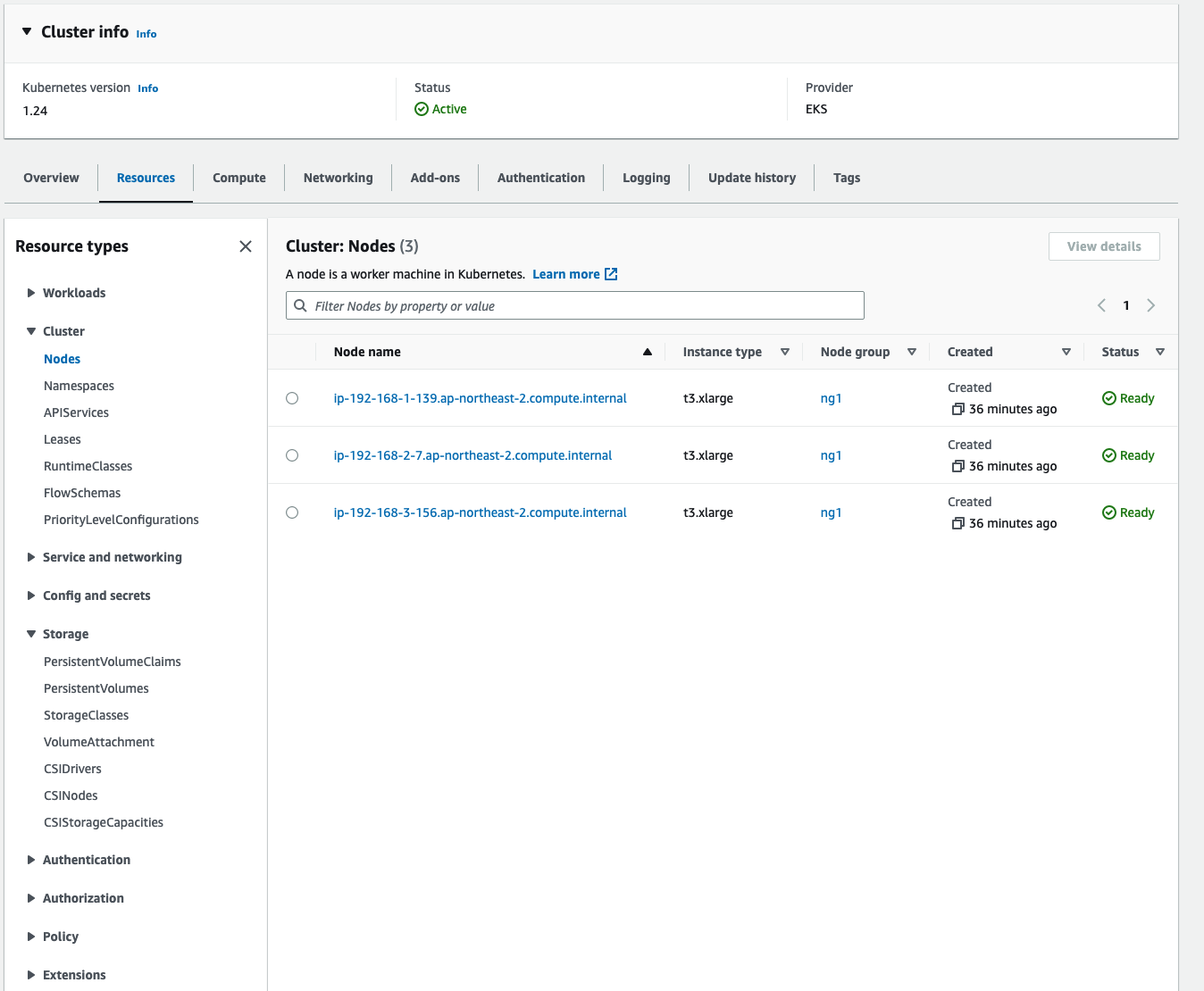
1. EKS Console
기본적으로 EKS Console을 통해서 클러스터의 상태와 Pod, Sevice, Storage, Configmap 등의 리소스 상태 체크가 가능하다. CLI에서 보다 정형화된 UI를 제공하므로, 한 번 들어가서 상태가 어떻게 되어 있는지 보기에 편리하다. 특히 k8s를 접한지 얼마 안되었으면, 이렇게 전체 리소스를 구조화해서 볼 수 있는 장점이 있다.
2. EKS Logging
2-1. Control Plane Logging
실제로 개발 초기에 어플리케이션과 k8s 연동관련해서 체크할 때 control plane을 좀 들여다보고 실제 운영 시에는 크게 신경쓰지는 않았다. managed k8s에서는 CSP에서 관리하는 영역으로, 가이드된 아키텍처를 적용하면 안정성을 보장해 준다. 그럼 이번 실습에서는 시스템에 문제가 생기거나, 디버깅이 필요한 경우를 대비해서 control plane 로그를 활성화 시켜보는 실습을 하겠다.
# 모든 로깅 활성화
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
{
"update": {
"id": "02ff59e2-8b0d-4c93-ae23-de7f0c4894cc",
"status": "InProgress",
"type": "LoggingUpdate",
"params": [
{
"type": "ClusterLogging",
"value": "{\"clusterLogging\":[{\"types\":[\"api\",\"audit\",\"authenticator\",\"controllerManager\",\"scheduler\"],\"enabled\":true}]}"
}
],
"createdAt": "2023-05-19T09:41:11.688000+09:00",
"errors": []
}
}
# 로그 그룹 확인
aws logs describe-log-groups | jq
{
"logGroups": [
{
"logGroupName": "/aws/eks/myeks/cluster",
"creationTime": 1684456902887,
"metricFilterCount": 0,
"arn": "arn:aws:logs:ap-northeast-2:033359017116:log-group:/aws/eks/myeks/cluster:*",
"storedBytes": 0
},
{
"logGroupName": "/aws/macie/classificationjobs",
"creationTime": 1664509571963,
"metricFilterCount": 0,
"arn": "arn:aws:logs:ap-northeast-2:033359017116:log-group:/aws/macie/classificationjobs:*",
"storedBytes": 822
}
]
}
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>AWS Cloudwatch에 k8s control plane 관련 log group이 생성되고, 해당 디렉토리에 위에서 활성화 시킨 로그들이 저장된다.
Cloudwatch의 Log Insight 탭에서 쿼리로 원하는 로그를 뽑아서 확인도 할 수 있다.
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc
추가로, k8s API에서는 Prometheus와 연동하여 모니터링과 분석에 유용한 metric 정보를 제공하는데, 아래와 같이 etcd정보도 호출해서 확인해볼 수 도 있다.
(kimchigood@myeks:default) [root@myeks-bastion-EC2 ~]# kubectl get --raw /metrics | grep "etcd_db_total_size_in_bytes"
# HELP etcd_db_total_size_in_bytes [ALPHA] Total size of the etcd database file physically allocated in bytes.
# TYPE etcd_db_total_size_in_bytes gauge
etcd_db_total_size_in_bytes{endpoint="http://10.0.160.16:2379"} 5.439488e+06
etcd_db_total_size_in_bytes{endpoint="http://10.0.32.16:2379"} 5.44768e+06
etcd_db_total_size_in_bytes{endpoint="http://10.0.96.16:2379"} 5.44768e+06
2-2. Pod Logging
CLI상에서 Pod 로그는 kubectl logs 명령을 사용하여 확인을 한다. Nginx Pod를 배포한 후, Pod의 로그가 어디에 저장되고, 어떻게 kubectl logs로 확인이 가능한지 알아보자.
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
path: /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh
# 배포
helm install nginx bitnami/nginx --version 14.1.0 -f nginx-values.yaml
# 확인
kubectl get ingress,deploy,svc,ep nginx
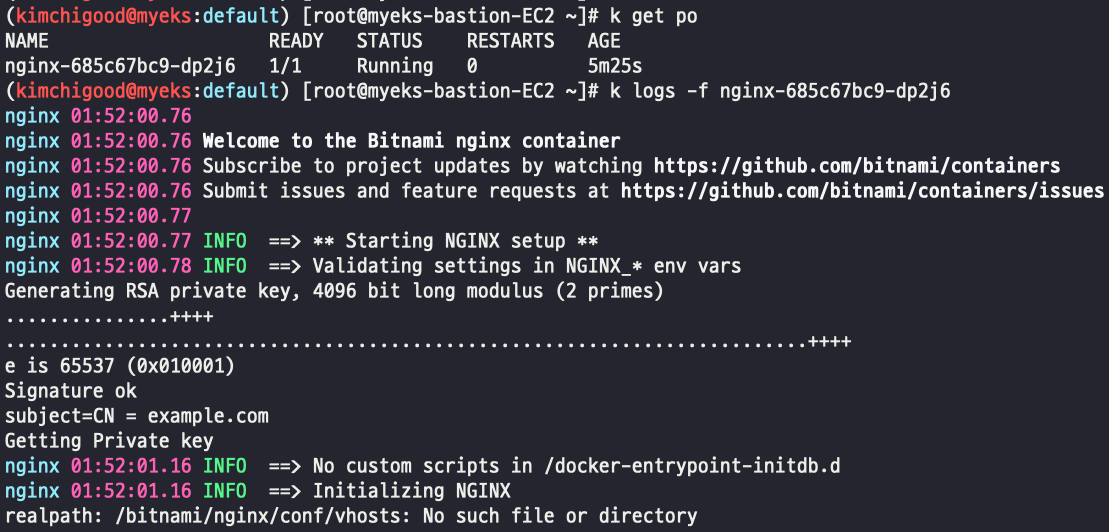
kubectl get targetgroupbindings # ALB TG 확인kubectl logs를 통해서 로그를 확인해보자. 간단한 명령으로 구동중인 Nginx의 로그들이 잘 찍히고 있다. 뭔가 해준게 없는데 왜 로그가 찍히는 걸까?
UNIX and Linux commands typically open three I/O streams when they run, called STDIN, STDOUT, and STDERR. By default, docker logs shows the command’s STDOUT and STDERR.
The official nginx image creates a symbolic link from /var/log/nginx/access.log to /dev/stdout, and creates another symbolic link from /var/log/nginx/error.log to /dev/stderr, overwriting the log files and causing logs to be sent to the relevant special device instead. See the Dockerfile.
Docker log에 따르면, logs 명령을 통해 STDOUT과 STDERR을 보여주며, 공식 nginx 이미지는 nginx log가 저장되는 경로에 /dev/stdout 과 /dev/stderr 로 심볼릭 링크를 만들어 줬다라고 되어있다.
도커파일 빌드 과정에서 이런 작업들을 해줬기 때문에 편하게 logs 명령을 통해 확인이 가능한 것이다.
# forward request and error logs to docker log collector
RUN ln -sf /dev/stdout /var/log/nginx/access.log \
&& ln -sf /dev/stderr /var/log/nginx/error.log참고로, k8s에서 기본적으로 저장되는 로그의 크기는 10Mi(메비바이트)이다. containerLogMaxSize. kubelet 설정을 통해서 바꿀 수 있는데, AKS 운영 중에 생각보다 로그가 많이 남아서 확인해보니 AKS는 50Mi이다. AKS에서는 kubelet 세팅 작업 후 새로운 노드풀에 kubelet을 적용하는 방식으로 셋업이 필요하다.
그럼 이 로그들은 실제로 어디에 저장되는 것일까?
먼저 pod를 describe 해서 어떤 노드에 떠있는 지 확인 한 후 해당 노드에 접속해보자. 경로를 /var/log/container로 옮기면 노드에 떠있는 Pod들의 로그 파일들이 저장되어 있다. nginx 로그 파일을 확인해 보면, 우리가 kubectl logs로 확인했던 놈과 같은걸 알 수 있다.
[ec2-user@ip-192-168-2-7 containers]$ pwd
/var/log/containers
[ec2-user@ip-192-168-2-7 containers]$ ls
aws-load-balancer-controller-6fb4f86d9d-nrk58_kube-system_aws-load-balancer-controller-c8dc69a5204abd466b8e3e4f07213cd38bd51e61cb5ca682cd43bbc55e374861.log
aws-node-6bvst_kube-system_aws-node-4f12ad5b2146098b4cc93f41bb2103ababd559ca773951a0c3e167885745ca48.log
aws-node-6bvst_kube-system_aws-vpc-cni-init-93ca381638e45ba475aebf8af312a214274b76b79548611966c1613facb871b1.log
coredns-6777fcd775-qdhqm_kube-system_coredns-794662e9c5d90cbac24294d6f5cb7ec7cda3d459b9e201ded7a1f97cce7710df.log
ebs-csi-node-vm9cw_kube-system_ebs-plugin-6957ff516c463ac22228cec67463ddf4e9cbe9139e5693fcd05c6c0fb79f8173.log
ebs-csi-node-vm9cw_kube-system_liveness-probe-a615b68f26a399cc3d500e3b164632323d155259a15d68bae18082f6cf49e97c.log
ebs-csi-node-vm9cw_kube-system_node-driver-registrar-9ad7f61cb18ba9d61a7839a1e759b648e178a2945e2eb4c50fad946d15882e0e.log
efs-csi-node-q9br7_kube-system_csi-driver-registrar-2c20a548d773eaf0e2b94dcaf4ecdcf090cd266568c8cec468e00ec8298ce277.log
efs-csi-node-q9br7_kube-system_efs-plugin-c40bd50bdfa940ec3cf382668dc34483162f7757f9a0bc123d9c1518744cb4b2.log
efs-csi-node-q9br7_kube-system_liveness-probe-439e14930731d9ce284a9c99a5f599d3f6ecda1a9b65397da5ac30c75b15a51e.log
kube-proxy-8d6vf_kube-system_kube-proxy-9540d7f347c9e6bdbca94342f3414bd03a41650d73446b152d35988e15456bd0.log
nginx-685c67bc9-dp2j6_default_nginx-c14d03cd7af97c414dff832f1b5da0b6a090de92bd6d983a31954db1905873de.log
[ec2-user@ip-192-168-2-7 containers]$ sudo cat nginx-685c67bc9-dp2j6_default_nginx-c14d03cd7af97c414dff832f1b5da0b6a090de92bd6d983a31954db1905873de.log
2023-05-19T01:52:00.766776383Z stderr F nginx 01:52:00.76
2023-05-19T01:52:00.767990056Z stderr F nginx 01:52:00.76 Welcome to the Bitnami nginx container
2023-05-19T01:52:00.7691305Z stderr F nginx 01:52:00.76 Subscribe to project updates by watching https://github.com/bitnami/containers
2023-05-19T01:52:00.770233255Z stderr F nginx 01:52:00.76 Submit issues and feature requests at https://github.com/bitnami/containers/issues
2023-05-19T01:52:00.771465554Z stderr F nginx 01:52:00.77
2023-05-19T01:52:00.772689007Z stderr F nginx 01:52:00.77 INFO ==> ** Starting NGINX setup **
2023-05-19T01:52:00.784173269Z stderr F nginx 01:52:00.78 INFO ==> Validating settings in NGINX_* env vars
2023-05-19T01:52:00.794169337Z stderr F Generating RSA private key, 4096 bit long modulus (2 primes)한가지 주의할 점은 Pod가 사라지면 노드도 같이 없어지는 것이다. 따라서 중요한 로그는 따로 로깅 아키텍처를 구성해서 저장하도록 하자.
2-3. Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
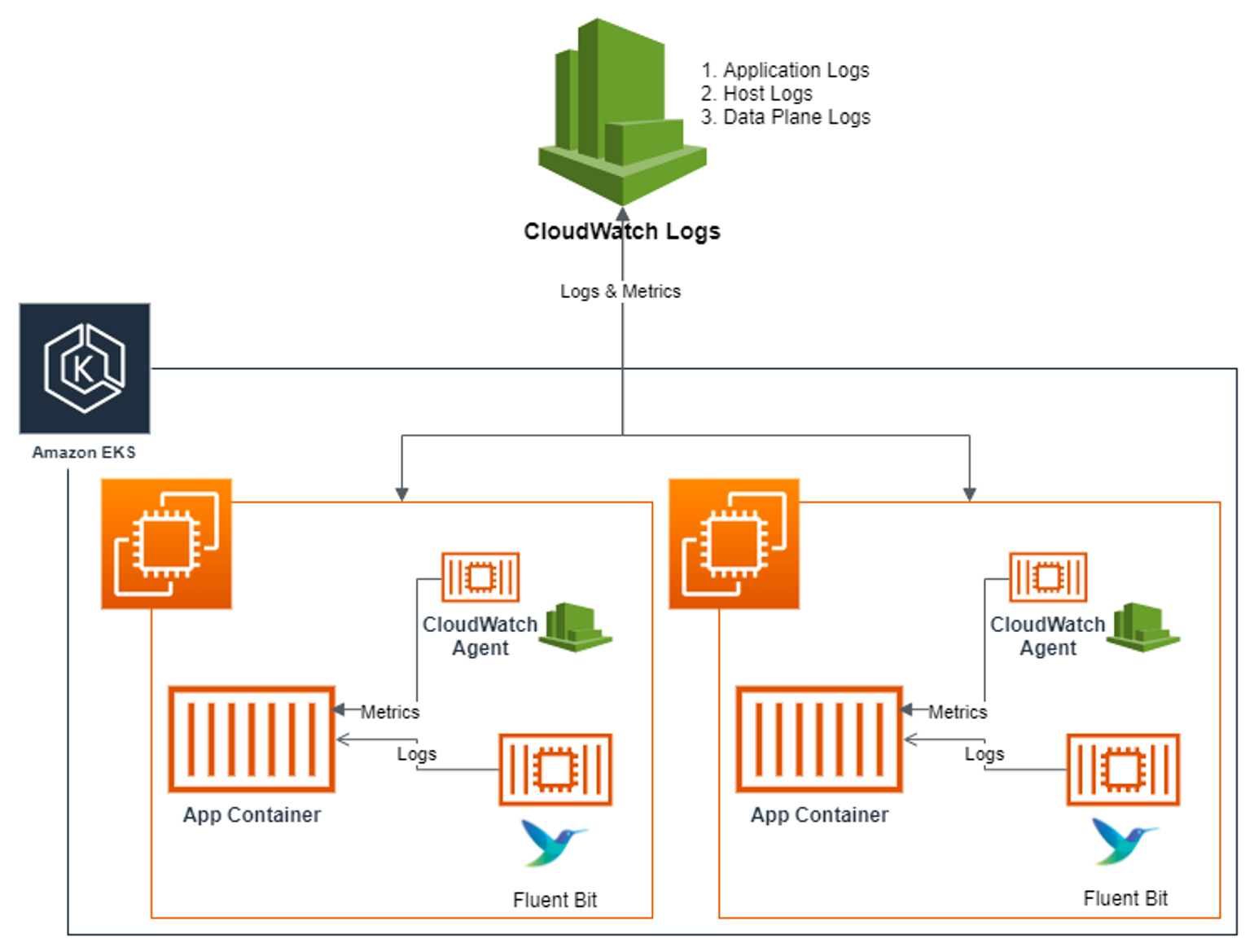
Cloudwatch agent와 로그를 수집하는 오픈소스인 Fluent Bit가 Daemonset 형태로 모든 노드에 배포가 된 후 수집된 로그를 Cloudwatch로 보내는 기능으로 시각화, 로그저장/로테이션 등의 기능을 제공하는 AWS만의 기능이다.
수집되는 로그의 종류는 아래와 같다.
- /aws/containerinsights/
Cluster_Name/application : 로그 소스(All log files in/var/log/containers), 각 컨테이너/파드 로그- /aws/containerinsights/
Cluster_Name/host : 로그 소스(Logs from/var/log/dmesg,/var/log/secure, and/var/log/messages), 노드(호스트) 로그- /aws/containerinsights/
Cluster_Name/dataplane : 로그 소스(/var/log/journalforkubelet.service,kubeproxy.service, anddocker.service), 쿠버네티스 데이터플레인 로그
그럼 바로 실습을 진행해보자.
# 설치
FluentBitHttpServer='On'
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
FluentBitReadFromTail='On'
curl -s https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f -
# 설치 확인
kubectl get-all -n amazon-cloudwatch
kubectl get ds,pod,cm,sa -n amazon-cloudwatch
kubectl describe clusterrole cloudwatch-agent-role fluent-bit-role # 클러스터롤 확인
kubectl describe clusterrolebindings cloudwatch-agent-role-binding fluent-bit-role-binding # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l name=cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ss -tnlp | grep fluent-bit; echo; done
# cloudwatch-agent 설정 확인
kubectl describe cm cwagentconfig -n amazon-cloudwatch
{
"agent": {
"region": "ap-northeast-2"
},
"logs": {
"metrics_collected": {
"kubernetes": {
"cluster_name": "myeks",
"metrics_collection_interval": 60
}
},
"force_flush_interval": 5
}
}
# CW 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자! >> / 호스트 패스 공유??? 보안상 안전한가? 좀 더 범위를 좁힐수는 없을까요?
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent
...
ssh ec2-user@$N1 sudo tree /dev/disk
...
# Fluent Bit Cluster Info 확인
kubectl get cm -n amazon-cloudwatch fluent-bit-cluster-info -o yaml | yh
apiVersion: v1
data:
cluster.name: myeks
http.port: "2020"
http.server: "On"
logs.region: ap-northeast-2
read.head: "Off"
read.tail: "On"
kind: ConfigMap
...
# Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인 - 링크
## 설정 부분 구성 : application-log.conf , dataplane-log.conf , fluent-bit.conf , host-log.conf , parsers.conf
kubectl describe cm fluent-bit-config -n amazon-cloudwatch위 세팅을 따르면 Fluent bit는 2020 포트가 할당되어 구동된다. 클러스터롤/롤바인딩을 통해 권한을 주고, amazon-cloudwatch 네임스페이스에 리소스들이 설치가 된다.
(kimchigood@myeks:default) [root@myeks-bastion-EC2 ~]# for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ss -tnlp | grep fluent-bit; echo; done
>>>>> 192.168.1.139 <<<<<
LISTEN 0 128 0.0.0.0:2020 0.0.0.0:* users:(("fluent-bit",pid=31576,fd=200))
>>>>> 192.168.2.7 <<<<<
LISTEN 0 128 0.0.0.0:2020 0.0.0.0:* users:(("fluent-bit",pid=30377,fd=191))
>>>>> 192.168.3.156 <<<<<
LISTEN 0 128 0.0.0.0:2020 0.0.0.0:* users:(("fluent-bit",pid=30474,fd=199))Cloudwatch의 Insight 메뉴에서 다양한 모니터링 기능을 활용해보자.
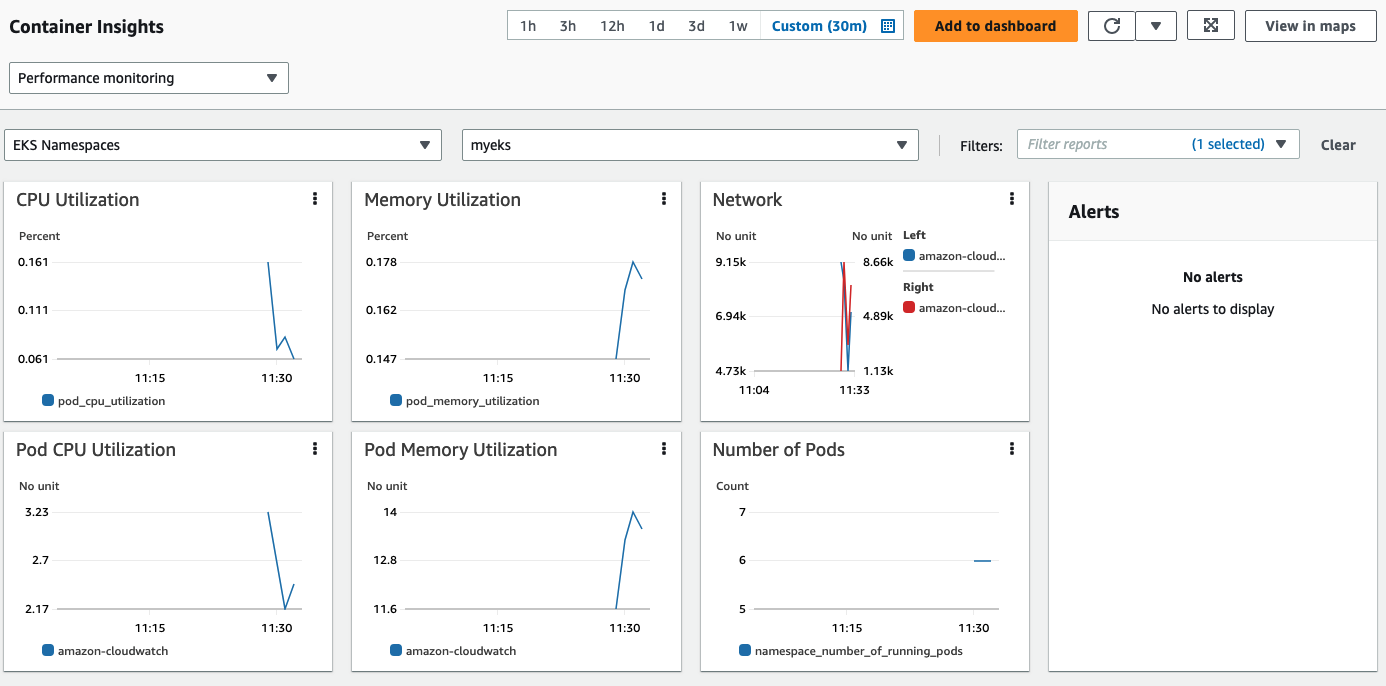
3. Metric과 Alert
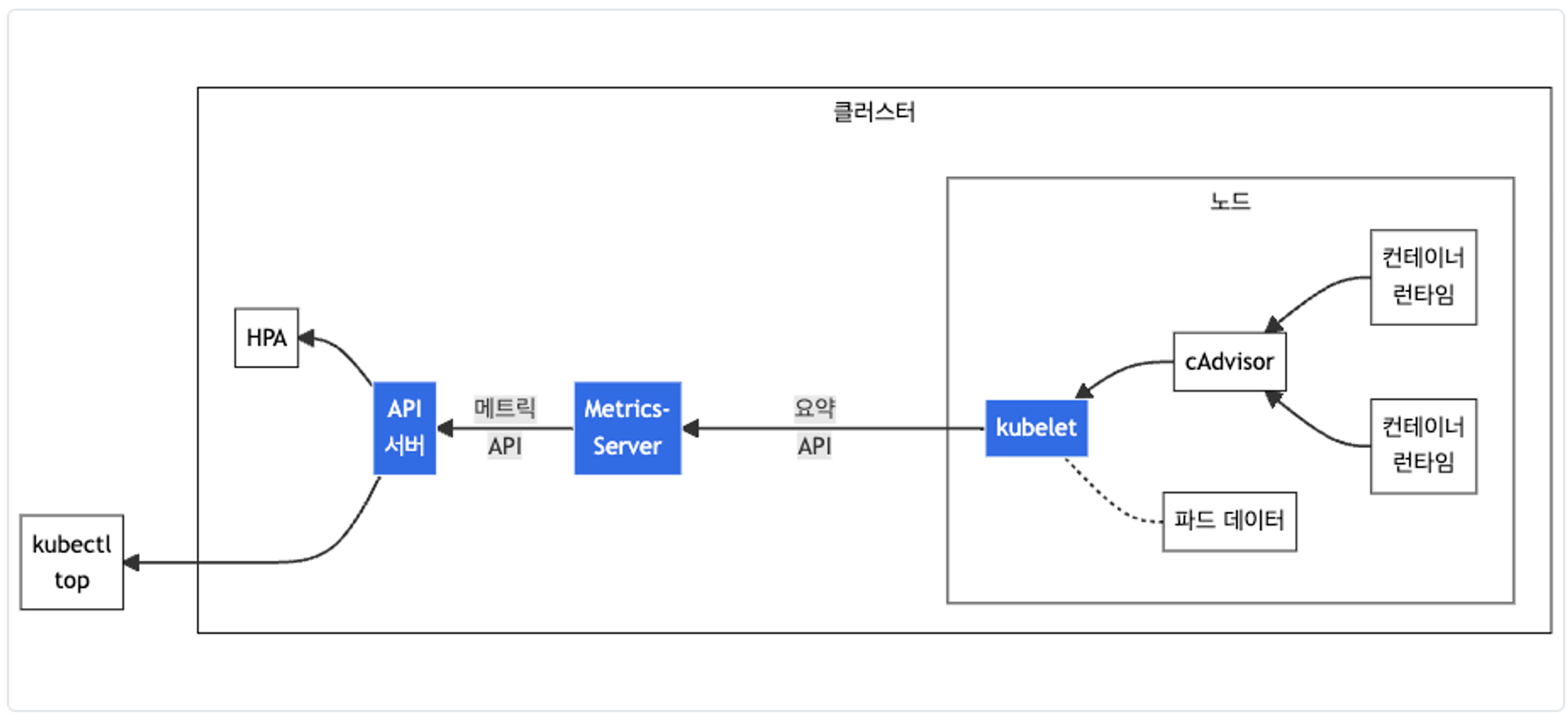
3-1. Metric
k8s에서는 metrics 정보를 addon으로 제공해준다. EKS에서는 따로 설치를 하면 metrics 정보 조회가 가능하다. AKS에서는 기본으로 들어가 있는 기능인데, 이렇게 addon으로 설치를 해보니 생소하긴 하다. metric
# 배포
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'3-2. Botkube
Botkube를 이용해서 slack에서 k8s 리소스나 상태를 조회하고, Alert을 받는 기능을 구현해보자. 실습을 하기위해서는 slack의 API Token이 필요하다.
# repo 추가
helm repo add botkube https://charts.botkube.io
helm repo update
# 변수 지정
export ALLOW_KUBECTL=true
export ALLOW_HELM=true
export SLACK_CHANNEL_NAME=webhook3
#
cat <<EOT > botkube-values.yaml
actions:
'describe-created-resource': # kubectl describe
enabled: true
'show-logs-on-error': # kubectl logs
enabled: true
executors:
k8s-default-tools:
botkube/helm:
enabled: true
botkube/kubectl:
enabled: true
EOT
# 설치
helm install --version v1.0.0 botkube --namespace botkube --create-namespace \
--set communications.default-group.socketSlack.enabled=true \
--set communications.default-group.socketSlack.channels.default.name=${SLACK_CHANNEL_NAME} \
--set communications.default-group.socketSlack.appToken=${SLACK_API_APP_TOKEN} \
--set communications.default-group.socketSlack.botToken=${SLACK_API_BOT_TOKEN} \
--set settings.clusterName=${CLUSTER_NAME} \
--set 'executors.k8s-default-tools.botkube/kubectl.enabled'=${ALLOW_KUBECTL} \
--set 'executors.k8s-default-tools.botkube/helm.enabled'=${ALLOW_HELM} \
-f botkube-values.yaml botkube/botkube
# 참고 : 삭제 시
helm uninstall botkube --namespace botkube간단하게 helm 설치로 slack과 연동이 되었고, k8s 클러스터 상태나 리소스 조회가 가능하다. 이제 이미지가 잘못된 Pod를 배포해서 경고를 받아보자.
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml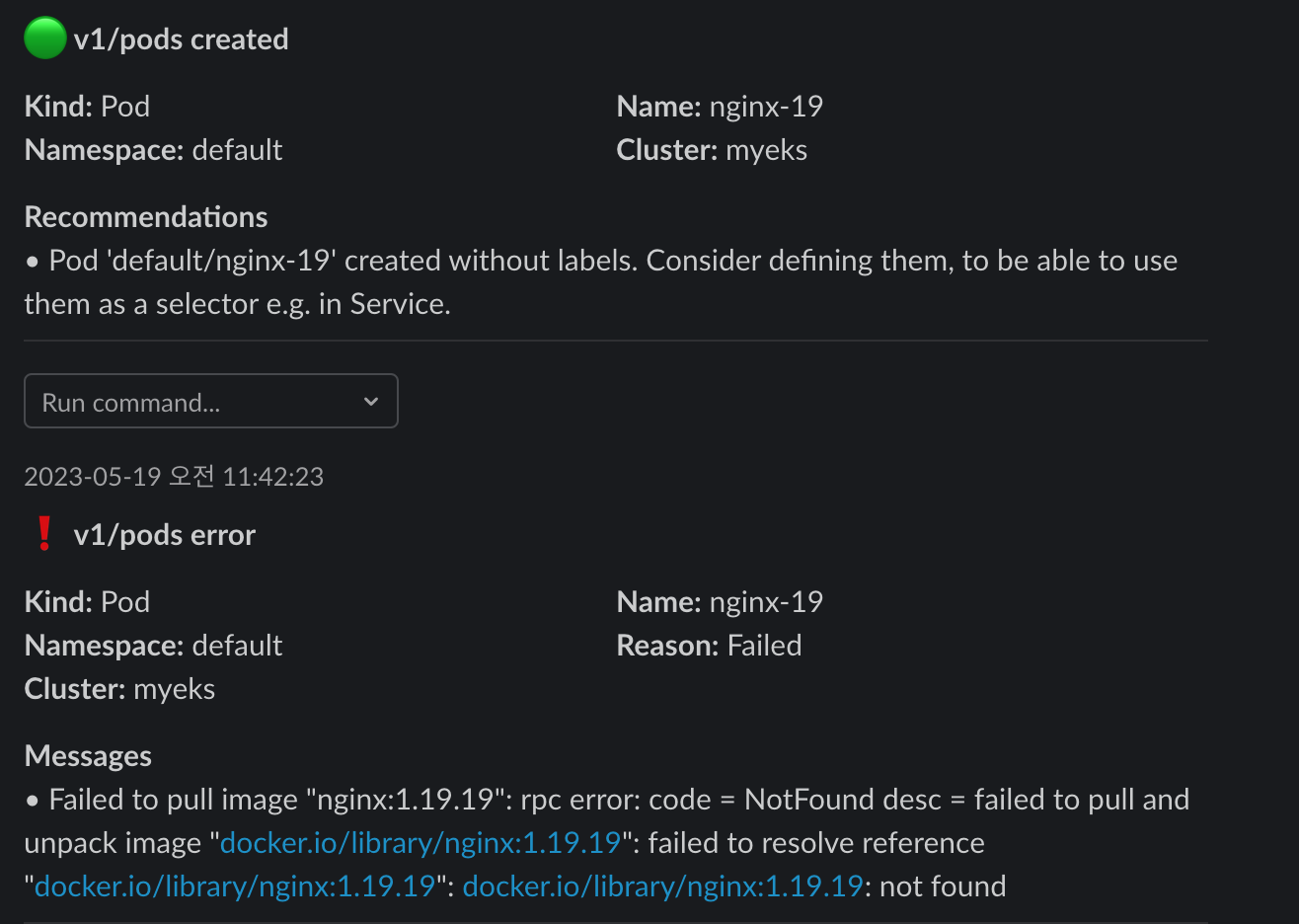
Pod가 설치되자마다 바로 날아온다. 이런 에러보다는 Pod가 restart 되었거나 PV의 용량이 꽉찼거나 할 때 Alert이 오면 매우 유용할 것 같다.
4. Prometheus Operator
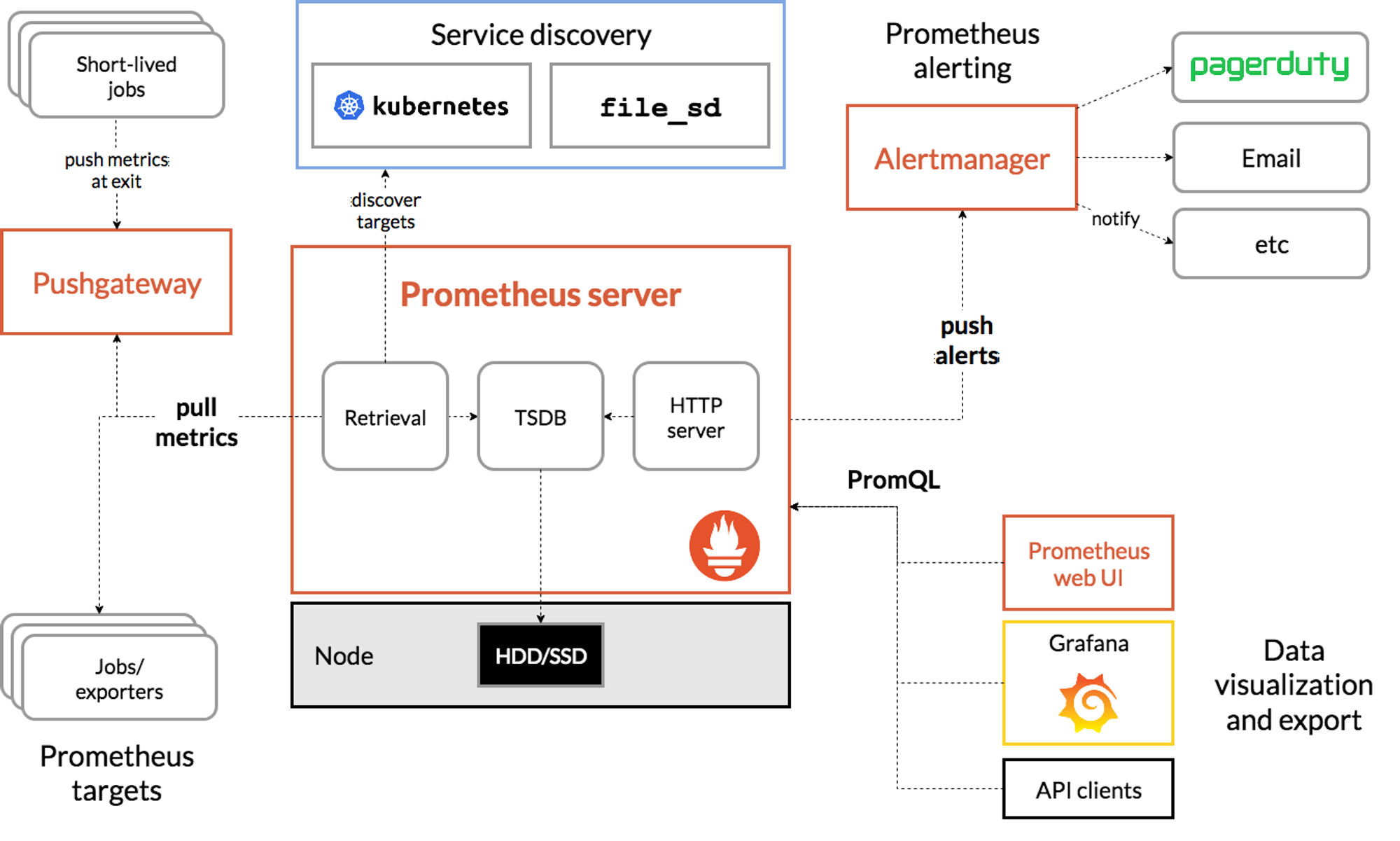
k8s를 운영하면 가장 먼저 떠오르는 모니터링 툴이 Prometheus와 Grafna이다. 아래 그림처럼 Prometheus를 통해 로그를 수집하고 시각화는 Grafana로 해주게 된다. helm chart로 쉽게 설치가 되는데, 사실 잘들여다보면 엄청 복잡하게 되어 있긴하다.
현업에서 k8s를 껏다 켰다 해야하는 이슈가 있는데 가끔 prometheus 데이터가 꼬일 때가 있다.
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo $CERT_ARN
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
# alertmanager:
# ingress:
# enabled: true
# ingressClassName: alb
# hosts:
# - alertmanager.$MyDomain
# paths:
# - /*
# annotations:
# alb.ingress.kubernetes.io/scheme: internet-facing
# alb.ingress.kubernetes.io/target-type: ip
# alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
# alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
# alb.ingress.kubernetes.io/success-codes: 200-399
# alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
# alb.ingress.kubernetes.io/group.name: study
# alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.27.2 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring설치한 후 prometheus에 접근하면, 어떤 정보들을 수집하고 있는 지 볼 수 있다. prometheus는 pull 방식으로 데이터를 가져오는데, 따로 세팅을 안하고 그냥 설치를 해주, controller plane 정보까지 모두 수집하는데, 꼭 필요한 정보만 가져오도록 세팅하는게 중요하다. 데이터 조회는 Prometheus 쿼리인 PromQL을 사용하게 된다.
이렇게 수집된 데이터를 좀 더 보기 편하게 시각화 해주는 것이 Grafana 이다. helm 차트를 설치할 때 prometheus와 같이 설치가 된다.
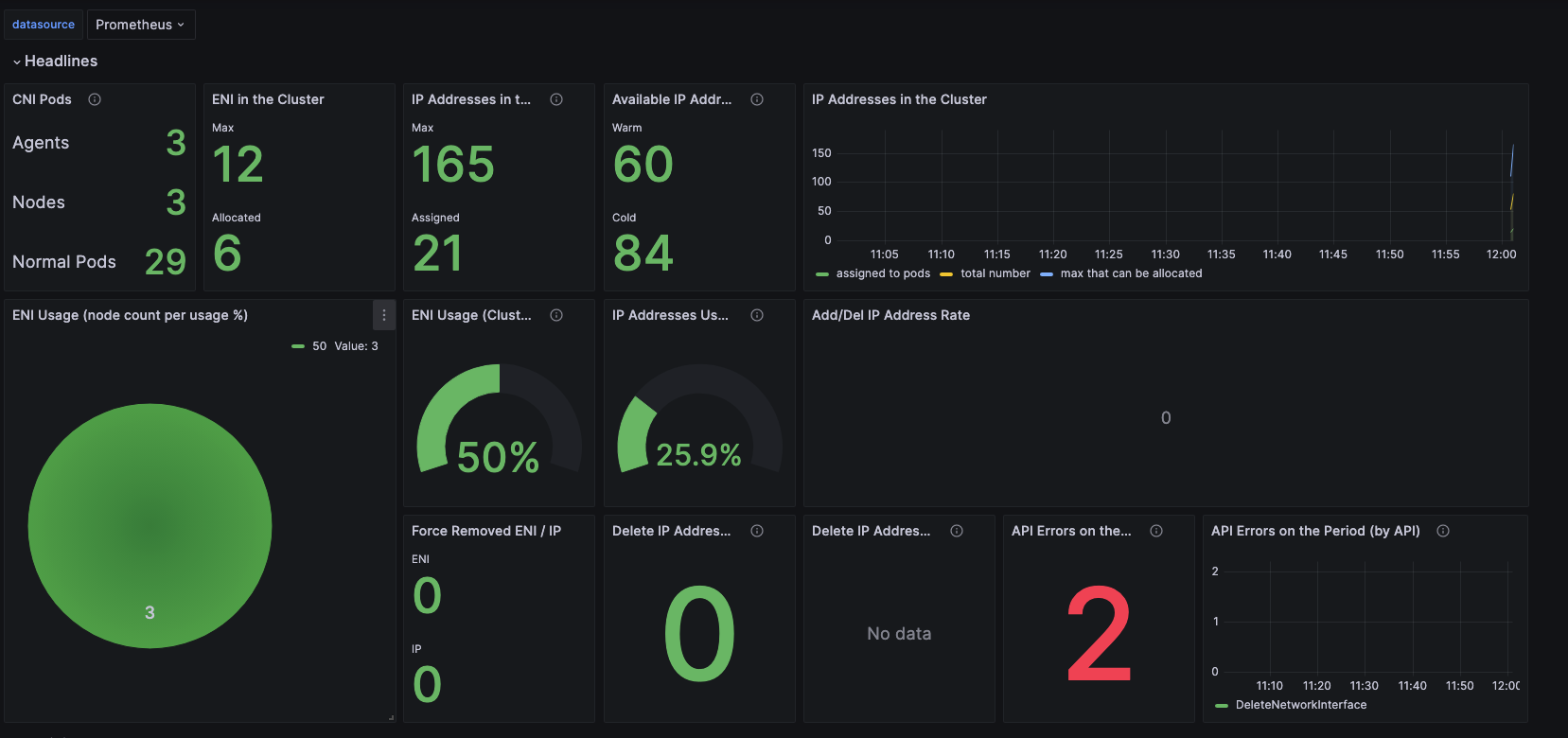
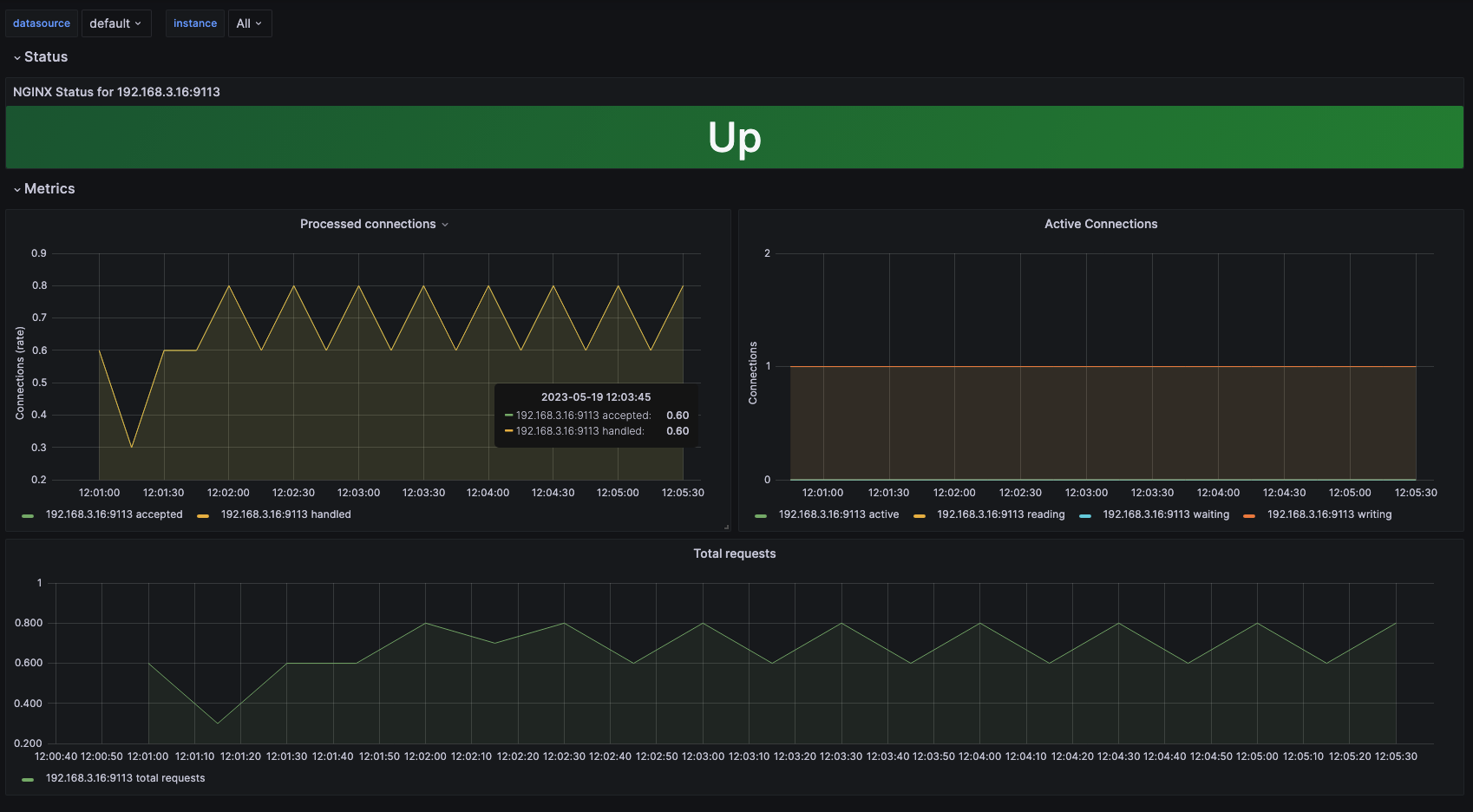
기본 기능말고, 어플리케이션에 특화된 대시보드 구성도 가능하다. Nginx의 경우 사이드카 패턴을 활용해서 Pod에 exporter 컨테이너를 추가하여, Nginx Connection 정보를 읽어 올 수 있다.
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# 메트릭 확인 >> 프로메테우스에서 Target 확인
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath={.items[0].status.podIP})
curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
Wrap up
이번 포스팅에서는 EKS 모니터링과 로깅에 대해 다뤄보았다. DevOps 엔지니어에게 중요한 스킬 중 하나가 이 파트라고 생각한다. 24시간 모니터링을 할 수 있는 상황이 아니면, 모니터링 기능을 통해서 문제를 사전에 파악하거나 빠르게 캐치해서 대응하는게 중요하다. k8s가 안정적으로 구축이 되었다면, 대부분 어플리케이션도 잘 구동되겠지만, Infra에서 발생한 재난은 막을 수 가 없으니, 이런 기능들을 통해서 인사이트를 얻는게 포인트이다. 개인적으로는 k8s를 통해서 내가 어떤 부분에 집중해야할 지 선택을 해야할 것 같은데, 많은 고민이되는 요즘이다..