📗[TO LEARN]
- 머신러닝 기초
- 선형 회귀
- 캐글
💡[배운것]
- 알고리즘
수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한것 - 위키디피아
- 선형 회귀 (Linear Regression)
모든 문제는 선형으로 풀 수 있다고 가정하는것이 선형 회귀
두 데이터간의 직선 관계를 찾아 x값이 주어졌을때 y값을 예측하는 것
시험 전 날 마신 커피 잔 수에 따라 시험 점수를 예측할 수 있을까?
| 커피잔수 | 시험점수 |
|---|---|
| 1 | 50 |
| 2 | 60 |
| 3 | 68 |
| 4 | 81 |
위의 표를 참조하여 직선데이터를 그리고 그래프로 표시한 후 가설을 세울 수 있어야 한다 (가설은 사람이 세워아함 / 기계가 할 수 없음)
✍ [score = 10 * coffee + 40]
이런식으로 공식을 세워야 추세를 예측하는데 도움이 된다
(나는 아무 근거없이 막연하기 대략 5잔정도면 90점이겠지 라고 생각했다;;)
가설 (Hypothesis)
H(x) = Wx + b
직선은 1차 함수를 사용하며,
정확한 예측을 위해 임의의 직선가설과 정답의 거리가 가까워 지도록 (mean squared error (평균제곱오차))를 사용해야 하며 cost function = 손실함수 값이 작게 나오도록 학습해야 한다
W(Weight)값과 b(bias)의 값을 계속 바꿔보며 Hypothesis cost function 이 낮아지는 값을 찾는것이 핵심 = 노가다
- 경사하강법 (Gradient descent method)
만약 정의한 손실함수가 2차함수처럼 동그란 모양을 가진다면
손실함수를 최소화 하기위해 쓴다
W(값 변경)x+b(값 변경) = cost가 떨어졌는지 아닌지 계산
iteration = 반복학습
Learning rate = 한칸 한칸 전진하는 단위
Learning rate가 크다고 무조건 좋은것은 아니며,
찾고하자는것은 Global cost minimum 이기 때문에
local cost minimum에 빠지지 않도록 노력하고
값을 변경해가며 최소값을 찾기위해 많은 실험을 해야한다
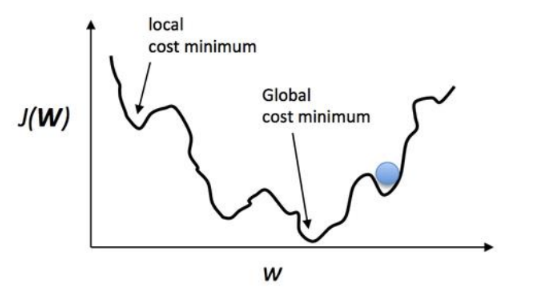
출처: https://regenerativetoday.com/logistic-regression-with-python-and-scikit-learn/
- 회귀(Regression)
연속적인 출력값이 있는 문제는 Regression으로 푼다
(사진으로 나이 예측 등)
입력값 : 얼굴 사진
나이 : 나이
연속적인 문제를 예측하는것 = 회귀 문제
머신러닝에서 출력값은 floating point = 소수값을 많이 씀
- 분류 (Classfication)
비연속적인 문제를 풀때 사용
예) 대학교 시험 전날 공부한 것으로 해당과목의 이수 여부를 예측
<이진 클래스 Binary Class>
이수 클래스 이수(Pass) 0 미이수(Fail) 1
분류해야 하는경우가 많을 경우 다중 분류 (Multi-classfication) 라고 부름
✍ 문제를 정의할때 "입력 출력 인풋 아웃풋 값"을 미리 정의하고
아웃풋값에 따라 문제를 접근하면 어떤것으로 풀어낼지가 용의
-
지도학습 Supervised learning (정답이 있을때 알려주면서 학습하는 방법)
ex) 입력값 = 음원파일, 출력값 = 장르 / 지도학습 적합 -
비지도학습 Unsupervised learning (정답을 알려주지않고 스스로 학습)
ex) 입력값 = 음원파일, 출력값 = ? / 비지도 학습 적합 -
강화학습 Reinforcement learning (알파고를 탄생시킨 머신러닝 방법)
ex) 입력값 = ? , 출력값 = ?
주어진 데이터 없이 실행과 오류를 반복하며 학습
👏 [느낀점]
일단... 쉽지않다!
영어와 수학은 기본이고
가설을 정의할 수 있는 사고가 있어야 머신러닝 엔지니어가 될 수 있겠다는 생각을 했다
금번 강의를 통해 확실히 느낀건
아무리 많은 몰입을 한다해도 이 학문은 꾸준한 공부를 통해
사고가 변하지 않는한 야매식으로 할 순 없을것이란걸 느꼈고
머신러닝을 완벽히 이해하고 넘어가기엔 솔직히 따라갈 수 없을것 같다
그래도 지금의 과정을 통해 머신러닝이 어떻게 동작하는지, 개념을 이해하고 내가 그것을 효율적으로 사용할 수 있을지에 대해 집중하여 공부해야겠다
