1. 오늘 내가 한 일!
프로젝트 시작! 오늘은 프로젝트 SA를 작성하고 오늘 하기로 정한 분량의 프로젝트를 성공하였다!!!너무나 감격😭😭✨
2. 프로젝트 SA
- DRF를 이용한 추천 서비스 시스템 프로젝트
[제주 모범음식점 추천서비스]
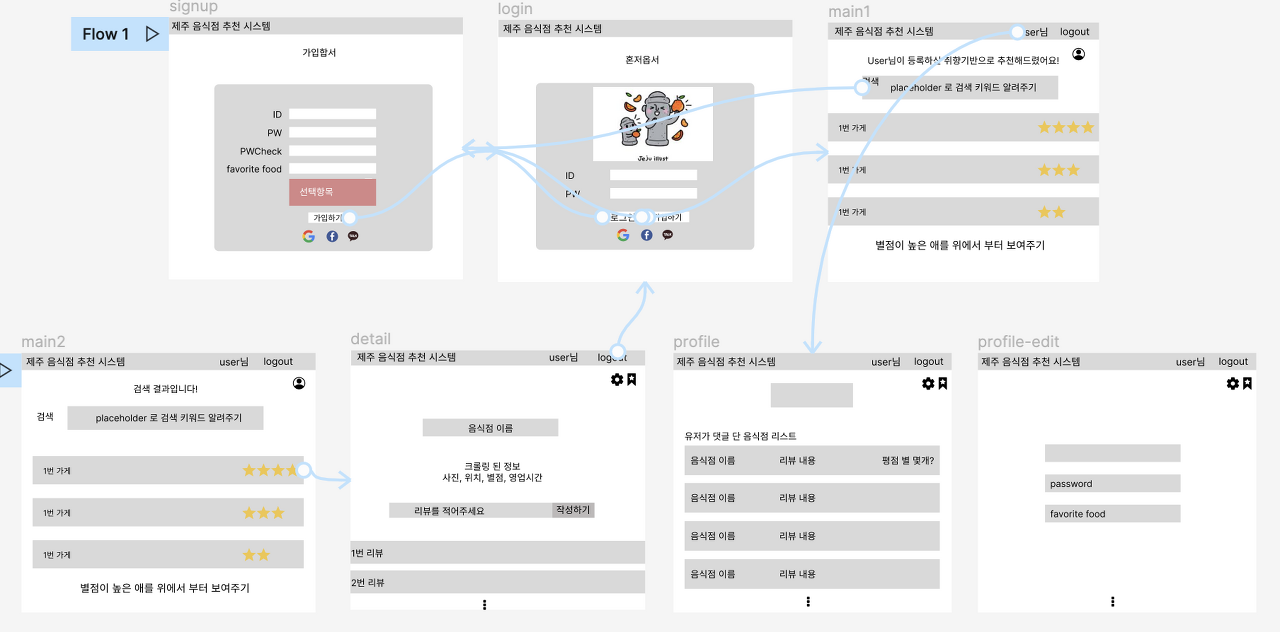
[ERD]
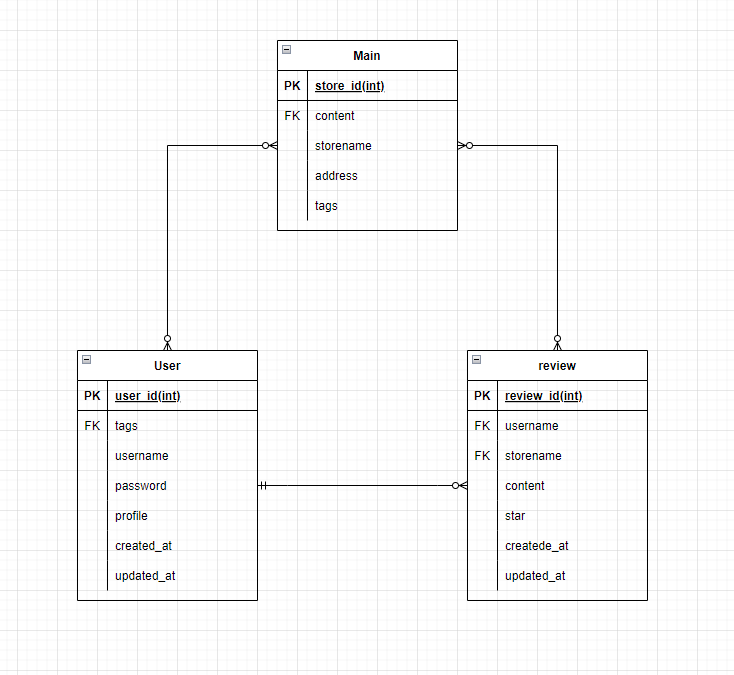
[API 설계]
[팀원들 간의 약속]
- 토요일에 만나서 프로젝트 하기
- 하루의 해야 할 양을 정해서 하기
- 커밋 약속: 생성 Add, 수정 Mod, 내용 자세하기 쓰기, 수시로 커밋하기!, 브랜치 확인하기
3. 문무해알
- UnicodeDecodeError: 'cp949' codec can't decode byte 0xed in position 2: illegal multibyte sequence
- 문제점
Traceback (most recent call last):
File "jeju.py", line 13, in <module>
df1 = pd.read_csv('jejulist.csv', encoding='cp949')
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\util\_decorators.py", line 211, in wrapper
return func(*args, **kwargs)
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\util\_decorators.py", line 331, in wrapper
return func(*args, **kwargs)
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\io\parsers\readers.py", line 950, in read_csv
return _read(filepath_or_buffer, kwds)
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\io\parsers\readers.py", line 605, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\io\parsers\readers.py", line 1442, in __init__
self._engine = self._make_engine(f, self.engine)
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\io\parsers\readers.py", line 1753, in _make_engine
return mapping[engine](f, **self.options)
File "C:\Users\ksh40\Desktop\DRF_Jeju_list_project\venv\lib\site-packages\pandas\io\parsers\c_parser_wrapper.py", line 79, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas\_libs\parsers.pyx", line 547, in pandas._libs.parsers.TextReader.__cinit__
File "pandas\_libs\parsers.pyx", line 636, in pandas._libs.parsers.TextReader._get_header
File "pandas\_libs\parsers.pyx", line 852, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas\_libs\parsers.pyx", line 1965, in pandas._libs.parsers.raise_parser_error
UnicodeDecodeError: 'cp949' codec can't decode byte 0xed in position 2: illegal multibyte sequence- 무엇을 몰랐는지(내가 한 시도)
처음에 인코딩을
df = pd.read_csv('main/jejulist.csv', encoding='cp949')으로 해주었을 때 잘 되었었는데 무슨 이유인지 모르겠지만 다른 팀원이 완성한 코드를 깃허브에 올린 것을 pull받아서 실행하니 이런 오류가 생겼다.
- 해결 방법
구글에 검색해본 결과
open('파일경로.txt', 'rt', encoding='UTF8')이렇게 하거나
open('파일경로', 'rt', encoding='UTF8')이렇게 해보라는 글이 제일 많았다.
하지만 이것으로는 해결이 되지 않아 더 검색해보니
그냥 encoding="UTF-8" 를 추가해보라는 글이 있어서 cp949를 UTF-8로 변경해주니 원래대로 잘 실행 되었다.
- 알게 된 것
cp949는 한글 인코딩 방식의 하나인데 파이썬에서는 이걸로 인코딩된 한글은 제대로 못 읽어내기 때문에 UTF-8을 사용해야겠다!!
https://bskyvision.com/entry/python-UnicodeDecodeError-cp949-codec-cant-decode-byte-0xed-in-position-135-illegal-multibyte-sequence-%EC%97%90%EB%9F%AC-%ED%95%B4%EA%B2%B0%EB%B2%95
- [Visual Studio Code] 한글 깨짐 해결하기
- 문제점
Visual Studio Code에 csv파일을 넣었는데 완전 다 깨져서 나오는 현상이 있었다.

- 무엇을 몰랐는지(내가 한 시도)
구글에 검색해본 결과 vscode의 설정을 살짝 바꿔주면 되는거였다!
- 해결 방법
Visual Studio Code 상단의 파일 - 기본 설정 - 설정 - 사용자 - 텍스트 편집기 - 파일 - Auto Guess Encoding 을 선택하면 된다!!
- 알게 된 것
https://scshim.tistory.com/306
- chorme-driver 설치 안하고 사용하기
- 문제점
- 무엇을 몰랐는지(내가 한 시도)
크롬 드라이버를 사용해야 하는데 모든 팀원들이 같은 코드를 함께 사용해야 했기 때문에 크롬 드라이버를 설치 안하고 사용하는 방법을 찾게 되었다.
- 해결 방법
- 알게 된 것
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)- selenium 크롤링 find_element_by_css_selector 사용 불가
- 문제점
selenium 크롤링 find_element_by_css_selector 사용 불가
- 무엇을 몰랐는지(내가 한 시도)
우리팀 프로젝트 코드에서 find_element_by_css_selector를 사용하고 있었는데 이게 어떤 코드인지 찾아보던 중에 이 코드가 더이상 사용 불가라는 글을 보게 되었다.
WebDriver 객체는 find_element_by_css_selector라는 속성이 없기 때문에 최근 버전의 selenium에서는 더 이상 find_element_by_css_selector을 쓸 수 없다는 것이다.
때문에 find_element_by_css_selector 대신 find_element 메소드를 사용해야 한다고 한다!!
- 해결 방법
from selenium.webdriver.common.by import By
driver.find_element(By.CSS_SELECTOR, 'CSS 셀렉터')- 알게 된 것
변화에 적응하자!!!
