5.1 개요
[ 라우팅과 포워딩 ]
- 라우팅 source ~ destination 까지의 route를 정한다. ⇒ 포워딩 테이블을 만드는데 기준이 된다.
- 포워딩 포워딩 테이블에 의해 datagram의 destination을 찾아 packet을 움직인다.
traditional → per-router 가 라우팅 테이블을 만들었지만
SDN(software defined network) → 중앙 집중형으로 라우팅 테이블을 만든다.
[ Per-router Control Plane ]
그림 5.1은 라우팅 알고리즘들이 모든 라우터 각각에서 동작하는 경우이다.
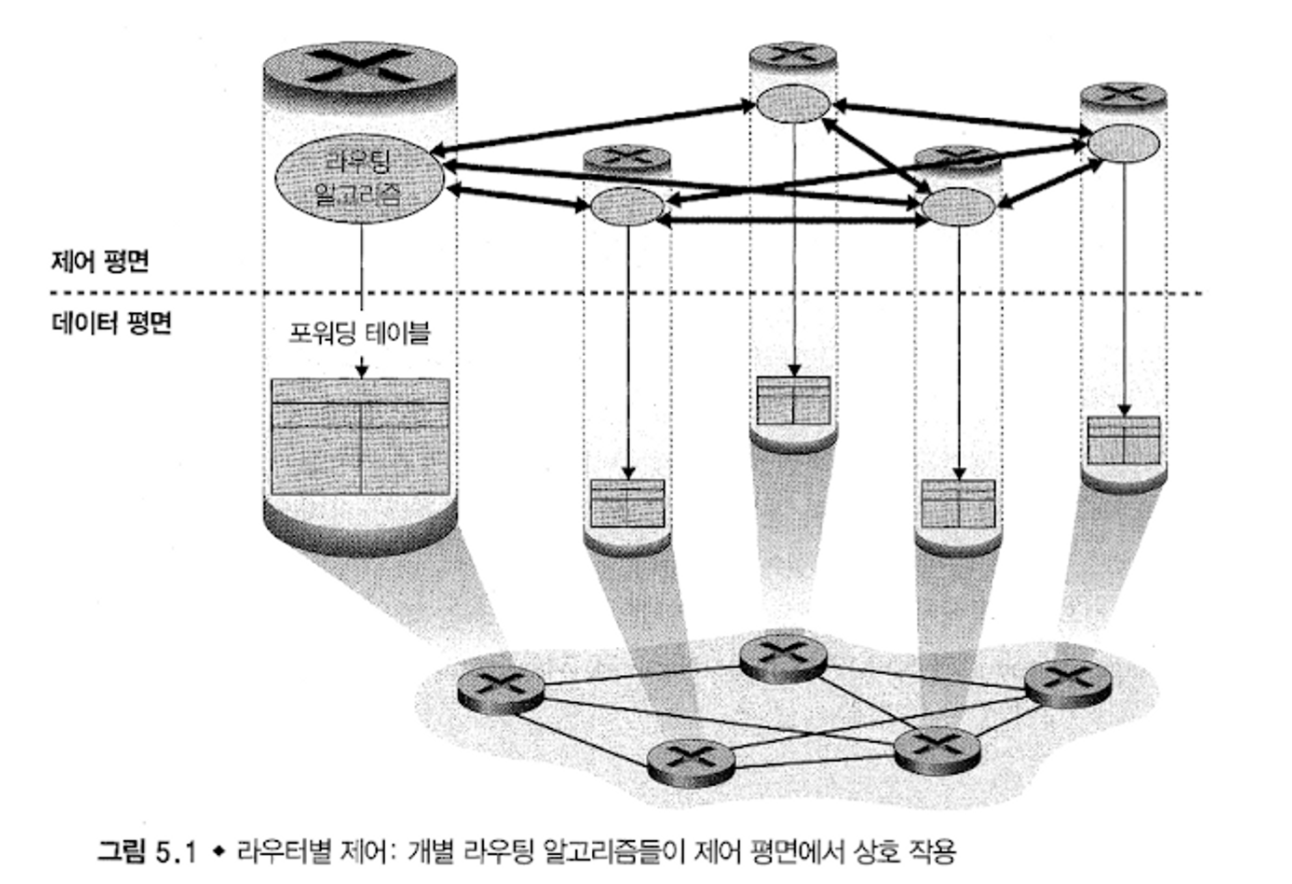
- 포워딩과 라우팅 기능이 모두 개별 라우터에 포함되어 있다.
- 각 라우터는 다른 라우터의 라우팅 구성요소와 통신하여 자신의 포워딩 테이블의 값을 계산한다.(OSPF, BGP 이용)
[ Logically Centralized Control Plane ]
distnct controller interact with local control agent(CA)

즉, remote controller가 모든 router의 정보를 수집(OpenFlow)하고 해당 정보를 바탕으로 포워딩 테이블을 만든다.
이후, 만들어진 포워딩 테이블을 각 라우터에 전달(OpenFlow)하면 각 라우터는 해당 포워딩 테이블을 기반으로 포워딩을 한다.
[ Per-router Control Plane vs Logically Centralized Control Plane ]
Logically Centralized Control Plane 에서
controller는 protocol(OpenFlow protocol)을 통해 각 라우터의 CA와 상호작용하여 라우터의 플로우 테이블을 구성 및 관리한다.
이때 각 라우터는 controller와 통신(OpenFlow protocol)하고 controller의 명령을 수행하는 기능만 가진다.
또한 per-router control plane과 달리 CA끼리 상호작용 하지 않으며 포워딩 테이블을 계산하는 데에 관여하지 않는다.
5.2 라우팅 알고리즘
라우팅 알고리즘의 목표? source ~ destination까지 좋은 경로를 결정하는 것!
일반적으로 좋은 경로는 최소 비용 경로를 뜻함
이러한 경로를 계산하기 위해서 라우팅 알고리즘이 존재함
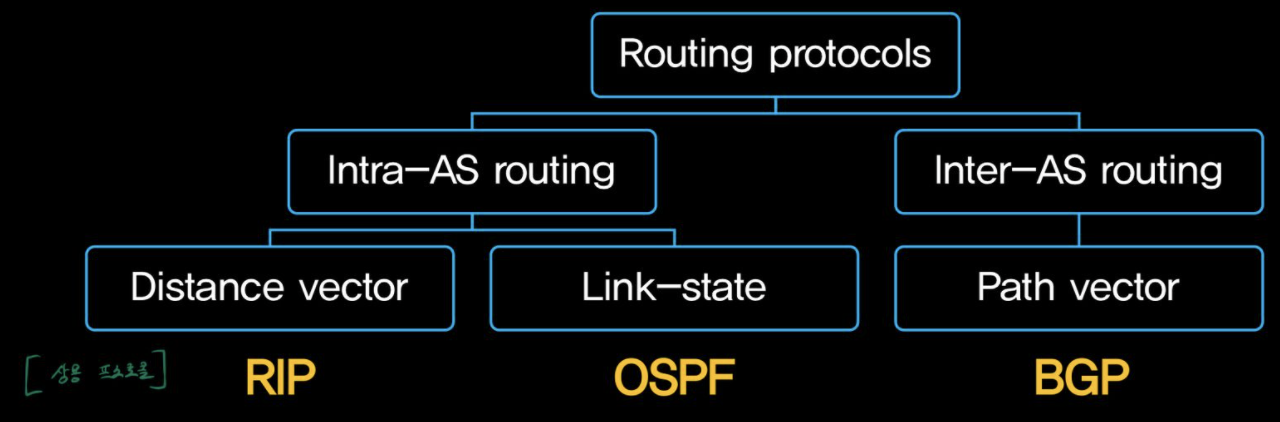
[ Routing Algorithm Classification ]
- Global vs Decentralized
| 중앙 집중형 라우팅 알고리즘(Global) | 분산 라우팅 알고리즘(Decentralized) |
|---|---|
| all routers have complete topology and all link cost information | 어떤 노드도 모든 링크의 비용에 대한 완전한 정보를 가지고 있지 않다. |
대신 각 노드는 자신에 직접 연결된 링크에 대한 비용 정보만 가지고 있다.
이후 이웃 노드와 정보 교환을 통해 노드는 목적지까지의 최소 비용 경로를 계산한다. |
| link state algorithm
⇒ 전체 상태 정보를 가지는 알고리즘 | distance vector algorithm |
| OSPF(AS 내 라우터끼리 통신) | RIP
BGP(다른 AS에서 BG router끼리 통신) |
- static vs dynamic
staticrouting algorithm routes are changed by administrator
dynamicrouting algorithm routes are changed quickly
[ Link- State Routing Algorithm ]
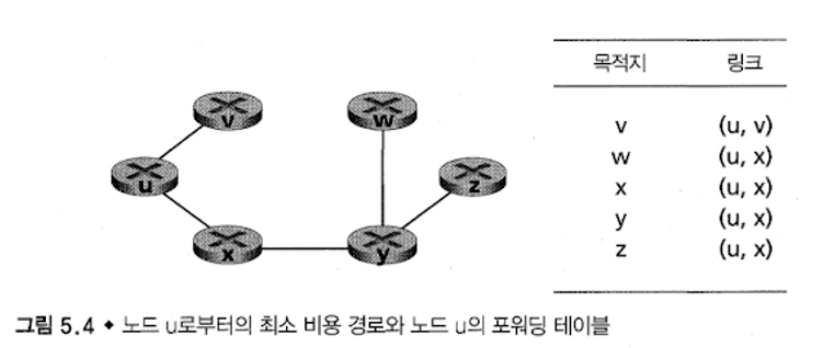
네트워크 topology와 모든 링크 비용이 알려져 있기 때문에 다익스트라 알고리즘을 이용해 최적의 경로를 알아낸다.
이를 통해 한 source에서 다른 모든 노드까지의 최적 경로를 계산해 routing table에 저장한다.
아래는 다익스트라 알고리즘이다.

[ Oscillation Problem ]
추후 추가

[ Distance Vector 라우팅 알고리즘 ]
Link-State 알고리즘이 네트워크 전체 정보를 이용하는 알고리즘인 반면
Distance Vector 알고리즘은 직접 연결된 라우터로부터 정보를 받고, 계산을 수행하며 계산된 결과(라우팅 테이블)를 다시 이웃들에게 배포하는 형식이다.
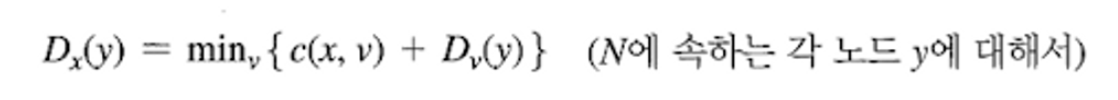
- Dx(y) : cost of least - cost path from x to y
- c(x,v) : cost to neighbor v
- Dv(y) : cost from neighbor v to destination y
if link cost changes:
- 각 노드는 이웃들로부터 업데이트를 기다리고
- 업데이터를 수신하면 새로 거리 벡터를 계산하고
- 이 새로운 거리 벡터를 반영한 라우팅 테이블을 이웃에게 전달한다.
[Good News Travels Fasts ]
거리 벡터 알고리즘을 수행하는 노드가 자신과 이웃 사이 링크의 비용이 변경된 것을 감지하면
자신의 거리벡터를 갱신하고, 이웃에게 새로운 거리 벡터를 보낸다.
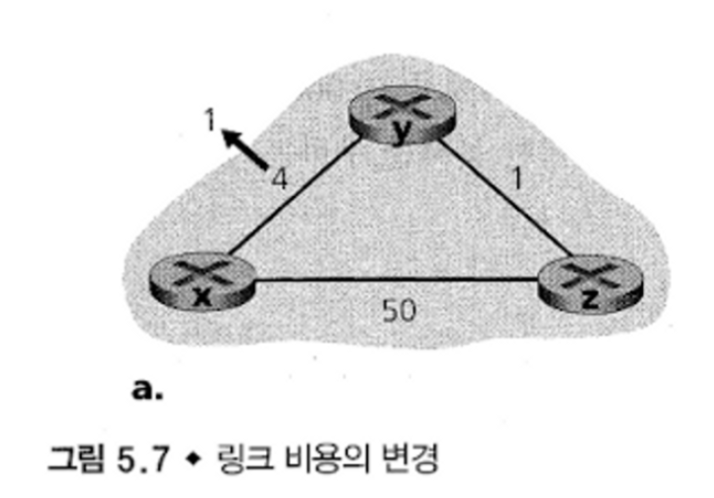
그림에서는 y에서 x로의 링크 비용이 4 에서 1로 변화한 상황이다.
t0 : y가 링크 비용이 변화( 4→ 1)함을 감지하고, 자신의 거리 벡터를 업데이트 한 후 이 변경값을 이웃들에게 알린다.
t1 : z는 y로부터 업데이트 정보를 받고 자신의 테이블을 갱신한다.
즉, z는 x까지의 거리 비용을 갱신( 5→2)하고 이웃에게 자신의 새로운 거리 벡터를 전송한다.
t2: y는 z로부터 업데이트 정보를 받고 자신의 테이블을 갱신한다.
하지만 y의 최소비용은 변화가 없으므로 y는 z에게 아무런 메시지를 보내지 않는다.
이로써 알고리즘은 종료된다.
(z가 x까지의 거리 비용이 2로 갱신이 되었지만, y → z → x == 1 + 2이므로 최소 비용이 갱신되지는 않는다.)
이렇게 비용이 감소한다는 소식은 네트워크 전역에 신속히 퍼져 나간다.
그럼 링크 비용이 증가할 때는 어떤일이 발생할까?
그림에서는 y에서 x로의 링크 비용이 4 에서 60으로 변화한 상황이다.
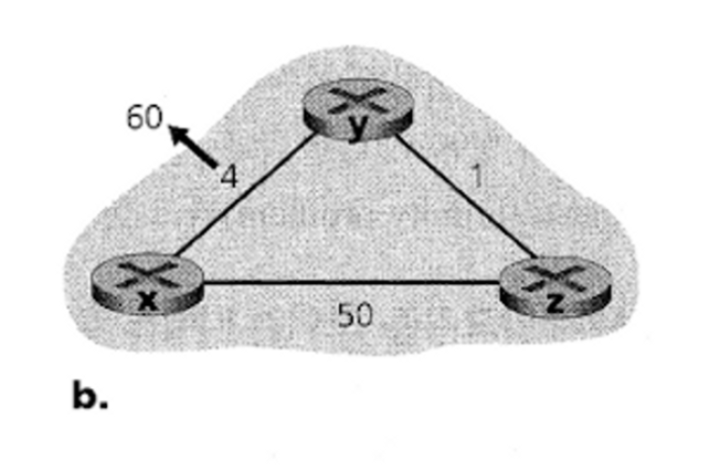
t0: y가 링크 비용 변화를 감지하였다.(링크 비용이 4 → 60으로 변함)
하지만, 최근에 z가 자신이 x까지 5의 비용으로 보낼 수 있다고 말했던 것을 기억하고
x까지의 최소 비용 경로를 갱신한다.( 1 + 5 → z로 보내는 데 비용 + z →x로 보내는 비용)
그리고 이 변경값을 이웃들에게 알린다.
t1: z는 y로부터 업데이트 정보를 받고, x까지의 최소 비용 경로를 갱신한다.( 1 + 6)
또한 이 변경값을 이웃들에게 알린다.
t2 : y는 x로부터 업데이트 정보를 받고, 마찬가지로 x까지의 최소 비용 경로를 업데이트 한다.( 1 + 7)
바로 z가 y를 거쳐서 x로 보내는 비용 값이 50을 넘어갈 때까지 이러한 프로세스가 지속된다.
이후 z는 x와의 직접 연결을 x로의 최소 비용 경로로 설정한다.(50)
이러한 업데이트를 전달받은 y는 z를 거쳐서 x로 전달하는 경로를 설정한다.
이렇게 링크 비용 증가라는 나쁜 소식은 정말 천천히 알려진다.
이런 문제를 무한 계수 문제라고 한다.
(count-to-inifinity problem)
[ 포이즌 리버스 Poisoned reverse ]
count-to-inifinity problem은 포이즌 리버스를 통해서 회피할 수 있다.
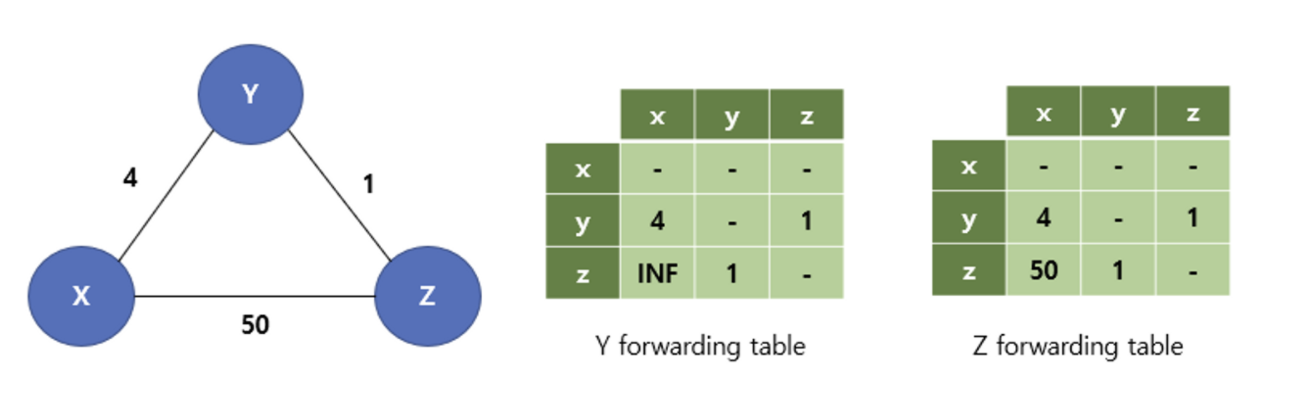
z노드에서 y를 통해 x로 가는게 최적 경로라면, z노드가 y노드에게 자신은 x노드로 가는 비용이 무한대로 전하는 방식이다.(Poisoned Reverse)
⇒ 그러면 y는 z에서 x로 가는 경로가 없다고 믿으므로, y는 z를 통해서 x로 가는 경로를 고려하지 않는다.
이렇게 하면 count-to-inifinity problem이 발생하더라도 2번의 iteration이면 최적 경로를 제대로 갱신할 수 있다.
방금과 같이 링크(x,y)의 비용이 4에서 60으로 증가한 상황을 다시 보자
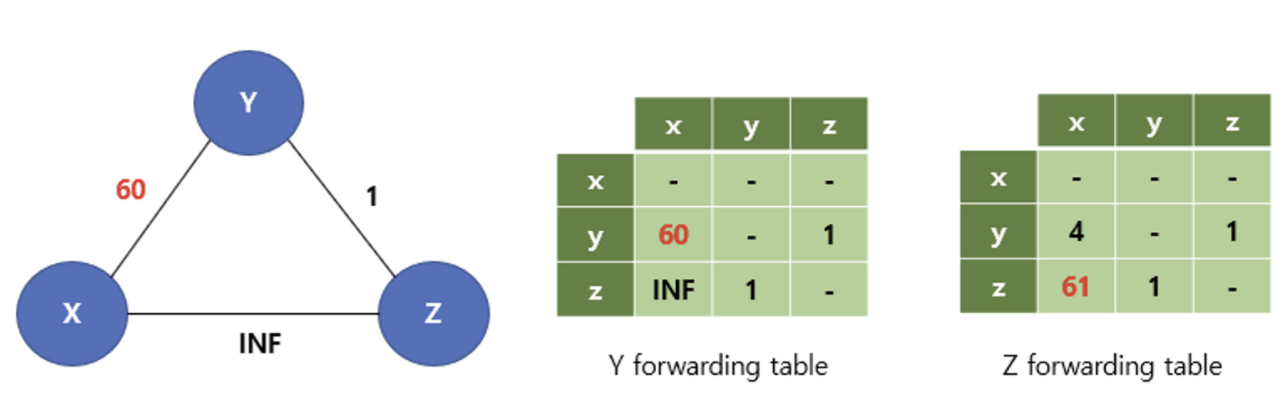
포이즌 리버스를 이용하면
t0: y는 이전에 z가 x를 거쳐서 가는 길이 없다고 했으므로(무한대를 보냈음)
따라서 x까지의 최소 비용 경로를 60으로 갱신하고 이 변경을 이웃 노드에게 전송한다.
t1: z는 x로의 경로를 x로의 직접 연결인 50으로 변경한다.
그리고 더 이상 y를 거치지 않으므로 이러한 변경사항을 이웃 노드에게 전송한다.
t2: z에게서 업데이트 메시지를 받은 뒤에 y는 최소 비용 경로를 51(1 +50)으로 갱신한다.
t3: 이제 y는 z를 거쳐서 x로 가므로 y에서 x까지로 가는 비용을 무한대로 바꾼다.
(포이즌 리버스)
하지만, 포이즌 리버스도 모든 무한 계수 문제를 해결할 수는 없다.
세 개 이상의 노드를 포함한 루프는 포이즌 리버스로는 감지할 수 없다.
[ Link - State Routing Algorithm vs Distance Vector Routing Algorithm]
LS 알고리즘
다익스트라 알고리즘을 수행하기 전에 각 노드가 네트워크에 대한 전체 topology를 알아야 하지만
DV 알고리즘
전체 정보를 사용하지 않고 하나의 노드가 가지는 정보는 단지 자신에게 직접적으로 연결된 이웃 router의 링크 비용과 그 이웃들로부터 수신하는 정보(라우팅 테이블) 뿐이다.
| Link - State Routing Algorithm | Distance Vector Routing Algorithm |
|---|---|
| 링크 비용이 변할 때마다 새로운 링크 비용이 모든 노드에게 전달된다. | 링크 비용이 변하고, 이 새로운 링크 비용이 이 링크에 연결된 어떤 노드의 최소 경로에 변화를 준 경우에만 DV 알고리즘은 수정된 링크 비용을 전파한다. |
| Router know the entire nbetwork topology | Router don’t know the entire nbetwork topology |
| Fast Convergence
(수렴 속도가 빠르다.) | Slow Convergence
(수렴 속도가 느리다.) |
| No routing loops | Count - to - infinity problem |
| OSPF(Open Shortest Path First) | RIP(Routing Information Protocol) |
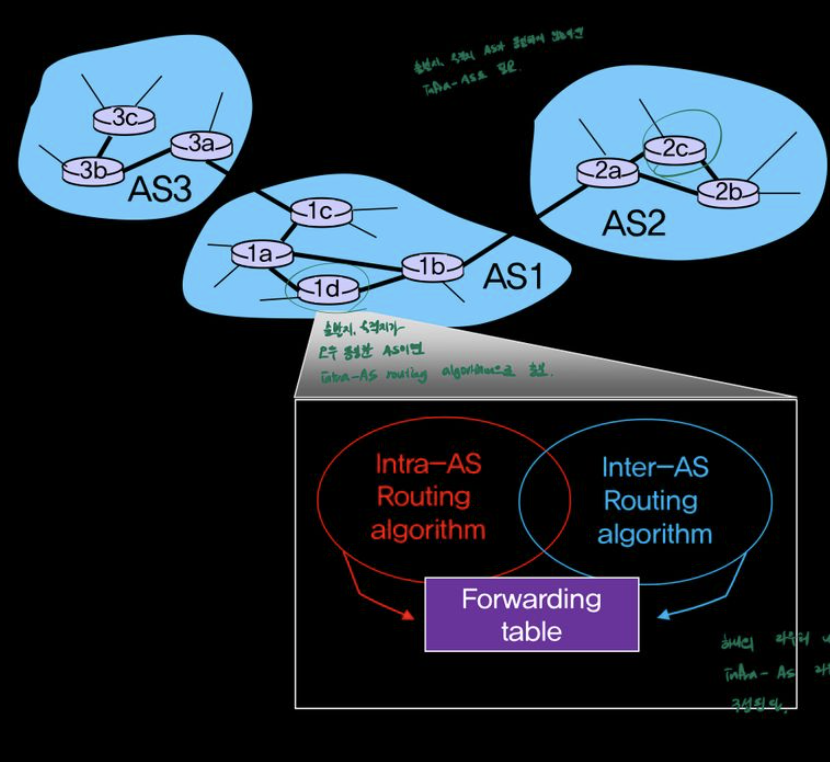
5.3 인터넷에서의 AS 내부 라우팅 OSPF
if all routers are identical ⇒ can’t store all destination in routing tables
and each network admin wanto to control routin in its own network
AS(Autonomous Systems)
같은 AS안에 있는 라우터들은 동일한 라우팅 알고리즘을 사용하고 상대방에 대한 정보를 가지고 있다.
이런 AS 내부에서 동작하는 라우팅 알고리즘을 AS 내부 라우팅 프로토콜 이라고 한다.
[ Intra -AS routing vs Inter-AS routing]
Intra -AS routing
- routers in same AS
- All routers in same AS must same intra-domain protocol
- Routers in different AS can run different intra-domain routing protocol
- Gatewat router(Border Router) to routers in other AS’s
Inter-AS routing
- Routing among AS
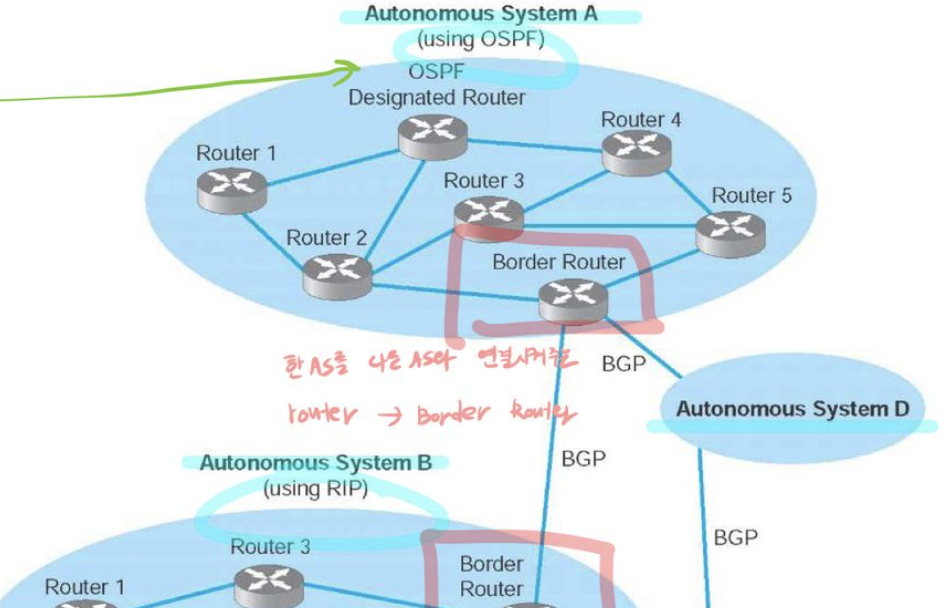
포워딩 테이블은 intra-and inter-AS routing algorithm 으로 구성된다.
개방형 최단 경로 우선(Open Shortest Path First, OSPF) 프로토콜
OSPF는 AS 내부 라우팅 프로토콜이다.
OSPF는 다익스트라 알고리즘을 이용해서 최단 경로를 찾는다.
OSPF는 같은 area의 라우터들에게만 링크 상태를 알린다.
또한 각 area의 border router가 외부 router로의 패킷 라우팅을 책임진다.
- Two level hierarchy : local area, backbone
- each node has detailed area topology(not entire topology)
- Area
border router- area를 요약해서 다른 area에 전달(즉 다른 area와 연결할 때 사용하는 router)
Backbone router- connect to other AS

what is benefit hierachical OSPF in large domains?
- minimize routing update traffic localizes the impact of topology changes to an area(그니깐 업데이트 된 게 area로 한정되니깐 이득인거임)
5.4 인터넷 서비스 제공업자(ISP)간의 라우팅 : BGP
[ OSPF 와 BGP의 차이점 ]
OSPF : AS 내부 라우팅 프로토콜
따라서 동일한 AS내에 있는 출발지와 목적지 사이에서 패킷을 라우팅 할 때 사용
그러나 여러 AS를 통과하도록 라우팅 할 때는 BGP(Border Gateway Protocol)이 필요하다.
[ eBGP, iBGP ]
AS의 가장자리에 위치한 BG(Border Gateway)들 간의 프로토콜을 BGP라고 한다.
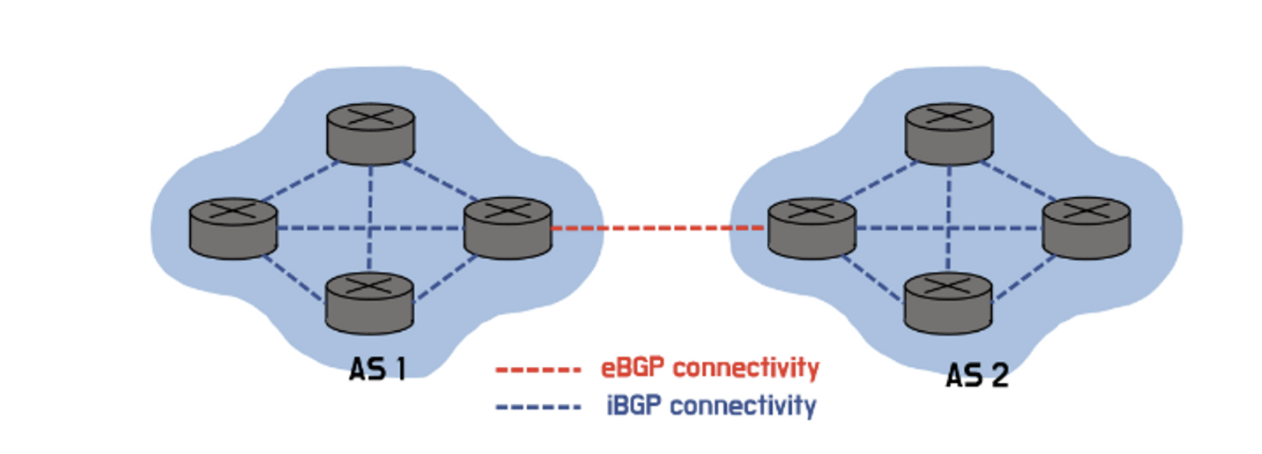
- iBGP
- AS 내부에 있는 다른 라우터에게 eBGP를 통해 얻어온 info를 전달하는 프로토콜
- eBPG
- 서로 다른 AS상의 BG끼리의 연결을 담당하는 BGP, inter-AS 프로토콜
[ BGP 의 역할 → 정보를 소문내라!!]
주변의 여러 라우터들에게 어떤 라우터가 어느 AS에 속해있는지에 대한 정보를 소문내는 것
예시) x에 대한 도달 가능 정보를 AS1과 AS2의 모든 라우터에게 알리는 경우
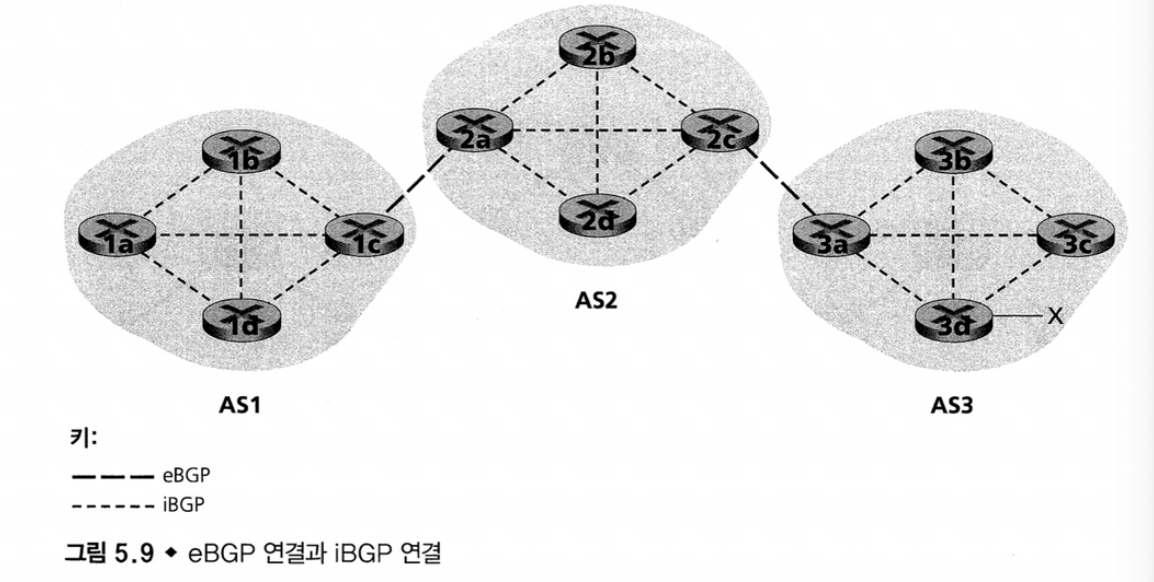
- AS3는 AS2의 BG에게 “AS3 x” 라는 eBGP 메시지를 전달한다.
- AS2 BG는 iBPG 메시지 “AS3 x” 를 2a를 포함한 AS2 내부의 모든 라우터에게 전송한다.
- AS2 BG는 eBPG 메시지 “AS2 AS3 x”를 AS1 BG에게 전달한다.
- AS1 BG는 iBPG 메세지를 통해서 AS1 내의 모든 라우터에게 전달한다.
이로써 AS1, AS2의 각 라우터들은 x의 존재와 x로 향하는 AS 경로를 알게 된다.
[ BGP route selection ]
- AS-PATH : 메시지가 통과하는 AS들의 리스트
- NEXT-HOP: internal-AS router to next-hop AS(외부 AS로 전달하기 위한 내부 AS)
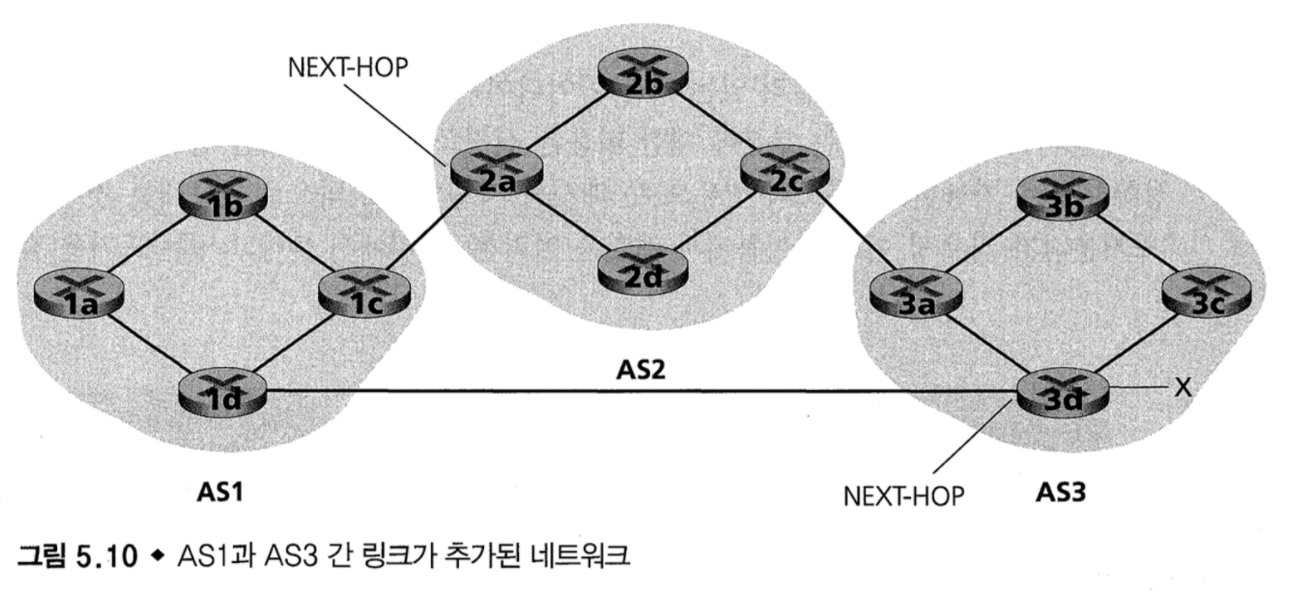
[ Hot Potato Routing ]
Gateway router may learn about multiple paths to destinations
→ 라우터 1c는 2개의 path가 있다는 것을 안다.
- AS1 gateway router 1c learns path “AS2 AS3 X” from 2a
- AS1 gateway router 1c learns path “AS3 X” from 3d
Hot Potato Routing에서는 Next-Hop이 짧은 Link를 선택한다.
즉, 여기까지 내용을 정리하면
- 서로 다른 AS간의 경로를 설정하는데에는 Inter-AS 라우팅 프로토콜인 BGP를 사용한다.
- BGP는 Hot Potato Routing 방식을 채택한다.
- 물론, policy에 맞게 결정한다.
전체 경로 중에서 자기 AS 외부에서 얼마의 비용이 드는지는 신경쓰지 않고 오로지 자신의 AS 내부의 비용만 줄이려는 이기적인 알고리즘이다.
따라서 한 AS 내 2개의 라우터가 동일한 목적지 주소에 대해 서로 다른 AS경로를 선택할 수도 있다.
ex) 라우터 1b는 본인에게서 가장 적은 비용이 드는 1c BG를 통해서 데이터를 내보낸다.
라우터 1d는 본인에게서 가장 적은 비용이 드는 1d BG를 통해서 데이터를 내보낸다.
[ 경로 선택 알고리즘 ]
-
지역 선호도( 즉 policy)가 경로에 할당된다.
이러한 지역 선호도는 네트워크 관리자에 의해 정책적인 결정이다.
-
가장 높은 지역 선호도 값을 가
-
지역 선호도(==policy)가 경로에 할당된다.이때 지역 선호도 값은 AS 네트워크 고나리자에 의한 정책적인 결정이다,.
-
가장 높은 지역 선호도를 가진 경로가 여러 개 있다면 이들 중에서
최단AS-PATH를 가진 경로가 선택된다.이때, BGP는 최단 경로 결정을 위해 DV 알고리즘을 사용한다.
-
같은 지역 선호도 값과 같은 AS-PATH 길이를 가진 남은 경로들에 대해
Hot Potato Routing을 수행한다. 즉,NEXT-HOP라우터 까지의 거리가 가장 가까운 경로가 선택된다.
[ IP anycast ]

- same IP address to each DNS server
- BGP router receives multiple route 알림 메시지, it thinks they are different paths to the same location
- each router locally pick the best route to that IP address
5.5 SDN(Software Defined Networking)
개별적인 router에 routing algorithm이 존재
router간에 데이터 교환을 하면서 각각 router가 전체 topology를 알아냄
distance vector 알고리즘을 이용해 최소 비용 cost를 알아냄
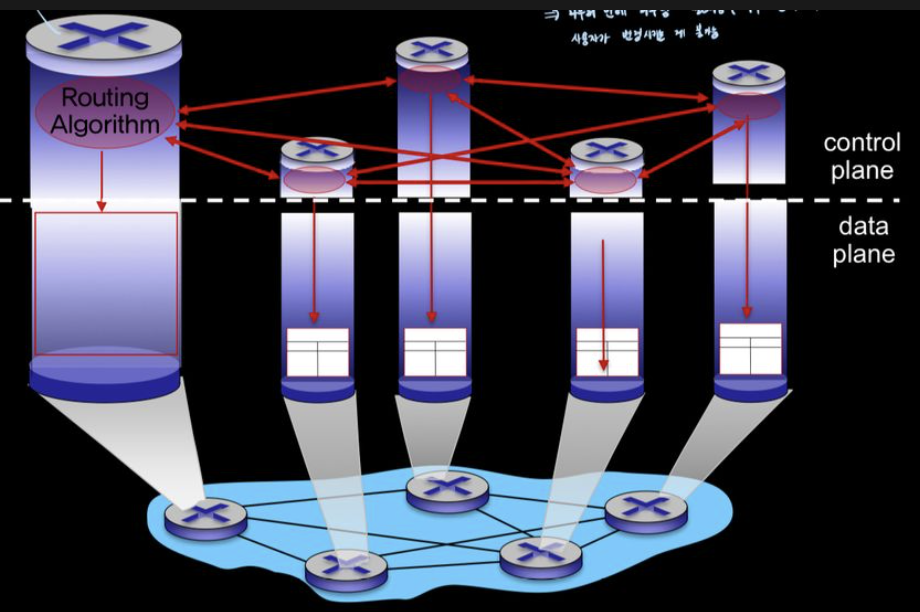
즉 router안에 router algorithm 이 존재해서 admin이 변형시키는 것이 불가능
[ A distinct controller ]
interacts with local control agents(CA) to compute forwarding tables
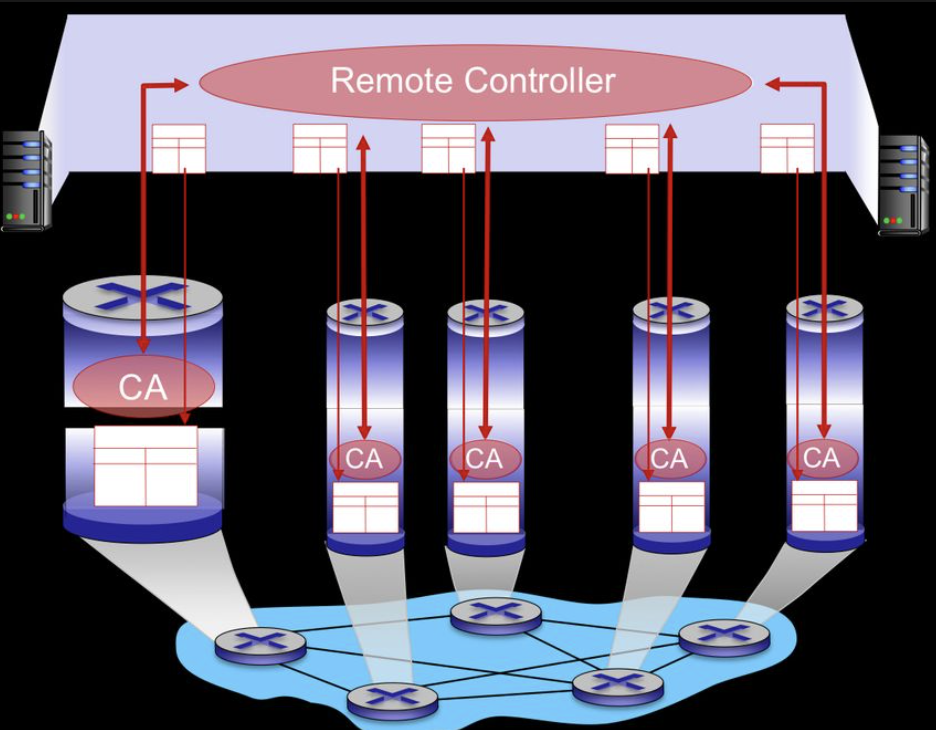
- 데이터 평면과 제어 평면의 분리
- 데이터 평면 : 네트워크 스위치로 구성, 플로우 테이블을 기반으로 데이터를 보낸다.
- 제어 평면 : 플로우 테이블을 결정, 관리
- 네트워크 제어 기능이 데이터 평면 스위치 외부에 존재
- 제어 평면이
SDN controller와네트워크 제어 응용으로 구분된다. - SDN controller가 제어 평면에서 동작하고 있는 네트워크 제어 응용들에 제공하여, 응용들이 하부 네트워크 장치들을 관리할 수 있는 수단을 제공한다.(OpenFlow API)
- 제어 평면이
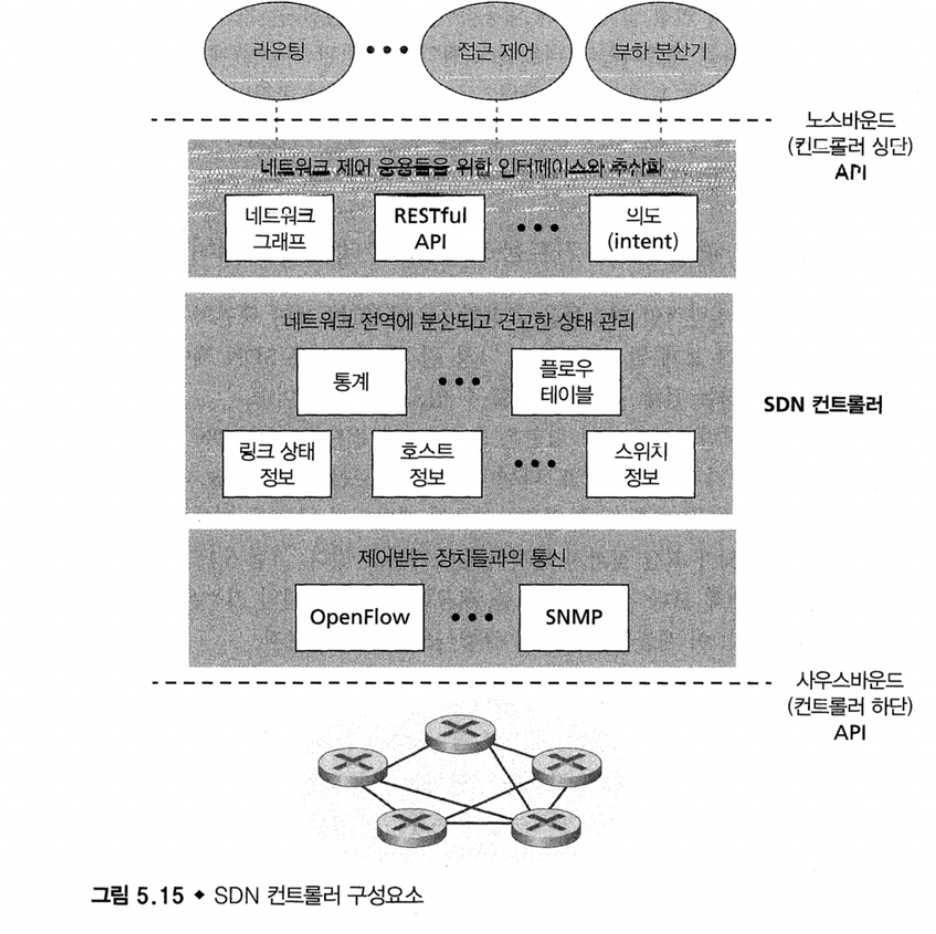
5.5.1 SDN 제어 평면 : SDN 컨트롤러와 SDN 네트워크 제어 응용들
- 사운드바운드 계층(OpenFlow API)
- SDN 컨트롤러가 router의 동작을 제어하려면, 컨트롤러와 그 장치들 사이에 정보를 전달하는 프로토콜이 존재해야 한다.
- ex) 연결된 링크가 단절되었다.
- 이러한 이벤트들은 SDN 컨트롤러에게 네트워크에 상태에 대한 최신의 정보를 제공한다.
- SDN controller는 새로운 정보를 반영하여 flow table를 update한다.
또한 update된 내용을 각 router에게 전달하고,
각 router는 flow table을 기반으로 데이터를 전달한다.
[Data plane switching]
- Protocol for communicating with controller and Data plane switches (ex) OpenFlow API
- Each router contains a flow table computed by a centralized routing controller
[ data plane ]

[ forwarding ]

[ SDN Controller]
data plane에 있는 CA들의 정보를 모아 플로우 테이블을 만든다.
via southbound API
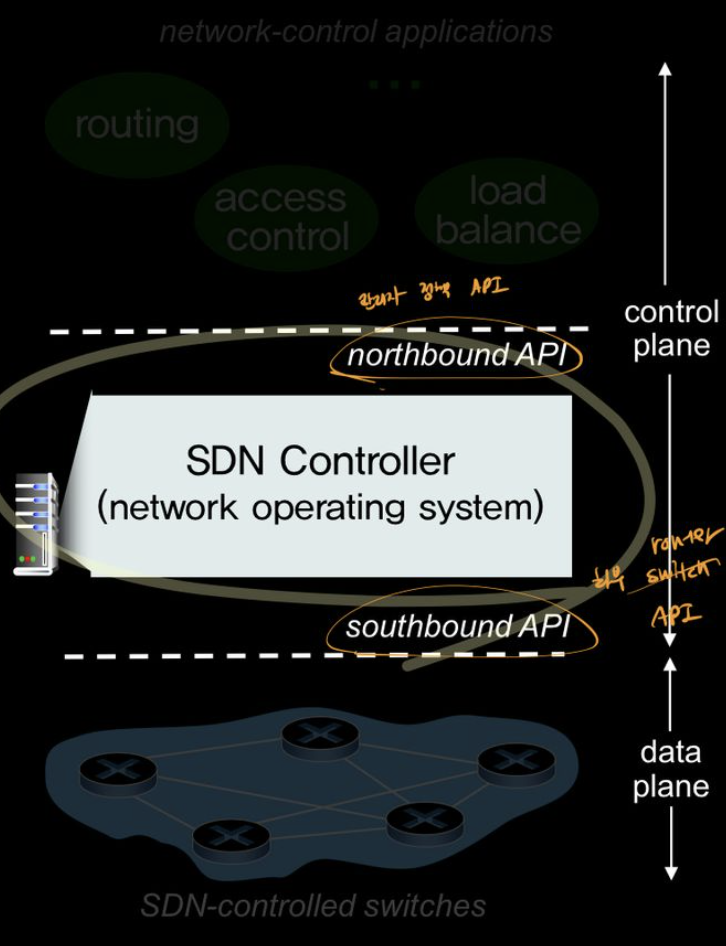
[ network control applications]
router 관리자가 결정할 수 있도록 쉽게 조작할 수 있는 API제공
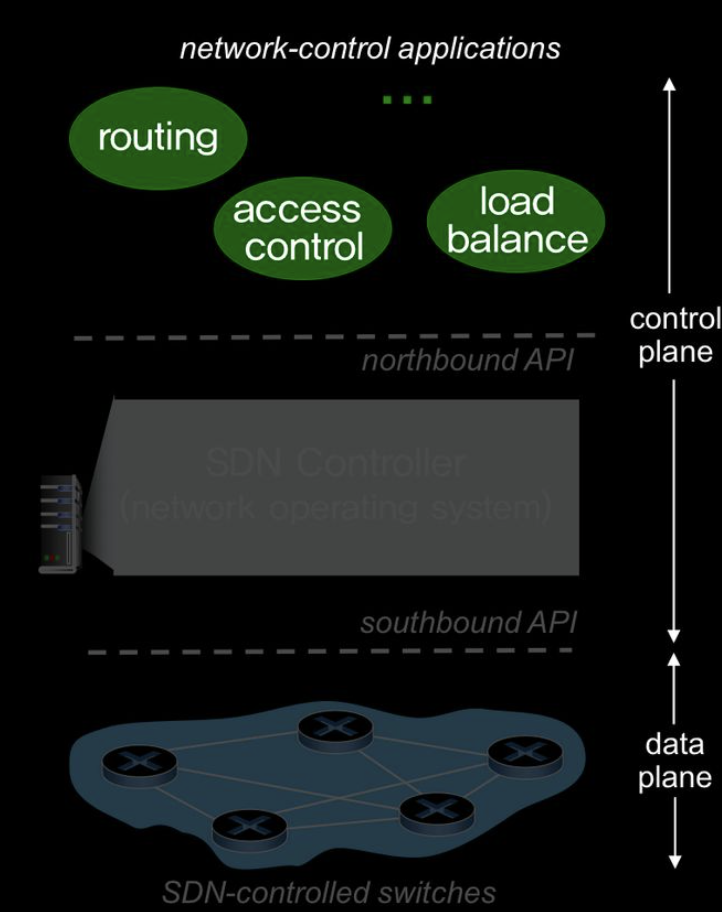
5.5.2 OpenFlow 프로토콜
OpenFlow는 SDN controller와 SDN으로 제어되는 스위치 사이에서 동작한다.
[ Controller - to - switch ]
- Configuration : controller queried switch configuration parameteres
- Read - state : controller quries statisitcs and features from switch’s flow table
- Modify-state : add, delete, modify flow entreis in the OpenFlow tables
- Send - Packet : controller can send a specific packet out of 페이로드에 보낼 패킷을 포함
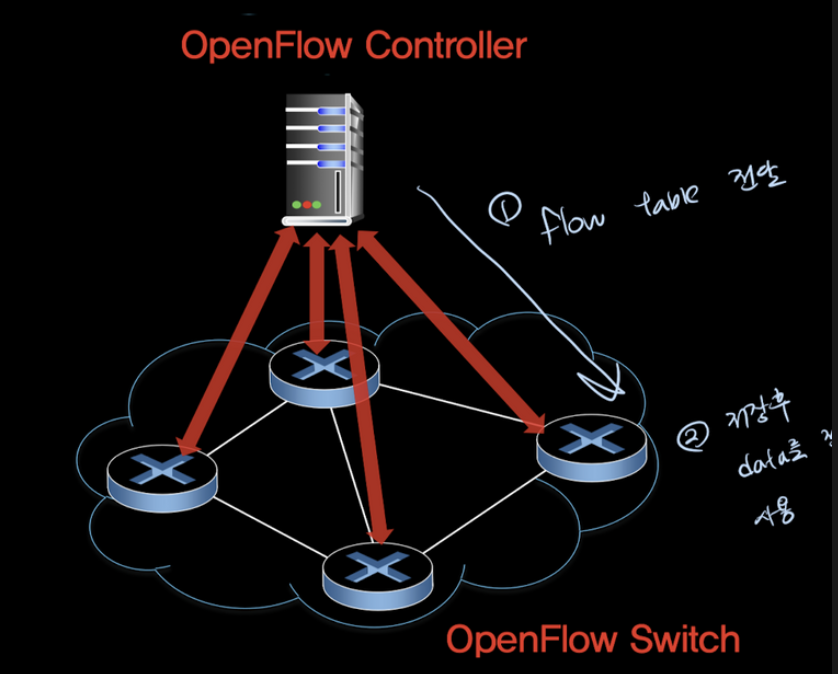
[ Switch-to-Controller]
- Flow-removed : flow table entry deleted at switch
- Port status : inform controller of a change on a port
- packet-in : transfer packet to controller(스위치에 도착한 패킷 중에서 플로우 테이블의 어느 엔트리와도 일치하지 않은 패킷을 controller에게 전송)
controller는 해당 정보를 받아서 flow table을 재구성한다.
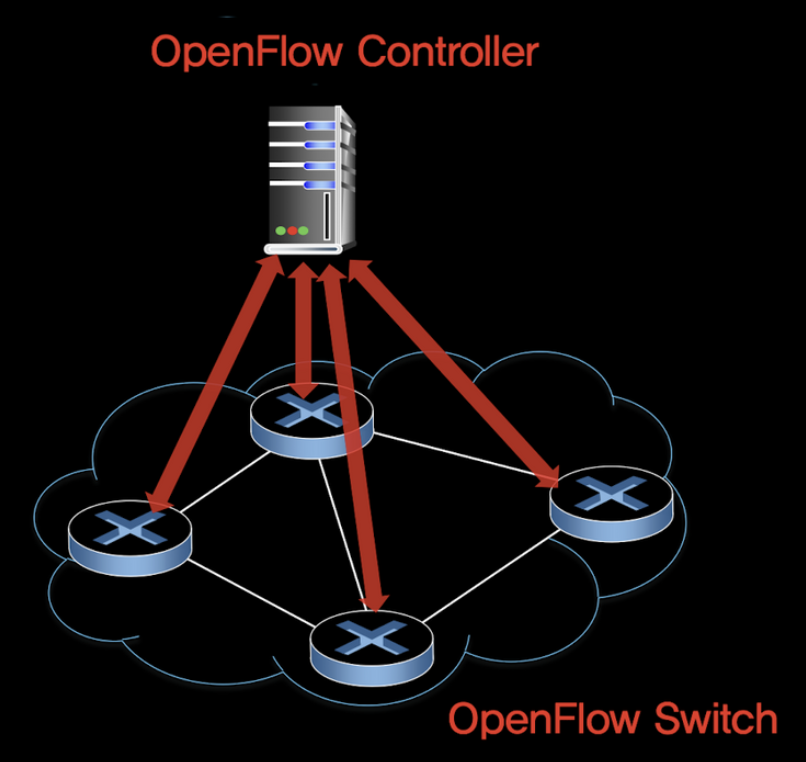
5.5.3 데이터 평면과 제어 평면의 상호 작용 : 예제
- 다익스트라 알고리즘이 패킷 스위치 외부에서 별도의 응용으로 수행된다.
- 패킷 스위치들이 링크 업데이트 정보를 서로 간이 아닌 SDN 컨트롤러에게 전송한다.
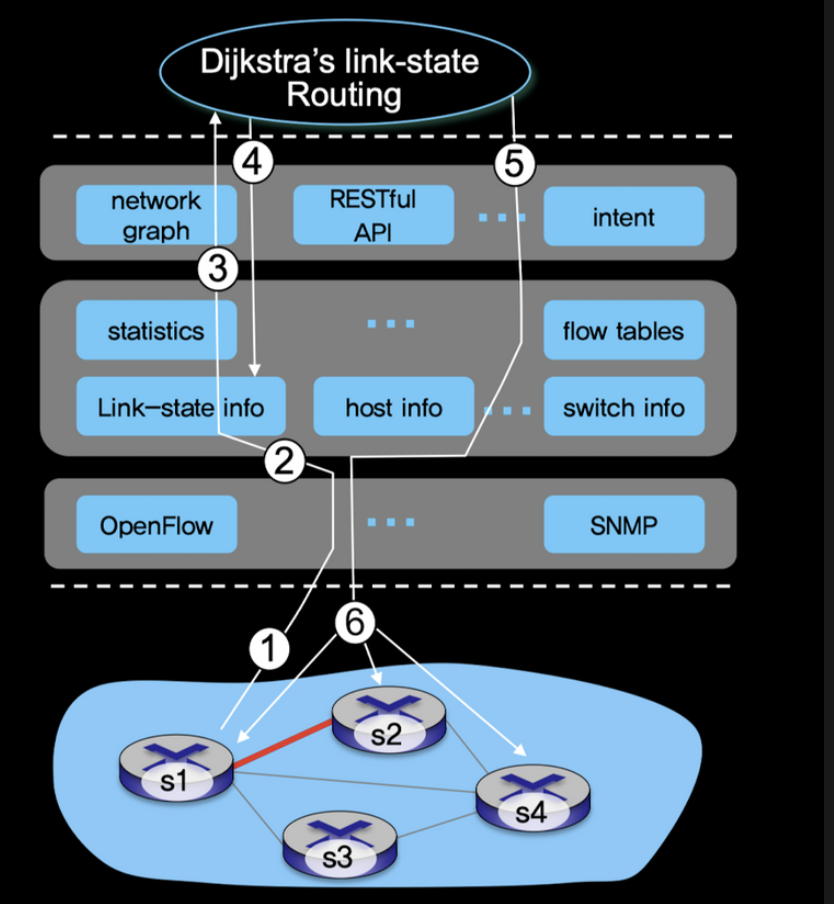
위 그림의 예에서 스위치 s1, s2 사이의 링크가 단절되었다.
- s2와 링크 단절을 감지한 s1은 openflow의 port status message를 사용하여 링크 상태 변화를 SDN 컨트롤러에게 알린다.
- 링크 상태 변화를 알리는 openflow message를 받은 SDN 컨트롤러는 링크상태 정보를 업데이트 시킨다.
- 다익스트라 알고리즘을 통해 최소 비용 경로를 갱신한다. 이를 플로우 테이블에 반영한다.
- OpenFlow를 사용하여 링크 상태 변화에 영향을 받는 스위치들에게 플로우 테이블을 보낸다.
5.6 인터넷 제어 메시지 프로토콜(ICMP)
ICMP(Internet Control Message Protocol)
ICMP는 TCP/IP 에서 IP 패킷을 처리할 때 발생되는 문제를 알려주는 프로토콜이다.
IP에는 패킷을 목적지에 도달시키기 위한 내용들로만 구성되어 있다.
따라서 중간에 패킷을 잃어버려도 source입장에서는 해당 내용을 모른다.
이러한 문제점을 해결하고자 host & router to communicate network-level-information(==error reporting)을 위해 만들어졌다.
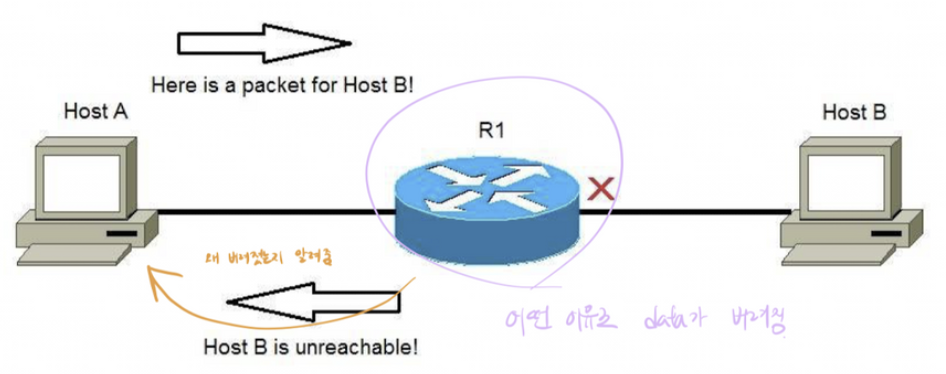
ICMP는 에러 상황이 발생할 경우 IP헤더에 기록되어 있는 source host로 에러에 대한 정보를 보내준다.
이러한 에러 정보를 받게 된 source에서는 destiniation 에 대한 상태를 알고, 이후에 다른 형식으로 데이터를 보낼 수 있다.
ICMP message : type, code → IP datagram causing error
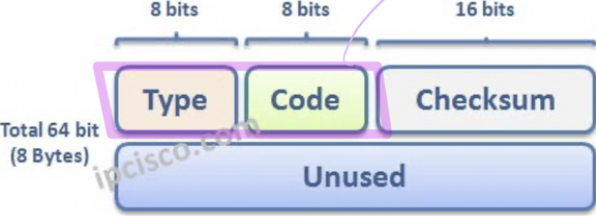
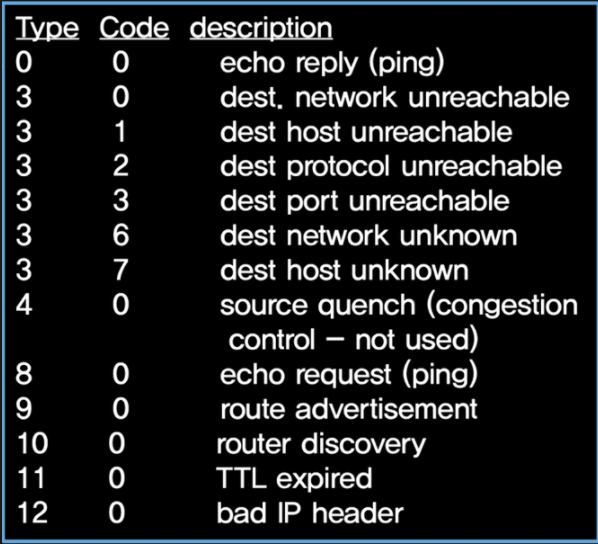
ICMPv6 : new version of ICMP
- plus message types : Packet Too Big
