Pandas
import pandas as pd
df = pd.read_csv('data/pew.csv')
df.head(2)
|
religion |
<$10k |
$10-20k |
$20-30k |
$30-40k |
$40-50k |
$50-75k |
$75-100k |
$100-150k |
>150k |
Don't know/refused |
| 0 |
Agnostic |
27 |
34 |
60 |
81 |
76 |
137 |
122 |
109 |
84 |
96 |
| 1 |
Atheist |
12 |
27 |
37 |
52 |
35 |
70 |
73 |
59 |
74 |
76 |
data = pd.melt(df,id_vars='religion', var_name='income', value_name='count')
data.head(2)
|
religion |
variable |
value |
| 0 |
Agnostic |
<$10k |
27 |
| 1 |
Atheist |
<$10k |
12 |
data.columns = ['religion', 'income', 'count']
data.sample()
|
religion |
income |
count |
| 37 |
Atheist |
$20-30k |
37 |
data.rename(columns={"income": "소득영역", "count": "갯수"})
|
religion |
소득영역 |
갯수 |
| 0 |
Agnostic |
<$10k |
27 |
| 1 |
Atheist |
<$10k |
12 |
| 2 |
Buddhist |
<$10k |
27 |
| 3 |
Catholic |
<$10k |
418 |
| 4 |
Don’t know/refused |
<$10k |
15 |
| ... |
... |
... |
... |
| 175 |
Orthodox |
Don't know/refused |
73 |
| 176 |
Other Christian |
Don't know/refused |
18 |
| 177 |
Other Faiths |
Don't know/refused |
71 |
| 178 |
Other World Religions |
Don't know/refused |
8 |
| 179 |
Unaffiliated |
Don't know/refused |
597 |
180 rows × 3 columns
pd.read_csv('data/billboard.csv')
|
year |
artist |
track |
time |
date.entered |
wk1 |
wk2 |
wk3 |
wk4 |
wk5 |
... |
wk67 |
wk68 |
wk69 |
wk70 |
wk71 |
wk72 |
wk73 |
wk74 |
wk75 |
wk76 |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
87 |
82.0 |
72.0 |
77.0 |
87.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
2000-09-02 |
91 |
87.0 |
92.0 |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2000-04-08 |
81 |
70.0 |
68.0 |
67.0 |
66.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
2000-10-21 |
76 |
76.0 |
72.0 |
69.0 |
67.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
2000-04-15 |
57 |
34.0 |
25.0 |
17.0 |
17.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 312 |
2000 |
Yankee Grey |
Another Nine Minutes |
3:10 |
2000-04-29 |
86 |
83.0 |
77.0 |
74.0 |
83.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 313 |
2000 |
Yearwood, Trisha |
Real Live Woman |
3:55 |
2000-04-01 |
85 |
83.0 |
83.0 |
82.0 |
81.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 314 |
2000 |
Ying Yang Twins |
Whistle While You Tw... |
4:19 |
2000-03-18 |
95 |
94.0 |
91.0 |
85.0 |
84.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 315 |
2000 |
Zombie Nation |
Kernkraft 400 |
3:30 |
2000-09-02 |
99 |
99.0 |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 316 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
60 |
37.0 |
29.0 |
24.0 |
22.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
317 rows × 81 columns
df = pd.read_csv('data/billboard.csv')
df.head(1)
|
year |
artist |
track |
time |
date.entered |
wk1 |
wk2 |
wk3 |
wk4 |
wk5 |
... |
wk67 |
wk68 |
wk69 |
wk70 |
wk71 |
wk72 |
wk73 |
wk74 |
wk75 |
wk76 |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
87 |
82.0 |
72.0 |
77.0 |
87.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
1 rows × 81 columns
df.columns
Index(['year', 'artist', 'track', 'time', 'date.entered', 'wk1', 'wk2', 'wk3',
'wk4', 'wk5', 'wk6', 'wk7', 'wk8', 'wk9', 'wk10', 'wk11', 'wk12',
'wk13', 'wk14', 'wk15', 'wk16', 'wk17', 'wk18', 'wk19', 'wk20', 'wk21',
'wk22', 'wk23', 'wk24', 'wk25', 'wk26', 'wk27', 'wk28', 'wk29', 'wk30',
'wk31', 'wk32', 'wk33', 'wk34', 'wk35', 'wk36', 'wk37', 'wk38', 'wk39',
'wk40', 'wk41', 'wk42', 'wk43', 'wk44', 'wk45', 'wk46', 'wk47', 'wk48',
'wk49', 'wk50', 'wk51', 'wk52', 'wk53', 'wk54', 'wk55', 'wk56', 'wk57',
'wk58', 'wk59', 'wk60', 'wk61', 'wk62', 'wk63', 'wk64', 'wk65', 'wk66',
'wk67', 'wk68', 'wk69', 'wk70', 'wk71', 'wk72', 'wk73', 'wk74', 'wk75',
'wk76'],
dtype='object')
pd.melt(df,id_vars=['year', 'artist', 'track', 'time', 'date.entered'],
var_name='week',
value_name='rating')
|
year |
artist |
track |
time |
date.entered |
week |
rating |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk1 |
87.0 |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
2000-09-02 |
wk1 |
91.0 |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2000-04-08 |
wk1 |
81.0 |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
2000-10-21 |
wk1 |
76.0 |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
2000-04-15 |
wk1 |
57.0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 24087 |
2000 |
Yankee Grey |
Another Nine Minutes |
3:10 |
2000-04-29 |
wk76 |
NaN |
| 24088 |
2000 |
Yearwood, Trisha |
Real Live Woman |
3:55 |
2000-04-01 |
wk76 |
NaN |
| 24089 |
2000 |
Ying Yang Twins |
Whistle While You Tw... |
4:19 |
2000-03-18 |
wk76 |
NaN |
| 24090 |
2000 |
Zombie Nation |
Kernkraft 400 |
3:30 |
2000-09-02 |
wk76 |
NaN |
| 24091 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk76 |
NaN |
24092 rows × 7 columns
df.shape
(317, 81)
df_melt = pd.melt(df,id_vars=['year', 'artist', 'track', 'time', 'date.entered'],
var_name='week',
value_name='rating')
df_melt.shape
(24092, 7)
pd.read_csv('data/country_timeseries.csv')
|
Date |
Day |
Cases_Guinea |
Cases_Liberia |
Cases_SierraLeone |
Cases_Nigeria |
Cases_Senegal |
Cases_UnitedStates |
Cases_Spain |
Cases_Mali |
Deaths_Guinea |
Deaths_Liberia |
Deaths_SierraLeone |
Deaths_Nigeria |
Deaths_Senegal |
Deaths_UnitedStates |
Deaths_Spain |
Deaths_Mali |
| 0 |
1/5/2015 |
289 |
2776.0 |
NaN |
10030.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
1786.0 |
NaN |
2977.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
| 1 |
1/4/2015 |
288 |
2775.0 |
NaN |
9780.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
1781.0 |
NaN |
2943.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
| 2 |
1/3/2015 |
287 |
2769.0 |
8166.0 |
9722.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
1767.0 |
3496.0 |
2915.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
| 3 |
1/2/2015 |
286 |
NaN |
8157.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
3496.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 4 |
12/31/2014 |
284 |
2730.0 |
8115.0 |
9633.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
1739.0 |
3471.0 |
2827.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 117 |
3/27/2014 |
5 |
103.0 |
8.0 |
6.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
66.0 |
6.0 |
5.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
| 118 |
3/26/2014 |
4 |
86.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
62.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 119 |
3/25/2014 |
3 |
86.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
60.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 120 |
3/24/2014 |
2 |
86.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
59.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 121 |
3/22/2014 |
0 |
49.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
29.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
122 rows × 18 columns
df = pd.read_csv('data/country_timeseries.csv')
df.sample()
|
Date |
Day |
Cases_Guinea |
Cases_Liberia |
Cases_SierraLeone |
Cases_Nigeria |
Cases_Senegal |
Cases_UnitedStates |
Cases_Spain |
Cases_Mali |
Deaths_Guinea |
Deaths_Liberia |
Deaths_SierraLeone |
Deaths_Nigeria |
Deaths_Senegal |
Deaths_UnitedStates |
Deaths_Spain |
Deaths_Mali |
| 115 |
3/29/2014 |
7 |
112.0 |
7.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
70.0 |
2.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
pd.melt(df,id_vars=['Date', 'Day'])
|
Date |
Day |
variable |
value |
| 0 |
1/5/2015 |
289 |
Cases_Guinea |
2776.0 |
| 1 |
1/4/2015 |
288 |
Cases_Guinea |
2775.0 |
| 2 |
1/3/2015 |
287 |
Cases_Guinea |
2769.0 |
| 3 |
1/2/2015 |
286 |
Cases_Guinea |
NaN |
| 4 |
12/31/2014 |
284 |
Cases_Guinea |
2730.0 |
| ... |
... |
... |
... |
... |
| 1947 |
3/27/2014 |
5 |
Deaths_Mali |
NaN |
| 1948 |
3/26/2014 |
4 |
Deaths_Mali |
NaN |
| 1949 |
3/25/2014 |
3 |
Deaths_Mali |
NaN |
| 1950 |
3/24/2014 |
2 |
Deaths_Mali |
NaN |
| 1951 |
3/22/2014 |
0 |
Deaths_Mali |
NaN |
1952 rows × 4 columns
df_melt = pd.melt(df,id_vars=['Date', 'Day'])
df_melt
|
Date |
Day |
variable |
value |
| 0 |
1/5/2015 |
289 |
Cases_Guinea |
2776.0 |
| 1 |
1/4/2015 |
288 |
Cases_Guinea |
2775.0 |
| 2 |
1/3/2015 |
287 |
Cases_Guinea |
2769.0 |
| 3 |
1/2/2015 |
286 |
Cases_Guinea |
NaN |
| 4 |
12/31/2014 |
284 |
Cases_Guinea |
2730.0 |
| ... |
... |
... |
... |
... |
| 1947 |
3/27/2014 |
5 |
Deaths_Mali |
NaN |
| 1948 |
3/26/2014 |
4 |
Deaths_Mali |
NaN |
| 1949 |
3/25/2014 |
3 |
Deaths_Mali |
NaN |
| 1950 |
3/24/2014 |
2 |
Deaths_Mali |
NaN |
| 1951 |
3/22/2014 |
0 |
Deaths_Mali |
NaN |
1952 rows × 4 columns
df_melt.variable
0 Cases_Guinea
1 Cases_Guinea
2 Cases_Guinea
3 Cases_Guinea
4 Cases_Guinea
...
1947 Deaths_Mali
1948 Deaths_Mali
1949 Deaths_Mali
1950 Deaths_Mali
1951 Deaths_Mali
Name: variable, Length: 1952, dtype: object
df_melt.variable.str.split('_')
0 [Cases, Guinea]
1 [Cases, Guinea]
2 [Cases, Guinea]
3 [Cases, Guinea]
4 [Cases, Guinea]
...
1947 [Deaths, Mali]
1948 [Deaths, Mali]
1949 [Deaths, Mali]
1950 [Deaths, Mali]
1951 [Deaths, Mali]
Name: variable, Length: 1952, dtype: object
df_melt['status'] = df_melt.variable.str.split('_').str.get(0)
df_melt['country'] = df_melt.variable.str.split('_').str.get(1)
df_melt.sample(3)
|
Date |
Day |
variable |
value |
status |
country |
| 180 |
8/31/2014 |
162 |
Cases_Liberia |
1698.0 |
Cases |
Liberia |
| 465 |
4/26/2014 |
35 |
Cases_Nigeria |
NaN |
Cases |
Nigeria |
| 64 |
8/11/2014 |
142 |
Cases_Guinea |
510.0 |
Cases |
Guinea |
pd.read_csv('data/weather.csv')
|
id |
year |
month |
element |
d1 |
d2 |
d3 |
d4 |
d5 |
d6 |
... |
d22 |
d23 |
d24 |
d25 |
d26 |
d27 |
d28 |
d29 |
d30 |
d31 |
| 0 |
MX17004 |
2010 |
1 |
tmax |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
27.8 |
NaN |
| 1 |
MX17004 |
2010 |
1 |
tmin |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
14.5 |
NaN |
| 2 |
MX17004 |
2010 |
2 |
tmax |
NaN |
27.3 |
24.1 |
NaN |
NaN |
NaN |
... |
NaN |
29.9 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 3 |
MX17004 |
2010 |
2 |
tmin |
NaN |
14.4 |
14.4 |
NaN |
NaN |
NaN |
... |
NaN |
10.7 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 4 |
MX17004 |
2010 |
3 |
tmax |
NaN |
NaN |
NaN |
NaN |
32.1 |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 5 |
MX17004 |
2010 |
3 |
tmin |
NaN |
NaN |
NaN |
NaN |
14.2 |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 6 |
MX17004 |
2010 |
4 |
tmax |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
36.3 |
NaN |
NaN |
NaN |
NaN |
| 7 |
MX17004 |
2010 |
4 |
tmin |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
16.7 |
NaN |
NaN |
NaN |
NaN |
| 8 |
MX17004 |
2010 |
5 |
tmax |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
33.2 |
NaN |
NaN |
NaN |
NaN |
| 9 |
MX17004 |
2010 |
5 |
tmin |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
18.2 |
NaN |
NaN |
NaN |
NaN |
| 10 |
MX17004 |
2010 |
6 |
tmax |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
30.1 |
NaN |
NaN |
| 11 |
MX17004 |
2010 |
6 |
tmin |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
18.0 |
NaN |
NaN |
| 12 |
MX17004 |
2010 |
7 |
tmax |
NaN |
NaN |
28.6 |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 13 |
MX17004 |
2010 |
7 |
tmin |
NaN |
NaN |
17.5 |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 14 |
MX17004 |
2010 |
8 |
tmax |
NaN |
NaN |
NaN |
NaN |
29.6 |
NaN |
... |
NaN |
26.4 |
NaN |
29.7 |
NaN |
NaN |
NaN |
28.0 |
NaN |
25.4 |
| 15 |
MX17004 |
2010 |
8 |
tmin |
NaN |
NaN |
NaN |
NaN |
15.8 |
NaN |
... |
NaN |
15.0 |
NaN |
15.6 |
NaN |
NaN |
NaN |
15.3 |
NaN |
15.4 |
| 16 |
MX17004 |
2010 |
10 |
tmax |
NaN |
NaN |
NaN |
NaN |
27.0 |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
31.2 |
NaN |
NaN |
NaN |
| 17 |
MX17004 |
2010 |
10 |
tmin |
NaN |
NaN |
NaN |
NaN |
14.0 |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
15.0 |
NaN |
NaN |
NaN |
| 18 |
MX17004 |
2010 |
11 |
tmax |
NaN |
31.3 |
NaN |
27.2 |
26.3 |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
28.1 |
27.7 |
NaN |
NaN |
NaN |
NaN |
| 19 |
MX17004 |
2010 |
11 |
tmin |
NaN |
16.3 |
NaN |
12.0 |
7.9 |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
12.1 |
14.2 |
NaN |
NaN |
NaN |
NaN |
| 20 |
MX17004 |
2010 |
12 |
tmax |
29.9 |
NaN |
NaN |
NaN |
NaN |
27.8 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 21 |
MX17004 |
2010 |
12 |
tmin |
13.8 |
NaN |
NaN |
NaN |
NaN |
10.5 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
22 rows × 35 columns
df = pd.read_csv('data/weather.csv')
df.head(1)
|
id |
year |
month |
element |
d1 |
d2 |
d3 |
d4 |
d5 |
d6 |
... |
d22 |
d23 |
d24 |
d25 |
d26 |
d27 |
d28 |
d29 |
d30 |
d31 |
| 0 |
MX17004 |
2010 |
1 |
tmax |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
27.8 |
NaN |
1 rows × 35 columns
pd.melt(df,
id_vars=['id', 'year', 'month', 'element'],
var_name='day',
value_name='temp')
|
id |
year |
month |
element |
day |
temp |
| 0 |
MX17004 |
2010 |
1 |
tmax |
d1 |
NaN |
| 1 |
MX17004 |
2010 |
1 |
tmin |
d1 |
NaN |
| 2 |
MX17004 |
2010 |
2 |
tmax |
d1 |
NaN |
| 3 |
MX17004 |
2010 |
2 |
tmin |
d1 |
NaN |
| 4 |
MX17004 |
2010 |
3 |
tmax |
d1 |
NaN |
| ... |
... |
... |
... |
... |
... |
... |
| 677 |
MX17004 |
2010 |
10 |
tmin |
d31 |
NaN |
| 678 |
MX17004 |
2010 |
11 |
tmax |
d31 |
NaN |
| 679 |
MX17004 |
2010 |
11 |
tmin |
d31 |
NaN |
| 680 |
MX17004 |
2010 |
12 |
tmax |
d31 |
NaN |
| 681 |
MX17004 |
2010 |
12 |
tmin |
d31 |
NaN |
682 rows × 6 columns
df.columns
Index(['id', 'year', 'month', 'element', 'd1', 'd2', 'd3', 'd4', 'd5', 'd6',
'd7', 'd8', 'd9', 'd10', 'd11', 'd12', 'd13', 'd14', 'd15', 'd16',
'd17', 'd18', 'd19', 'd20', 'd21', 'd22', 'd23', 'd24', 'd25', 'd26',
'd27', 'd28', 'd29', 'd30', 'd31'],
dtype='object')
df_melt = pd.melt(df,
id_vars=['id', 'year', 'month', 'element'],
var_name='day',
value_name='temp')
df_melt.pivot_table(index=['id', 'year', 'month', 'day'],
columns='element',
values='temp')
|
|
|
element |
tmax |
tmin |
| id |
year |
month |
day |
|
|
| MX17004 |
2010 |
1 |
d30 |
27.8 |
14.5 |
| 2 |
d11 |
29.7 |
13.4 |
| d2 |
27.3 |
14.4 |
| d23 |
29.9 |
10.7 |
| d3 |
24.1 |
14.4 |
| 3 |
d10 |
34.5 |
16.8 |
| d16 |
31.1 |
17.6 |
| d5 |
32.1 |
14.2 |
| 4 |
d27 |
36.3 |
16.7 |
| 5 |
d27 |
33.2 |
18.2 |
| 6 |
d17 |
28.0 |
17.5 |
| d29 |
30.1 |
18.0 |
| 7 |
d3 |
28.6 |
17.5 |
| d14 |
29.9 |
16.5 |
| 8 |
d23 |
26.4 |
15.0 |
| d5 |
29.6 |
15.8 |
| d29 |
28.0 |
15.3 |
| d13 |
29.8 |
16.5 |
| d25 |
29.7 |
15.6 |
| d31 |
25.4 |
15.4 |
| d8 |
29.0 |
17.3 |
| 10 |
d5 |
27.0 |
14.0 |
| d14 |
29.5 |
13.0 |
| d15 |
28.7 |
10.5 |
| d28 |
31.2 |
15.0 |
| d7 |
28.1 |
12.9 |
| 11 |
d2 |
31.3 |
16.3 |
| d5 |
26.3 |
7.9 |
| d27 |
27.7 |
14.2 |
| d26 |
28.1 |
12.1 |
| d4 |
27.2 |
12.0 |
| 12 |
d1 |
29.9 |
13.8 |
| d6 |
27.8 |
10.5 |
df_pivot = df_melt.pivot_table(index=['id', 'year', 'month', 'day'],
columns='element',
values='temp')
https://taptorestart.tistory.com/entry/Jupyter-Notebook-%EC%A3%BC%ED%94%BC%ED%84%B0-%EB%85%B8%ED%8A%B8%EB%B6%81-%EB%8B%A8%EC%B6%95%ED%82%A4shortcuts-%EC%A0%95%EB%A6%AC
df_pivot.index
MultiIndex([('MX17004', 2010, 1, 'd30'),
('MX17004', 2010, 2, 'd11'),
('MX17004', 2010, 2, 'd2'),
('MX17004', 2010, 2, 'd23'),
('MX17004', 2010, 2, 'd3'),
('MX17004', 2010, 3, 'd10'),
('MX17004', 2010, 3, 'd16'),
('MX17004', 2010, 3, 'd5'),
('MX17004', 2010, 4, 'd27'),
('MX17004', 2010, 5, 'd27'),
('MX17004', 2010, 6, 'd17'),
('MX17004', 2010, 6, 'd29'),
('MX17004', 2010, 7, 'd3'),
('MX17004', 2010, 7, 'd14'),
('MX17004', 2010, 8, 'd23'),
('MX17004', 2010, 8, 'd5'),
('MX17004', 2010, 8, 'd29'),
('MX17004', 2010, 8, 'd13'),
('MX17004', 2010, 8, 'd25'),
('MX17004', 2010, 8, 'd31'),
('MX17004', 2010, 8, 'd8'),
('MX17004', 2010, 10, 'd5'),
('MX17004', 2010, 10, 'd14'),
('MX17004', 2010, 10, 'd15'),
('MX17004', 2010, 10, 'd28'),
('MX17004', 2010, 10, 'd7'),
('MX17004', 2010, 11, 'd2'),
('MX17004', 2010, 11, 'd5'),
('MX17004', 2010, 11, 'd27'),
('MX17004', 2010, 11, 'd26'),
('MX17004', 2010, 11, 'd4'),
('MX17004', 2010, 12, 'd1'),
('MX17004', 2010, 12, 'd6')],
names=['id', 'year', 'month', 'day'])
df_pivot.columns
Index(['tmax', 'tmin'], dtype='object', name='element')
df_pivot.values
array([[27.8, 14.5],
[29.7, 13.4],
[27.3, 14.4],
[29.9, 10.7],
[24.1, 14.4],
[34.5, 16.8],
[31.1, 17.6],
[32.1, 14.2],
[36.3, 16.7],
[33.2, 18.2],
[28. , 17.5],
[30.1, 18. ],
[28.6, 17.5],
[29.9, 16.5],
[26.4, 15. ],
[29.6, 15.8],
[28. , 15.3],
[29.8, 16.5],
[29.7, 15.6],
[25.4, 15.4],
[29. , 17.3],
[27. , 14. ],
[29.5, 13. ],
[28.7, 10.5],
[31.2, 15. ],
[28.1, 12.9],
[31.3, 16.3],
[26.3, 7.9],
[27.7, 14.2],
[28.1, 12.1],
[27.2, 12. ],
[29.9, 13.8],
[27.8, 10.5]])
df_pivot.reset_index(inplace=True)
df_pivot.values
array([['MX17004', 2010, 1, 'd30', 27.8, 14.5],
['MX17004', 2010, 2, 'd11', 29.7, 13.4],
['MX17004', 2010, 2, 'd2', 27.3, 14.4],
['MX17004', 2010, 2, 'd23', 29.9, 10.7],
['MX17004', 2010, 2, 'd3', 24.1, 14.4],
['MX17004', 2010, 3, 'd10', 34.5, 16.8],
['MX17004', 2010, 3, 'd16', 31.1, 17.6],
['MX17004', 2010, 3, 'd5', 32.1, 14.2],
['MX17004', 2010, 4, 'd27', 36.3, 16.7],
['MX17004', 2010, 5, 'd27', 33.2, 18.2],
['MX17004', 2010, 6, 'd17', 28.0, 17.5],
['MX17004', 2010, 6, 'd29', 30.1, 18.0],
['MX17004', 2010, 7, 'd3', 28.6, 17.5],
['MX17004', 2010, 7, 'd14', 29.9, 16.5],
['MX17004', 2010, 8, 'd23', 26.4, 15.0],
['MX17004', 2010, 8, 'd5', 29.6, 15.8],
['MX17004', 2010, 8, 'd29', 28.0, 15.3],
['MX17004', 2010, 8, 'd13', 29.8, 16.5],
['MX17004', 2010, 8, 'd25', 29.7, 15.6],
['MX17004', 2010, 8, 'd31', 25.4, 15.4],
['MX17004', 2010, 8, 'd8', 29.0, 17.3],
['MX17004', 2010, 10, 'd5', 27.0, 14.0],
['MX17004', 2010, 10, 'd14', 29.5, 13.0],
['MX17004', 2010, 10, 'd15', 28.7, 10.5],
['MX17004', 2010, 10, 'd28', 31.2, 15.0],
['MX17004', 2010, 10, 'd7', 28.1, 12.9],
['MX17004', 2010, 11, 'd2', 31.3, 16.3],
['MX17004', 2010, 11, 'd5', 26.3, 7.9],
['MX17004', 2010, 11, 'd27', 27.7, 14.2],
['MX17004', 2010, 11, 'd26', 28.1, 12.1],
['MX17004', 2010, 11, 'd4', 27.2, 12.0],
['MX17004', 2010, 12, 'd1', 29.9, 13.8],
['MX17004', 2010, 12, 'd6', 27.8, 10.5]], dtype=object)
pd.read_csv('data/billboard.csv')
|
year |
artist |
track |
time |
date.entered |
wk1 |
wk2 |
wk3 |
wk4 |
wk5 |
... |
wk67 |
wk68 |
wk69 |
wk70 |
wk71 |
wk72 |
wk73 |
wk74 |
wk75 |
wk76 |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
87 |
82.0 |
72.0 |
77.0 |
87.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
2000-09-02 |
91 |
87.0 |
92.0 |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2000-04-08 |
81 |
70.0 |
68.0 |
67.0 |
66.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
2000-10-21 |
76 |
76.0 |
72.0 |
69.0 |
67.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
2000-04-15 |
57 |
34.0 |
25.0 |
17.0 |
17.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 312 |
2000 |
Yankee Grey |
Another Nine Minutes |
3:10 |
2000-04-29 |
86 |
83.0 |
77.0 |
74.0 |
83.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 313 |
2000 |
Yearwood, Trisha |
Real Live Woman |
3:55 |
2000-04-01 |
85 |
83.0 |
83.0 |
82.0 |
81.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 314 |
2000 |
Ying Yang Twins |
Whistle While You Tw... |
4:19 |
2000-03-18 |
95 |
94.0 |
91.0 |
85.0 |
84.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 315 |
2000 |
Zombie Nation |
Kernkraft 400 |
3:30 |
2000-09-02 |
99 |
99.0 |
NaN |
NaN |
NaN |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| 316 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
60 |
37.0 |
29.0 |
24.0 |
22.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
317 rows × 81 columns
df = pd.read_csv('data/billboard.csv')
df.sample()
|
year |
artist |
track |
time |
date.entered |
wk1 |
wk2 |
wk3 |
wk4 |
wk5 |
... |
wk67 |
wk68 |
wk69 |
wk70 |
wk71 |
wk72 |
wk73 |
wk74 |
wk75 |
wk76 |
| 109 |
2000 |
Gilman, Billy |
One Voice |
4:07 |
2000-06-17 |
86 |
86.0 |
82.0 |
72.0 |
65.0 |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
1 rows × 81 columns
df.columns
Index(['year', 'artist', 'track', 'time', 'date.entered', 'wk1', 'wk2', 'wk3',
'wk4', 'wk5', 'wk6', 'wk7', 'wk8', 'wk9', 'wk10', 'wk11', 'wk12',
'wk13', 'wk14', 'wk15', 'wk16', 'wk17', 'wk18', 'wk19', 'wk20', 'wk21',
'wk22', 'wk23', 'wk24', 'wk25', 'wk26', 'wk27', 'wk28', 'wk29', 'wk30',
'wk31', 'wk32', 'wk33', 'wk34', 'wk35', 'wk36', 'wk37', 'wk38', 'wk39',
'wk40', 'wk41', 'wk42', 'wk43', 'wk44', 'wk45', 'wk46', 'wk47', 'wk48',
'wk49', 'wk50', 'wk51', 'wk52', 'wk53', 'wk54', 'wk55', 'wk56', 'wk57',
'wk58', 'wk59', 'wk60', 'wk61', 'wk62', 'wk63', 'wk64', 'wk65', 'wk66',
'wk67', 'wk68', 'wk69', 'wk70', 'wk71', 'wk72', 'wk73', 'wk74', 'wk75',
'wk76'],
dtype='object')
pd.melt(df,
id_vars=['year', 'artist', 'track', 'time', 'date.entered'],
var_name='week',
value_name='rating')
|
year |
artist |
track |
time |
date.entered |
week |
rating |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk1 |
87.0 |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
2000-09-02 |
wk1 |
91.0 |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2000-04-08 |
wk1 |
81.0 |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
2000-10-21 |
wk1 |
76.0 |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
2000-04-15 |
wk1 |
57.0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 24087 |
2000 |
Yankee Grey |
Another Nine Minutes |
3:10 |
2000-04-29 |
wk76 |
NaN |
| 24088 |
2000 |
Yearwood, Trisha |
Real Live Woman |
3:55 |
2000-04-01 |
wk76 |
NaN |
| 24089 |
2000 |
Ying Yang Twins |
Whistle While You Tw... |
4:19 |
2000-03-18 |
wk76 |
NaN |
| 24090 |
2000 |
Zombie Nation |
Kernkraft 400 |
3:30 |
2000-09-02 |
wk76 |
NaN |
| 24091 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk76 |
NaN |
24092 rows × 7 columns
df_melt = pd.melt(df,
id_vars=['year', 'artist', 'track', 'time', 'date.entered'],
var_name='week',
value_name='rating')
df_melt
|
year |
artist |
track |
time |
date.entered |
week |
rating |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk1 |
87.0 |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
2000-09-02 |
wk1 |
91.0 |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2000-04-08 |
wk1 |
81.0 |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
2000-10-21 |
wk1 |
76.0 |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
2000-04-15 |
wk1 |
57.0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 24087 |
2000 |
Yankee Grey |
Another Nine Minutes |
3:10 |
2000-04-29 |
wk76 |
NaN |
| 24088 |
2000 |
Yearwood, Trisha |
Real Live Woman |
3:55 |
2000-04-01 |
wk76 |
NaN |
| 24089 |
2000 |
Ying Yang Twins |
Whistle While You Tw... |
4:19 |
2000-03-18 |
wk76 |
NaN |
| 24090 |
2000 |
Zombie Nation |
Kernkraft 400 |
3:30 |
2000-09-02 |
wk76 |
NaN |
| 24091 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk76 |
NaN |
24092 rows × 7 columns
df.shape, df_melt.shape
((317, 81), (24092, 7))
df_melt[ df_melt.track == 'loser']
|
year |
artist |
track |
time |
date.entered |
week |
rating |
df_songs = df_melt[['year', 'artist', 'track', 'time']]
df_songs.shape
(24092, 4)
df_songs.drop_duplicates(inplace=True)
C:\Users\user\AppData\Local\Temp\ipykernel_7456\1127336564.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_songs.drop_duplicates(inplace=True)
df_songs.shape
(317, 4)
df_songs['id']=range(len(df_songs))
C:\Users\user\AppData\Local\Temp\ipykernel_7456\1922217867.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_songs['id']=range(len(df_songs))
df_songs.head()
|
year |
artist |
track |
time |
id |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
0 |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
1 |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2 |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
3 |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
4 |
df_melt.merge(df_songs, on=['year', 'artist', 'track', 'time'])
|
year |
artist |
track |
time |
date.entered |
week |
rating |
id |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk1 |
87.0 |
0 |
| 1 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk2 |
82.0 |
0 |
| 2 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk3 |
72.0 |
0 |
| 3 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk4 |
77.0 |
0 |
| 4 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk5 |
87.0 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 24087 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk72 |
NaN |
316 |
| 24088 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk73 |
NaN |
316 |
| 24089 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk74 |
NaN |
316 |
| 24090 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk75 |
NaN |
316 |
| 24091 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk76 |
NaN |
316 |
24092 rows × 8 columns
df_ratings = df_melt.merge(df_songs, on=['year', 'artist', 'track', 'time'])
df_ratings
|
year |
artist |
track |
time |
date.entered |
week |
rating |
id |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk1 |
87.0 |
0 |
| 1 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk2 |
82.0 |
0 |
| 2 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk3 |
72.0 |
0 |
| 3 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk4 |
77.0 |
0 |
| 4 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
2000-02-26 |
wk5 |
87.0 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 24087 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk72 |
NaN |
316 |
| 24088 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk73 |
NaN |
316 |
| 24089 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk74 |
NaN |
316 |
| 24090 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk75 |
NaN |
316 |
| 24091 |
2000 |
matchbox twenty |
Bent |
4:12 |
2000-04-29 |
wk76 |
NaN |
316 |
24092 rows × 8 columns
df_ratings = df_ratings[['date.entered', 'week', 'rating']]
df_ratings
|
date.entered |
week |
rating |
| 0 |
2000-02-26 |
wk1 |
87.0 |
| 1 |
2000-02-26 |
wk2 |
82.0 |
| 2 |
2000-02-26 |
wk3 |
72.0 |
| 3 |
2000-02-26 |
wk4 |
77.0 |
| 4 |
2000-02-26 |
wk5 |
87.0 |
| ... |
... |
... |
... |
| 24087 |
2000-04-29 |
wk72 |
NaN |
| 24088 |
2000-04-29 |
wk73 |
NaN |
| 24089 |
2000-04-29 |
wk74 |
NaN |
| 24090 |
2000-04-29 |
wk75 |
NaN |
| 24091 |
2000-04-29 |
wk76 |
NaN |
24092 rows × 3 columns
df_songs
|
year |
artist |
track |
time |
id |
| 0 |
2000 |
2 Pac |
Baby Don't Cry (Keep... |
4:22 |
0 |
| 1 |
2000 |
2Ge+her |
The Hardest Part Of ... |
3:15 |
1 |
| 2 |
2000 |
3 Doors Down |
Kryptonite |
3:53 |
2 |
| 3 |
2000 |
3 Doors Down |
Loser |
4:24 |
3 |
| 4 |
2000 |
504 Boyz |
Wobble Wobble |
3:35 |
4 |
| ... |
... |
... |
... |
... |
... |
| 312 |
2000 |
Yankee Grey |
Another Nine Minutes |
3:10 |
312 |
| 313 |
2000 |
Yearwood, Trisha |
Real Live Woman |
3:55 |
313 |
| 314 |
2000 |
Ying Yang Twins |
Whistle While You Tw... |
4:19 |
314 |
| 315 |
2000 |
Zombie Nation |
Kernkraft 400 |
3:30 |
315 |
| 316 |
2000 |
matchbox twenty |
Bent |
4:12 |
316 |
317 rows × 5 columns
import pandas as pd
pd.read_csv('전국_평균_분양가격(2013년_9월부터_2015년_8월까지).csv', encoding = 'cp949')
|
지역 |
2013년12월 |
2014년1월 |
2014년2월 |
2014년3월 |
2014년4월 |
2014년5월 |
2014년6월 |
2014년7월 |
2014년8월 |
... |
2014년11월 |
2014년12월 |
2015년1월 |
2015년2월 |
2015년3월 |
2015년4월 |
2015년5월 |
2015년6월 |
2015년7월 |
2015년8월 |
| 0 |
서울 |
18189 |
17925 |
17925 |
18016 |
18098 |
19446 |
18867 |
18742 |
19274 |
... |
20242 |
20269 |
20670 |
20670 |
19415 |
18842 |
18367 |
18374 |
18152 |
18443 |
| 1 |
부산 |
8111 |
8111 |
9078 |
8965 |
9402 |
9501 |
9453 |
9457 |
9411 |
... |
9208 |
9208 |
9204 |
9235 |
9279 |
9327 |
9345 |
9515 |
9559 |
9581 |
| 2 |
대구 |
8080 |
8080 |
8077 |
8101 |
8267 |
8274 |
8360 |
8360 |
8370 |
... |
8439 |
8253 |
8327 |
8416 |
8441 |
8446 |
8568 |
8542 |
8542 |
8795 |
| 3 |
인천 |
10204 |
10204 |
10408 |
10408 |
10000 |
9844 |
10058 |
9974 |
9973 |
... |
10020 |
10020 |
10017 |
9876 |
9876 |
9938 |
10551 |
10443 |
10443 |
10449 |
| 4 |
광주 |
6098 |
7326 |
7611 |
7346 |
7346 |
7523 |
7659 |
7612 |
7622 |
... |
7752 |
7748 |
7752 |
7756 |
7861 |
7914 |
7877 |
7881 |
8089 |
8231 |
| 5 |
대전 |
8321 |
8321 |
8321 |
8341 |
8341 |
8341 |
8333 |
8333 |
8333 |
... |
8067 |
8067 |
8067 |
8067 |
8067 |
8145 |
8272 |
8079 |
8079 |
8079 |
| 6 |
울산 |
8090 |
8090 |
8090 |
8153 |
8153 |
8153 |
8153 |
8153 |
8493 |
... |
8891 |
8891 |
8526 |
8526 |
8629 |
9380 |
9192 |
9190 |
9190 |
9215 |
| 7 |
경기 |
10855 |
10855 |
10791 |
10784 |
10876 |
10646 |
10266 |
10124 |
10134 |
... |
10356 |
10379 |
10391 |
10355 |
10469 |
10684 |
10685 |
10573 |
10518 |
10573 |
| 8 |
세종 |
7601 |
7600 |
7532 |
7814 |
7908 |
7934 |
8067 |
8067 |
8141 |
... |
8592 |
8560 |
8560 |
8560 |
8555 |
8546 |
8546 |
8671 |
8669 |
8695 |
| 9 |
강원 |
6230 |
6230 |
6230 |
6141 |
6373 |
6350 |
6350 |
6268 |
6268 |
... |
6365 |
6365 |
6348 |
6350 |
6182 |
6924 |
6846 |
6986 |
7019 |
7008 |
| 10 |
충북 |
6589 |
6589 |
6611 |
6625 |
6678 |
6598 |
6587 |
6586 |
6586 |
... |
6724 |
6743 |
6749 |
6747 |
6783 |
6790 |
6805 |
6682 |
6601 |
6603 |
| 11 |
충남 |
6365 |
6365 |
6379 |
6287 |
6552 |
6591 |
6644 |
6805 |
6914 |
... |
6940 |
6989 |
6976 |
6980 |
7161 |
7017 |
6975 |
6939 |
6935 |
6942 |
| 12 |
전북 |
6282 |
6281 |
5946 |
5966 |
6277 |
6306 |
6351 |
6319 |
6436 |
... |
6583 |
6583 |
6583 |
6583 |
6542 |
6551 |
6556 |
6601 |
6750 |
6580 |
| 13 |
전남 |
5678 |
5678 |
5678 |
5696 |
5736 |
5656 |
5609 |
5780 |
5685 |
... |
5768 |
5784 |
5784 |
5833 |
5825 |
5940 |
6050 |
6243 |
6286 |
6289 |
| 14 |
경북 |
6168 |
6168 |
6234 |
6317 |
6412 |
6409 |
6554 |
6556 |
6563 |
... |
6881 |
6989 |
6992 |
6953 |
6997 |
7006 |
6966 |
6887 |
7035 |
7037 |
| 15 |
경남 |
6473 |
6485 |
6502 |
6610 |
6599 |
6610 |
6615 |
6613 |
6606 |
... |
7125 |
7332 |
7592 |
7588 |
7668 |
7683 |
7717 |
7715 |
7723 |
7665 |
| 16 |
제주 |
7674 |
7900 |
7900 |
7900 |
7900 |
7900 |
7914 |
7914 |
7914 |
... |
7724 |
7739 |
7739 |
7739 |
7826 |
7285 |
7285 |
7343 |
7343 |
7343 |
17 rows × 22 columns
first_df = pd.read_csv('전국_평균_분양가격(2013년_9월부터_2015년_8월까지).csv', encoding = 'cp949')
first_df.head(2)
|
지역 |
2013년12월 |
2014년1월 |
2014년2월 |
2014년3월 |
2014년4월 |
2014년5월 |
2014년6월 |
2014년7월 |
2014년8월 |
... |
2014년11월 |
2014년12월 |
2015년1월 |
2015년2월 |
2015년3월 |
2015년4월 |
2015년5월 |
2015년6월 |
2015년7월 |
2015년8월 |
| 0 |
서울 |
18189 |
17925 |
17925 |
18016 |
18098 |
19446 |
18867 |
18742 |
19274 |
... |
20242 |
20269 |
20670 |
20670 |
19415 |
18842 |
18367 |
18374 |
18152 |
18443 |
| 1 |
부산 |
8111 |
8111 |
9078 |
8965 |
9402 |
9501 |
9453 |
9457 |
9411 |
... |
9208 |
9208 |
9204 |
9235 |
9279 |
9327 |
9345 |
9515 |
9559 |
9581 |
2 rows × 22 columns
first_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17 entries, 0 to 16
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역 17 non-null object
1 2013년12월 17 non-null int64
2 2014년1월 17 non-null int64
3 2014년2월 17 non-null int64
4 2014년3월 17 non-null int64
5 2014년4월 17 non-null int64
6 2014년5월 17 non-null int64
7 2014년6월 17 non-null int64
8 2014년7월 17 non-null int64
9 2014년8월 17 non-null int64
10 2014년9월 17 non-null int64
11 2014년10월 17 non-null int64
12 2014년11월 17 non-null int64
13 2014년12월 17 non-null int64
14 2015년1월 17 non-null int64
15 2015년2월 17 non-null int64
16 2015년3월 17 non-null int64
17 2015년4월 17 non-null int64
18 2015년5월 17 non-null int64
19 2015년6월 17 non-null int64
20 2015년7월 17 non-null int64
21 2015년8월 17 non-null int64
dtypes: int64(21), object(1)
memory usage: 3.0+ KB
pd.read_csv('주택도시보증공사_전국_평균_분양가격(2019년_12월).csv', encoding = 'cp949')
|
지역명 |
규모구분 |
연도 |
월 |
분양가격(㎡) |
| 0 |
서울 |
전체 |
2015 |
10 |
5841 |
| 1 |
서울 |
전용면적 60㎡이하 |
2015 |
10 |
5652 |
| 2 |
서울 |
전용면적 60㎡초과 85㎡이하 |
2015 |
10 |
5882 |
| 3 |
서울 |
전용면적 85㎡초과 102㎡이하 |
2015 |
10 |
5721 |
| 4 |
서울 |
전용면적 102㎡초과 |
2015 |
10 |
5879 |
| ... |
... |
... |
... |
... |
... |
| 4330 |
제주 |
전체 |
2019 |
12 |
3882 |
| 4331 |
제주 |
전용면적 60㎡이하 |
2019 |
12 |
NaN |
| 4332 |
제주 |
전용면적 60㎡초과 85㎡이하 |
2019 |
12 |
3898 |
| 4333 |
제주 |
전용면적 85㎡초과 102㎡이하 |
2019 |
12 |
NaN |
| 4334 |
제주 |
전용면적 102㎡초과 |
2019 |
12 |
3601 |
4335 rows × 5 columns
last_df = pd.read_csv('주택도시보증공사_전국_평균_분양가격(2019년_12월).csv', encoding = 'cp949')
last_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
dtypes: int64(2), object(3)
memory usage: 169.5+ KB
last_df.isna().sum()
지역명 0
규모구분 0
연도 0
월 0
분양가격(㎡) 277
dtype: int64
pd.to_numeric(last_df['분양가격(㎡)'])
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\_libs\lib.pyx in pandas._libs.lib.maybe_convert_numeric()
ValueError: Unable to parse string " "
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_4668\3953485802.py in <module>
----> 1 pd.to_numeric(last_df['분양가격(㎡)'])
~\anaconda3\lib\site-packages\pandas\core\tools\numeric.py in to_numeric(arg, errors, downcast)
182 coerce_numeric = errors not in ("ignore", "raise")
183 try:
--> 184 values, _ = lib.maybe_convert_numeric(
185 values, set(), coerce_numeric=coerce_numeric
186 )
~\anaconda3\lib\site-packages\pandas\_libs\lib.pyx in pandas._libs.lib.maybe_convert_numeric()
ValueError: Unable to parse string " " at position 28
from numpy import nan
type(nan)
float
pd.to_numeric(last_df['분양가격(㎡)'],errors='coerce')
0 5841.0
1 5652.0
2 5882.0
3 5721.0
4 5879.0
...
4330 3882.0
4331 NaN
4332 3898.0
4333 NaN
4334 3601.0
Name: 분양가격(㎡), Length: 4335, dtype: float64
last_df['분양가격'] = pd.to_numeric(last_df['분양가격(㎡)'],errors='coerce')
last_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
5 분양가격 3957 non-null float64
dtypes: float64(1), int64(2), object(3)
memory usage: 203.3+ KB
last_df['분양가격']*3.3
0 19275.3
1 18651.6
2 19410.6
3 18879.3
4 19400.7
...
4330 12810.6
4331 NaN
4332 12863.4
4333 NaN
4334 11883.3
Name: 분양가격, Length: 4335, dtype: float64
last_df['평당분양가격'] = last_df['분양가격']*3.3
last_df['평당분양가격'].describe()
count 3957.000000
mean 10685.824488
std 4172.222780
min 6164.400000
25% 8055.300000
50% 9484.200000
75% 11751.300000
max 42002.400000
Name: 평당분양가격, dtype: float64
last_df
|
지역명 |
규모구분 |
연도 |
월 |
분양가격(㎡) |
분양가격 |
평당분양가격 |
| 0 |
서울 |
전체 |
2015 |
10 |
5841 |
5841.0 |
19275.3 |
| 1 |
서울 |
전용면적 60㎡이하 |
2015 |
10 |
5652 |
5652.0 |
18651.6 |
| 2 |
서울 |
전용면적 60㎡초과 85㎡이하 |
2015 |
10 |
5882 |
5882.0 |
19410.6 |
| 3 |
서울 |
전용면적 85㎡초과 102㎡이하 |
2015 |
10 |
5721 |
5721.0 |
18879.3 |
| 4 |
서울 |
전용면적 102㎡초과 |
2015 |
10 |
5879 |
5879.0 |
19400.7 |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 4330 |
제주 |
전체 |
2019 |
12 |
3882 |
3882.0 |
12810.6 |
| 4331 |
제주 |
전용면적 60㎡이하 |
2019 |
12 |
NaN |
NaN |
NaN |
| 4332 |
제주 |
전용면적 60㎡초과 85㎡이하 |
2019 |
12 |
3898 |
3898.0 |
12863.4 |
| 4333 |
제주 |
전용면적 85㎡초과 102㎡이하 |
2019 |
12 |
NaN |
NaN |
NaN |
| 4334 |
제주 |
전용면적 102㎡초과 |
2019 |
12 |
3601 |
3601.0 |
11883.3 |
4335 rows × 7 columns
last_df.규모구분.unique()
array(['전체', '전용면적 60㎡이하', '전용면적 60㎡초과 85㎡이하', '전용면적 85㎡초과 102㎡이하',
'전용면적 102㎡초과'], dtype=object)
last_df.규모구분.str.replace('전용면적','')
0 전체
1 60㎡이하
2 60㎡초과 85㎡이하
3 85㎡초과 102㎡이하
4 102㎡초과
...
4330 전체
4331 60㎡이하
4332 60㎡초과 85㎡이하
4333 85㎡초과 102㎡이하
4334 102㎡초과
Name: 규모구분, Length: 4335, dtype: object
last_df['전용면적'] = last_df.규모구분.str.replace('전용면적','')
last_df['전용면적'] = last_df['전용면적'].str.replace('초과','~')
last_df['전용면적'] = last_df['전용면적'].str.replace('이하','')
last_df['전용면적'] = last_df['전용면적'].str.replace(' ','').str.strip()
last_df
|
지역명 |
규모구분 |
연도 |
월 |
분양가격(㎡) |
분양가격 |
평당분양가격 |
전용면적 |
| 0 |
서울 |
전체 |
2015 |
10 |
5841 |
5841.0 |
19275.3 |
전체 |
| 1 |
서울 |
전용면적 60㎡이하 |
2015 |
10 |
5652 |
5652.0 |
18651.6 |
60㎡ |
| 2 |
서울 |
전용면적 60㎡초과 85㎡이하 |
2015 |
10 |
5882 |
5882.0 |
19410.6 |
60㎡~85㎡ |
| 3 |
서울 |
전용면적 85㎡초과 102㎡이하 |
2015 |
10 |
5721 |
5721.0 |
18879.3 |
85㎡~102㎡ |
| 4 |
서울 |
전용면적 102㎡초과 |
2015 |
10 |
5879 |
5879.0 |
19400.7 |
102㎡~ |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 4330 |
제주 |
전체 |
2019 |
12 |
3882 |
3882.0 |
12810.6 |
전체 |
| 4331 |
제주 |
전용면적 60㎡이하 |
2019 |
12 |
NaN |
NaN |
NaN |
60㎡ |
| 4332 |
제주 |
전용면적 60㎡초과 85㎡이하 |
2019 |
12 |
3898 |
3898.0 |
12863.4 |
60㎡~85㎡ |
| 4333 |
제주 |
전용면적 85㎡초과 102㎡이하 |
2019 |
12 |
NaN |
NaN |
NaN |
85㎡~102㎡ |
| 4334 |
제주 |
전용면적 102㎡초과 |
2019 |
12 |
3601 |
3601.0 |
11883.3 |
102㎡~ |
4335 rows × 8 columns
last_df.columns
Index(['지역명', '규모구분', '연도', '월', '분양가격(㎡)', '분양가격', '평당분양가격', '전용면적'], dtype='object')
last_df.drop(columns=['규모구분', '분양가격(㎡)'],inplace=True)
last_df
|
지역명 |
연도 |
월 |
분양가격 |
평당분양가격 |
전용면적 |
| 0 |
서울 |
2015 |
10 |
5841.0 |
19275.3 |
전체 |
| 1 |
서울 |
2015 |
10 |
5652.0 |
18651.6 |
60㎡ |
| 2 |
서울 |
2015 |
10 |
5882.0 |
19410.6 |
60㎡~85㎡ |
| 3 |
서울 |
2015 |
10 |
5721.0 |
18879.3 |
85㎡~102㎡ |
| 4 |
서울 |
2015 |
10 |
5879.0 |
19400.7 |
102㎡~ |
| ... |
... |
... |
... |
... |
... |
... |
| 4330 |
제주 |
2019 |
12 |
3882.0 |
12810.6 |
전체 |
| 4331 |
제주 |
2019 |
12 |
NaN |
NaN |
60㎡ |
| 4332 |
제주 |
2019 |
12 |
3898.0 |
12863.4 |
60㎡~85㎡ |
| 4333 |
제주 |
2019 |
12 |
NaN |
NaN |
85㎡~102㎡ |
| 4334 |
제주 |
2019 |
12 |
3601.0 |
11883.3 |
102㎡~ |
4335 rows × 6 columns
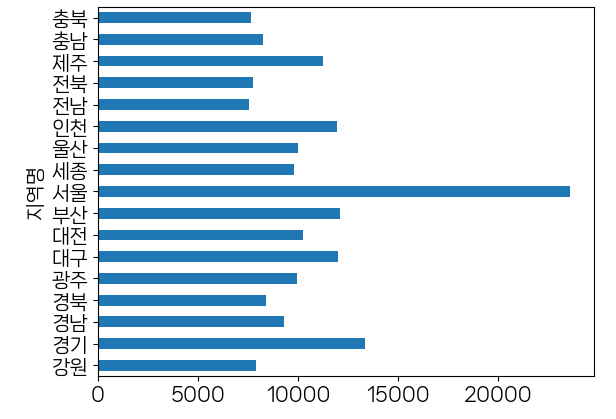
last_df.groupby(['지역명'])['평당분양가격'].mean()
지역명
강원 7890.750000
경기 13356.895200
경남 9268.778138
경북 8376.536515
광주 9951.535821
대구 11980.895455
대전 10253.333333
부산 12087.121200
서울 23599.976400
세종 9796.516456
울산 10014.902013
인천 11915.320732
전남 7565.316532
전북 7724.235484
제주 11241.276712
충남 8233.651883
충북 7634.655600
Name: 평당분양가격, dtype: float64
last_df.groupby(['지역명'])['평당분양가격'].mean().plot(kind='bar')
<AxesSubplot:xlabel='지역명'>

last_df.groupby(['지역명'])['평당분양가격'].mean().plot(kind='barh')
<AxesSubplot:ylabel='지역명'>
last_df.groupby(['전용면적'])['평당분양가격'].mean()
전용면적
102㎡~ 11517.705634
60㎡ 10375.137421
60㎡~85㎡ 10271.040071
85㎡~102㎡ 11097.599573
전체 10276.086207
Name: 평당분양가격, dtype: float64
last_df.groupby(['전용면적','지역명'])['평당분양가격'].mean()
전용면적 지역명
102㎡~ 강원 8311.380000
경기 14771.790000
경남 10358.363265
경북 9157.302000
광주 11041.532432
...
전체 전남 7283.562000
전북 7292.604000
제주 10784.994000
충남 7815.324000
충북 7219.014000
Name: 평당분양가격, Length: 85, dtype: float64
last_df.groupby(['전용면적','지역명'])['평당분양가격'].mean().reset_index()
|
전용면적 |
지역명 |
평당분양가격 |
| 0 |
102㎡~ |
강원 |
8311.380000 |
| 1 |
102㎡~ |
경기 |
14771.790000 |
| 2 |
102㎡~ |
경남 |
10358.363265 |
| 3 |
102㎡~ |
경북 |
9157.302000 |
| 4 |
102㎡~ |
광주 |
11041.532432 |
| ... |
... |
... |
... |
| 80 |
전체 |
전남 |
7283.562000 |
| 81 |
전체 |
전북 |
7292.604000 |
| 82 |
전체 |
제주 |
10784.994000 |
| 83 |
전체 |
충남 |
7815.324000 |
| 84 |
전체 |
충북 |
7219.014000 |
85 rows × 3 columns
data = last_df.groupby(['전용면적','지역명'])['평당분양가격'].mean().reset_index()
data.round()
|
전용면적 |
지역명 |
평당분양가격 |
| 0 |
102㎡~ |
강원 |
8311.0 |
| 1 |
102㎡~ |
경기 |
14772.0 |
| 2 |
102㎡~ |
경남 |
10358.0 |
| 3 |
102㎡~ |
경북 |
9157.0 |
| 4 |
102㎡~ |
광주 |
11042.0 |
| ... |
... |
... |
... |
| 80 |
전체 |
전남 |
7284.0 |
| 81 |
전체 |
전북 |
7293.0 |
| 82 |
전체 |
제주 |
10785.0 |
| 83 |
전체 |
충남 |
7815.0 |
| 84 |
전체 |
충북 |
7219.0 |
85 rows × 3 columns
data.round(-1)
|
전용면적 |
지역명 |
평당분양가격 |
| 0 |
102㎡~ |
강원 |
8310.0 |
| 1 |
102㎡~ |
경기 |
14770.0 |
| 2 |
102㎡~ |
경남 |
10360.0 |
| 3 |
102㎡~ |
경북 |
9160.0 |
| 4 |
102㎡~ |
광주 |
11040.0 |
| ... |
... |
... |
... |
| 80 |
전체 |
전남 |
7280.0 |
| 81 |
전체 |
전북 |
7290.0 |
| 82 |
전체 |
제주 |
10780.0 |
| 83 |
전체 |
충남 |
7820.0 |
| 84 |
전체 |
충북 |
7220.0 |
85 rows × 3 columns
pd.pivot_table(last_df,index=['전용면적','지역명'],values=['평당분양가격']).reset_index().round()
|
전용면적 |
지역명 |
평당분양가격 |
| 0 |
102㎡~ |
강원 |
8311.0 |
| 1 |
102㎡~ |
경기 |
14772.0 |
| 2 |
102㎡~ |
경남 |
10358.0 |
| 3 |
102㎡~ |
경북 |
9157.0 |
| 4 |
102㎡~ |
광주 |
11042.0 |
| ... |
... |
... |
... |
| 80 |
전체 |
전남 |
7284.0 |
| 81 |
전체 |
전북 |
7293.0 |
| 82 |
전체 |
제주 |
10785.0 |
| 83 |
전체 |
충남 |
7815.0 |
| 84 |
전체 |
충북 |
7219.0 |
85 rows × 3 columns