
custom trainer class를 만드는 이유
우리의 데이터는 3개의 레이블을 가지고 있으며, 각각의 레이블의 비율이 약 87:11:2인 비대칭 데이터이다.
일반적인 방법으로 학습을 하면 소수인 데이터에 대한 예측이 잘 안 될 수 있으므로 특별한 방법을 쓰기로 했다. (근데 왜 학습이 잘 안되나요? 라는 질문을 받으면 뭐라고 답해야 할지 잘 모르겠네)
Imbalanced Dataset Sampler
첫 번째 방법은 Imbalanced Dataset Sampler다.
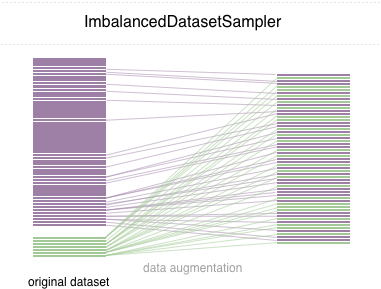
원리는 해당 깃허브의 이 사진이 잘 설명해주고 있다. 데이터를 적절히 언더샘플링, 오버샘플링하여 원래는 비대칭 데이터인 것이, 학습을 할 때에는 같은 비율인 것으로 인식되게 해주는 것이다.
PyPI에 등록되지 않아 직접 설치해야 한다.
Self-adjusting Dice Loss
두 번째 방법은 Self-adjusting Dice Loss다.
논문에 따르면 로스를 계산할 때 이걸 사용한 것만으로도 비대칭 데이터에 대한 성능이 좋아졌다고 한다.
sadice 패키지를 설치하는 것으로 사용할 수 있다.
pip install sadice코드 구현
transformers 버전은 4.10.0이다.
필요한 것을 임포트한다. torchsampler는 직접 다운받아서 프로젝트 폴더에 넣어주었다.
from sadice import SelfAdjDiceLoss
from torch.utils.data import DataLoader
from transformers import Trainer
from torchsampler import ImbalancedDatasetSamplerhttps://huggingface.co/transformers/main_classes/trainer.html
Trainer에 대해 설명하는 해당 문서에서 커스텀 trainer를 만드려면 Trainer 클래스를 상속받아 필요한 부분만 따로 작성하라고 한다.
ImbalancedDatasetSampler를 사용하는 trainer
첫 번째는 ImbalancedDatasetSampler를 사용하는 trainer이다.
class ImbalancedSamplerTrainer(Trainer):
def get_train_dataloader(self) -> DataLoader:
train_dataset = self.train_dataset
def get_label(dataset):
return dataset["labels"]
train_sampler = ImbalancedDatasetSampler(
train_dataset, callback_get_label=get_label
)
return DataLoader(
train_dataset,
batch_size=self.args.train_batch_size,
sampler=train_sampler,
collate_fn=self.data_collator,
drop_last=self.args.dataloader_drop_last,
num_workers=self.args.dataloader_num_workers,
pin_memory=self.args.dataloader_pin_memory,
)Trainer 클래스의 소스코드에서 get_train_dataloader를 복붙해온 뒤, 필요한 부분만 바꿨다.
원본 클래스는 입력으로 들어온 데이터셋의 클래스에 따라 유동적으로 대응하게 되어있으나, 나는 어차피 입력으로 들어올 데이터셋은 dataset.Dataset일 것이라는 전제 하에 작성하였다. 저번 글에서 만든 데이터셋만 쓸 예정이기 때문에. 다른 데이터셋에 대해 이걸 사용하려고 하면 에러가 날 것.
Dice Loss를 사용하는 trainer
두 번째는 SelfAdjDiceLoss를 사용하는 트레이너이다.
https://huggingface.co/transformers/main_classes/trainer.html
이 페이지에 친절하게도 예제가 있어서 쉽게 따라할 수 있었다.
class TrainerWithDiceLoss(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
criterion = SelfAdjDiceLoss()
loss = criterion(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else losstransformers의 모든 모델은 forward연산에서 정해진 로스 함수로 로스를 계산해서 로스와 로짓 값과 기타 등등을 함께 반환한다. trainer는 기본적으로 각 모델이 forward에서 계산한 로스를 사용하기 때문에, 커스텀 로스를 사용하려면 compute_loss에 계산하는 걸 넣어줘야 한다. (기본값은 regression 문제라면 MSELoss, single-label classification 문제라면 CrossEntropyLoss, multi-label classification 문제라면 BCEWithLogitsLoss이다.)
sadice 패키지의 SelfAdjDiceLoss는 single-label classification 문제에서만 사용할 수 있게 구현되어 있다. 그래서 내가 구현한 TrainerWithDiceLoss도 single-label classification에서만 사용할 수 있다. 어차피 우리 프로젝트도 single-label classification이기 때문에 상관없었다.
전체 코드
이번엔 더 특별한 것은 없다.
from sadice import SelfAdjDiceLoss
from torch.utils.data import DataLoader
from transformers import Trainer
from torchsampler import ImbalancedDatasetSampler
class ImbalancedSamplerTrainer(Trainer):
def get_train_dataloader(self) -> DataLoader:
train_dataset = self.train_dataset
def get_label(dataset):
return dataset["labels"]
train_sampler = ImbalancedDatasetSampler(
train_dataset, callback_get_label=get_label
)
return DataLoader(
train_dataset,
batch_size=self.args.train_batch_size,
sampler=train_sampler,
collate_fn=self.data_collator,
drop_last=self.args.dataloader_drop_last,
num_workers=self.args.dataloader_num_workers,
pin_memory=self.args.dataloader_pin_memory,
)
class TrainerWithDiceLoss(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
criterion = SelfAdjDiceLoss()
loss = criterion(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else lossDice Loss를 사용하여 학습해보니, train과 validate 단계에서 어떤 특정한 수치 이하로 잘 내려가지 않는 특징을 보여주었다.
하지만 ImbalancedDatasetSampler를 사용한 쪽이 F1 score 기준으로 0.05정도 성능이 좋게 나와서 Dice Loss 트레이너는 자연스럽게 안쓰게 되었다. 둘 다 써보기엔 시간이 없다...
