강화학습
1.Reinforcement Learning 개념 및 기초

강화학습 개념 정리: 단단한 강화학습, 단단한 심층 강화학습 내용 기반
2023년 7월 12일
2.REINFORCE 알고리즘

이번 포스트에서는 REINFORCE 알고리즘을 학습한다. REINFORCE은 목적함수를 따라 정책 경사를 계산하여 정책을 결정하는 파라미터를 최적화하는 방법으로 먼저 목적함수는 다음과 같이 궤적에 대한 이득의 기댓값으로 정의한다. $$ J(\pi\theta) = E
2023년 7월 20일
3.SARSA 알고리즘
SARSA 알고리즘은 앞에서 학습한 REINFORCE 알고리즘(정책경사 사용))과는 달리 가치 함수를 학습하는 알고리즘이다. SARSA 알고리즘에서는 $Q^\pi(s,a)$를 학습하며, 심층신경망을 사용할 경우에는 신경망이 이를 근사하게 된다. 가치함수 중에서도 상태
2023년 8월 16일
4.DQN 알고리즘
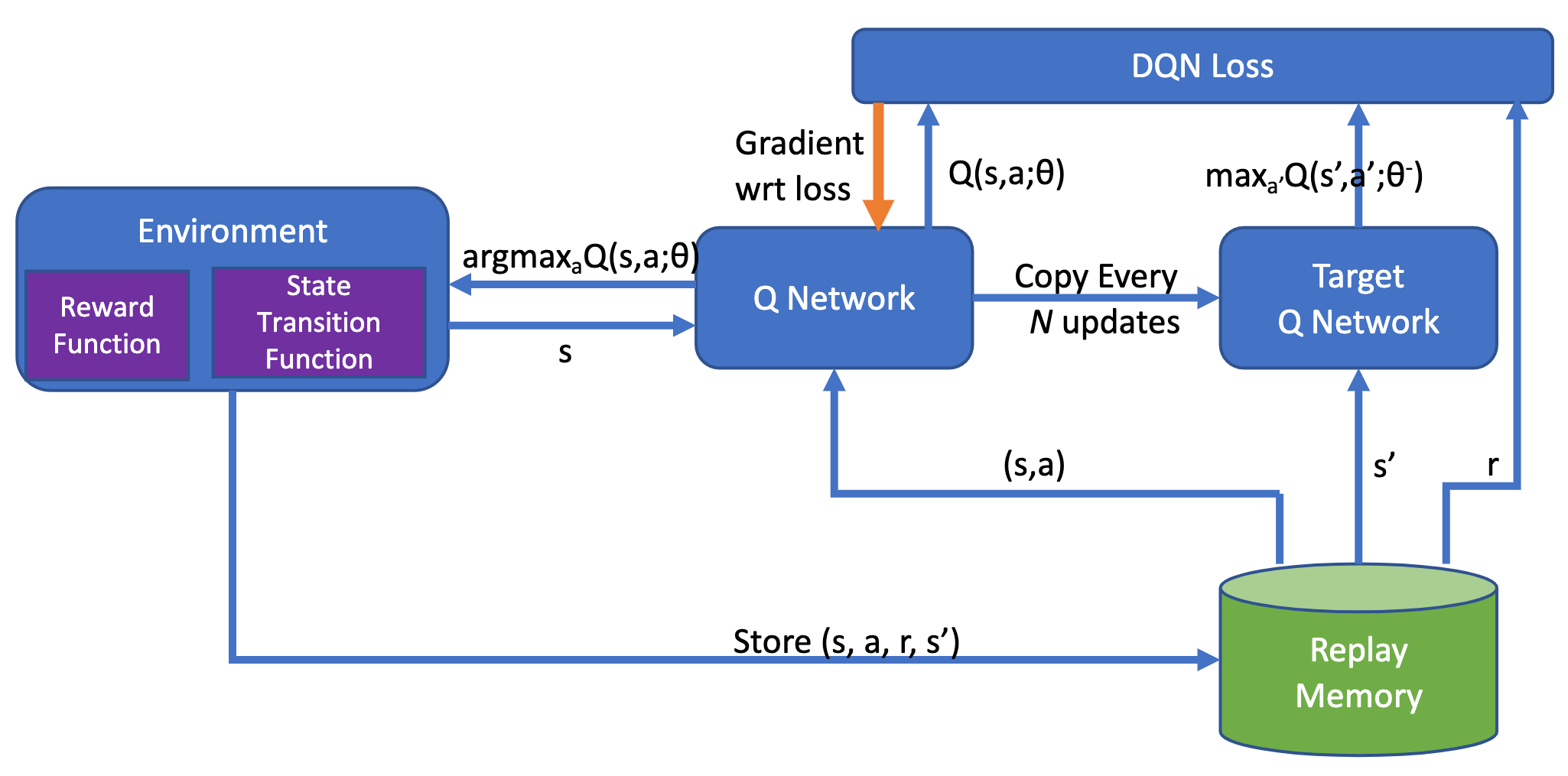
2023년 9월 6일