심층 Q 네트워크(DQN, Deep Q Network)는 SARSA와 마찬가지로 Q 함수를 근사하는 가치 기반 시간차 알고리즘으로 현재 정책에 대한 Q 함수를 학습하는 SARSA와는 다르게 최적 Q 함수를 학습한다. 앞선 글에서 각 알고리즘의 타겟 Q 함수를 다음과 같이 구하였다.
여기서 DQN과 SARSA의 가장 큰 차이점을 알 수 있는데, 이는 DQN이 SARSA와 달리 비활성정책 알고리즘이라는 것이다. 비활성정책 알고리즘은 향상시키고자 하는 목표 정책과 데이터를 수집하기위한 정책을 분리할 수 있으며, 이를 통해 SARSA에 비해 굉장이 높은 표본 효율성(sample efficiency)을 얻을 수 있다.
DQN의 비활성정책 속성을 나타내는 부분은 으로, 향상하고자 하는 정책이 , 데이터 수집 시에 사용된 정책이 라고 했을 때, SARSA와 달리 기대값을 풀기 위해 실제로 취득된 데이터를 사용하는 것이 아니라 향상시키고자 하는 정책 에 대한 최대값을 취한다. 즉, 데이터 취득 단계에서 state 에서 선택된 행동 가 타겟 Q 함수 계산 시에 사용되지 않기 때문에 데이터 수집 정책 가 업데이트에 영향을 주지 않는다.
DQN 또한 SARSA에서와 비슷하게 데이터 수집 시에 탐험-활용 사이의 균형을 잘 맞추어야 하며, 상태-행동 공간이 아주 크다면 모든 (s,a) 쌍을 경험하기 어렵기 때문에 심층 신경망 등의 함수 근사를 사용하게 된다. 다만 심층 신경망의 일반화 성능에도 한계가 있어 모든 (s,a) 쌍에 대한 정확한 Q 함수 값을 근사하는 것을 기대하기는 어렵다. 따라서 (s,a) 공간 내에서 좋은 정책이 자주 경험할 것 같은 상태와 행동에 집중하여 학습하여야 한다. 현재 Q 함수에 대한 탐욕적 행동이 현재의 가장 좋은 정책이므로 데이터 수집 또한 비슷한 분포를 가지고 있어야 학습이 잘 진행될 것이며, 이를 위해 이전에 학습했던 엡실론 탐욕적 정책이나 볼츠만 정책을 사용할 수 있다.
엡실론 탐욕적 정책 특정 확률 에 따라 무작위 행동을 하거나 현재 Q 함수에 대한 탐욕적 행동을 한다. 볼츠만 정책은 이와는 달리 행동의 상대적인 Q 가치를 이용하여 행동을 선택하며, 현재 상태 에서 Q 가치를 최대화하는 행동 가 가장 많이 선택되지만 그 다음으로 높은 Q 가치를 갖는 행동들도 더러 선택될 것이며, 낮은 Q 가치를 갖는 행동은 거의 선택되지 않을 것이다. 따라서 좀 더 유망한 행동을 탐험하는 데 집중하는 효과를 얻을 수 있다.
볼츠만 정책을 만들기 위하여 다음과 같이 Q 함수에 소프트맥스 함수를 적용하고, 파라미터 를 통해 확률분포의 균일한 정도를 조절한다.
그림 1. 파라미터 의 효과
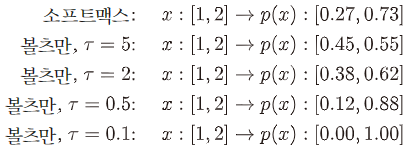
그림 2. 엡실론 탐욕적 정책과 볼츠만 정책의 비교
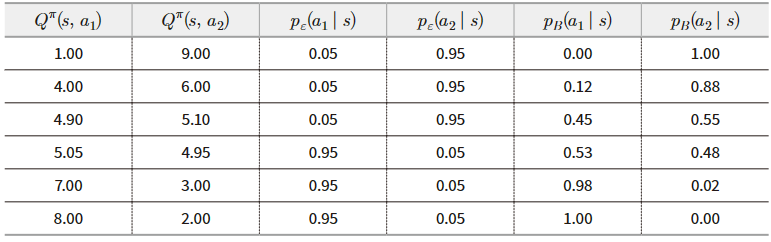
그림2에서는 엡실론 탐욕적 정책과 볼츠만 정책의 차이점을 볼 수 있는데, 극단적으로 두 행동 가치가 5.05, 4.95와 같이 거의 비슷하더라도 엡실론 탐욕적 정책에서는 조금이라도 높은 행동만 많이 선택되는 반면, 볼츠만 정책에서는 골고루 선택된다. 이렇듯 볼츠만 정책은 엡실론 탐욕적 정책보다 안정적인 학습을 하도록 돕지만, 가끔씩 가장 좋은 행동이 현재의 가치 함수에서는 낮은 값을 보이는 등의 상황에서는 좋은 행동이 선택될 확률이 매우 낮아지기 때문에 지역적 최솟값에 빠질 수 있고, 파라미터 를 학습 초기에 큰 값을 갖게 함으로써 해결할 수 있다.
다음으로 DQN의 높은 표본 효율성(sample efficiency)은 경험 재현(experience reply)를 통해 얻을 수 있다. 일반적으로 활성 정책 알고리즘의 경우 현재 정책에 따라 수집된 데이터만을 업데이트에 활용할 수 있으며, 업데이트를 하고 나서는 해당 데이터를 모두 버려야한다. 이는 매우 비효율적이며, 특히 신경망이 예측하는 Q 가치 과 사이의 차이가 클 경우 여러 번 업데이트 해야할 경우도 생기는데 이러한 작업이 불가능하다. 그리고 업데이트를 위해 사용되는 데이터는 하나의 에피소드에서 취득되고 미래 상태와 보상은 이전 상태와 행동에 따라 결정되기 때문에 데이터끼리 매우 밀접하게 연관되어 있어 파라미터 업데이트의 분산이 커질 수 있다.
경험 재현(experience reply)은 이러한 문제를 아주 간단하게 해결한다. DQN에서는 업데이트를 위해 (s,a,r,s')의 데이터가 필요하고, 이를 데이터 수집 정책을 통해 수집하면서 메모리에 저장해 놓는 것이다. 일반적으로 메모리의 크기는 10,000개에서 1,000,000정도의 데이터 튜플을 저장할 수 있으며, 학습 시에는 이러한 메모리에서 적은 갯수의 데이터 묶음(batch)를 무작위로 뽑아서 손실함수를 계산하고 업데이트에 사용한다. 이러한 방법을 사용할 경우 메모리에 다양한 에피소드, 정책 하에서 수집된 경험이 저장되어 있기 때문에 데이터 간 연관성이 적어져 업데이트의 분산이 줄어들고, 데이터 효율이 증가한다. 만약 메모리가 꽉찬다면, 먼저 들어온 데이터를 지우고 새로운 데이터를 저장하며, 이를 통해 최근에 수집된 경험에 집중 할 수 있도록 한다. 추가적으로 데이터 선택 및 삭제를 무작위로 하는 것이 아니라 어떤 score을 기반으로 수행하는 "Prioritized Experience Replay" 방법 또한 많이 사용된다.
그림 3. DQN 의사코드

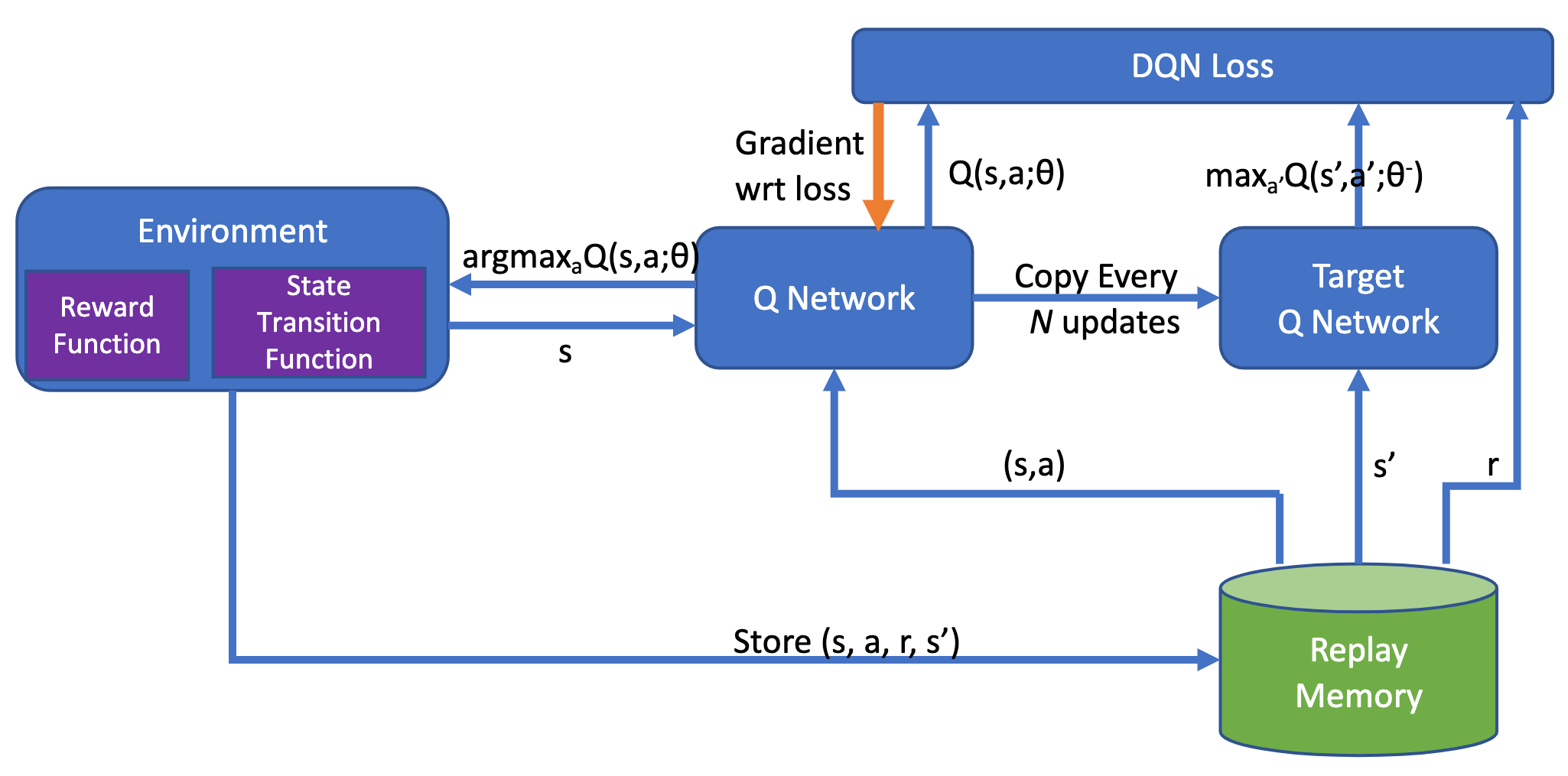
그림 4. DQN의 파이프라인