기본 구성 요소
가장 흔한 2가지 컴퓨터 구조는 폰 노이만 구조와 하버드 구조이다.
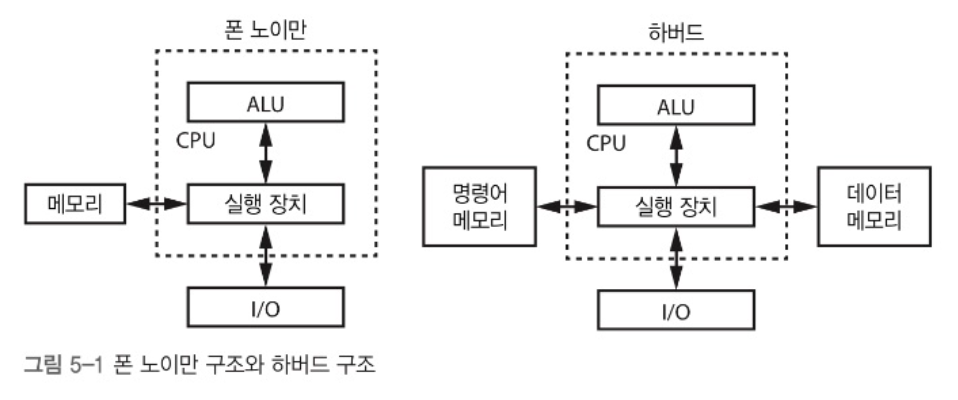
이 둘의 차이는 메모리 배열이다.
- 폰 노이만 : 명령어와 데이터를 동시에 가져올 수 없다(데이터 버스와 주소 버스가 하나).
- 하버그 구조 : 동시에 가져올 수 있어 빠르지만 두 번재 메모리를 처리하기 위한 별도의 버스 필요
프로세스 코어
위 그림은 CPU가 1개뿐이다. CPU는 ALU, 레지스터, 실행 장치의 조합이다.
멀티프로세서 시스템을 통해 단일 CPU보다 훨씬 더 좋은 성능을 얻어낼 수 있다. 하지만 여러 CPU를 활용할 수 있도록 프로그램을 병렬화(parallelized)하는 문제가 매우 어렵다.
반도체 회로 크기가 줄면서 비용이 낮아졌다. 따라서, CPU를 더 빠르게 만듦으로써 더 나은 성능을 달성할 수 있었다. 하지만, 이는 전력 장벽(power wall)에 부딫힌다. 열로 인해 회로를 소형화하며 고성능화하기가 어려워졌다.
작아진 회로 크기를 활용한 새로운 해결책이 나옴으로써 기존 CPU의 정의가 바뀌었다. 예전 CPU 구조를 지금은 프로세서 코어(processor core)라 부른다. 이러한 코어가 여러 개 들어가는 멀티코어(multicore) 프로세서가 일반적으로 쓰인다.
마이크로 프로세서와 마이크로컴퓨터
마이크로 프로세서
- 메모리와 I/O가 프로세서 코어와 다른 패키지에 있는 경우
- 큰 시스템이 들어가는 부품에 사용된다.
마이크로컴퓨터
- 모든 요소가 한 패키지에 있는 경우
- 단일 칩으로 구성된 작은 컴퓨터(ex. 식기세척기)이다.
프로시저, 서브루틴, 함수
하기 싫은 일이 있으면 엔지니어들은 자신을 대신해 줄 무언가를 만든다. 심지어 이것을 만드는데 드는 노력이 더 많음에도 불구하고 이를 감행한다.
프로그래머들이 피하고 싶어하는 일 중 대표적으로 중복 코드 작성이 있다. 이를 줄이면 코드가 메모리를 덜 차지하고, 코드에 버그가 있는 경우 여러 군데를 모두 조회하지 않고 한 군데만 고치면 된다는 장점이 있다.
함수(function 또는 프로시저, 서브루틴)는 코드를 재사용(reuse)하는 주요 수단이다. 프로그래밍에서 함수 정의 및 호출의 과정이 컴퓨터내에서 어떻게 작동하는지 알아보자.
함수를 호출하면 함수를 실행하고 다시 원래 자리로 돌아올 방법이 필요하다. 원래 자리로 돌아오기 위해선 어디서 함수를 호출했는지를 기억해야 한다. 이 위치는 바로 프로그램 카운터(PC) 값이다.
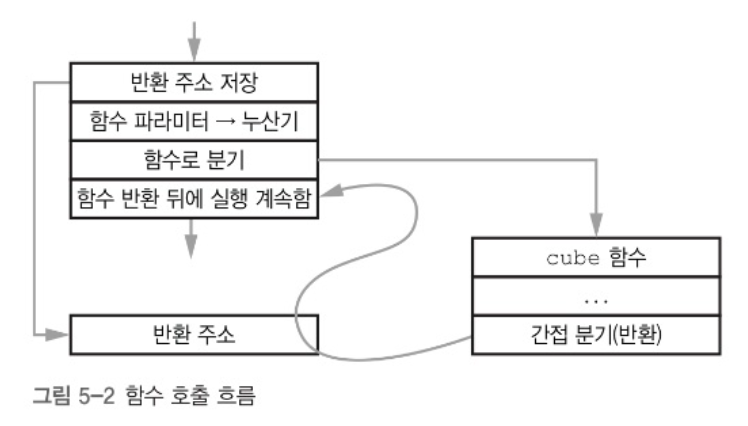
이 과정에는 상당히 많은 작업이 필요하다. 따라서 대부분 기계는 이런 과정을 돕는 명령어들을 제공한다. 예를 들어, BL이라는 명령어는 함수로 호출하는 명령어와 현재 명령어의 다음 위치(PC + 4)를 저장하는 명령어를 하나로 합친 것이다.
스택
함수가 자기 자신을 호출하는 재귀 형태도 존재한다. 대표적으로 JPEG 압축을 사용해 사진 크기를 감소시키는 경우가 있다.
재귀적 분할(recursive subdivision)을 사용해 압축을 해보자. 과정은 다음과 같다
- 모든 픽셀을 네 부분을 나누고, 각 부분을 검사한다.
- 이 과정을 1픽셀짜리 조각이 생길 때 까지 계속한다.
아래 그림은 이를 의사코드(pseudocode)로 표현한 subdivide 함수다.

subdivide함수는 정사각형의 왼쪽 아래 꼭짓점의x,y좌표와 크기 (size)를 파라미터로 받는다.
아래 그림은 이 함수를 통해 이미지 분할하는 과정을 도식화한다.
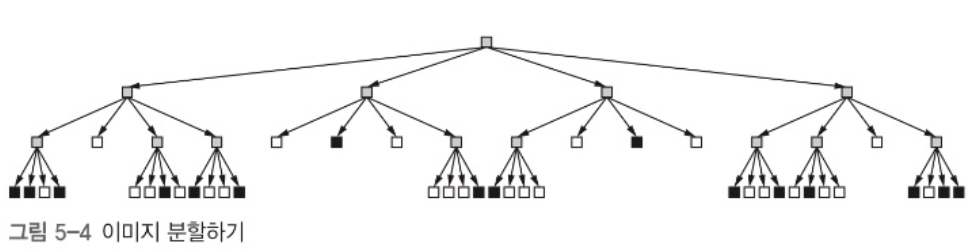
이 구조를 트리(tree) 또는 (수학에서는) 유향 비순환 그래프(DAG, directed acyclic graph)라 부른다.
재귀 함수가 제대로 작동하려면 반혼 주소를 여럿 저장할 수 있어야 한다. 그리고, 함수에서 호출 지점으로 반환할 때 저장된 주소 중 어떤 주소를 사용할지 결정할 수 있어야 한다.
이미지를 분할하기 위해 subdivide 함수를 호출할 때 발생하는 패턴을 살펴보자.
트리 아래로 내려갈 수 있으면 계속 내려가고 더 이상 내려갈 수 없다면 옆으로 간다. 이러한 순회 방식을 깊이 우선 순회라 한다.
한편, 옆에를 먼저 방문 후 더 이상 옆으로 갈 수 없을 때 아래로 가는 방식을 너비 우선 탐색이라 한다.
트리에서 한 수준을 내려갈 때마다 돌아올 위치를 기억해야 하는데, 일단 원래 위치로 돌아오고 나면 저장했던 위치는 필요 없어진다.
필요한 것은 쌓아둔 접시 더미 같은 역할을 할 수 있는 장치다. 함수 호출 시 반환 주소를 접시에 담아 쌓아놓고, 돌아올 때는 접시 더미의 맨 위의 접시에 내용을 확인하여 반환 주소를 결정 후 접시를 제거한다. 이러한 구조를 스택(Stack) 또는 LIFO 구조라 한다.
스택에 더 이상 들어갈 공간이 없는 경우를 스택 오버플로라 하고, 비어있는 스택에 접근하는 경우를 스택 언더플로라 한다.
이러한 스택은 매우 중요한 역할을 하므로 대부분의 컴퓨터 하드웨어는 이를 지원한다. 이런 지원에는 소프트웨어로 스택 오버플로를 일일히 검사하지 않게 해주는 한계 레지스터(limit register)가 있다.
스택은 단지 반환 주소를 저장하기 위한 수단이 아니다. subdivide 함수는 성능 향상을 위해 이미지의 절반 크기를 계산에 지역 변수에 넣고 이 지역 변수에 들어 있는 값을 8번 사용한다. 함수를 호출할 때 이 값들을 그냥 덮어쓰면 안된다. 지역 변수도 스택에 저장해야한다는 뜻이다.
이렇게 하면 각각 함수의 호출이 서로 독립적이게 된다. 이 때, 스택에 저장되는 지역 변수나 반환 주소들을 묶어 스택 프레임(stack frame)이라 한다.
인터럽트
부엌에서 쿠키를 만들기 위해 레시피를 보며 반죽을 섞고 있다. 레시피는 단지 나를 위한 프로그램에 불과하다.
이 상황에서 누군가가 우리집을 방문한 경우를 알 필요가 있다. 이런 활동을 순서도(flowchart)로 표현할 수 있다. 순서도는 작업이 이뤄지는 순서를 표현하는 다이어그램이다.
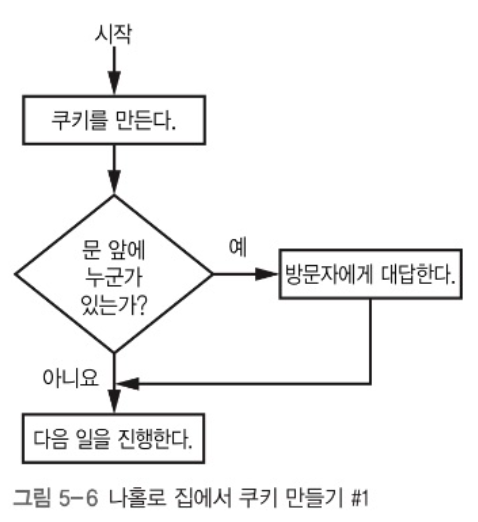
쿠키를 만드는 과정에서 한 번만 문 앞에 누가 있는지를 확인한다면 곤란할 것이다. 중요한 소포가 온 경우엔 그 즉시 문앞으로 가야 할 것이다. 이를 고려하여 순서도를 다시 만들어보자.
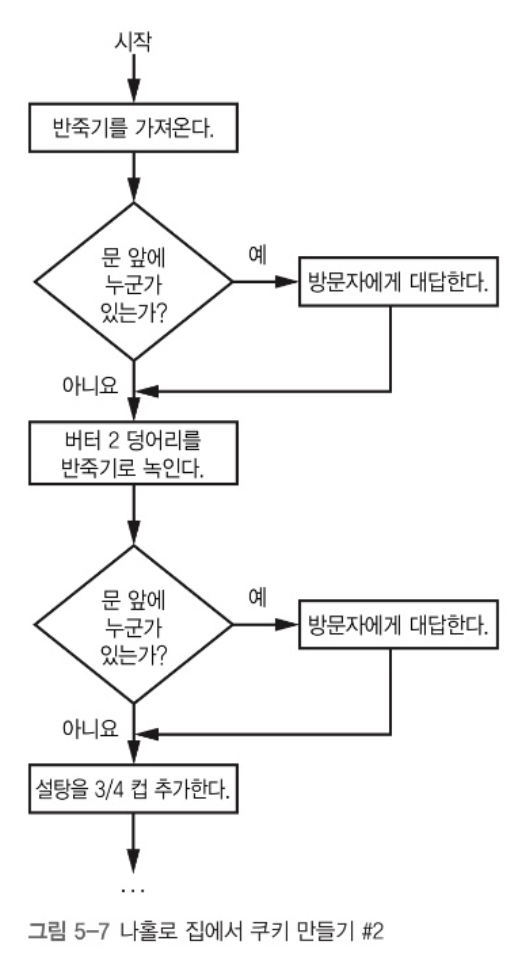
이런 방식을 폴링(polling)이라 한다. 이 방식이 잘 작동할 것 같지만 실제로 그렇지는 않다. 배달 온 소포를 받을 가능성은 커지지만 문 앞에 누가 왔는지 검사하는데 너무 많은 시간이 소모된다.
작업을 더 하위 작업들로 나누고 각 작업 사이마다 체크하는 방식은 한계가 있다. 실행 중인 프로그램을 잠깐 중단(interrupt)시켜 주의를 기울여야 외부의 요소에 대응할 수 있다. 이러한 기능을 하는 하드웨어를 실행 장치에 추가해야 한다.
요즘 사용되는 프로세서 대부분은 인터럽트(interrupt) 시스템이 들어간다. 이는 적절한 신호가 들어오면 CPU 실행을 잠깐 중단시킬 수 있는 핀이나 전기 연결을 포함한다.
인터럽트 시스템이 작동되는 방식은 다음과 같다.
- CPU가 주의를 기울여야하는 주변 장치는 인터럽트 요청을 생성한다.
- 프로세서는 현재 실행중인 명령어를 끝까지 실행한다.
- 그 후, 프로세서는 현재 실행 중인 프로그램을 잠시 중단시키고 인터럽트 핸들러(interrupt handler)라는 전혀 다른 프로그램(함수)을 실행한다.
- 인터럽트 핸들러 작업이 끝나면 원래 실행 중이던 프로그램이 중단된 위치부터 다시 실행한다.
이러한 인터럽트 역할은 위 예제에서 초인종이라고 생각하면 된다. 이 때, 고려해야 할 요소가 몇 가지 있다.
- 인터럽트에 대한 응답시간
- 인터럽트 핸들러 실행 시간
- 배달 기사에게 너무 많은 시간을 소모하면 쿠키가 타버릴 수 있다.
- 인터럽트 서비스 후 원래 하던일을 하기 위한 현재 상태 저장법
- 인터럽트 핸들러는 실행 중이던 프로그램의 레지스터를 저장했다가 나중에 원래 프로그램으로 돌아오기 전에 레지스터 값을 복구해줘야 한다.
인터럽트 시스템은 서비스 후 돌아올 프로그램의 위치를 스택에 저장한다. 또한, 자신이 덮어쓸 레지스터를 모두 저장해야 할 의무가 존재한다.
보통 인터럽트 핸들러 주소를 저장하기로 약속한 메모리 주소가 존재한다. 컴퓨터는 이를 통해 인터럽트 핸들러 위치를 찾는다.
인터럽터가 일어나면 컴퓨터는 인터럽트 벡터에 저장된 주소를 살펴보고 제어를 그 주소로 옮긴다. (즉, PC값을 인터럽트 벡터에 저장된 값으로 설정.)
이러한 인터럽트를 통해 예외 상황에도 대처할 수 있다. 예외를 인터럽트 핸들러를 통해 처리하면 인터럽트 핸들러 안에서 문제를 해결함으로써 오류가 생긴 프로그램이 계속 실행될 수도 있다.
또한, 인터럽트 간 우선순위(priority)가 존재하여 더 중요한 인터럽트를 먼저 처리하게 해준다.
상대 주소 지정
여러 프로그램을 동시에 실행하기 위해선 각 프로그램을 서로 전환시켜 줄 수 있는 관리자 프로그램이 필요하다. 이를 운영체제(OS)라 한다.
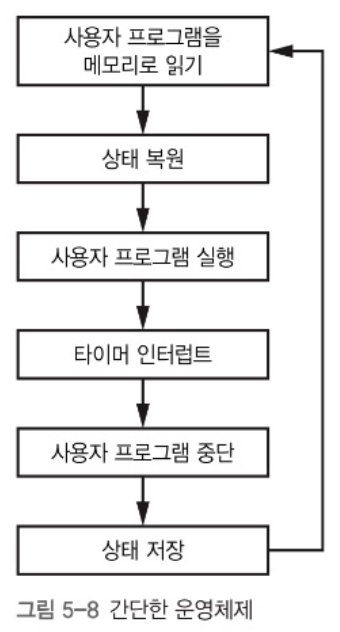
OS는 타이머를 이용해 사용자 프로그램을 전환시켜줄 때가 됐는지 판단한다. 이러한 스케줄링 기법을 시분할(time slicing)이라 한다.
시분할 방식은 시간을 정해진 간격으로 나누고, 정해진 시간 간격 동안 사용자 프로그램을 실행한다.
이 방법은 매우 느리다. 프로그램을 메모리로 불러오려면 시간이 걸리므로, 아래 처럼 각 프로그램에게 각기 다른 공간을 허용하면 더 빠르게 시분할이 가능하다.

절대 주소 지정을 사용하면 1000번지에서 실행되도록 만들어진 프로그램은 2000번지에서 제대로 실행되지 않은다. 인덱스 레지스터(index register)를 사용하면 이를 해결할 수 있다. 유효 주소(effective address)를 계산하여 보정을 해주면 다른 주소에서도 오류 없이 사용이 가능하다.
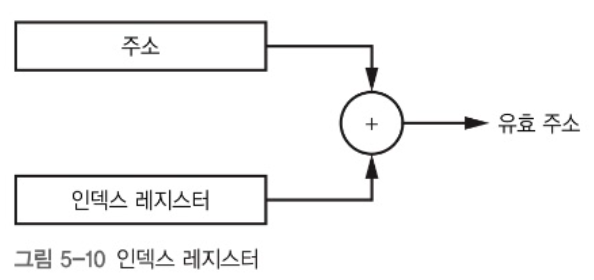
- 프로그램이 1000번지에서 실행되도록 만들어져있다면, OS는 이 프로그램을 3000번지에서 실행하기 위한 인덱스 레지스터를 2000 으로 설정할 수 있다.
또 다른 방법은 상대 주소 지정이 있다. 명령어의 주소값을 절대 주소가 아닌 (현 위치에서의) 상대 주소로 해석하는 것이다. 이를 통해 프로그램을 메모리의 원하는 위치로 자유롭게 재배치할 수 있다.
메모리 장치 관리
현 시대에서 멀티태스킹은 선택이 아닌 필수다. 앞서 살펴봤던 인덱스 레지스터와 상대 주소 지정이 멀티태스킹에 도움이 될순 있지만 충분하진 않다. 프로그램에 버그가 있는 경우엔 한계가 있다.
각 프로그램을 분리하면 이를 쉽게 해결할 수 있다. 오늘날 대부분의 마이크로 프로세서에는 메모리 장치 관리(MMU)가 들어있다.
MMU는 가상 주소(virtual address)와 물리 주소(physical address)로 구분한다. MMMU는 가상 주소를 물리 주소로 변환해준다.

MMU는 인덱스 레지스터에 비해 더 많은 주소 범위를 가진다. 가상 주소를 MSB, LSB로 나눈다.
- MSB : 페이지 테이블을 통해 변환
- LSB : 물리적 주소의 범위와 동일
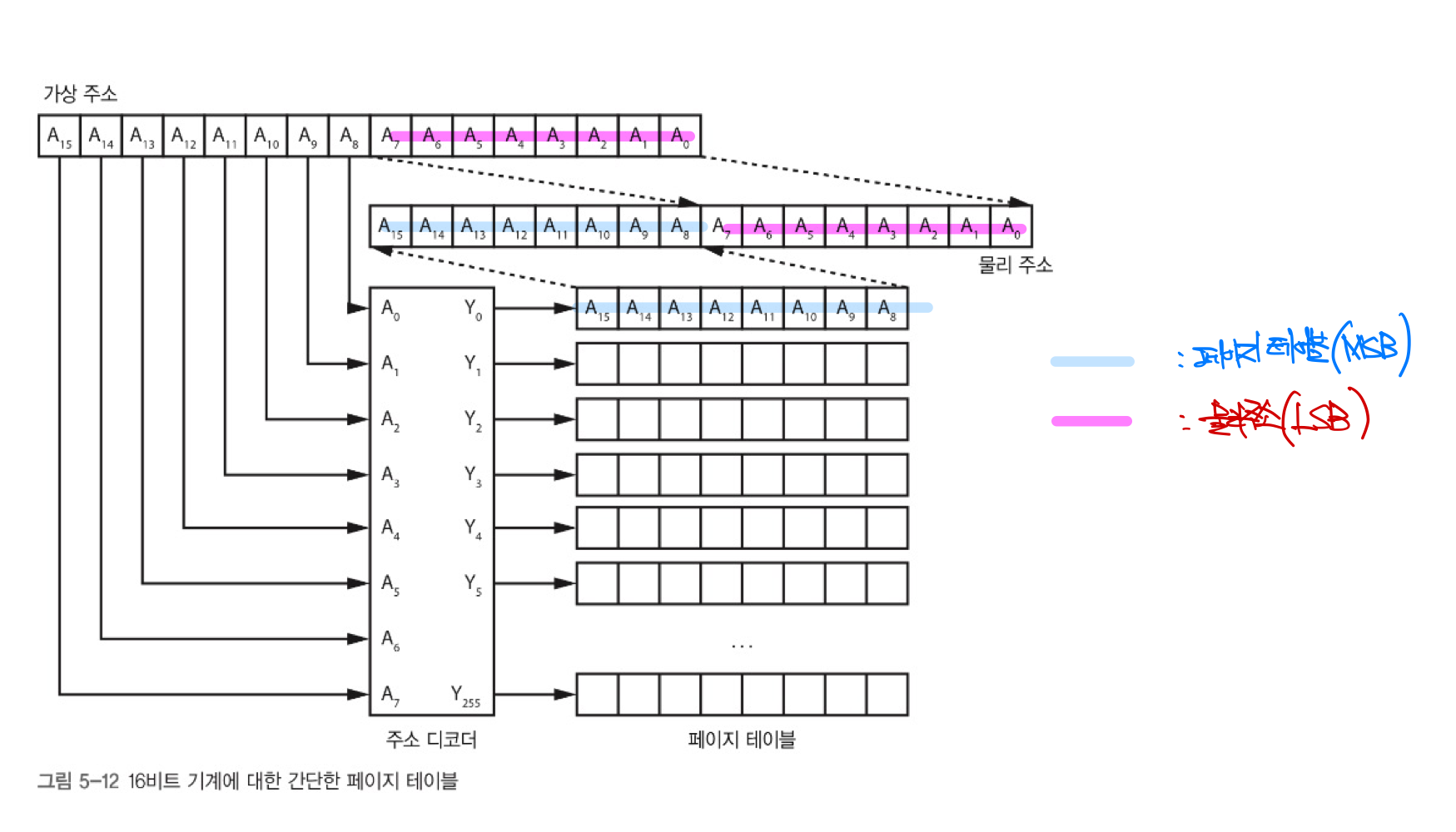
- 페이지 테이블 : 각 페이지가 물리 메모리상에 차지하는 실제 위치 정보들
가상 메모리가 연속적인 것 처럼 보이나 실제로는 그럴 필요가 없다. 심지어 프로그램이 실행되는 도중에 프로그램이 위치한 물리적 메모리 주소가 바뀔 수 있다.
페이지 크기를 좀 더 작게 만들 수 있지만, 페이지 크기를 줄이면 페이지 테이블 크기가 늘어난다. 이를 해결할 방법이 필요하다.
현대적 프로세서의 MMU의 페이지 테이블은 크기가 정해져 있다. 페이지 테이블 항목은 주 메모리에 저장되거나 주 메모리가 부족한 경우 디스크에 저장된다. 즉, 페이지 테이블 항목 중 일부를 필요로 할 때만 자신의 페이지 테이블로 가져온다.
또한, 제어 비트라는 것을 제공하는데 대표적인 예시들은 다음과 같다.
- 실행 불가 비트 : CPU가 이 페이지에 있는 명령어 실행 불가
- 읽기 전용 비트 : CPU가 이 페이지를 쓰는 것이 불가
이를 통해 프로그램이 실수로 자기 데이터를 실행하는 경우를 방지할 수 있다.
프로그램이 물리적 메모리에 연관되지 않은 주소에 접근하면 페이지 폴트(page fault)가 발생한다. 대표적으로 스택 오버플로의 경우 스택 범위를 벗어나는 주소에 접근하므로 페이지 폴트가 발생한다.
이 경우, MMU가 추가 메모리를 할당해 스택 공간을 늘림으로써 사용자 프로그램 실행을 계속할 수 있다.
MMU를 통해 폰 노이만 구조와 하버드 구조의 구분이 의미가 없어졌다. 단일 메모리 버스만 사용(폰 노이만 구조)해도 명령어 메모리와 데이터 메모리를 분리하여 제공할 수 있다.
가상 메모리
MMU가 가상 주소를 물리 메모리 주소로 변환해준다. 하지만 가상 메모리는 그 이상이다. 페이지 폴트 매커니즘으로 인해 프로그램은 필요한 만큼 많은 메모리가 있다고 생각할 수 있다.
만약, 요청받은 메모리가 메모리의 크기보다 큰 경우는 어떻게 될까? OS는 현재 필요하지 않은 메모리 페이지를 디스크로 옮긴다. (이를 스왑 아웃이라 한다.) 이런 스왑 아웃된 페이지에 프로그램이 접근하면 OS는 필요한 메모리 공간을 확보하고 요청받은 페이지를 다시 메모리에 불러들인다 (이를 스왑 인이라 한다.)
이런 식으로 페이지를 처리하는 것을 요구불 페이징(demand paging)이라 한다.
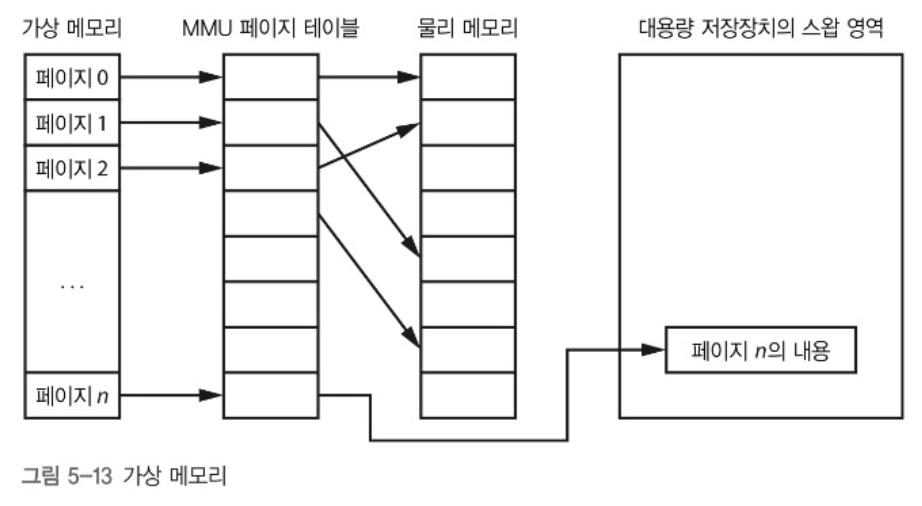
스왑(스왑 인 또는 스왑 아웃)은 시스템 성능이 크게 저하된다. 그러나, 공간이 부족하여 프로그램을 실행 못할 바엔 성능이 안좋더라도 프로그램을 실행하는 것이 더 중요하다.
따라서, 가상 메모리 시스템은 속도를 향상시키는 것이 중요하다. 대표적인 기법으로 LRU 알고리즘이 있다.
시스템 공간과 사용자 공간
멀티태스킹 시스템은 현재 실행 중인 프로그램이 컴퓨터 안에서 실행되는 유일한 프로그램이란 착각을 들게 한다. MMU는 각 프로세스에게 자신만의 메모리 주소 공간을 제공해 이런 환상을 키워준다.
하지만, I/O 장치가 추가되면 이러한 환상이 힘들어진다. 예를 들어, OS의 타이머를 사용자가 맘대로 바꿔버린다면 모든것이 예상과 다르게 작동할 것이다. 마찬가지로, MMU의 설정을 사용자가 맘대로 바꿀 수 있다면 MMU가 프로그램을 완전히 격리시키지 못할 것이다.
여러 CPU는 추가 하드웨어를 제공해 이를 해결한다. 시스템 모드와 사용자 모드를 구분하는 비트를 레지스터에 추가한다.
이런 방식에는 여러 가지 장점이 있다.
- 사용자 프로그램으로부터 OS를 보호하고, 사용자 프로그램을 다른 사용자 프로그램으로부터 보호한다.
- 사용자 프로그램이 MMU 등의 몇몇 요소에 손을 댈 수 없기에 OS가 프로그램에 대한 자원 할당을 전적으로 제어할 수 있다. 하드웨어 예외는 오직 시스템 공간에서만 처리된다.
메모리 계층과 성능
과거에 비해 CPU의 속도는 매우 빨라졌지만 메모리는 그렇지 못하다. 따라서, CPU가 메모리를 기다리느라 아무 일도 하지 않는 경우를 줄이기 위해 온갖 방법을 다 쓰기 시작했다.
프로세서는 보통 RAM이라는 주 메모리와 통신하는데 이는 프로세서 속도의 10%에 불과하다. HDD나 SSD는 이보다 더 느릴 수 있다.
이를 해석하면 CPU가 메모리를 기다리느라 많은 시간을 소비해야 한다는 뜻이다. 따라서, 캐시(cache)라는 하드웨어를 CPU에 추가한다. 이는 주 메모리에 비해 훨씬 작지만 훨씬 빠르고 프로세서와 같은 속도로 작동한다.
분기가 없는 경우 프로그램 메모리를 순서대로 읽어온다는 사실을 알 수 있고, 프로그램이 사용하는 데이터는 한데 모여있는 경우가 빈번하다는 사실도 알 수 있다. CPU 메모리 컨트롤러는 메모리에서 연속된 열에 있는 데이터를 한꺼번에 가져온다. 대부분은 연속된 위치에 있는 데이터가 필요하기 때문이다.
메모리에 접근하는 패턴이 순차적이 아니라 캐시 실패(cache miss)가 발생해도 CPU는 고속 메모리 접근이 가능하기 때문에 더 유리하다. 캐시 실패란 그 데이터가 캐시에 없어 메모리에서 가져와야되는 경우를 말한다.
반대로 캐시 적중(cache hit)은 CPU가 원하는 내용을 캐시에서 찾은 경우를 말한다.
캐시 메모리에도 몇 가지 계층이 있다. CPU와 거리순으로 L1, L2, L3 캐시가 있다. CPU에서 멀어질 수록 더 느려지고 더 커진다. 디스패처(dispatcher)도 존재하는데 이는 여러 가지 크기의 내용물을 채워넣거나 꺼내는 일을 담당하는 아주 큰 논리회로이다.
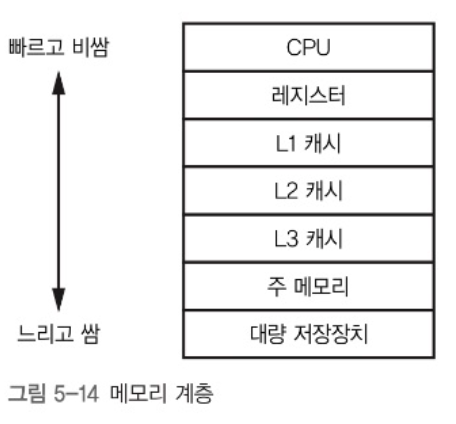
더 복잡한 수정을 가하면 성능을 향상 시킬 수 있다. 메모리에서 데이터를 미리 가져오는 프리 페치(prefetch)나 조건 분기 명령어 결과를 예측하는 분기 예측(branch prediction) 회로가 포함된다. 심지어 순서를 벗어나는 실행(out-of-order execution)을 처리하는 회로도 존재한다.
캐시의 일관성을 유지하는 것이 가장 큰 문제이다. 캐시에서 해당 내용이 변경되었을 때 이를 메모리에도 기록해야 하는데 2가지 기법이 존재한다.
- Write through
- 캐시 접근시 메모리에 즉시 기록
- 복잡하진 않나 성능이 별로
- Write back
- 기존 값이 수정됐음을 표시해두고 output할 때 한 번에 수정
- 복잡하나 성능이 좋다.
메모리상의 데이터 배치
메모리에는 명령어 뿐만 아니라 데이터도 담는다. 이 경우 데이터는 정적 데이터이다. 정적이란 프로그램을 작성할 때 얼마나 많은 메모리가 필요한지 알고 있다는 뜻이다. 따라서, 이런 여러 데이터 영역을 서로 충돌하지 않게 배치할 수 있어야 한다.
그러나, 대부분의 프로그램은 동적 데이터를 다뤄야 한다. 동적이란 프로그램을 실행하기 전에는 크기를 알 수 없는 데이터를 의미한다.
동적 데이터는 주로 정적 데이터가 차지하는 영역의 바로 위 영역에 쌓이며, 이를 힙(Heap)이라 한다. 더 많은 데이터를 저장해야할 경우 스택은 아래로, 힙은 위로 자라난다. 힙과 스택이 서로 충돌하지 않게 하는 것이 중요하다.
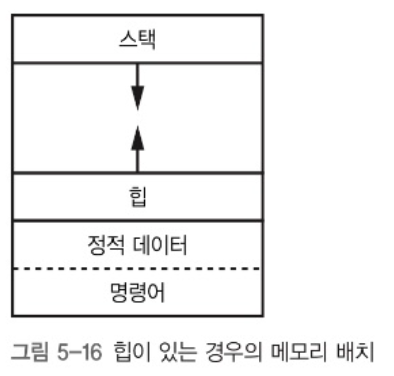
프로그램 실행
프로그램 실행 시 매번 새로 함수를 작성하는 것보단 누군가가 만들어 놓은 함수를 사용할 수 있으면 더 편하다. 이를 달성하기 위해선 자주 사용되는 함수들을 한데 모아 라이브러리로 만드는 것이다.
본격적인 프로그램은 라이브러리뿐 아니라, 여러 조각으로 이뤄진다. 이 덕분에 여러 사람이 한 프로그램의 여러 부분을 동시 개발할 수 있다.
허나, 프로그램을 여러 조각으로 나누면 이를 하나로 엮거나 연결할 방법이 필요하다. 링커(Linker)라는 특별한 프로그램을 사용해 여러 조각을 하나로 연결해 실행한다.
프로그램을 이루는 모든 부분이 합쳐져서 실행 파일을 이룰 때 런타임 라이브러리가 추가된다. 이는 진입점 명령어보다 먼저 불러진다.
진입점
프로그램의 첫 번째 명령어가 위치한 주소
런타임 라이브러리는 메모리 설정을 책임진다. 즉, 스택과 힙 영역을 설정한다는 뜻이다. 이외에도 많은 기능들을 수행한다.
