메모리 장치마다 IO 속도가 다르고 이가 속도에 영향을 미친다. 이를 염두하여 데이터를 조직적으로 잘 정리하면 더 나은 성능을 얻을 수 있다.
데이터를 조직화하는 표준적인 방법 데이터 구조를 알아보자. 데이터 구조는 여러 유형의 메모리를 더 효율적으로 사용하기 위해 존재하며 참조 지역성을 고려하여 설계되었다.
참조 지역성
1. 필요한 데이터를 (메모리 상) 서로 근처에 유지하자.
2. 금방 사용할 데이터는 더 가까운 곳에 저장하자.
기본 데이터 타입
프로그래밍 언어는 다양한 기본 데이터 타입을 제공한다. 이런 타입은 다음 두가지 측면이 존재한다.
- 크기(size) : 비트 수
- 해석(interpretation) : 부호/부동 소수점/문자/포인터 여부 등
포인터(Pointer)
단지 컴퓨터 아키텍처에 따라 결정되는 크기의 부호가 없는 정수며, 집 주소와 비슷하다. (주소가 집 자체는 아니지만 집을 찾을 때 사용하는 것 처럼 원하는 값이 메모리 상에 있는 위치를 알 수 있다.)
지금으로썬 말이 안되지만 초기엔 포인터와 정수가 같은 크기라 가정하고 둘을 서로 바꿔쓰는 경우가 많았다. 이 때문에 문제가 많았다.
이 때문에, 이식성에 신경을 쓰기 시작(인터넷과 웹 출현도 한몫함) 했으며 JAVA 처럼 포인터를 아예 없앤 언어가 생겨났다.
참조(Reference)
포인터의 추상적 개념. 잘못된 포인터 사용으로 인한 오류를 막기 위해 도입됐다.
배열
아파트 한 동에는 주소가 있고, 한 아파트 동 안에 여러 집이 있으며, 각 집마다 호수가 있다. 배열은 아파트이며, 각 집들은 원소라 할 수 있다.
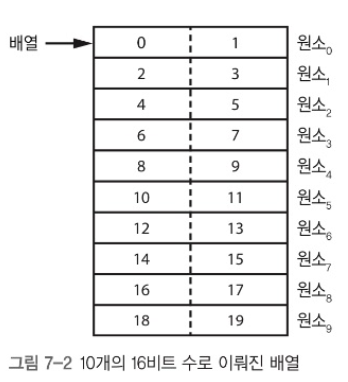
- 아파트 : 배열
- 집 : 원소
- 인덱스 : 집 호수
이 외에 각 원소는 첫 번째 원소의 주소(기저 주소)로 부터 얼마나 떨어져 있는지를 나타내는 오프셋(offset) 으로 지정할 수 있다.
다차원 배열
위 그림은 1차원 배열에 해당한다. 만약 층마다 3개의 집이 있는 4층짜리 아파트는 2차원 배열이다. 동, 층, 호수로 인덱스를 만들면 3차원, 단지, 동, 층, 호수로 인덱스를 만들면 4차원 배열이 된다.
다차원 배열에 메모리가 저장되는 과정을 알아보자. 예를 들어 층마다 3개의 집이 있는 4층 아파트(4 X 3 2차원 배열)이 있다고 해보자.
집마다 전단지를 돌린다고 하면 다음 2가지 방법이 있을 것이다.
- 1층 1호 -> 1층 2호 -> 1층 3호 -> 2층 1호 ...
- 1층 1호 -> 2층 1호 -> 3층 1호 -> 4층 1호 -> 1층 2호
실제 상황과 마찬가지로 첫 번째 방법이 지역성이 더 좋고 힘도 덜든다.
첫 번째 원소를 기준으로 계산한 상대적인 주소는 다음과 같다.
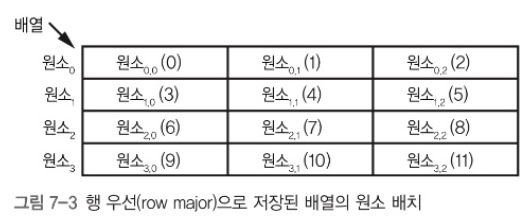
- 1층 1호 -> 1층 2호 -> 1층 3호 -> 2층 1호 순으로 진행
- 행 인덱스가 바뀔 때마다 더 많은 이동이 일어난다는 것을 알 수 있다.
인덱스 범위가 벗어난 경우
언어마다 인덱스 검사를 해주는 언어도 많지만 그렇지 않은 언어도 있다.(C, C++ 등) 인덱스를 벗어난 주소에 접근하는 경우 프로그램이 망가지거나, 엉뚱한 데이터에 접근하여 보안상 구멍이 생길 수 있다.
언어가 인덱스 검사를 해주지 않는다면 항상 인덱스 범위를 준수하도록 노력하자.
비트맵
특정 데이터를 표현할 때, 기본 데이터로 하기엔 너무 큰 경우가 있다. 1비트면 표현이 가능한 데이터를 바이트를 쓰면 효율적이지 못하다. 이러한 경우 비트맵을 사용하면 효율적으로 데이터를 표현할 수 있다.
35비트를 추적하는 상황이 있다. 그러면 아래 그림과 같이 바이트가 5개만 있으면 35비트를 충분히 담을 수 있다.
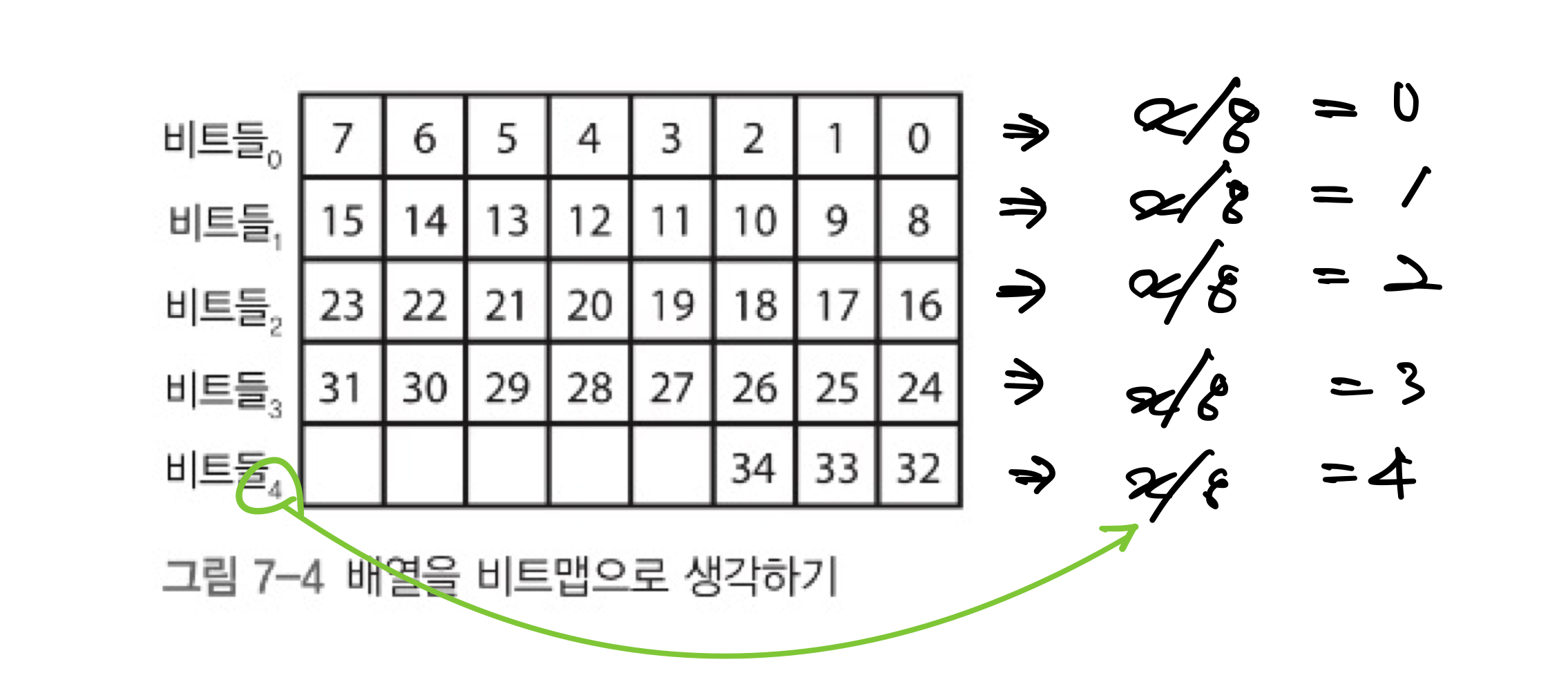
비트맵에 대한 기본 연산은 다음 4가지이다.
- 비트 설정하기(1로 만들기)
- 비트 지우기(0으로 만들기)
- 비트가 1인지 검사하기
- 비트가 0인지 검사하기
각 비트들은 정수 나눗셈(/) 을 통해 현재 포함된 바이트를 찾을 수 있다. 이는 비트 시프트를 사용하면 더 빠르게 계산할 수 있다.
이후, 비트 위치에 대한 마스크가 필요하다. 마스크를 계산하는 법은 다음과 같다.
1. 0x07 AND (비트 번호)
2. (1)의 결과를 1비트 왼쪽 시프트
이를 활용하면 기본 연산 4가지를 쉽게 수행할 수 있다.
- 비트 설정하기 : 비트들 = 비트들 OR 마스크
- 비트 지우기(0으로 만들기) : 비트들 AND (NOT 마스크)
- 비트가 1인지 검사하기 : (비트들 AND 마스크) != 0
- 비트가 0인지 검사하기 : (비트들 AND 마스크) == 0
문자열
여러 문자로 이뤄진 시퀀스를 문자열이라 한다.
문자열을 연산할 땐 그 길이를 알아야 하는데, 이를 배열로 처리하기엔 가변 문자열 데이터에 작용하는 프로그램이 많아 한계가 있다.
첫 번째 방법은 문자열 안에 별도로 길이를 저장하는 것이다. 그러나, 이는 문자열 길이가 제한되며 길이를 저장하기 위해 바이트를 할당할 경우 메모리 정렬 경계에 있기 힘들 수 있다.
두 번재 방법은 문자열 끝에 NUL 문자를 추가하는 것이다. 대부분의 기계에 주어진 값이 NUL 인지 체크하는 명령어가 있으므로 다른 문자에 비해 NUL 문자를 사용한다.
하지만, 문자열의 길이를 알기위해선 문자열을 스캔하면서 문자수를 세야하며, 문자열 중간에 NUL 문자를 넣는 것은 불가능하다.
복합 데이터 타입
구조체
간단한 데이터를 저장할땐 기본 타입으로 충분하지만, 그렇지 않은 경우가 많다. 현대적인 대부분의 언어는 원하는대로 데이터 타입을 만들 수 있는 방법을 제공하는데, 이를 구조체(Structure)라 하며, 이 안에 있는 여러 방을 구조체의 멤버(Member)라 한다.
일시를 표현해야되는 상황이 있다고 해보자. 다음 구조체를 정의하여 구조체 배열로 데이터를 저장하면 가독성이 좋을 것이다.

구조체가 예샹보다 메모리를 더 차지하는 경우가 종종 있다. 아래 구조체를 보자.
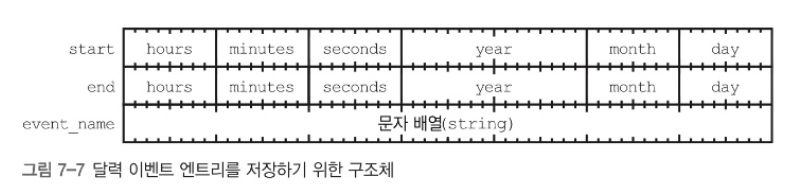
프로그래밍 언어는 멤버 순서가 바뀌면 문제가 될 수 있기에 프로그래머가 지정한 멤버 순서를 지킨다. 하지만, 언어는 메모리 정렬도 지켜야 한다. year 멤버는 4 ~ 5번째 바이트에 위치시키면 경계에 걸치기 때문에 배치를 바꿔야 한다.
프로그래밍 언어 도구는 패딩(padding) 을 필요한 만큼 추가해 이 문제를 해결한다. 따라서, 실제 메모리 배치는 다음과 같다.

공용체
구조체는 멤버들이 각기 다른 메모리를 차지한다. 하지만, 공용체(Union)은 멤버들이 메모리를 모두 공유할 수 있다.
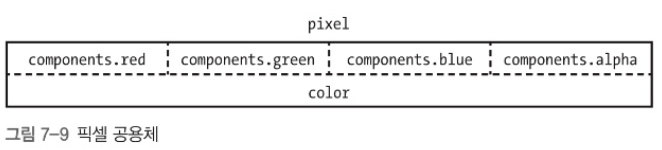
이 공용체를C 문법으로 사용하면 다음과 같다.
pixel.color: 0x12345678pixel.components.red: 0x12pixel.components.green: 0x34
단일 연결 리스트
배열은 실제 데이터만 저장하지 데이터 관리를 위한 부가 정보를 요구하지 않는다. 또한, 데이터양이 정해지지 않은 경우 적합하지 않다.
연결 리스트(linked list)는 목록에 들어갈 원소 개수를 모르는 경우 배열보다 더 효율적이다.

next: 다음 원소 주소를 저장하는 포인터- 헤드 : 리스트의 맨 앞 원소를 저장하는 포인터
- 테일 : 리스트의 마지막 (보통
null포인터로 표현)
배열과 가장 큰 차이점이라면 각 원소가 메모리에 연속적으로 위치하지 않는다는 점이다.
동적 메모리 할당
프로그램 데이터 공간 구성에는 정적으로 할당된 데이터 영역 다음에 프로그램 런타임 라이브러리가 설정해주는 힙 영역이 존재한다.
MMU(메모리 관리 유닛)이 있는 시스템은 런타임 라이브러리가 프로그램에게 필요한 메모리 용량을 판단해 OS에게 요청한다.
배열 등의 변수가 사용하는 메모리는 정적(static)이다. 이런 변수에 할당된 주소는 바뀌지 않는다.
반면, 리스트 노드와 같은 존재하는 동적(dynamic)이다. 필요에 따라 생기기도 하고 사라지기도 한다. 이러한 동적인 대상에 사용할 메모리를 힙에서 얻는다.
프로그램은 힙을 관리할 수 있어야 한다. 사용중/사용 가능한 메모리를 알야아 한다. 물론, 이런 목적에 사용하는 라이브러리 함수가 있으므로, 직접 이런 함수(malloc, free 등)를 작성할 필요는 없다. 이들 중, C언어의 malloc, free 함수를 보자.
malloc
단일 연결 리스트 데이터 구조를 사용해 작동한다. 힙은 여러 개의 블록으로 나뉘고, 각 블록에는 크기와 다음 블록에 대한 포인터가 포함된다.

처음에는 전체 힙이 한 블록으로 존재한다. 이후, 프로그램이 요청할 때 마다 malloc 은 충분한 크기의 블록을 찾아 요청받은 공간에 대한 포인터를 반환 후 프로그램에게 할당한 메모리를 반영해 블록의 크키와 링크를 조정한다.
이렇게 연결리스트를 사용하는 방식에는 부가 비용이 발생한다. 예를 들어 64비트 컴퓨터라면 next, size 로 인해 블록당 16바이트가 소모된다.
free
이후, 프로그램이 free로 메모리를 해제하면 메모리가 다시 연결리스트에 추가된다.
근데, 할당받지 않은 메모리를 해제(free) 시키면 어떻게 될까? 단일 연결 리스트 내에 size와 next 필드를 오염시킬 수 있다. 이는 size와 next가 필요한 연산(메모리 할당이나 해제)이 실행되기 전까지는 발견되지않아 알아차리기 힘들다.
더 호율적인 메모리 할당
노드에 문자열을 가리키는 포인터가 포함된 연결리스트를 생각해보자.
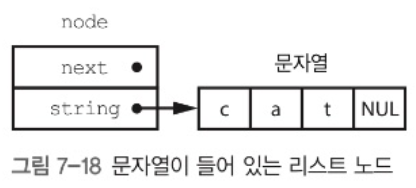
이런 경우, 노드에 사용할 메모리와 문자열에 사용할 메모리를 모두 할당해야 한다. 이는 malloc 의 부가 비용이 상대적으로 커진다.
위 예시에서 64비트 컴퓨터는 노드를 처리하기 위해 16바이트 부가 비용(next, size)가 필요하고, 4바이트인 cat 문자열을 처리하기 위해 16바이트 부가 비용이 더 필요하다.
노드와 문자열을 동시에 할당하면 이 문제를 해결할 수 있다. 노드와 문자열의 크기를 합하고 메모리 경계를 지키기 위해 패딩(padding)을 추가한 크기의 공간을 할당하면 된다.

- 부가 비용이 절반으로 줄어듦을 알 수 있다.
- 이렇게 되면
free함수도 한 번만 호출하면 된다.
가비지 컬렉션
동적 메모리를 관리시 포인터를 잘못쓰면 문제가 생긴다. 포인터는 단순히 메모리 주소를 나타내는 숫자에 불과하다.
포인터를 사용해 존재하지 않는 메모리에 접근하거나 프로세서의 메모리 경계에 맞지 않는 주소에 접근하면 예외가 발생하여 프로그램이 중단된다.
JAVA나 JavaScript 같은 언어는 포인터, malloc이나 free를 사용하지 않으면서 동적 메모리 할당을 지원한다. 이들은 모두 가비지 컬렉션(garbage collcetion) 을 구현한다.
특히, 자바 같은 언어는 포인터 대신 참조(reference)를 사용한다.
참조(reference)
포인터를 추상화한 개념으로 포인터와 비슷한 기능을 제공하지만 메모리 주소를 노출하진 않는다.
가비지 컬렉션을 사용하는 언어는 메모리 할당 연산자 new 를 제공하는 경우가 있다. 그러나, 데이터 요소를 삭제하는 연산자(ex. free)는 없다.
런타임 환경이 변수 사용을 추적해 더 이상 사용하지 않는 메로리를 자동으로 해제해준다. 이 방법은 다양한데 대표적으로 변수의 참조 횟수를 카운팅(counting)하여 이 값이 0이 됐을 때 해제하는 참조 카운팅(reference counting) 기법이 있다.
단점
프로그래머가 가비지 컬렉션 시스템을 제어할 수 없다. 이로 인해 프로그램이 아주 중요한 일을 하는 도중에 갑지ㅣ 컬렉션 시스템이 작동돼서 문제가 생기는 경우도 있다.
또한, 불필요한 참조가 남는 경우가 자주 있기에 프로그램이 메모리를 더 많이 사용하는 경향이 있다. 불필요한 참조는 빠르게 메모리 재활용을 해야하지만, 가비지 컬렉션이 이를 느려지게 한다. 나쁜 포인터(Bad Pointer) 처럼 프로그램이 중단되진 않지만 느려질 수 있다. 더하여, 불필요한 참조를 추적하는 작업이 디버깅이 어렵다.
이 외에 가비지 컬렉션에 대한 자세한 내용은 아래 링크를 참조하자.
https://d2.naver.com/helloworld/1329
이중 연결 리스트
단일 연결 리스트(SLL)의 delete 함수는 O(n) 시간이나 걸린다. 만약, 데이터가 아주 많다면 삭제 시간은 이에 따라 더 느려질 것이다.
이중 연결 리스트는 노드의 next 외에 previous 라는 멤버가 더해져 이전 원소에 대한 포인터도 가지고 있는 데이터 구조이다.

이로 인해, 노드 당 부가 비용은 2배가 되지만 delete 시 노드를 앞에서 방문할 필요가 없어진다. (이는 공간/시간의 trade off라 할 수 있다.)
이중 연결리스트는 리스트 전체를 방문하지 않아도 원하는 위치에 노드를 추가/삭제하기 용이하다. 아래 그림을 보자.

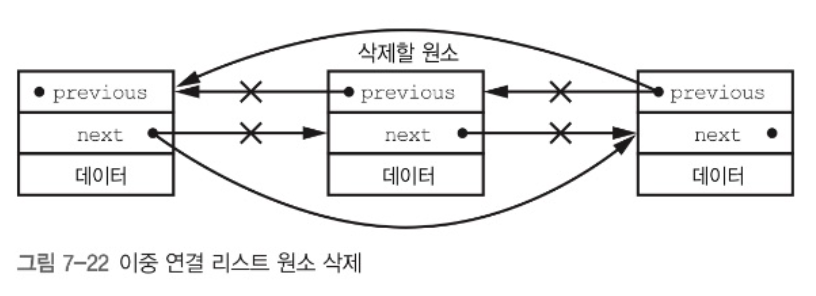
계층적 데이터 구조
지금까지 살펴본 SLL, DLL은 모두 선형적(linear) 데이터 구조이다. 데이터를 효율적으로 가져오고 싶은 경우 이는 최선의 방법이 아니며, 계층적 데이터 구조를 사용하면 특정 상황에서 데이터를 가져올 때 유리할 수 있다.
이진트리
가장 간단한 계층적 데이터 구조는 이진 트리(binary tree) 이다.

트리의 루트(root)는 연결 리스트의 헤드와 같으며, 간접 주소 지정을 활용한다는 면에서 DLL과 유사하다.
이진트리 삽입

마치 스무고개를 하듯 루트 노드부터 시작하여 크기를 비교하여 적당한 위치에 삽입이 된다. 이 시행은 O(n) 시간이 소모된다.
이진트리 탐색

마찬가지로, 스무고개를 하듯 루트 노드부터 시작하여 크기를 비교하며 값을 찾는다. 맨 끝까지 도달(current == NULL)한 경우엔 찾지 못한 경우를 의미한다.
주의할 점
이진 트리는 소위 말해 균형이 잡혀있어야 한다. 루트 노드를 기준으로 한 쪽으로만 데이터가 몰려 있으면 이는 균형잡히지 않았다 라고 얘기한다.
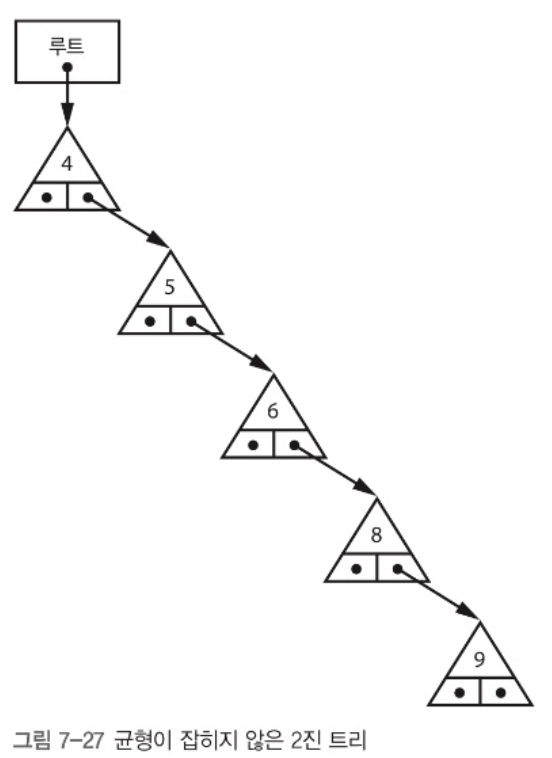
이런 경우는 DLL을 사용하는 것과 같다. 트리의 높이(log n)이 원소의 개수(n)과 동일하기 때문에 계층적 데이터 구조의 장점을 살릴 수 없다.
트리 균형 알고리즘은 계산 비용이 더 많이 들고 일부는 저장 공간도 더 사용한다. 그러나, 불균형한 트리를 수정하는건 엄청난 이득(n -> log n)이므로 트리가 커질 수록 이런 부가 비용은 빠르게 극복할 수 있다.
대용량 저장장치
블록(block)
디스크의 기본 단위.
클러스터(cluster)
디스크에서 연속적인 블록이다. 한 클러스터에 데이터를 저장하는 건 데이터의 크기가 너무 큰 경우에 비효율적이다. 데이터는 사용 가능한 섹터가 있으면 위치와 관계없이 저장된다.
결론은, 어떤 데이터를 저장하기 위한 저장소 블록 대신, 충분한 크기가 고정된 블록을 여럿 확보하는 것이 좋다. 이후, 데이터를 이 블록들에 나눠 담아야 한다.
연결 리스트의 순회는 오래(O(n)) 걸리기 때문에 디스크 블록의 사용 여부를 판단하기엔 좋지 않다.
데이터를 메모리상에서 관리할 때는 포인터를 통한 메모리 참조로도 충분하다. 그러나, 장기적으로 데이터를 저장할 경우 디스크를 사용한다. 이 경우엔 영구적인 어떤 존재(값)이 필요한데, 파일 이름이 그 답이다.
데이터베이스
이진 트리(binary tree)
데이터를 메모리에 저장할 때는 훌륭한 방법이지만, 큰 데이터를 저장하기엔 안좋다. (트리 노드는 크기가 작은 경향이 있어 디스크 섹터에 잘 들어맞지 않기 때문)
비 트리(B tree)
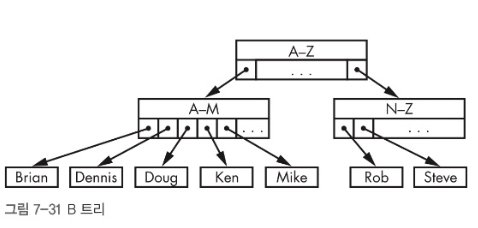
- 균형 트리이지만 이진 트리는 아니다.
- 이진 트리 노드보다 더 많은 가지(자식들)가 있다.
- 균형 이진 트리보다는 공간을 덜 효율적으로 사용하지만, 성능이 좋고 특히 디스크에 쓰기 시 성능이 좋다.
데이터베이스(DB)
- 정해진 방식으로 조직화된 데이터 모음
- 이진 트리 대신 B 트리라는 데이터 구조를 사용
데이터베이스 관리 시스템(DBMS)
DB에 정보를 읽기/쓰기 해주는 프로그램
인덱스
저장된 데이터를 특정 방법을 기준으로 접근 시 사용한다. 아래 그림과 같이 조직화된 노드들을 주 인덱스라 한다.
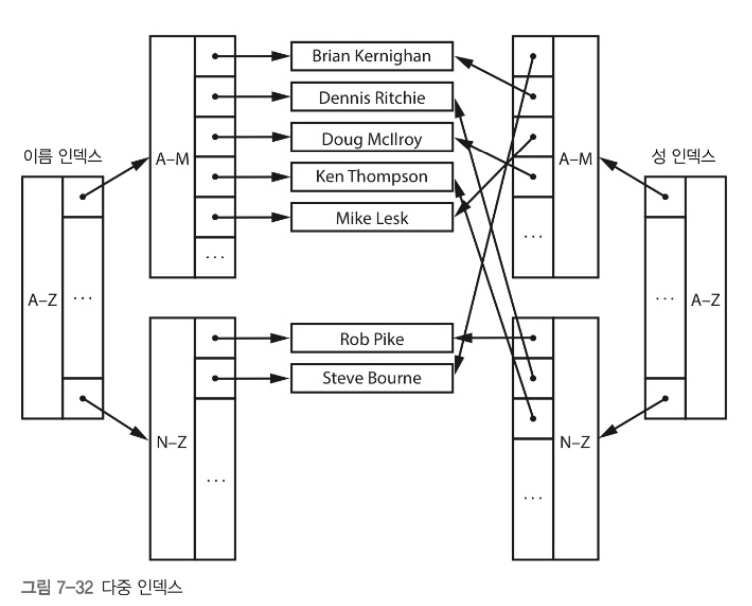
인덱스의 경우 데이터 변경마다 모든 인덱스를 갱신해야 한다는 단점이 있따. 그러나, 데이터 변경보다 검색이 더 많으므로 이런 트레이드 오프는 괜찮다.
벡터를 사용한 I/O
시스템 성능에 있어 복사를 효율적으로 처리하는 것이 중요하다. 그러나, 복사 자체를 아예 피할 수 있다면 성능은 더 좋아질 것이다.
OS와 사용자 공간 프로그램 사이에는 데이터가 아주 많이 오고가고, 이러한 데이터는 연속적인 메모리에 위치하지 않는 경우가 자주 있다.
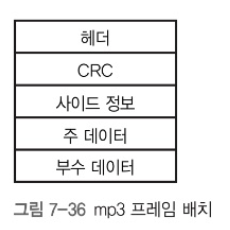
따라서, 시스템에게 프레임의 각 부분을 가리키는 포인터의 집합을 전달하고, 시스템이 데이터를 쓸 때 각 부분을 하나로 합쳐주면 더 효율적이라 볼 수 있다.

아이디어는 크기와 데이터에 대한 포인터로 이뤄진 벡터를 OS에게 넘기는 것이다. OS는 이 벡터를 통해 프레임을 조합한다. 데이터 읽기/쓰기 모두 벡터를 사용할 수 있다. 이를 차례대로 분산/수집이라 한다.
참고
IP 데이터가 패킷으로 전달되고, TCP는 패킷이 올바른 순서로 전달되게 할 책임이 있다. 여기서 분산/수집이 사용된다.
객체지향의 함정
객체를 저장하기 위한 C 구조체는 다음과 같다.
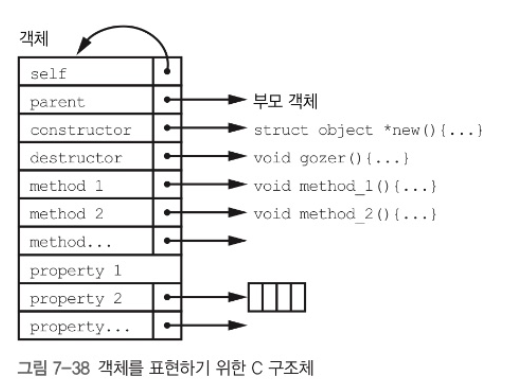
- 메소드들이 독립적으로 존재하여 저장공간이 비대해진다.
메서드를 별도의 데이터 구조에 나눠 담으면 이런 문제를 해결할 수 있다.

- 이 경우 객체와 관련된 트레이드 오프가 존재한다.
해시
해시
대용량 저장장치가 아닌 메모리에 데이터를 저장하고 읽는 연산에서 사용된다.
해시 함수
- 검색에 사용할 키(key)에 대해 이들을 균일하게 배치시켜주는 함수
- 해시 함수가 계산하기 쉽고 균일하게 배치(키를 버킷에 골고루 뿌려주는 경우)를 시켜준다면 검색이 아주 빨라진다.
- 해시 함수의 결과값을 사용해 키에 대응하는 데이터를 메모리에 저장할 수 있다.
- 해시 함수의 메모리 크기보다 작은 범위의 값을 만들어야 한다.
해시 테이블
- 해시 함수의 결과 배열
- 해시 테이블의 크기를 소수(prime number)로 만들면 균일하게 배치된다.
버킷
- 해시 테이블의 각 원소
해시 체인
같은 버킷에 데이터가 여러 개인 경우 SLL을 통해 연결하는 것
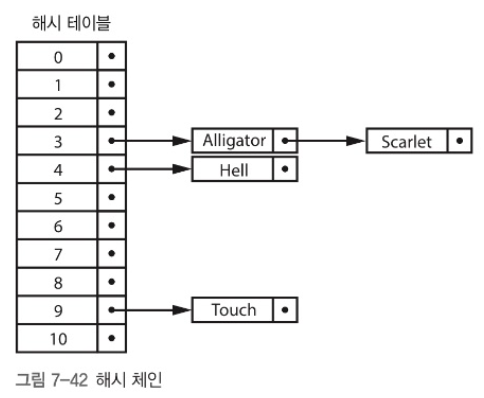
- 충돌이 해결된다.
완전 해시
각 키를 유일한 버킷에 연결시켜주는 것

좋은 글 감사합니다. 자주 올게요 :)