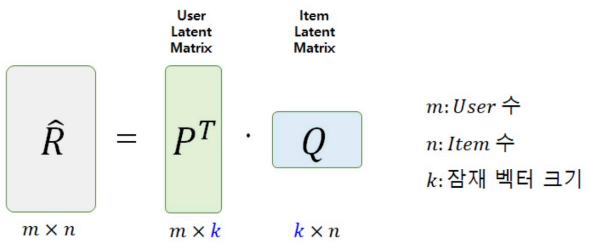
Matrix Factorization의 원리
하나의 User-Item 행렬을 User와 Item의 Latent Factor 행렬곱으로 분할하는 방법
- P : 각 사용자의 특성을 나타내는 k개의 요인값으로 이루어진 행렬
- Q : 각 아이템의 특성을 나타내는 k개의 요인값으로 이루어진 행렬
- k : Latent Factor (잠재 요인)
- : 평점 예측치
SGD를 사용한 MF 알고리즘
MF 알고리즘 프로세스
-
잠재요인 k 선택
- 다양한 k를 비교하면서 최적의 수를 결정하는 것이 바람직함
-
P, Q 행렬 초기화
- P, Q 두 행렬로 분해하기 위해 임의의 수로 초기화
-
예측 평점 계산
-
실제값 R과 예측값 간 오차 계산 및 P, Q 수정
Stochastic Gradient Decent (SGD)Alternating Least Squares (ALS)
-
기준 오차 도달 확인
- 기준 오차에 만족하거나, 정해진 iteration을 완료할 때까지 3~5번 과정 반복
- 기준 오차에 만족하거나, 정해진 iteration을 완료할 때까지 3~5번 과정 반복
Stochastic Gradient Decent (SGD)
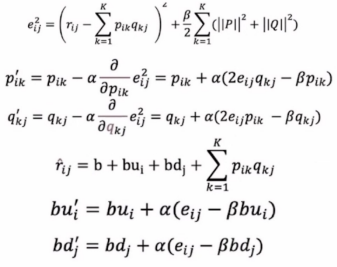
- : 오차의 제곱 + Regularization Term
- : 업데이트된 P, Q
- : Learning rate (학습률)
- : Regularization Term
- : 예측값
- b : 전체 평균
- : 사용자 i에 대한 평가 경향 (사용자 i의 평균과 전체 평균의 차이)
- : 아이템 j에 대한 평가 경향
- : 업데이트된 사용자 i, 아이템 j에 대한 평가 경향
Regularization Term : Overfitting을 방지하기 위한 장치
💡 다음 MovieLens 실습에서는 위의 기본적인 MF 알고리즘 프로세스를 SGD를 사용하여 진행한다.
- 데이터 불러오기
import os
import pandas as pd
import numpy as np
base_src = '' #각자 경로
u_data_src = os.path.join(base_src,'u.data')
r_cols = ['user_id','movie_id','rating','timestamp']
ratings = pd.read_csv(u_data_src,
sep='\t',
names = r_cols,
encoding='latin-1')
#timestamp 제거
ratings = ratings[['user_id','movie_id','rating']].astype(int)- MF 클래스 정의, 정확도 계산
class MF():
def __init__(self,ratings,hyper_params):
self.R = np.array(ratings)
#사용자 수(num_users)와 아이템 수 (num_items)를 받아온다.
self.num_users, self.num_items = np.shape(self.R)
#아래는 MF weight 조절을 위한 하이퍼 파라미터
# K : 잠재요인(Latent Factor)의 수
self.K = hyper_params['K']
# alpha : 학습률
self.alpha = hyper_params['alpha']
# beta : 정규화 계수
self.beta = hyper_params['beta']
# iterations : SGD 계산을 할 때의 반복 횟수
self.iterations = hyper_params['iterations']
# verbose : SGD의 학습 과정을 중간중간에 출력할 것인지에 대한 여부
self.verbose = hyper_params['verbose']
#P와 Q를 가지고 RMSE 함수 형성
def rmse(self):
#self.R의 rating 데이터 속에서 0이 아닌 요소에 인덱스 가져오기
xs, ys = self.R.nonzero()
self.predictions = []
self.errors = []
for x, y in zip(xs, ys):
#get_prediction은 사용자 x, 아이템 y에 대해서 평점 예측치를 계산하는 class method
prediction = self.get_prediction(x,y)
self.predictions.append(prediction)
#실측값과 예측값의 차이를 리스트에 어펜드
self.errors.append(self.R[x,y] - prediction)
#방금 한 것을 array 형태로 다시 바꿔준다
self.predictions = np.array(self.predictions)
self.errors = np.array(self.errors)
#우리가 알고 있는 rmse를 클래스 매서드로 구현
return np.sqrt(np.mean(self.errors**2))
#학습에 대한 method 구현
def train(self):
#P행렬과 Q행렬 난수 초기화
#표준편차 = 잠재변수의 개수 분의 1
self.P = np.random.normal(scale=1./self.K,
size = (self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K,
size = (self.num_items, self.K))
#사용자 평가 경향도 초기화; 0으로부터 시작
self.b_u = np.zeros(self.num_users)
self.b_d = np.zeros(self.num_items)
self.b = np.mean(self.R[self.R.nonzero()])
rows, columns = self.R.nonzero()
#SGD를 적용할 대상; 평점이 있는 요소의 인덱스와 그 평점을 리스트로 만들어서 samples에 저장
self.samples = [(i,j,self.R[i,j]) for i, j in zip(rows, columns)]
training_process = []
for i in range(self.iterations):
#다양한 시작점에서 계속 shuffle를 하면서 진행
np.random.shuffle(self.samples)
self.sgd()
#SGD로 P와 Q와 B_u, B_d가 업데이트되었으므로 이에 따른 새로운 RMSE 계산
rmse = self.rmse()
training_process.append((i+1, rmse))
if self.verbose:
if (i+1) % 10 == 0:
print('Iteration : %d ; train RMSE = %.4f' % (i+1, rmse))
return training_process
#i 사용자의 j 아이템에 대한 평점 예측
def get_prediction(self, i, j):
#r_hat = 전체 평점 + 사용자 유저에 대한 평가 경향 + 아이템에 대한 평가 경향 + 사용자 요인에 대해서 i번째 사용자에 대한 요인값
prediction = self.b + self.b_u[i] + self.b_d[j] + self.P[i,:].dot(self.Q[j,].T)
return prediction
#sgd 구하기 : 최적의 P, Q, b_u, b_d 구하기
def sgd(self):
for i, j, r in self.samples:
prediction = self.get_prediction(i,j)
#오차 계산) 실제값과 예측값의 차이
e = r - prediction
#사진 1 참고
self.b_u[i] += self.alpha * (e - self.beta * self.b_u[i])
self.b_d[j] += self.alpha * (e - self.beta * self.b_d[j])
#사진 2 참고
self.P[i,:] += self.alpha * ((e * self.Q[j,:]) - (self.beta * self.P[i,:]))
self.Q[j,:] += self.alpha * ((e * self.P[i,:]) - (self.beta * self.Q[j,:]))
R_temp = ratings.pivot(index='user_id',
columns='movie_id',
values='rating').fillna(0)
hyper_params = {
'K' : 30,
'alpha' : 0.001,
'beta' : 0.02,
'iterations' : 100,
'verbose' : True
}
mf = MF(R_temp, hyper_params)
train_process = mf.train()
SGD를 이용한 기본적인 MF 알고리즘을 학습한 결과, 반복 횟수가 증가할수록 오차가 줄어드는 것을 확인할 수 있다. 가장 낮은 RMSE는 0.8853으로, 이웃과 평가 경향을 고려한 사용자 기반 협업 필터링보다 더 좋은 성능을 보인다. 물론, 이번 실습에서는 train/test set으로 분할하지 않았기에 좋은 성능을 보이는 것이 자명하다.
💡 다음 MovieLens 실습에서는 train/test set을 분리하여 SGD를 이용한 MF 알고리즘을 진행한다.
- train/test set 분할
### 데이터 읽는 과정 생략 ###
from sklearn.utils import shuffle #데이터가 imbalance하면 계층화추출, balance하면 셔플(계층화 추출하면, 표본의 대표성을 저해할 수 있기 때문)
TRAIN_SIZE = 0.75
#(사용자 - 영화 - 평점)
ratings = shuffle(ratings,random_state=2021)
cutoff = int(TRAIN_SIZE * len(ratings))
ratings_train = ratings.iloc[:cutoff]
ratings_test = ratings.iloc[cutoff:]- MF 클래스 정의, 정확도 계산
class NEW_MF():
def __init__(self,ratings,hyper_params):
self.R = np.array(ratings)
#사용자 수(num_users)와 아이템 수 (num_items)를 받아온다.
self.num_users,self.num_items = np.shape(self.R)
#아래는 MF weight 조절을 위한 하이퍼 파라미터
# K : 잠재요인(Latent Factor)의 수
self.K = hyper_params['K']
# alpha : 학습률
self.alpha = hyper_params['alpha']
# beta : 정규화 계수
self.beta = hyper_params['beta']
# iterations : SGD의 계산을 할 때의 반복 횟수
self.iterations = hyper_params['iterations']
# verbose : SGD의 학습 과정을 중간중간에 출력할 것인지에 대한 여부
self.verbose = hyper_params['verbose']
# 데이터가 연속적이지 않을 때, 인덱스와 맞지 않는 것을 방지하기위해 맵핑해주는 작업
item_id_index = []
index_item_id = []
for i, one_id in enumerate(ratings):
item_id_index.append([one_id, i])
index_item_id.append([i, one_id])
self.item_id_index = dict(item_id_index)
self.index_item_id = dict(index_item_id)
user_id_index = []
index_user_id = []
for i, one_id in enumerate(ratings.T):
user_id_index.append([one_id, i])
index_user_id.append([i, one_id])
self.user_id_index = dict(user_id_index)
self.index_user_id = dict(index_user_id)
def rmse(self):
# self.R에서 평점이 있는(0이 아닌) 요소의 인덱스를 가져온다.
xs,ys = self.R.nonzero()
# prediction과 error를 담을 리스트 변수 초기화
self.predictions = []
self.errors = []
# 평점이 있는 요소(사용자 x, 아이템 y) 각각에 대해서 아래의 코드를 실행
for x,y in zip(xs,ys):
#사용자 x, 아이템 y에 대해서 평점 예측치를 get_prediction()함수를 사용해서 계산
prediction=self.get_prediction(x,y)
# 예측값을 예측값 리스트에 추가
self.predictions.append(prediction)
# 실제값(R)과 예측값의 차이(errors) 계산해서 오차값 리스트에 추가
self.errors.append(self.R[x,y] - prediction)
#예측값 리스트와 오차값 리스트를 numpy array형태로 변환
self.predictions = np.array(self.predictions)
self.errors = np.array(self.errors)
#error를 활용해서 RMSE 도출
return np.sqrt(np.mean(self.errors**2))
def sgd(self):
for i,j,r in self.samples:
#사용자 i 아이템 j에 대한 평점 예측치 계산
prediction = self.get_prediction(i,j)
# 실제 평점과 비교한 오차 계산
e = (r - prediction)
# 사용자 평가 경향 계산 및 업데이트
self.b_u[i] += self.alpha *(e - (self.beta * self.b_u[i]))
# 아이템 평가 경향 계산 및 업데이트
self.b_d[j] += self.alpha *(e - (self.beta * self.b_d[j]))
# P 행렬 계산 및 업데이트
self.P[i,:] += self.alpha * ((e * self.Q[j,:]) - (self.beta * self.P[i,:]))
# Q 행렬 계산 및 업데이트
self.Q[j,:] += self.alpha * ((e * self.P[i,:]) - (self.beta * self.Q[j,:]))
def get_prediction(self,i,j):#평점 예측값 구하는 함수
#전체 평점 + 사용자 평가 경향 + 아이템에 대한 평가 경향 + i번쨰 사용자의 요인과 j번째 아이템 요인의 행렬 곱
prediction = self.b + self.b_u[i] + self.b_d[j] + self.P[i,:].dot(self.Q[j,:].T)
return prediction
# Test Set 선정
def set_test(self,ratings_test):
test_set = []
for i in range(len(ratings_test)):
x = self.user_id_index[ratings_test.iloc[i,0]] # 사용자 id
y = self.item_id_index[ratings_test.iloc[i,1]] # 영화 id
z = ratings_test.iloc[i,2] # 평점
test_set.append([x,y,z])
self.R[x,y] = 0
self.test_set = test_set
return test_set
# Test Set RMSE 계산
def test_rmse(self):
error = 0
for one_set in self.test_set:
predicted = self.get_prediction(one_set[0], one_set[1])
error += pow(one_set[2] - predicted, 2)
return np.sqrt(error/len(self.test_set))
def test(self):
self.P = np.random.normal(scale=1./self.K,
size = (self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K,
size = (self.num_items, self.K))
#사용자 평가 경향도 초기화; 0으로부터 시작
self.b_u = np.zeros(self.num_users)
self.b_d = np.zeros(self.num_items)
self.b = np.mean(self.R[self.R.nonzero()])
rows, columns = self.R.nonzero()
self.samples = [(i,j, self.R[i,j]) for i,j in zip(rows, columns)]
training_process = []
for i in range(self.iterations):
np.random.shuffle(self.samples)
self.sgd()
rmse1 = self.rmse()
rmse2 = self.test_rmse()
training_process.append((i+1, rmse1, rmse2))
if self.verbose:
if (i+1) % 10 == 0:
print('Iteration : %d ; Train RMSE = %.4f ; Test RMSE = %4f'% (i+1, rmse1, rmse2))
return training_process
def get_one_prediction(self, user_id, item_id):
return self.get_prediction(self.user_id_index[user_id],
self.item_id_index[item_id])
def full_prediction(self):
return self.b + self.b_u[:, np.newaxis] + self.b_d[np.newaxis, :] + self.P.dot(self.Q.T)
R_temp = ratings.pivot(index='user_id',
columns='movie_id',
values='rating').fillna(0)
hyper_params = {
'K' : 30,
'alpha' : 0.001,
'beta' : 0.02,
'iterations' : 100,
'verbose' : True
}
mf = NEW_MF(R_temp, hyper_params)
test_set = mf.set_test(ratings_test)
result = mf.test()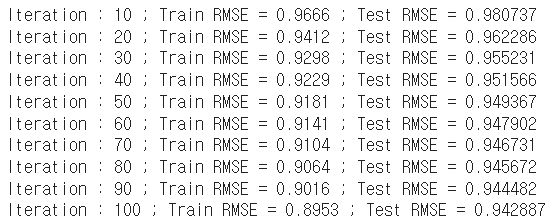
train/test set으로 분할하여 SGD를 이용한 MF 알고리즘을 진행한 결과, RMSE가 가장 낮을 때 0.943으로 이웃과 평가 경향을 고려한 사용자 기반 협업 필터링과 비슷한 성능을 보임을 알 수 있다.
- 예측 평점 행렬
print(mf.full_prediction())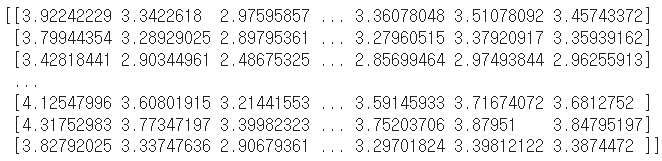
위의 예측 평점 행렬에서 각 행은 사용자 i의 영화들에 대한 예측 평점을 의미한다.
MF의 최적 파라미터 찾기
MF에서 사용되는 K, iterations, alpha, beta 등 다양한 파라미터를 실험을 통해서 가장 성능이 좋은 최적의 파라미터로 설정하는 과정이 필요하다.
MF의 최적 파라미터를 찾는 순서
(K -> iterations -> ...)
- 대략적인 최적의 K 위치 찾기
- 대략적 K 주변 탐색으로 최적 K 찾기
- K값을 고정한 후 최적의 iterations 선택
- K와 iterations를 고정하고 다른 최적의 파라미터 찾으면서 반복하기
MF vs SVD
MF, SVD는 기계학습에 널리 사용되는 기법이지만, 명백히 다름
-
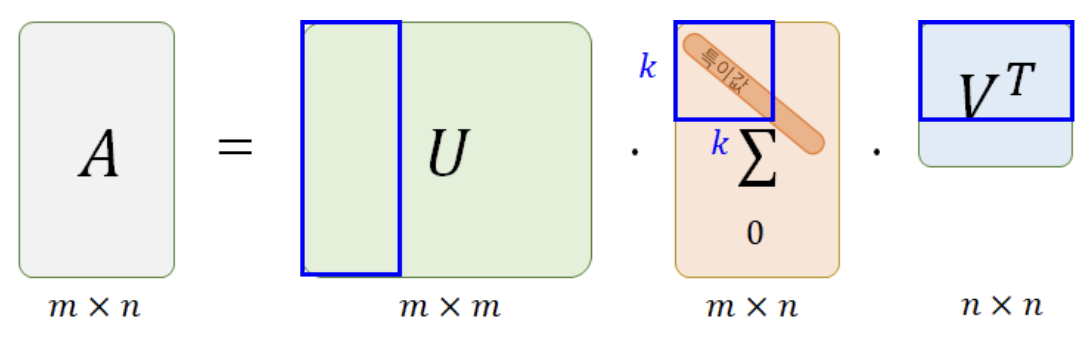
SVD: 기본 행렬 R을 3개의 행렬로 분해하고 학습한 후 3개의 행렬로 본 행렬 R을 재현하는 기법- But, 본 행렬에 Null값을 허용하지 않으므로 본 행렬에 없는 값을 예측하는 데에는 문제가 있음
- Null값 대신 0으로 대체하면 0을 특정한 값으로 인식해 추후 예측 시에 0에 최대한 가까운 값이 나오도록 예측되는 문제 발생
-
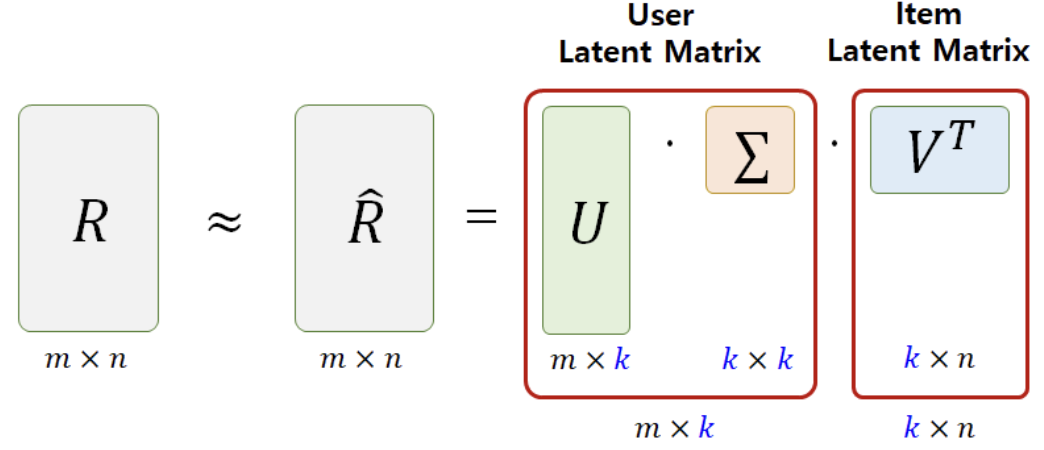
MF: 기본 행렬 R을 두 개의 행렬로 분해하여 학습- Null값을 0으로 표현하지만, P와 Q 행렬에서 0은 제외하고 계산하므로 사실상 Null값을 제외하고 계산하는 구조
- 즉, 본 행렬에 Null값이 있었다 하더라도, P/Q 행렬에는 Null값이 없기 때문에 학습이 끝나면 P/Q를 사용해서 본 행렬의 Null값에 대해서도 상당히 정확한 예측이 가능한 특징을 가짐
- SVD의 구조
- MF의 구조

좋은 글 잘보고 갑니다. 그런데 요즘은 mf를 잘 사용하지 않으려고 하는 기술적 경향이 있는것 같습니다.
그 이유에 대한 판단이 있으시다면 의견 부탁드립니다 ㅎㅎ