이웃을 고려한 CF
KNN 방법Thresholding 방법
- 일반적으로 Thresholding 방법이 KNN 방법보다 정확
- Thresholding은 정해진 임계치를 넘는 사용자가 없는 경우 추천 불가 -> 보통 KNN 방법 사용
💡 이웃을 고려한 CF - MovieLens 실습에서는 먼저 사용자간 유사도를 계산하고, KNN 방법을 통해 추천 대상이 평가한 영화에 대해 예상 평가값을 계산해 실제값과 비교하여 정확도를 계산하고, 실제 사용자에게 영화를 추천한다.
- 데이터 입력, 함수 정의, 사용자간 유사도 계산
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 데이터 불러오기 및 데이터 셋 만들기
# base_src = ' ' # 데이터 경로
u_user_src = os.path.join(base_src, 'u.user')
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv(u_user_src,
sep = '|',
names = u_cols,
encoding = 'latin-1')
users = users.set_index('user_id')
u_item_src = os.path.join(base_src, 'u.item')
i_cols = ['movie_id', 'title', 'release data', 'video release data',
'IMDB URL', 'unknown', 'Action', 'Adventure', 'Animation',
'Children\'s', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy',
'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi',
'Thriller', 'War', 'Western']
movies = pd.read_csv(u_item_src,
sep = '|',
names = i_cols,
encoding = 'latin-1')
movies = movies.set_index('movie_id')
u_data_src = os.path.join(base_src, 'u.data')
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(u_data_src,
sep = '\t',
names = r_cols,
encoding = 'latin-1')
def RMSE(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true) - np.array(y_pred))**2))
# 유사집단의 크기를 미리 정하기 위해서 기존 score 함수에 neighbor_size 인자값 추가
def score(model, neighbor_size = 0):
# 테스트 데이터의 user_id와 movie_id 간 pair를 맞춰 튜플형원소 리스트 데이터를 만듬
id_pairs = zip(x_test['user_id'], x_test['movie_id'])
# 모든 사용자-영화 짝에 대해서 주어진 예측모델에 의해 예측값 계산 및 리스트형 데이터 생성
y_pred = np.array([model(user, movie, neighbor_size) for (user, movie) in id_pairs])
# 실제 평점값
y_true = np.array(x_test['rating'])
return RMSE(y_true, y_pred)
x = ratings.copy()
y = ratings['user_id']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, stratify = y)
rating_matrix = x_train.pivot(index = 'user_id', columns = 'movie_id', values = 'rating')
# train set의 모든 가능한 사용자 pair의 cosine similarities 계산
# cosine similarity를 계산하는 사이킷런 라이브러리 import
from sklearn.metrics.pairwise import cosine_similarity
# cosine similarity를 구하기 위해 rating값을 복사하고, 계산 시 NaN값 에러 대비를 위해 결측치를 0으로 대체
matrix_dummy = rating_matrix.copy().fillna(0)
# 모든 사용자간 cosine similarity 구함
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
# 필요한 값 조회를 위해서 인덱스 및 컬럼명 지정
user_similarity = pd.DataFrame(user_similarity,
index = rating_matrix.index,
columns = rating_matrix.index)- KNN 방법으로 예측치, 정확도 계산
def CF_knn(user_id, movie_id, neighbor_size = 0):
if movie_id in rating_matrix.columns:
sim_scores = user_similarity[user_id].copy()
movie_ratings = rating_matrix[movie_id].copy()
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
movie_ratings = movie_ratings.dropna()
sim_scores = sim_scores.drop(none_rating_idx)
if neighbor_size == 0:
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
if len(sim_scores) > 1:
neighbor_size = min(neighbor_size, len(sim_scores))
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
user_idx = np.argsort(sim_scores)
sim_scores = sim_scores[user_idx][-neighbor_size:]
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
mean_rating = 3.0
else:
mean_rating = 3.0
return mean_rating
# 정확도 계산
score(CF_knn, neighbor_size = 30)
KNN 방법을 적용해 이웃을 30으로 설정했을 때의 RMSE는 약 1.008로, 이웃을 적용하지 않은 기본 CF 알고리즘에서의 결과보다 개선되었음을 알 수 있다.
- 실제 사용자에게 영화 추천
# 실제 주어진 사용자에 대해 추천을 받는 기능 구현
rating_matrix = ratings.pivot_table(values = 'rating',
index = 'user_id',
columns = 'movie_id')
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity,
index = rating_matrix.index,
columns = rating_matrix.index)
# 추천 로직
def recom_movie(user_id, n_items, neighbor_size = 30):
user_movie = rating_matrix.loc[user_id].copy()
for movie in rating_matrix.columns:
if pd.notnull(user_movie.loc[movie]):
user_movie.loc[movie] = 0
else:
user_movie.loc[movie] = CF_knn(user_id, movie, neighbor_size)
movie_sort = user_movie.sort_values(ascending = False)[:n_items]
recom_movies = movies.loc[movie_sort.index]
recommendations = recom_movies['title']
return recommendations
recom_movie(user_id = 729, n_items = 5, neighbor_size = 30) 
최적의 이웃 크기 결정
-
위에서 진행했던 코드는 neighbor_size를 임의로 30으로 지정해서 진행했지만 성과(추천의 정확도)가 최대가 되는 집단의 크기는 정해져 있는 것이 아니기 때문에 각각의 데이터를 다룰 때마다 달라져야 한다.
-
집단의 크기에 따른 성과 곡선이 아래 그림과 같이 나타나는 이유는 집단의 크기가 너무 커진다면 집단 전체에 대한, 즉 베스트 셀러 방식과 동일해진다. 반대로 집단의 크기가 너무 작아지면 신뢰성이 떨어지게 된다. 결국 이러한 underfitting 또는 overfitting을 방지하는 방법은 실험적으로 성과가 최대가 되는 집단의 크기를 판단하는 것이다.
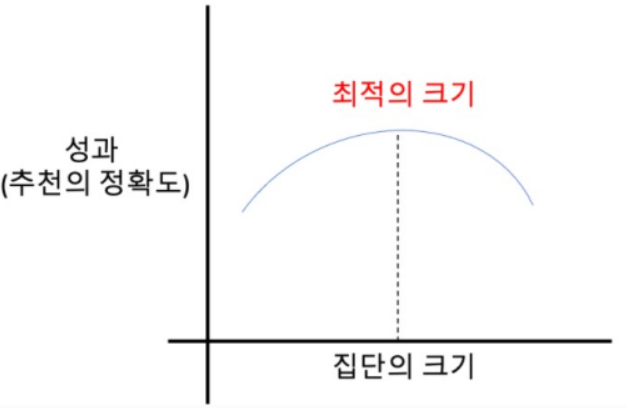
- 이웃의 크기를 바꿔가며 정확도 계산 (GridSearch)
# neighbor_size가 10, 20, 30, 40, 50, 60인 경우에 대해서 RMSE를 계산하고 이를 출력한다.
for neighbor_size in [10, 20, 30, 40, 50, 60]:
print('Neighbor size = %d : RMSE = %.4f'%(neighbor_size, score(CF_knn, neighbor_size)))
사용자의 평가 경향을 고려한 CF
사용자의 평가 경향을 고려해야 하는 이유
- 평가를 전체적으로 후하게 또는 박하게 하는 사용자가 존재
- 평가 경향을 고려해 예측치를 조정하면 CF의 정확도를 개선시킬 수 있다.
평가 경향을 고려한 CF 알고리즘을 통한 추천 프로세스

- 각 사용자 평점 평균 계산
- 평점 편차 = (평점 - 해당 사용자의 평점 평균)
- 평점 편차의 예측값 계산
- 평가값 = 평점 편차 x 다른 사용자 유사도
- 실제 예측값 = 평점 예측값 + 평점 평균
💡 평가 경향을 고려한 CF - MovieLens 실습에서는 먼저 사용자간 유사도를 계산하고, KNN 방법에 평가 경향을 추가 고려해 예측값을 계산해 실제값과 비교하여 정확도를 계산한다.
- 사용자의 평가 경향을 고려해 예측치, 정확도 계산
rating_mean = rating_matrix.mean(axis = 1)
rating_bias = (rating_matrix.T - rating_mean).T
def CF_knn_bias(user_id, book_id, neighbor_size = 0):
if book_id in rating_bias.columns:
sim_scores = user_similarity[user_id].copy()
book_ratings = rating_bias[book_id].copy()
none_rating_idx = book_ratings[book_ratings.isnull()].index
book_ratings = book_ratings.drop(none_rating_idx)
sim_scores = sim_scores.drop(none_rating_idx)
if neighbor_size == 0:
prediction = np.dot(sim_scores, book_ratings) / sim_scores.sum()
prediction = prediction + rating_mean[user_id]
else:
if len(sim_scores) > 1:
neighbor_size = min(neighbor_size, len(sim_scores))
sim_scores = np.array(sim_scores)
book_ratings = np.array(book_ratings)
user_idx = np.argsort(sim_scores)
sim_scores = sim_scores[user_idx][-neighbor_size:]
book_ratings = book_ratings[user_idx][-neighbor_size:]
prediction = np.dot(sim_scores, book_ratings) / sim_scores.sum()
prediction = prediction + rating_mean[user_id]
else:
prediction = rating_mean[user_id]
else:
prediction = rating_mean[user_id]
return prediction
score(CF_knn_bias, 30)사용자의 평가 경향을 추가 고려할 때의 RMSE는 약 0.942로, 앞서 KNN 방법만을 적용한 CF 알고리즘에서의 결과보다 개선되었음을 알 수 있다.
그 외의 CF 정확도 개선 방법
1) 정규화 (Normalization)
- 사용자의 평가 경향을 고려한 방식
- 사용자의 평가를 각자의 평균, 표준편차로 정규화
2) 분산 가중치 (Variance weighting)
- 아이템 별 분산을 고려하여 가중치 부여
사용자의 아이템 분산이 작으면 추천할 아이템 카테고리가 작아진다. - 사용자의 아이템 분산이 커지면 추천할 아이템 카테고리가 커진다.
3) 결측값 채우기 (Default rating)
- 빈 칸을 채워서 추천의 범위를 넓히는 방식
- 추천의 범위는 넓어지지만 올바른 추천이 아닐 수 있다.
4) 시간 고려 (Time dependent rating)
- 각 사용자들이 평가한 시점이 가까운지 멀리 있는지 고려하여 평가
5) 신뢰도 가중 (Significance weights)
- 같은 유사도를 가진 이웃이 있더라도
공통 평가의 개수가 많을수록 가중치를 더 부여
