
2020.12.22 ~ 2021.2.19일 까지의 Lablup에서의 internship 후기를 남겨보려고 한다.
Internship 지원과정
국민대 소프트웨어학부에서는 매 방학마다 IT회사와의 internship 기회를 제공한다. 나는 이번이 4학년 2학기 겨울방학이였는데 보통은 이 시기에 다들 취업준비를 한다고 한다.
근데 무언가 아직 취직준비를 하기 보다는 좀 더 현업이 어떤지를 느껴보고 contribution을 해보고 싶다는 생각이 강하게 들었다.
그래서 이번 겨울 방학에도 internship 프로그램을 지원하게 되었다.

위 사진의 프로그래머스 공고사항을 보고 내 관심역량에 따라 다양한 업무 가능, 그리고 '머신러닝 플랫폼을 활용하여 실제 모델 학습 및 데이터 분석을 해보고 싶은 사람'에 꽂혀서 지원하게 되었다. 저번 Common Computer internship에서도 머신러닝 관련 프로젝트를 많이 했는데 무언가 기여할 수 있겠다 라는 느낌이 많이 들었다.
공고에 지원한 뒤 종현님과 면접을 통해서 합격하였다. (YEAHHHH!!)

Lablup은 무엇을 하는 회사인가?
나는 항상 internship을 할때마다 senior 분들에게 여쭤보는 부분이 있다. 회사가 개발하는 것이 무엇이고, 어떤 BM을 가지고 있는지에 대해서 보통 여쭤본다. 왜냐하면 내가 일하는 회사가 어떤 일을 하는지, 내가 무얼 만드는지도 모르는 사람이 되고 싶지 않기 때문이다.
AI 연구를 위한 리소스 관리 플랫폼인 Backend.AI를 오픈소스로 개발하는 회사.
한 마디로 삽질을 줄여주는 회사이다.(거 해보시면 압니다.. 이게 얼마나 빛과 소금인지)
AI 관련 프로젝트를 하다보면 정말 짜증나는 경우들이 많다. 특히 모델을 돌리기 위해서 사전작업들이 필요한데. 모델이 필요로하는 dependency 설정이나, 모델을 돌리기 위한 tool 같은걸 직접 install 하고 pytorch나 tensorflow를 사용할 때면 모델이 사용하는 여러 라이브러리들을 일일이 설치하고 버전 관리도 했어야 했다.
이전 인턴 때 한 senior분이 이런 말씀을 해주셨다.
삽질도 30분 이상 넘어가면 낭비라고 생각합니다. 스스로 삽질하면서 깨치는 것도 중요하지만 삽질도 삽질 by 삽질이라서... 일단 30분 넘게 안되면 그냥 나한테 물어보세요. 그리고 이걸 기록해두고 다른 사람은 삽질 안하게 합시다!
이런 짜증나는 작업들, 알고 있고 혹은 모른다 하더라도 크게 보았을때 시간 낭비 삽질인 부분을 Lablup에서는 Backend.ai 라는 product를 통해서 도와준다. 미리 만들어놓은 kernel image를 통해서 사용자들은 위와 같이 귀찮고 짜증나는 일련의 과정들을 겪을 필요 없이 사용만 하면 되는것이다!
나는 무엇을 했나?
- Make Apache-Spark kernel Image
- Make python kernel Image
- Make minecraft bedrock-serve Image
- Docsprint
- Translate tutorial of Backend.ai (English -> Korean)
대략 요약하자면 위와 같은 일들을 하였다.
python kernel 이미지와 minecraft kernel image는 main task인 Apahe-Spark image를 만들기 위해서 연습해본 것이라고 보면 된다. 일종의 튜토리얼 과정 이였지만.. 내가 이해력이 부족해서 그런지 이런저런 Trouble들을 많이 겪었고 특히 Apache-Spark에서는 Troubleshooting을 위해서 꽤나 고생했던 기억이 있다.
Docsprint는 Lablup에서는 docs를 sphinx를 이용해서 관리하는데 docs의 버전이 꽤 오래되어서 회사분들 다같이 1~3일 동안 Document를 정리하는 시간을 가졌다. (Documentation + Sprint)여서 Docsprint가 아닐까...?
그리고 ppt로 된 Backend.ai 튜토리얼이 있었는데 실제로 Backend.ai가 무엇인지 파악하기 위해서 이것을 읽고 실습해보았다. 그 과정에서 혹시 한국인 client가 있을 수도 있기에 이를 한국어로 번역하는 일을 다른 인턴분과 함께 하게 되었다.
Process of Making kernel image
kernel image를 만들기 위해서 대략 아래와 같은 순서에 따라 개발하였다.
- OP에서 task를 할당 받고 (OP : Open Project)
- 할당 받은 task의 image에 대해서 무엇인지 학습
- 필요한 Dependency 확인 및 Dockerfile 작성
- 작성된 Dockerfile을 local Macbook에서 test
- Test후에 LABLE을 하단부에 붙여넣기
- 완성된 Dockerfile 과 service-def를 hub에 push
- backend.ai 로 test 및 Troubleshooting
- PR & code Review
- Merge
Troubleshooting for Apache-Spark
Spark kernel image를 만들면서 겪었던 몇 가지 Trouble을 공유해보려고 한다. Trouble들을 정리해보자면 대략 아래와 같다.
- Dockerfile에서 ENV에 설정해둔 것이 적용 안되었던 문제
- spark-master.sh를 통해서 서버 log를 작성하는 dir이 만들어지는데 이게 권한이 없어서 error가 나는 문제
- API endpoint error
1. Dockerfile에서 ENV에 설정해둔 것이 적용 안되었던 문제
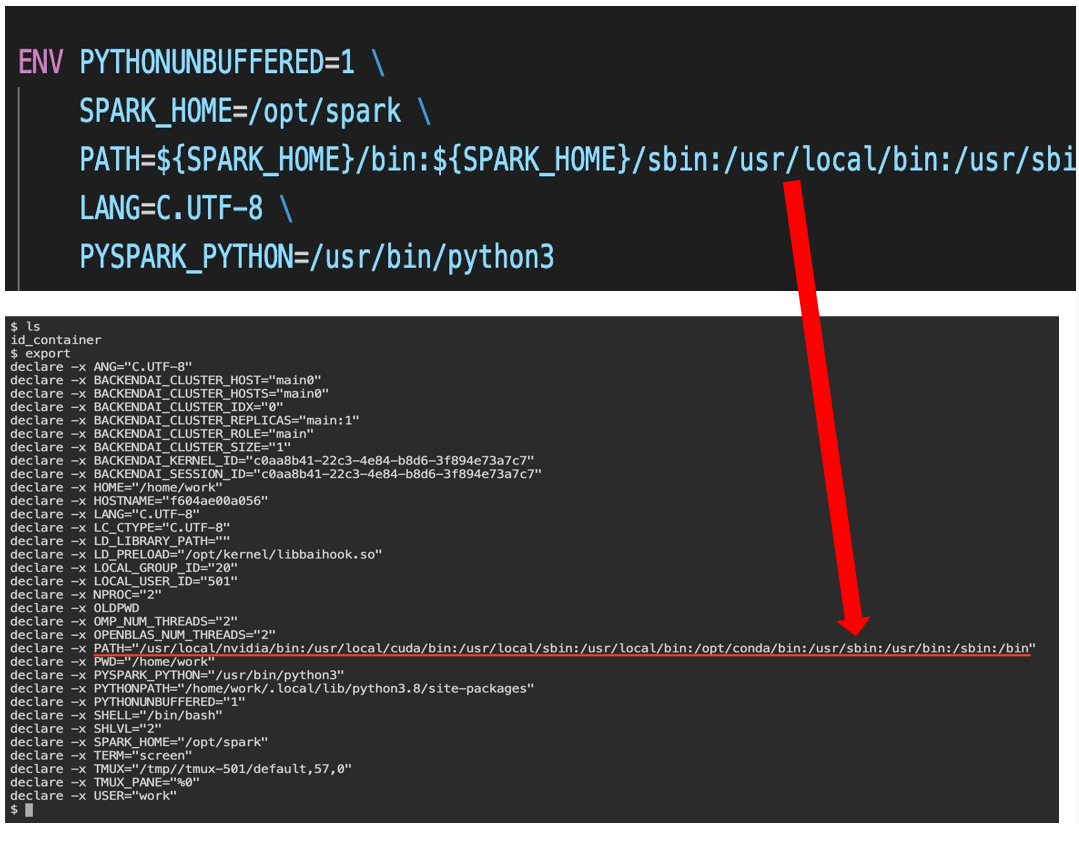 1번은 진짜 이게 어이없는 삽질이였던게 어떻게~~~해도해도 안되서 여쭤보니.. 그냥 내 backend.ai 버전이 너무 뒤쳐져있었던 것이 문제였다. 이미 이전에 고쳐진 bug였는데 devOps 경험이 일천한 나머지 자주 pull을 해야하는 것을 몰랐다. git pull하고 version conflict나는 것들을 해결해주니 바로 해결되었다...
1번은 진짜 이게 어이없는 삽질이였던게 어떻게~~~해도해도 안되서 여쭤보니.. 그냥 내 backend.ai 버전이 너무 뒤쳐져있었던 것이 문제였다. 이미 이전에 고쳐진 bug였는데 devOps 경험이 일천한 나머지 자주 pull을 해야하는 것을 몰랐다. git pull하고 version conflict나는 것들을 해결해주니 바로 해결되었다...
2. Permission denied 문제
2번 문제는 /opt 하단에 spark 바이너리 파일들과 패키지 라이브러리들이 존재하는데 Backend.ai 에서 부여하는 권한으로는 /opt에 read, execute만 가능할 뿐 write하는 권한이 없었다. 보안 개념상으로는 당연한 얘기이다. 그래서 이를 해결하기 위해서 bootstrap.sh 파일을 이용해 container가 켜지는 동시에 /opt/spark 디렉토리를 /home/work 아래로 copy하게 했었다. 근본적인 해결책은 아니였지만 먹히긴 했다(후술하겠지만 이렇게 해결하진 않았고 다른 3번 에러와 맞닿드리면서 이 방법도 바꾸었다).
보안 개념상으로는 당연한 얘기이다. 그래서 이를 해결하기 위해서 bootstrap.sh 파일을 이용해 container가 켜지는 동시에 /opt/spark 디렉토리를 /home/work 아래로 copy하게 했었다. 근본적인 해결책은 아니였지만 먹히긴 했다(후술하겠지만 이렇게 해결하진 않았고 다른 3번 에러와 맞닿드리면서 이 방법도 바꾸었다).
3. API endpoint error
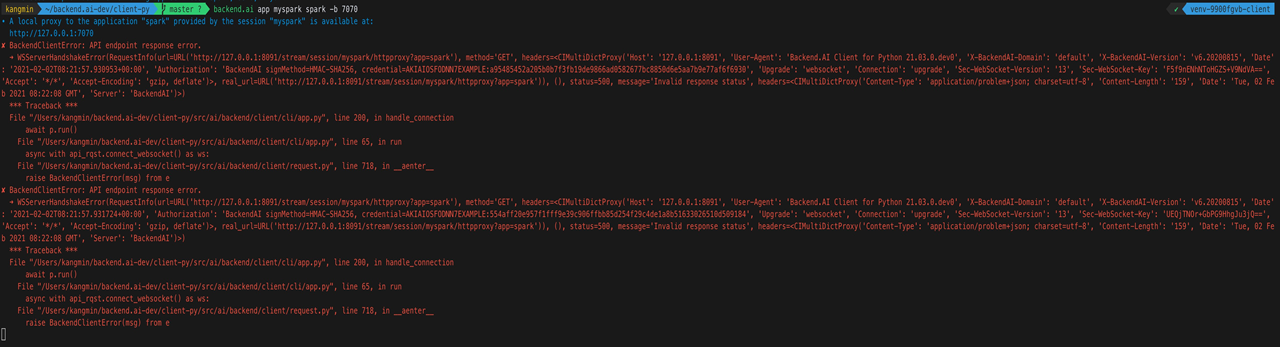 이 문제는 app이 부팅하는데 시간이 걸려서 나는 문제였다. 그럼 시간이 안걸리게 바로 켜지게 하면 되잖아?! 이런 생각 하에
이 문제는 app이 부팅하는데 시간이 걸려서 나는 문제였다. 그럼 시간이 안걸리게 바로 켜지게 하면 되잖아?! 이런 생각 하에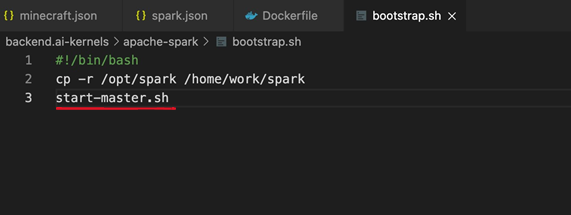 이렇게 container가 켜지자마자 start-master.sh를 실행해버렸다. 에러 안뜨고 잘 실행은 되었지만.. 시니어 분께서 '패키지 바이너리가 홈 디렉토리 하단에 들어갈 필요가 없다' 고 말씀하셔서 2,3번을 모두 같이 고쳐야만 했다. 즉 최적화 작업에 들어갔다.
이렇게 container가 켜지자마자 start-master.sh를 실행해버렸다. 에러 안뜨고 잘 실행은 되었지만.. 시니어 분께서 '패키지 바이너리가 홈 디렉토리 하단에 들어갈 필요가 없다' 고 말씀하셔서 2,3번을 모두 같이 고쳐야만 했다. 즉 최적화 작업에 들어갔다.
Optimize kernel image
일단 패키지 바이너리를 home에서 빼면 bootstap.sh에서 copy하는 부분을 없애야 했고 이렇게 되면 2번 문제가 해결이 되지 않았다. (아ㄴ ㅣ.. 다시 되돌아가라고..?!!) 다행스럽게도 해결방법은 있었다. 이런 spark와 같이 규모가 큰 프로젝트는 따로 작업 디렉토리를 지정할 수 있는 방법이 있을거다라는 힌트를 주셨다. 역시 찾아보니 그러한 방법이 있었다. spark-env.sh에서 export SPARK_LOG_DIR 을 이용해 위치를 따로 지정해줄 수 있었다. 이를 bootstarp.sh에 추가하여 해결하였다. 그리고 이렇게 함으로써 spark를 work권한으로 실행할 수 있게되었다.
ref)https://hoyy.github.io/posts/spark-start-install-standalone 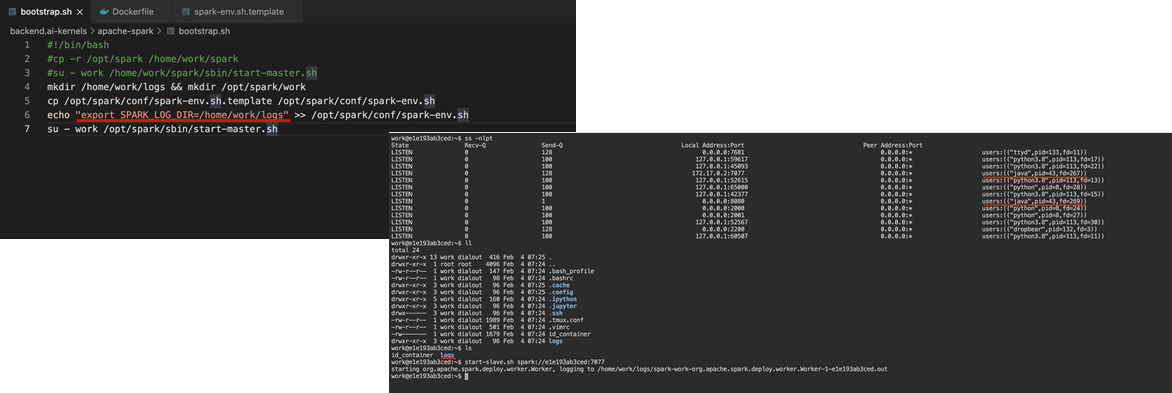
그리곤 pyspark를 jupyter notebook과 연동되게끔 만들어보자는 task도 같이 진행했다. 이건 쉬웠던 것이 Dockerfile에서 pip install을 통해 받아온 후 backend.ai로 jupyter notebook을 실행하면 아래와 같이 문제 없이 잘 실행되었다.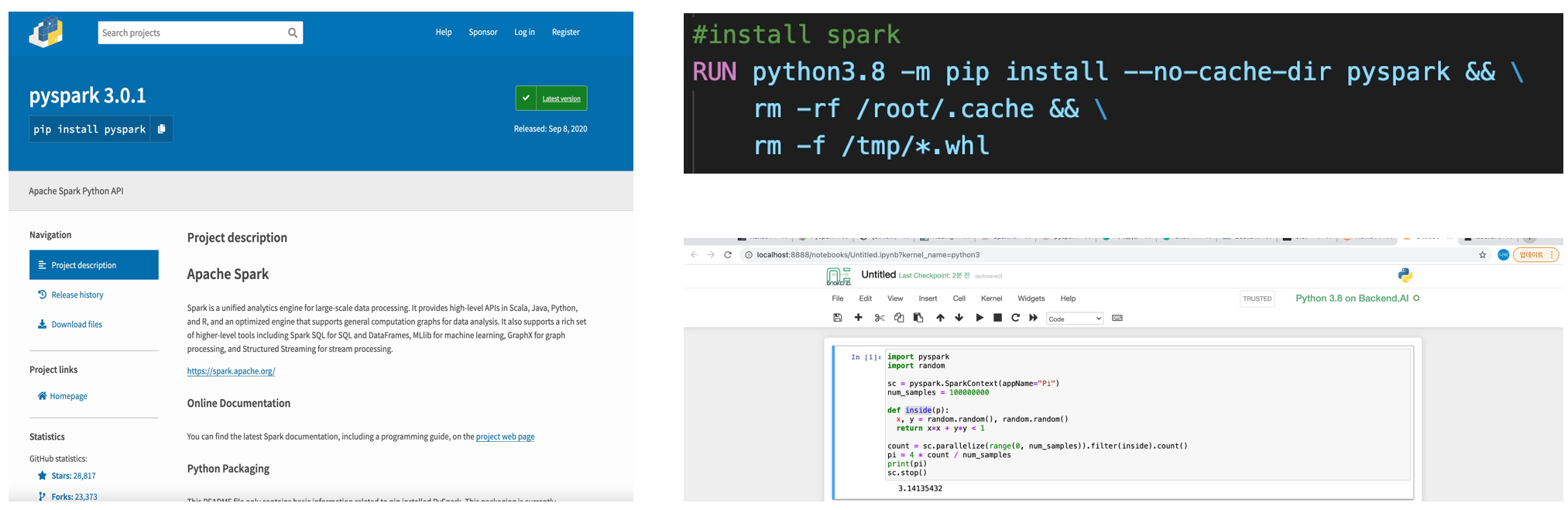
마지막으로 Dockerfile의 overlayfs을 특성을 이용해서 최대한 docker images들에 올라와 있는 나머지 image들과 비슷하게 Dockerfile을 작성했다.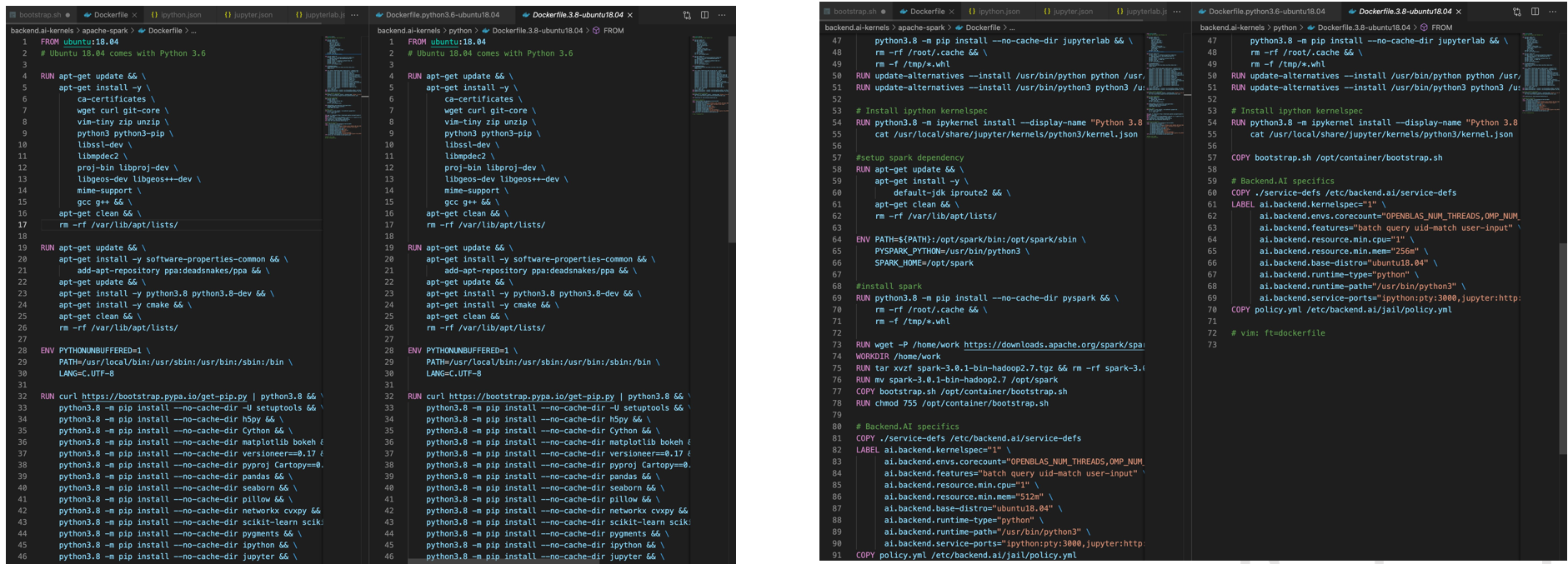 최대한 다른 이미지들과 같은 부분을 그대로 이용하고 그 이후에 달라지는 부분을 뒤로 미뤄야했다. 이렇게 해야만 resource들을 아낄 수 있다. container가 작은 size일 경우에는 아무 문제가 없지만.. image가 점점 쌓이고 나중엔 크기가 40~50G가 될 경우엔 낭비되는 자원이 꽤 크게 될 것이기에 이런 최적화 작업이 중요하다.
최대한 다른 이미지들과 같은 부분을 그대로 이용하고 그 이후에 달라지는 부분을 뒤로 미뤄야했다. 이렇게 해야만 resource들을 아낄 수 있다. container가 작은 size일 경우에는 아무 문제가 없지만.. image가 점점 쌓이고 나중엔 크기가 40~50G가 될 경우엔 낭비되는 자원이 꽤 크게 될 것이기에 이런 최적화 작업이 중요하다.
ref)
https://devaom.tistory.com/5
https://www.joinc.co.kr/w/man/12/docker/storage
https://blog.naver.com/alice_k106/221530340759
Contribution
온갖 고생 끝에 만든 Apache-Spark 커널 이미지를 merge 하는데 마침내 성공하였다. 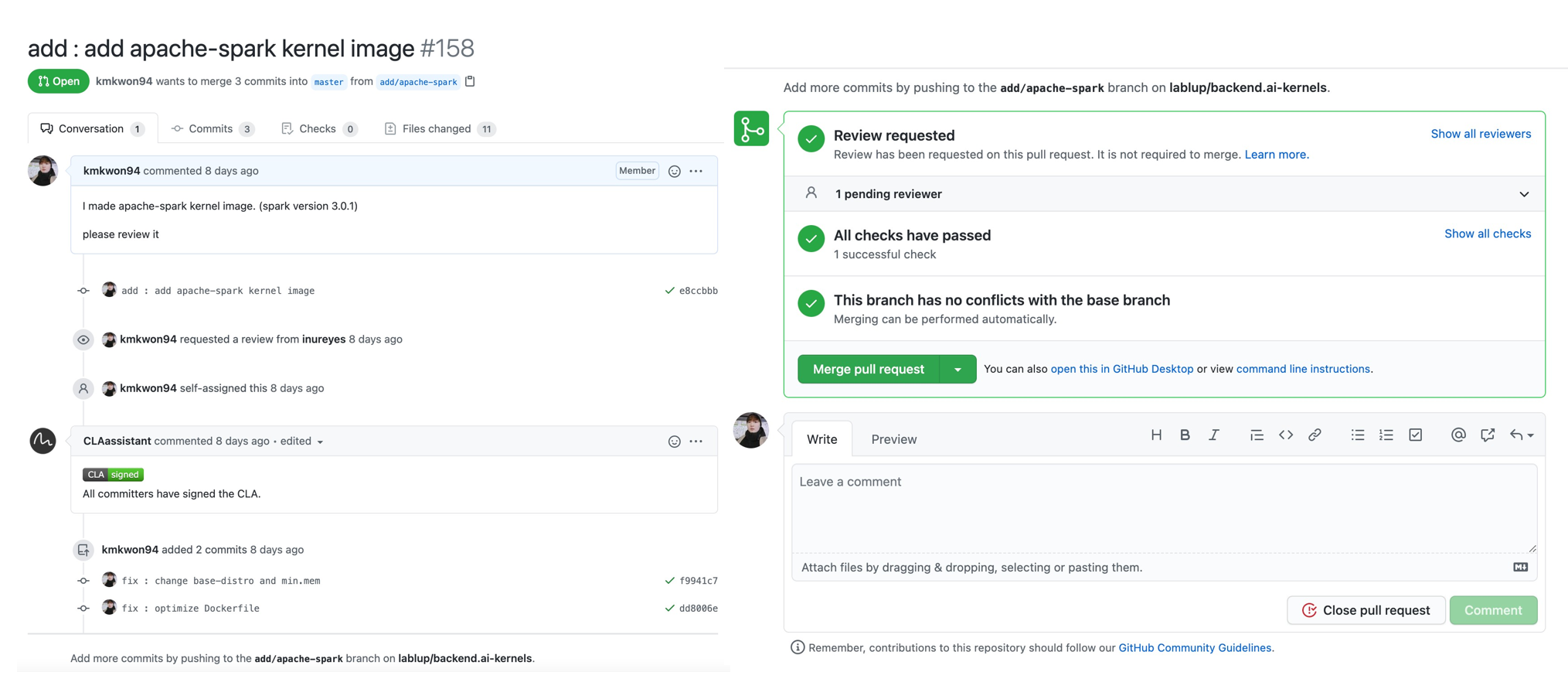
후기
이번 인턴쉽에서는 backend.ai 라는 product을 다루고 사람들이 바로 사용할 수 있는 커널 이미지를 만들어서 기여한 매우 뜻깊은 경험이였다. 코로나의 여파로 회사에 출근해서 일 하는 것이 더 즐거웠을 정도로, 대다수는 재택근무였다. 마지막 날 정규님의 말씀하신게 직접 오프라인에서 인턴분들이 모르는 부분에 대해서 질문도하고 우리가 답변도 하고 이런 심도있는 인턴쉽이 이뤄지지 못한 것이 아쉽다였는데, 무척 공감되는 말씀이였다.
재택에서 근무가 이뤄지다보니 회사에서 일 할때랑은 집중력의 차이가 심하였다. 거의 체감상 1.5배? 로 더 힘들었던 것 같다.
다음에는 정말 오프라인에서 마주보면서 이런저런 이야기도 하고, 개발 외적인 여러 말씀도 들을 기회가 있었으면 좋겠다.
좋은 곳에서 훌륭하신 분들과 일할 수 있어서 유익한 경험이였다.
