대부분의 DBMS의 목적은 많은 데이터를 안전하게 저장 및 관리하고 사용자가 원하는 데이터를 빠르게 조회하는 것이 목적
그렇다면 옵티마이저가 좋은 실행 계획을 수행할 수립할 수 있어야 하며
사용자는 옵티마이저의 실행 계획을 이해할 수 있어야 합니다.
통계 정보
5.7까지는 인덱스에 대한 개괄적인 정보를 가지고 실행 계획을 수립하여
테이블 컬럼의 값 분포의 정보가 없기 때문에 실행 계획 정확도가 떨어지는 경우가 많았습니다.
8.0부터는 인덱스되지 않은 컬럼들에 대해서도 분포도를 수집해서 저장하는 히스토그램 정보가 도입되었습니다.
(그렇다고 인덱스의 통계 정보가 필요치 않은 것은 아님)
테이블 및 인덱스 통계 정보
비용 기반 최적화에서 가장 중요한 것은 통계 정보입니다.
실제 저장된 레코드가 1억건인데 레코드가 10건 미만인 것 처럼 돼 있다면 옵티마이저는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용할 것 입니다.
MySQL 서버의 통계 정보
5.6 부터는 InnoDB Storage Engine을 사용하는 테이블에 대한 통계 정보를 영구적으로 관리할 수 있게 개선되었습니다.
각 테이블의 통계 정보를 innodb_index_stats, innodb_table_stats 테이블로 관리할 수 있게 개선되었습니다.
테이블을 생성할 때 STATS_PERSISTENT옵션을 설정할 수 있습니다.
이 설정에 따라 테이블 단위로 영구적인 통계 정보를 보관할지 결정을 합니다.
Clusted Index, Secondary Index의 페이지 크기 조회
SELECT *
FROM mysql.innodb_tables_stats
WHERE table_name IN (실제 테이블 이름);
전체적인 통계 조회
SELECT *
FROM innodb_table_stats
WHERE database_name='employees'
AND TABLE_NAME = 테이블 명;
5.5까지는 테이블의 통계 정보가 메모리에만 저장되며, 서버 재시작시 통계 정보 초기화
그러나 특정 이벤트에 통계 정보가 갱신이 됩니다.
- 테이블 새로 오픈
- 테이블의 레코드가 대량으로 변경
- ANALYZE TABLE 수행
- INNODB 모니터 활성화
- SHOW TABLE STATUS, SHOW INDEX FROM 명령 실행
.. 이 존재
테이블의 통계 정보가 갱신되면 인덱스 레인지 스캔으로 잘 처리하던 MySQL서버가 갑자기 풀 테이블 스캔으로 실행되는 상황이 발생할 수 있습니다.
innodb_stats_auto_recalc OFF로 설정해서 통계 정보가 자동으로 갱신되는 것을 막을 수 있습니다. (기본 값 ON)
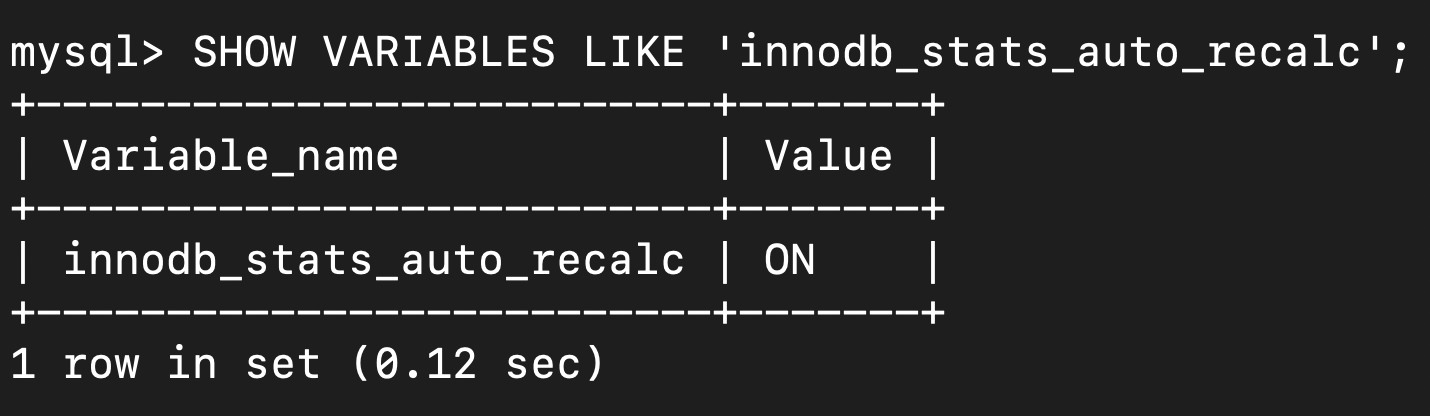
기본적으로 활성화되는 변수 innodb_stats_auto_recalc 는 테이블 행의 10% 이상이 변경될 때 통계가 자동으로 계산되는지 여부를 제어합니다.
영구적인 통계 정보를 이용하고자 한다면 OFF로 설정하기
테이블을 생성할 때 STATS_AUTO_RECALC 설정하기
1 - 통계 정보를 MySQL 5.5 이전의 방식대로 수집
0 - ANALYZE 명령을 실행할 때만 수집
DEFAULT - 통계 정보수집을 시스템 설정 변수로 결정
https://dev.mysql.com/doc/refman/8.0/en/innodb-persistent-stats.html
⭐️ 그래서 킬까 말까? 어쩌라고?
히스토그램
MySQL 5.7까지의 통계 정보는 단순히 인덱스된 컬럼의 유니크한 값의 개수만 가져 이러한 정보만으로는 최적의 실행 계획을 수립하기에는 부족했습니다.
그래서 실제 인덱스의 일부 페이지를 랜덤으로 가져와 참조하는 방식을 사용했으며
8.0부터는 컬럼의 데이터 분포도를 참조할 수 있는 Histogram 정보를 활용할 수 있게 되었습니다.(드디어)
히스토그램 정보 수집 및 삭제
- 8.0버전에서 히스토그램 정보는 컬럼 단위로 관리
- 자동으로 수집되지 않고
ANALYZE TABLE ... UPDATE HISTOGRAM명령으로 수동으로 수집, 관리 - 수집된 히스토그램 정보는 시스템 딕셔너리에 함께 저장, MySQL 서버가 시작될 때
information_schema.column_statistics테이블에 로드
히스토그램 정보 조회
SELECT *
FROM COLUMN_STATISTICS
WHERE SCHEMA_NAME='스키마 이름'
AND TABLE_NAME='테이블 이름';
MySQL 8.0 버전에서는 2종류의 히스토그램 타입이 지원
- Singleton : 컬럼값 개별로 레코드 건수를 관리하는 히스토그램,
Value-Based 히스토그램또는도수 분포라고 불림 - Equi_height(높이 균형) : 컬럼값의 범위를 균등한 개수로 구분해서 관리하는 히스토그램, height-Balanced 히스토그램이라고도 불림
히스토그램은 Bucket단위로 구분되어 레코드 건수나 컬럼값의 범위가 관리
Singleton은 각 버킷이 컬럼의 값과 발생 빈도의 비율의 2개 값을 가짐
주로 코드 값과 같이 유니크한 값의 개수가 상대적으로 적은경우 사용
Example : 성별 M, F에 누적된 레코드 건수의 비율
Equi-Based는 시작 값과 마지막 값, 그리고 발생 빈도율, 각 버킷에 포함된 유니크한 값의 개수 등 4개의 값을 가짐
information_schema.column_statistics 테이블의 내용
sampling-rate : 히스토그램 정보를 수집하기 위해 스캔한 페이지의 비율
0.35라면 35%를 스캔, 샘플링 비율이 높으면 정확한 히스토그램이지만
그만큼 부하가 높다는 것을 의미
MySQ서버는 histogram_generation_max_mem_size 시스템 변수에 설정된 메모리 크기에 맞게 적절히 샘플링
histogram-type : 히스토그램 종류를 저장
number-of-bucket-specified : 히스토그램 생성 시 설정했던 버킷의 개수를 저장, 기본으로 100개이며 최대 1024개 가능하나 100개면 충분한 것으로 알려짐
히스토그램도 삭제할 수 있지만 쿼리의 실행 계획이 달라질 수 있으므로 주의해야 합니다.
ANALYZE TABLE table.column DROP HISTOGRAM ON column1, coumn2;
(히스토그램을 삭제하지 않고 사용하지 않게 하는 방법도 존재)
히스토그램의 용도
히스토그램 정보로 인해 Join에서 드라이빙, 드리븐 테이블이 결정됩니다.
세밀한 히스토그램 정보를 사용하지 않고 전체 레코드 건수나 크기같이 단순한 정보만으로 조인의 드라이빙 테이블을 결저앟게 됩니다.
이로 인해 쿼리의 성능이 10배 차이가 생길 수 있습니다.
히스토그램과 인덱스
조건절에 일치하는 레코드 건수를 예측하기 위해 옵티마이저는 실제 인덱스의 B-Tree를 샘플링해서 살펴봅니다.(Index-Dive라고 표현)
인덱스 컬럼을 검색 조건으로 사용하는 경우 그 컬럼의 히스토그램을 사용하지 않고 실제 인덱스 다이브를 통해 직접 수집한 정보를 활용합니다.
(실제 검색 조건의 대상 값에 대한 샘플링을 실행하는 것이므로 항상 히스토그램보다 정확한 결과를 기대!)
주로 인덱스되지 않은 컬럼에 대한 데이터 분포도를 참조하는 용도로 사용됩니다.
하지만 인덱스 다이브는 어느 정도의 비용이 필요, 때로는 실행 계획 수립만으로 상당한 인덱스 다이브를 실행하고 비용도 커집니다.
코스트 모델
MySQL서버가 쿼리를 처리하려면 다양한 작업을 필요
- Disk로부터 데이터 페이지 읽기
- 메모리(InnoDB BF Pool)로부터 데이터 페이지 읽기
- 인덱스 키 비교
- 레코드 평가
- 메모리 임시 테이블 작업
- 디스크 임시 테이블 작업
MySQL 서버는 사용자의 쿼리에 이러한 다양한 작업이 얼마나 필요한지 예측하고
전체 작업 비용을 계산한 결과를 바탕으로 최적의 실행 계획을 찾습니다.
이렇게 쿼리 비용 계산에 필요한 단위 작업들의 비용을 Cost Model이라고 함
- 5.7 이전까지는 Cost Model을 MySQL 서버 소스코드에 상수화(하드웨어 스펙에 따라 코스트 모델이 달라져야 한다.)
- 8.0부터 컬럼의 데이터 분포를 위한 히스토그램과 각 인덱스별 메모리에 적재된 페이지 비율이 관리, 옵티마이저 실행 계획 수립에 사용
Cost Model에서 중요한 것은 각 단위 작업에 설정되는 비용 값이 커지면 어떤 실행 계획이 고비용으로 바뀌고 어떤 실행 계획이 저비용으로 바뀌는지 파악하는 것
📗깊은 조예가 없다면 값을 건들지 말자.
실행 계획 확인
EXPLAIN ...
테이블 형식으로 출력
EXPLAIN + FORMAT=TREE or FORMAT=JSON ...
Tree, Json 형태로 출력
EXPLAIN ANALYZ ...
실행 계회과 단계별 소요 시간 정보를 확인, EXPLAIN과 달리 실제 쿼리를 실행하고 사용된 실행 계획과 소요된 시간을 보여줍니다.
시간이 아주 많이 걸리는 쿼리라면 EXPLAIN을 우선 실행한 후 어느 정도 튜닝한 후 명령을 실행하자
실행 계획 분석
- JSON, TREE 형태로 출력할 수 있으며
- 접근 방법, 최적화 방법, 어떤 인덱스를 사용하는지 등을 이해하는 것이 중요함
- 테이블 기준으로 표의 각
레코드는쿼리에서 사용된 테이블의 개수만큼 출력(서브쿼리로 임시 테이블을 생성한 경우 그 임시 테이블까지 포함) - 실행 순서는 위에서 아래로 표시(UNION이나 상관 서브쿼리와 같은 경우 순서대로 표시 X)
- 출력된 실행 계획에서 위쪽에 출력된 결과일수록 쿼리의 바깥부분이거나 먼저 접근한 테이블
- 아래쪽 결과일수록 쿼리의 안쪽 나중에 접근한 테이블
id column
하나의 SELECT 문장은 다시 1개 이상의 하위 SELECT 문장을 포함할 수 있습니다.
SELECT ...
FROM (SELECT ... FROM tb_test1) tb1, tb_test2 tb2
WHERE tb1.id = tb2.id;
위의 쿼리 문장에 있는 각 SELECT를 다음과 같이 분리해서 생각해 볼수 있음
- SELECT ... FROM tb_test1;
- SELECT ... FROM tb1, tb_test2 WHERE tb1.id = tb2.id;
이제 SELECT 쿼리별로 id column이 부여, 위의 실행 계획에서는 최소 2개의 id값이 표시될 것
하지만 1개의 SELECT 쿼리에 조인된 테이블은 1개의 id값을 사용하는 특징이 있습니다.
(이러한 특징으로 서브 쿼리가 조인을 사용하는 방향으로 최적화되었는지 파악이 가능)
하지만 id 컬럼이 접근 순서를 의미하지는 않음, EXPLAIN FORMAT=TREE를 사용하여 확인하면 정확한 순서가 출력됩니다.
select_type column
각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시하는 컬럼
종류
SIMPLE, PRIMARY, UNION, DEPENDENT UNION, UNION RESULT, SUBQUERY, DEPENDENT SUBQUERY, DERIVED, DEPENDENT DERIVED, UNCACHEABLE SUBQUERY, UNCACHEABLE UNION, MATERIALIZED
SIMPLE : Union, SubQuery가 없는 단순한 SELECT 쿼리(조인은 미포함), 복잡한 쿼리라도 제일 바깥 쿼리에는 일반적으로 SIMPLE
PRIMARY : Union, SubQuery를 포함하는 가장 바깥쪽의 쿼리, SIMPLE과 마찬가지로 단 1개만 존재
UNION : Union으로 결합하는 단위 SELECT 쿼리 가운데 두 번째 이후의 단위에 UNION이라고 출력
DEPENDENT UNION : UNION과 동일하게 결합하는 쿼리에서 출력되나 결합된 쿼리가 외부 쿼리에 의해 영향을 받는 경우에 출력, 자세히는 Union으로 결합된 쿼리가 IN절에 사용되면 내부 쿼리에 IN절 조건이 자동 생성되며 이러한 경우에 출력
UNION RESULT : UNION의 결과를 담아두는 테이블을 의미, 8.0 이전에는 Union, Union All 모두 임시 테이블을 생성했지만 임시 테이블을 생성하지 않도록 개선 (UNION은 여전히 임시 테이블을 생성)
SUBQUERY : select_type에서의 서브쿼리는 FROM절 이외에서 사용되는 서브쿼리를 의미
FROM절에서의 서브쿼리는 DERIVED로 출력, 외에는 모두 SUBQUERY로 출력
Nested Query : Select절에 사용된 경우
Sub Query : Where절에서 사용된 경우
Derived Table : From절에 사용된 경우, inline view라고도 부름
서브쿼리의 반환 값 특성에 따라 구분하기도 함
Scalar Sub Query : 단 1개의 컬럼에서 1개의 레코드만 반환하는 쿼리
Row Sub Query : 컬럼의 개수와 관계없이 하나의 레코드만 반환하는 쿼리
DEPENDENT SUBQUERY : 서브쿼리가 바깥쪽 select 쿼리에 정의된 컬럼을 사용하는 경우,
외부 쿼리가 먼저 수행된 후 내부 쿼리가 실행돼야 하므로 일반 서브쿼리보다 처리 속도가 느릴 때가 많음
DERIVED : 5.5까지는 서브쿼리가 FROM절에 사용된 경우 항상 DERIVED 실행 계획을 사용했으나 5.6 이후부터는 옵티마이저 옵션(optimizer_switch)에 따라join으로 최적화하는 형태가 수행되기도 함
단위 SELECT쿼리의 실행 결과로 메모리나 디스크에 임시 테이블을 생성하는 것
5.6이후 부터는 옵티마이저 옵션에 따라 쿼리의 특성에 맞게 임시 테이블에도 인덱스를 추가해서 만들 수 있게 최적화
