현대 딥러닝은 엄청난 데이터와의 싸움이라고 볼 수 있다.
GTP-3모델은 천억개의 데이터.. 많기도 하다.
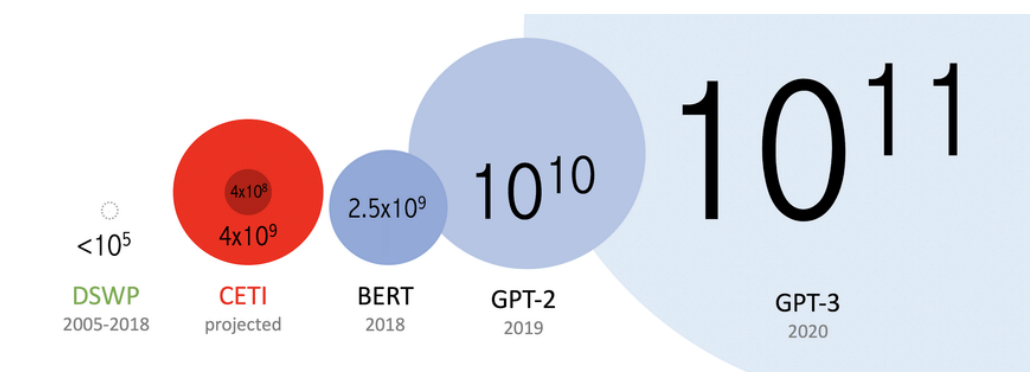
그러니 이 엄청난 데이터를 처리할 수 있는 장비도 딥러닝에 있어서 실력(?)이라고 볼 수 있다. 즉 GPU를 얼마나 확보했는지가 딥러닝에 있어서는 중요한 이슈라고 볼 수 있다.
Multi-GPU 어떻게 다룰것인가?
용어 정리
-
Single : 1개 사용 vs Multi : 2개 이상 사용
-
GPU vs Node : Node(System)는 1대의 컴퓨터를 의미
-
Single Node Single GPU : 1대의 컴퓨터에서 1개의 GPU 사용
-
Single Node Multi GPU : 1대의 컴퓨터에서 여러 개의 GPU 사용
-
Multi Node Multi GPU : 서버실에서 여러 개의 GPU 사용
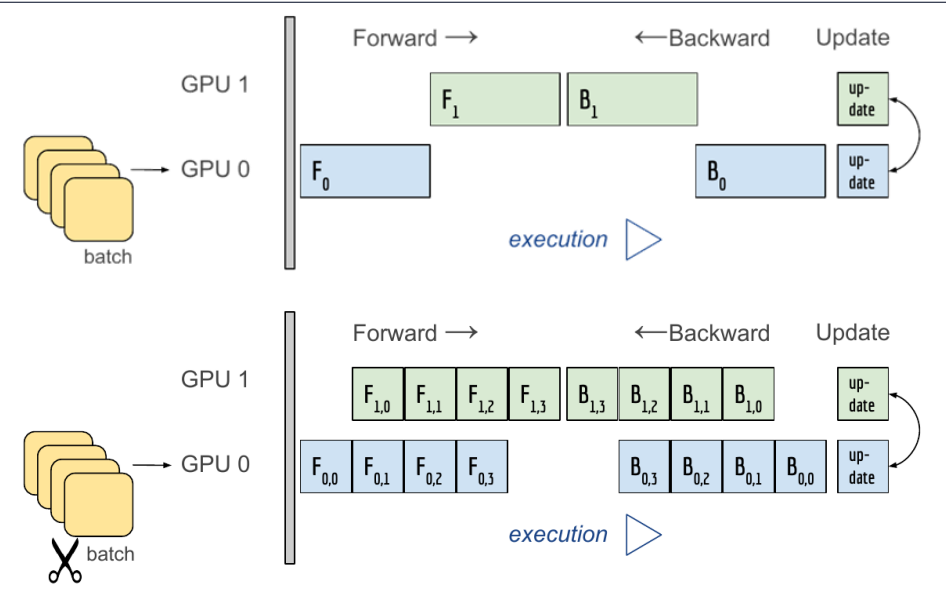
Model parallel
- 다중 GPU에 학습을 분산하는 두 가지 방법
- 모델을 나누기 / 데이터를 나누기 - 모델을 나누는 것은 생각보다 예전부터 썼음 (alexnet)
- 모델의 병목, 파이프라인의 어려움 등으로 인해
- 모델 병렬화는 고난이도 과제
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(Bottleneck,
[3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
# 첫번째 모델을 cuda 0에 할당
self.seq1 = nn.Sequential(
self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2
).to('cuda:0')
# 두번째 모델을 cuda 1에 할당
self.seq2 = nn.Sequential(
self.layer3, self.layer4, self.avgpool,).to('cuda:1')
self.fc.to('cuda:1')
# 두 모델을 연결하기
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))Data parallel
- 데이터를 나눠 GPU에 할당후 결과의 평균을 취하는 방법
- minibatch 수식과 유사한데 한번에 여러 GPU에서 수행
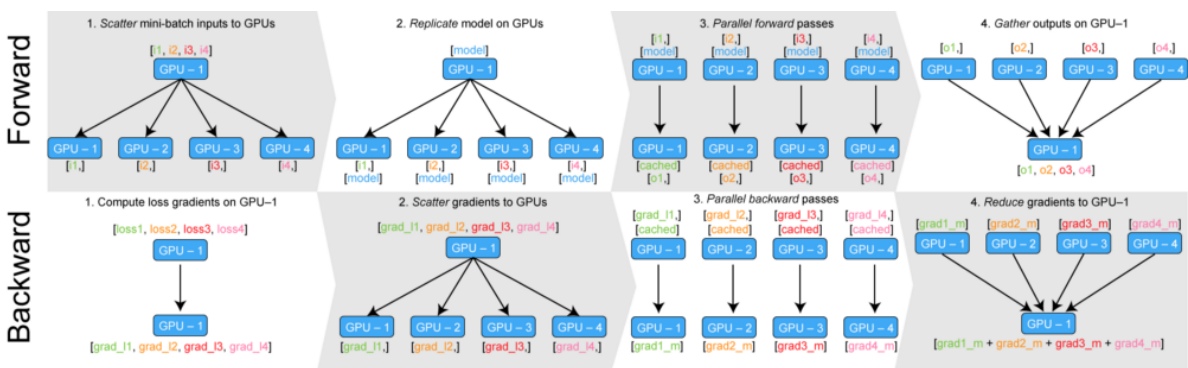
PyTorch에서는 아래 두 가지 방식을 제공
→ DataParallel, DistributedDataParallel
- DataParallel – 단순히 데이터를 분배한후 평균을 취함
→ GPU 사용 불균형 문제 발생, Batch 사이즈 감소 (한 GPU가 병목), GIL - DistributedDataParallel – 각 CPU마다 process 생성하여 개별 GPU에 할당
→ 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 냄

Naver Boostcamp AI Tech 3기🎈⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ㅤㅤ⠀⠀ㅤㅤㅤㅤㅤㅤㅤㅤ2022 데이터분석 청년수련생