PyTorch datasets & dataloaders
파이토치 인공지능의 첫걸음
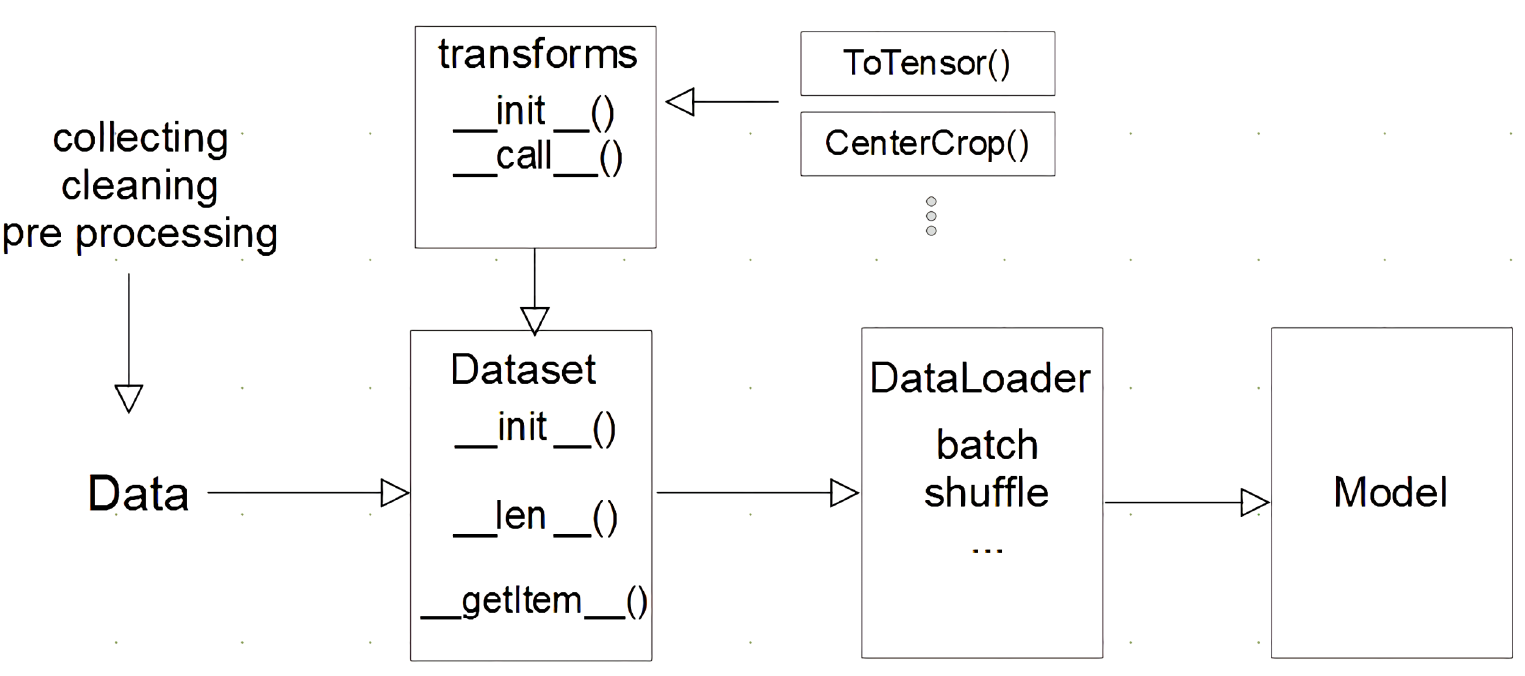
- 데이터셋을 신경망에 넣기 전에 보통 저 순서로 데이터 처리과정이 이루어진다.
- 데이터를 전처리하는 과정과 데이터를 텐서로 변환하는 과정은 보통 다른단계에서 이루어진다.(텐서로 변환하는과정을 transforms단계에서 처리한다.)
Dataset
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels):
self.lables = labels
self.data = text
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text":text, "Class":label}
return sampleinit : 초기 데이터 생성 방법을 지정
len : 데이터 전체 길이를 반환
getitem : index가 주어졌을 때 반환되는 데이터의 형태, dataloader에서 호출(데이터를 불러올때 어떻게 불러올지, + 주로 classification 문제에서는 dict형태로 반환)
Dataset 클래스 생성시 유의점
- 데이터 형태에 따라 각 함수를 다르게 정의함
- 모든 것을 데이터 생성 시점에 처리할 필요는 없음: image의 Tensor 변화는 학습에 필요한 시점에 변환
- 데이터 셋에 대한 표준화된 처리방법 제공 필요
→ 후속 연구자 또는 동료에게는 빛과 같은 존재 - 최근에는 HuggingFace등 표준화된 라이브러리 사용
DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- dataset: 하나의 데이터를 어떻게 가져올지
- dataloader: index를 가지고 여러개를 묶어서(batch size) 모델에 넣어줌
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels) # dataset 생성
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True) # DataLoader Generator
next(iter(MyDataLoader))
# {'Text': ['Glum', 'Sad'], 'Class': ['Negative', 'Negative']}
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
for dataset in MyDataLoader:
print(dataset)
# {'Text': ['Glum', 'Unhapy'], 'Class': ['Negative', 'Negative']}
# {'Text': ['Sad', 'Amazing'], 'Class': ['Negative', 'Positive']}
# {'Text': ['Happy'], 'Class': ['Positive']}DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)option
- 아래의 옵션을 참고해 코드를 짜면 된다.(주로 sampler, batch_size 사용(+ 종종 collate_fn까지))
DataLoader(dataset, # Dataset 인스턴스가 들어감
batch_size=1, # 배치 사이즈를 설정
shuffle=False, # 데이터를 섞어서 사용하겠는지를 설정
sampler=None, # sampler는 index를 컨트롤
batch_sampler=None, # 위와 비슷하므로 생략
num_workers=0, # 데이터를 불러올때 사용하는 서브 프로세스 개수
collate_fn=None, # map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능
pin_memory=False, # Tensor를 CUDA 고정 메모리에 할당
drop_last=False, # 마지막 batch를 사용 여부
timeout=0, # data를 불러오는데 제한시간
worker_init_fn=None # 어떤 worker를 불러올 것인가를 리스트로 전달
)
Naver Boostcamp AI Tech 3기🎈⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ㅤㅤ⠀⠀ㅤㅤㅤㅤㅤㅤㅤㅤ2022 데이터분석 청년수련생