
1. 머신 러닝 모델의 평가
- 데이터: 훈련용 / 검증용 / 테스트용
- 훈련 데이터: 머신 러닝 모델 학습 용도
- 테스트 데이터: 학습한 머신 러닝 모델의 성능을 평가하기 위한 용도
- 검증 데이터: 모델의 성능을 조정하기 위한 용도 (과적합 판단, 하이퍼파라미터 튜닝)
ㄴ 하이퍼파라미터(초매개변수): 모델의 성능에 영향을 주는 사람이 값을 지정하는 변수 (ex. learning rate, 뉴런 수 등)
ㄴ 매개변수: 가중치와 편향. 학습을 하는 동안 값이 계속해서 변하는 수 (사용자가 결정 X, 모델이 학습하는 과정)
2. 분류(Classification)와 회귀(Regression)
(1) 이진 분류 문제(Binary Classification)
: 주어진 입력에 대해서 두 개의 선택지 중 하나의 답을 선택해야 하는 경우
(2) 다중 클래스 분류(Multi-class Classification)
: 주어진 입력에 대해서 세 개 이상의 선택지 중에서 답을 선택해야 하는 경우
(3) 회귀 문제(Regression)
: 연속적인 값의 범위 내에서 예측값이 나오는 경우
3. 지도 학습과 비지도 학습
(1) 지도 학습(Supervised Learning)
: 레이블(Label)이라는 정답과 함께 학습하는 것 (ex. 자연어 처리)
ㄴ 예측값과 실제값의 차이인 오차를 줄이는 방식으로 학습
(2) 비지도 학습(Unsupervised Learning)
: 데이터에 별도의 레이블이 없이 학습하는 것 (ex. LSA, LDA)
(3) 자기지도 학습(Self-Supervised Learning, SSL)
: 레이블이 없는 데이터가 주어지면, 모델이 학습을 위해서 스스로 데이터로부터 레이블을 만들어서 학습 (ex. Word2Vec, BERT)
4. 샘플(Sample)과 특성(Feature)
- 독립 변수 x의 행렬을 X라고 할 때, 독립 변수의 개수가 n개이고 데이터의 개수가 m인 행렬 X
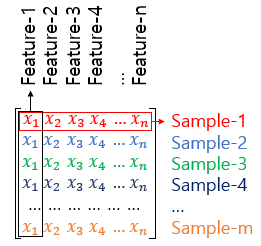
ㄴ 하나의 행: 샘플(Sample)
ㄴ 종속 변수 y를 예측하기 위한 각각의 독립 변수 x: 특성(Feature), 열
5. 혼동 행렬(Confusion Matrix)
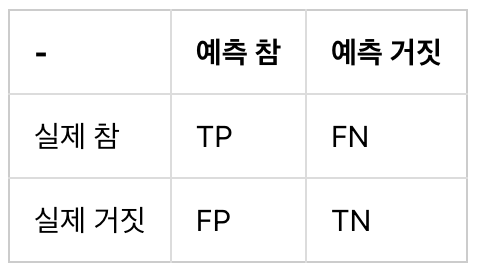
- True Positive(TP): 실제 True인 정답을 True라고 예측 (정답)
- False Positive(FP): 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN): 실제 True인 정답을 False라고 예측 (오답)
- True Negative(TN): 실제 False인 정답을 False라고 예측 (정답)
(1) 정밀도(Precision)
: 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
TP / (TP + FP)(2) 재현율(Recall)
: 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
TP / (TP + FN)(3) 정확도(Accuracy)
: 전체 예측한 데이터 중에서 정답을 맞춘 것에 대한 비율
(TP + TN) / (TP + FN + FP + TN)*F1-Score를 사용하여 편중된 데이터 문제 해결
6. 과적합(Overfitting)과 과소 적합(Underfitting)
-
과적합: 훈련 데이터를 과하게 학습한 경우
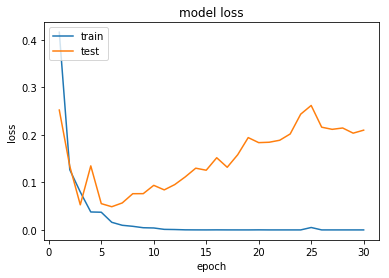
ㄴ y축: 오차(loss)
ㄴ x축: 에포크(epoch) 전체 훈련 데이터에 대한 훈련 횟수 -> 지나치면 과적합 발생
테스트 데이터의 오차가 증가하기 전이나, 정확도가 감소하기 전에 훈련을 멈추는 것이 바람직 -
과소적합: 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태
ㄴ 딥 러닝: 과적합을 막을 수 있는 드롭 아웃(Dropout), 조기 종료(Early Stopping)
ㅤ
Step 1. 주어진 데이터를 훈련 데이터, 검증 데이터, 테스트 데이터로 나눈다. 가령, 6:2:2 비율로 나눌 수 있다.
Step 2. 훈련 데이터로 모델을 학습한다. (에포크 +1)
Step 3. 검증 데이터로 모델을 평가하여 검증 데이터에 대한 정확도와 오차(loss)를 계산한다.
Step 4. 검증 데이터의 오차가 증가하였다면 과적합 징후이므로 학습 종료 후 Step 5로 이동, 아니라면 Step 2.로 재이동한다.
Step 5. 모델의 학습이 종료되었으니 테스트 데이터로 모델을 평가한다.
