1. Constituency and Dependency
언어적 구조적으로 문장을 어떻게 parsing 할지 두가지 관점이 있다. Constituency (= phrase structure grammer = context-free grammars (CFG)) parsing 과 Dependency parsing 이다. Constituency parsing은 문법적으로 접근하여 문장의 구성요소를 파악하여 구조를 분석하는 방법이며, Dependency parsing은 단어 간의 의존 관계를 파악하여 구조를 분석한다.
1.1 Constitnuency Parsing
Phrase structure 는 단어들이 중첩된 구조 (nested constituents) 로 되어있다. 처음에 단어들이 주어지면 단어들을 합쳐서 구문 phrase 을 만든다. 구문은 재귀적으로 더 큰 구문으로 합칠 수 있다. 각 단어가 가지는 문법적 의미를 표현할 수 있다.

** NP: Noun Phrase, PP: Prepositional Phrase
1.2 Dependency Parsing
Dependency structure 는 어떤 단어가 어느 단어에 의존적 관계 (modify / argument of) 가 있는지 보여준다. 각 단어 간의 의존관계를 화살표로 표시한다. 문장이 자유 어순을 가지거나 문장 성분이 생략 가능한 언어에서 선호하는 방식이다.

1.3 Why do we need sentence structure?
언어를 정확하게 이해하기 위해서는 문장의 구조를 이해해야 한다. 인간이 복잡한 아이디어들을 소통할 때는 단어들을 큰 unit 으로 합쳐서 전달하기 때문에 어떤 것에 어느 것에 연결되어있는지를 알아야한다. 그런데 문장에 ambiguity 가 생길 때가 있다.
Prepositional phrase attachment ambiguity
문장에서 한 단어가 어떤 단어를 꾸미는 지에 따라 의미가 달라지기 때문에 애매한 상황들이 생긴다. 예를 들면 다음과 같은 상황이다. 우주에서 고래의 수를 세었다는 것인지, 우주에서 온 고래의 수를 세었다는 것인지... 형용사구, 동사구, 전치사구 등이 어떤 단어를 수식하는지에 따라 의미가 달라지는 모호성이다.

Coordination scope ambiguity
구 들이 어떤 단어를 수식하는지 범위에 따라 달라지는 모호성이다. Fred Gregory를 수식하는 범위에 따라서 의미가 변한다.

2. Dependency grammer and Dependency structure
dependency 는 보통 tree로 표현할 수 있다. tree의 parent node에 해당하는, 화살표가 나가는 단어를 head (governor, superior, regent)라고 하고, child node에 해당하는 화살표가 오는 단어를 dependent (modifier, inferior, subordinate) 라고 한다.
The rise of annotated data
treebank 를 만드는 것이 느려보이지만 grammer를 building 하는 것보다 유용하다.
- Resuability of the labor
- Broad coverage, not just a few intuitions
- Frequencies and distributional information
- A way to evaluate systems
Dependency Conditioning Preferences
Dependency parsing의 전형적인 특징은 다음과 같다.
- Bilexical affinities: 두 단어 사이의 실제 의미가 드러나는 관계
- Dependency distance: dependency 의 거리는 주로 가까운 위치에서 dependent 관계를 형성한다.
- Intervening material: 동사나 구두점을 사이에 두고 dependency 관계는 잘 형성되지 않는다.
- Valency of heads: head 가 문장 내에서 결합하는 문장 구성 성분의 수를 고려한다.
Dependency Parsing
- 문장은 각 단어에 대해 어떤 단어에 의존하고 있는지 선택함으로서 parse 된다. 대부분의 경우 ROOT에 의존하는 단어는 한개이고, cycle 을 형성하지 않는다 (A->B, B-> A). 그렇기 때문에 dependency는 tree를 만들게 된다. 또한, 화살표들은 서로 cross (non-projective) 할 수 없다.
Projectivity
Projectivity는 단어들을 linear order로 놓았을 때, dependency arc 들이 cross 하는 상황이 없는 것이다. CFG tree는 Projective 해야한다.
하지만 dependency theory는 보통 non-projective structure 를 허용한다.
Methods of Dependency Parsing
-
Dynamic programming
-
Graph algorithms
- create a Minimum Spanning Tree (MST) for a sentence
- 가능한 모든 의존관계를 고려한 뒤 가장 확률이 높은 구문분석 tree 선택
-
Constraint Satisfaction
- 문법적 조건을 설정하고 조건을 만족하지 못한 경우는 제거하여 조건을 만족하는 단어만 Parsing
-
Transition-based parsing
- = Deterministic dependency parsing
- 두 단어의 의존여부를 순서대로 결정하여 점진적으로 구문분석 tree 구성
3. Transition-based parsing
Greedy transition-based parsing
parser는 bottom-up 방식으로 동작한다. 문장의 모든 단어는 stack, buffer에 있다. shift-reduce parser 방식으로, shift, Left-Arc, Right-Arc 과정이 반복된다.
- shift : buffer의 top word 를 (가장 왼쪽 단어) stack 의 top position (가장 오른쪽)으로 이동
- left arc : stack 의 top word 를 화살표로 연결 (<-), 그리고 dependent 제거
- right arc : stack 의 top word 를 화살표로 연결 (->) 그리고 dependent 제거

Arc-standard transition-based parser
"I ate fish" 분석
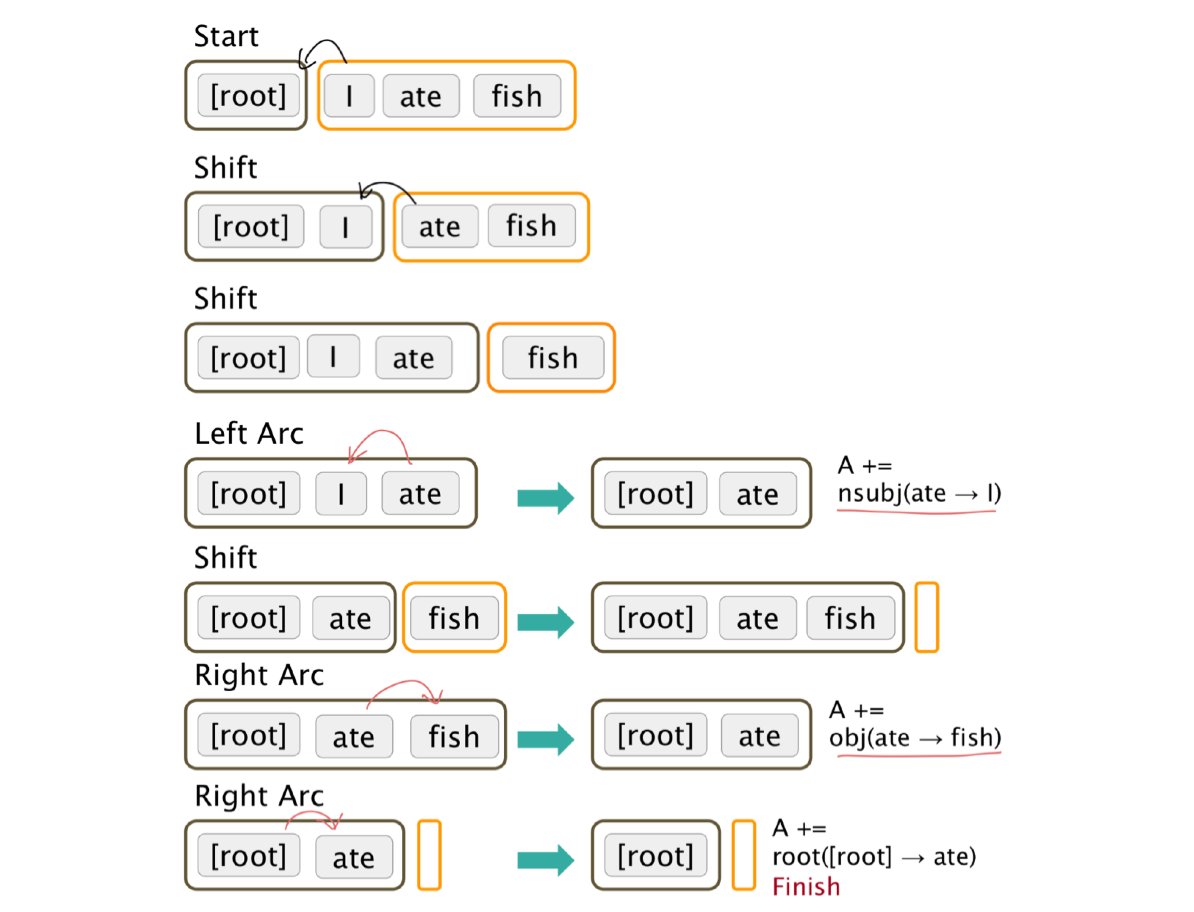
MaltParser
그럼 다음 action을 어떻게 선택할까? classification 을 위해 사용한 feature 는 다음과 같다: top of stack word, 그 단어의 POS, top of buffer word, 그 단어의 POS 등등...
그리고 search 를 사용하지 않았다. 즉 대안(alternatives) 없이 current word 에 대해서 3 가지 액션 중 하나만 classify 하고 바로 그 뒤로 넘어갔다. Lenear 하게 쭉쭉 뻗어나가며 classify 하고 지나간 선택에 대해서는 다시 돌아가지 않는다.
이 방법은 좋은 성능으로 아주 빠르게 linear time 안에 가능하다.
Evaluation of Dependecy Parsing
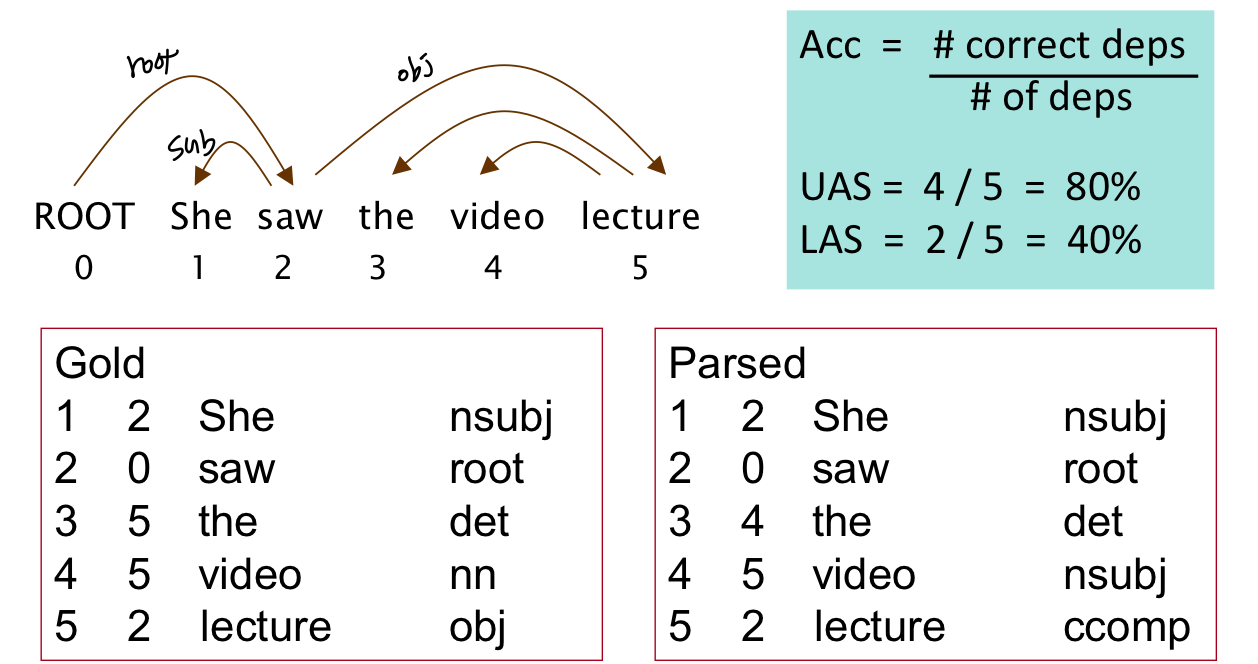
UAS: Unlabeled attachment score
LAS: Labeled attachment score
Handling non-projectivity
앞서 설명한 arc-stanard algorithm은 projective dependency tree 만 형성가능하다.

4. Neural dependency parser
- 단어를 back of words 방식으로 나타내면 엄청나게 dimension 이 커져 버리고, 거기에다가 엄청나게 sparse 한 feature 가 된다. 전통적인 dependency parsing의 단점을 보완하기 위해 neural dependency parsing을 제안한다.
Distributed Representations
단어를 d-dimensional dense vector (word embedding) 로 표현한다. 따라서 비슷한 단어들은 벡터가 가까울 것이다. 반면에 part-of-speech tags (POS) 와 dependency label 또한 d-dimensional vector 로 표현된다.
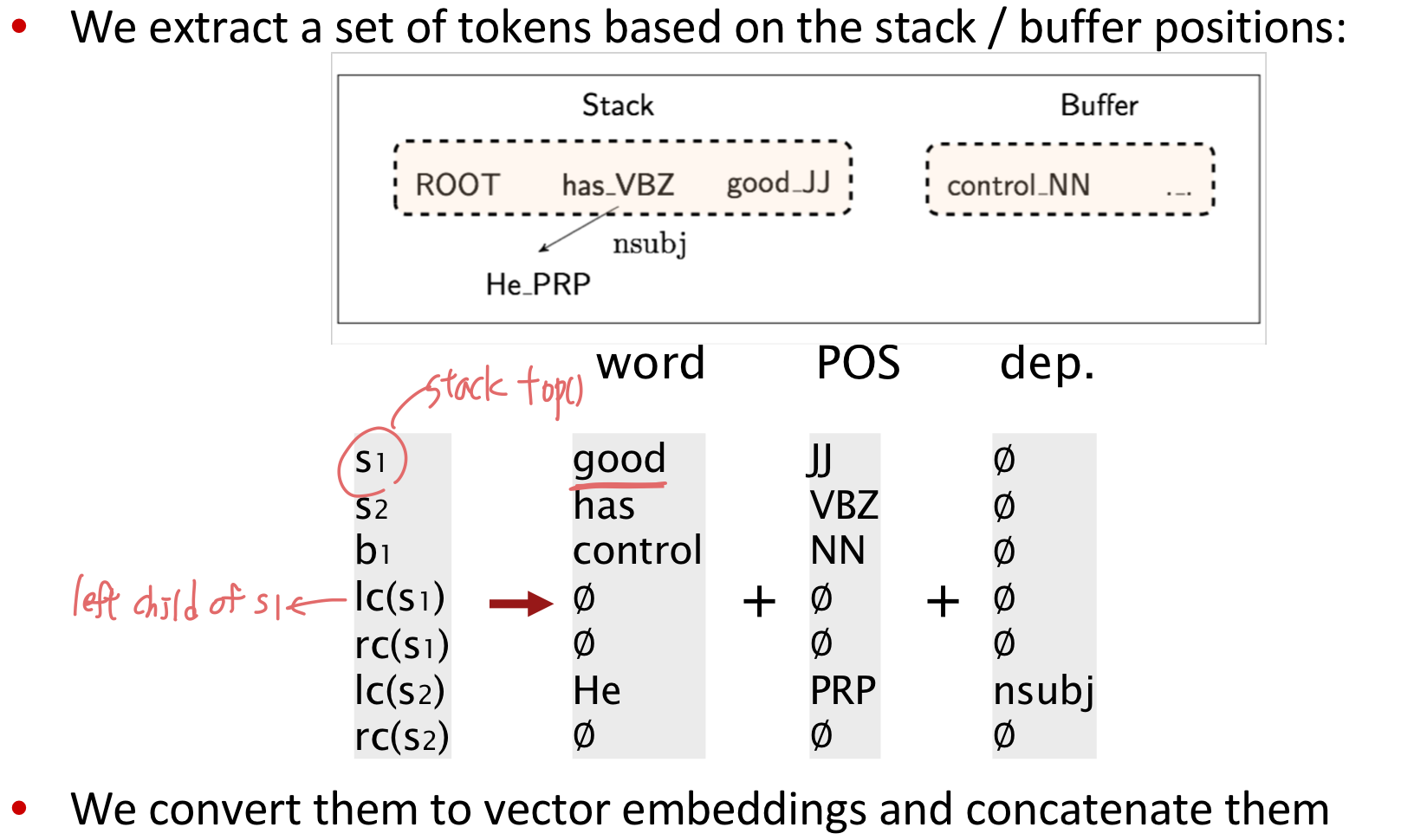
Model Architecture

Graph-based dependency parsers
- 각 edge 에 대해 모든 가능한 dependency 에 대한 score를 계산한다.
- 각 edge에서 가장 점수가 높은 것을 head 로 더한다.
- 같은 과정을 모든 다른 단어에 대해서 반복한다.
A neural graph-based dependency parser
- 성능이 높다.
- 하지만 simple neural transition-based parser 보다 느리다. 문장 길이가 n 일 때 가능한 dependency가 n^2 있다.

[Reference]
