학습 주제
맥스님의 ChatGPT 강의
학습 내용
ChatGPT를 학습에 어떻게 이용할 수 있을지?
-
우려: 개발자의 일을 모두 없애는 것 아니냐.
-
ChatGPT를 매일 써봤으면 좋겠음.
-
ChatGPT는 초거대 언어모델.
-
ChatGPT를 학습에 이용할 때 tip
-
slack에 나의 경험을 올리기, 내지는 툴 소개
LLM(Large Language Model), GPT, ChatGPT

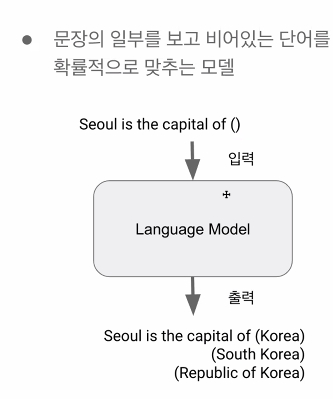
확률적으로 다음 단어를 예측함.
답은 여러가지 일 수 있음.
GPT는 이러한 Language Model, 비지도 학습 모델임. 웹상의 문서를 수집하고 파싱하면서, 이런 단어가 나오겠구나 훈련함
text를 받고 pattern을 보고, 다음 단어를 예측
- GPT는 출력을 조절할 수 있는데 이를 temperture 이라함. 100에 가까울 수록 자유도가 높음. 0에 가까울 수록 가능성이 높은 것 순으로 return 하게 되어 있음.
예전엔 이런 language model이 거대하지 않았으나, google이 논문을 발표하고 나서 가속화 됨. GPT4 의 경우 매우 거대함.
Language Model
1. 모델 훈련
2. 모델 사용 (추론/예측)

주식, 부동산 가격 처럼 특정 가격을 예측. regression(회귀 본석)
불연속 적인 카테고리로 분류: Classification
머신 러닝 만드는 노력이 100이라면 , 어떤 모델을 만들껀지 세우고, 훈련데이터 수집하고 정제에 많이 걸림.
Caggle 에는 훈련데이터가 많이 있음. 경진 대회 많이 함.
- 어려운 건 문제 정의, 훈련 데이터 수집, 정제 (수집, 정제는 단조롭고 시간이 많이 걸리는 일)
- Garbage in Garbage out
- 좋은 텍스트를 주게되면, 모델이 잘 학습을 함.
- 지도학습에 비해선 훈련데이터를 수집하기 쉬움.
context window가 4, (OpenAI) (transitioned) (from) (non-profit) (to) (for-profit) 을 훈련하려고 하면,
-
4라면 앞으 토큰 4개를 읽고 다음 예측
OpenAi transitioned from, non-profit
transitioned, from, non-profit, to
from, non-profit, to, for-profit
window가 하나씩 이동하면서 문장
window가 크면 클수록 메모리가 늘어남. 기억력이 좋아짐. -
context를 얼마나 알고 있는지
- 이를 코드에 적용할 수 있음. token의 시퀸스이기 때문에
GPT엔 두개의 서브 모델, word completion, code completion 모델이 있음.

GPT는 문자 자체를 이해하지 못함. 이를 행렬화 된 숫자로 이해함.

단어 모두에 일련번호를 붙일 수는 없음. 너무 공간이 큼. 작은 차원으로 transform 하는 것이
word embedding이라고 함.
- 비슷한 단어는 비슷한 공간에 위치함.

- 데이터 엔지니어링도 하둡 (구글에서 발표한 두 논문, GFS, Map reduce)에서 시작.
- 구글도 야후처럼 안전한 쪽으로 가려고 하는 보신주의로 바뀌어 가는 중.
- youtube, 광고, document정도고 수익이 그 정도에.
언어를 이해한다기 보다, 통계를 기반으로 만들어짐

code completion을 이용해 code를 짤 때 무조건 믿지 말고, test case를 만들어서 확인.
생산성은 좋은데 실수를 좀 하는 주니어 개발자와 일하는 느낌.
GPT 3.5 도 5개 모델이 있음. 개별적으로 쓰려면 유료임
Fine Tuning
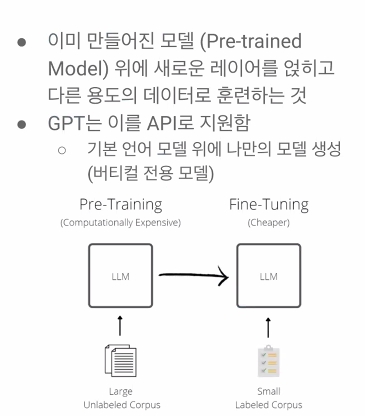
이미 만들어진 모델 위에 -> 내 도메인을 훈련시켜서 -> 내 분야에 조금 더 전문화된 모델로 만들고 싶다.
경량 LLM 모델들
- 웹 상에 널려있는 지식들을 GPT와 대화를 통해 이해하는게 가능
Prompts 엔지니어링 탄생 -> 질의를 어떻게 하느냐에 따라 결과가 달라짐
Chat-GPT가 거짓말을 잘 하기 때문에, 골라서 취사선택을 해야함.
단발성 대화로 끝내지 말고, 계속해서 이어서 바꿔달라, 수정해달라 하면 원하는 것을 쉽게 얻을 수 있음.
- ChatGPT 플러그인을 사용하면 -> 리서치로 끝나는 것이 아니라 모든걸 할 수 있음
-> 개발자라면 나만의 플러그인을 만들 수 있음.
그렇 어떻게 사용할까

- 질문은 구체적으로

- 정말 구체적으로 많이 질문하는 것이 좋음. 항상 정답을 알려주지는 않음.
-Github의 Copilot

- 생각보다 잘 만들어줌.
- 이전 같으면 구글 검색이나, 동료에게 물어봤을 것을 해결해줌.
ChatGPT처럼 엄청 뜨는 기술을 바라보는 관점

- 쫓아다닌 것은 시간 낭비.
- 이 툴을 이용해 어떻게 활용해볼까를 고민
- 뒤에서 쫓아가더라도 아무런 문제 없음.
Q & A
