학습주제
Hashcode 질문 가져오기
학습내용
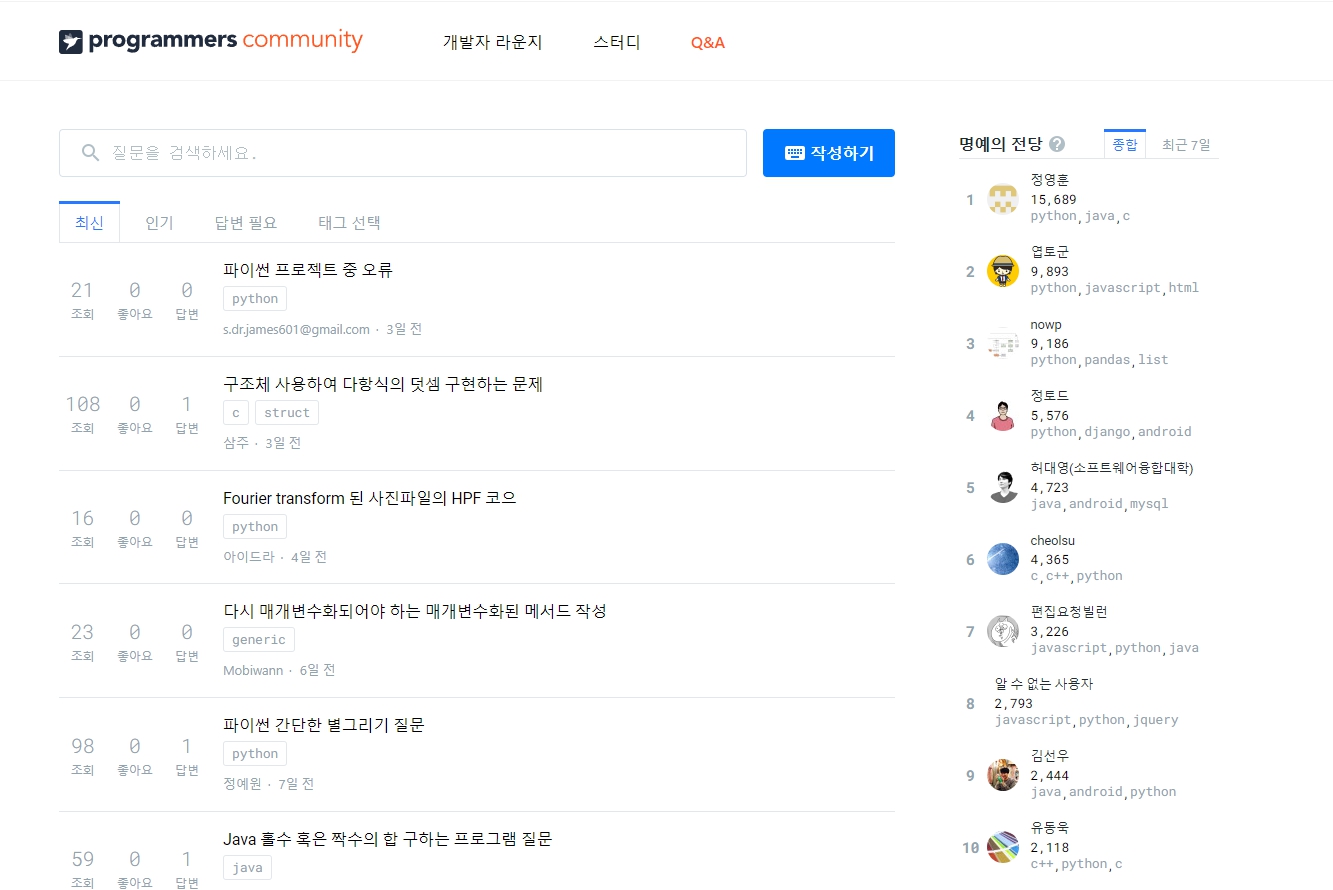
가져올 웹사이트에 접속하면 질문목록이 있다.
우리는 여기서 질문 제목 리스트를 가져올 계획.
- 제목이 어디에 있는지 파악해야함.
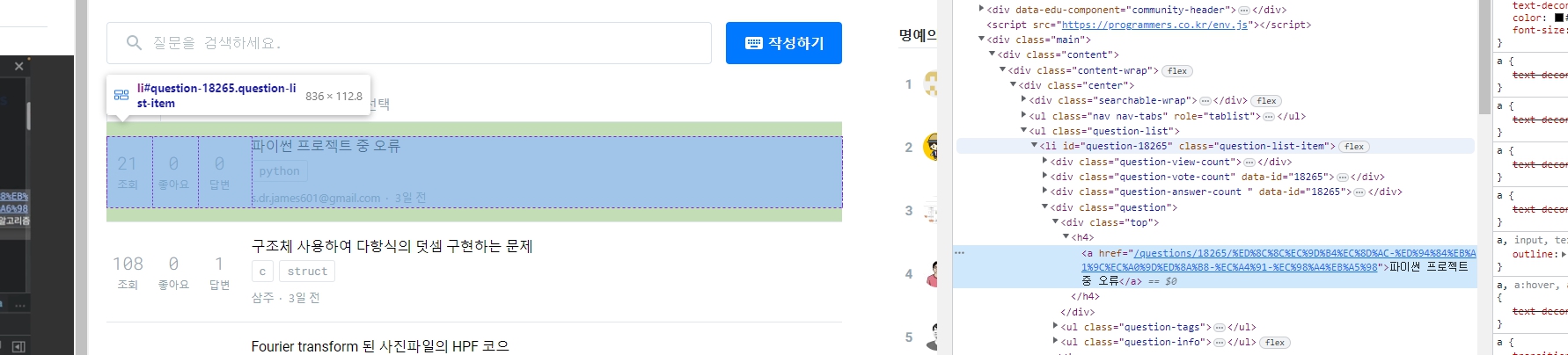
li 태그 중 class=question-list-item 인 애들을 가져오면 됨.
그 전에
과도한 요청을 보내면 안됨.
상업적 이용에 유의해야함.
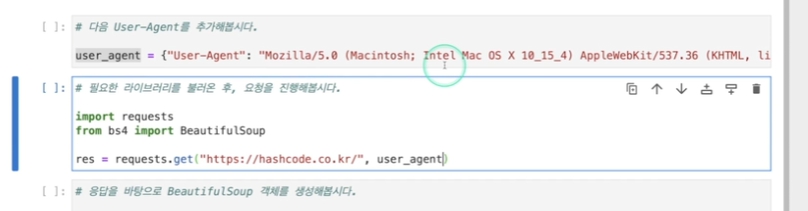
두번째 인자는 헤더임. 헤더는 딕셔너리 형태로 정해져 있음. user_agent를 넘겨주면, 그 값을 받아 요청해줌.

soup에 담아준다.
먼저 li 중 class=qusetion-list-item
원하는 값은 li 중 h4 내에 있는데, h4가 상당히 많음.
사실 h4를 보면 다 질문이 있는 것을 볼 수있음.
조건에 맞는 class를 하나만 요청하는 것이 아닌, 연쇄적으로도 요청할 수 있음.
단 뒤에 붙는 .find는 하위 태그 내 class명이어야 함.
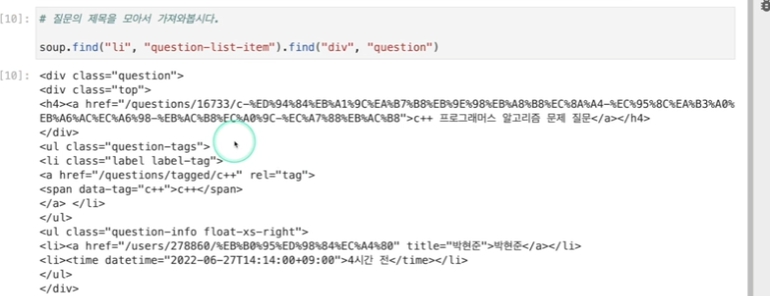
조금 더 안으로 들어 온 것을 확인.
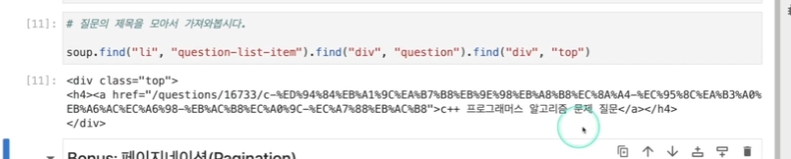
한번 더 적용

객체 내 속성 h4를 호출

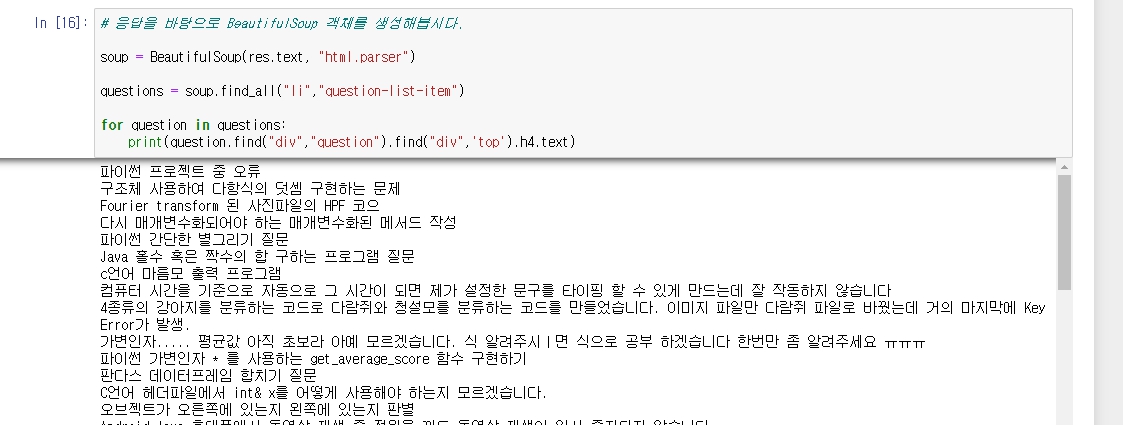
마지막으로 text 부분만 뽑아내면
원하는 정보가 나옴.
그러나 우리가 원하는 정보는 각각의 question-list-item 내에 접근해야 하므로, for문을 돌려 class가 question-list-item인 각각의 태그 객체를 리턴받아 각각 접근해야한다.
우리는 한 페이지의 목록외에
2, 3, 4 연속해서 접근하고 싶음.
저걸 페이지네이션이라고 함.
한 화면에 나올 크기를 고려하여 데이터베이스 형식으로 나눔.
스크래핑 하는 입장에서 저 페이지네이션에 각각 접근해야되기 때문.
1페이지에 대한 스크래핑, 2페이지에 대한 스크래핑... n페이지에 대한 스크래핑.. 반복적으로 해내야함.
이걸 한꺼번에 요청하면 서버에 부하가 걸림. 따라서 일정한 요청시간 간격을 두고 요청해야함.
대부분의 페이지네이션은 주소 뒤 ?와 함께 요청한 페이지가 적혀있음. 이를 쿼리스트링이라고 함.
를 입력하면 4페이지의 질문목록이 나온다.
앞에있는
까지는 같고 뒤의 숫자만 다른 것을 알 수 있다.
실습

각 다른 링크에 대한 요청을 하려면 나 또한 n개의 요청을 해야함.
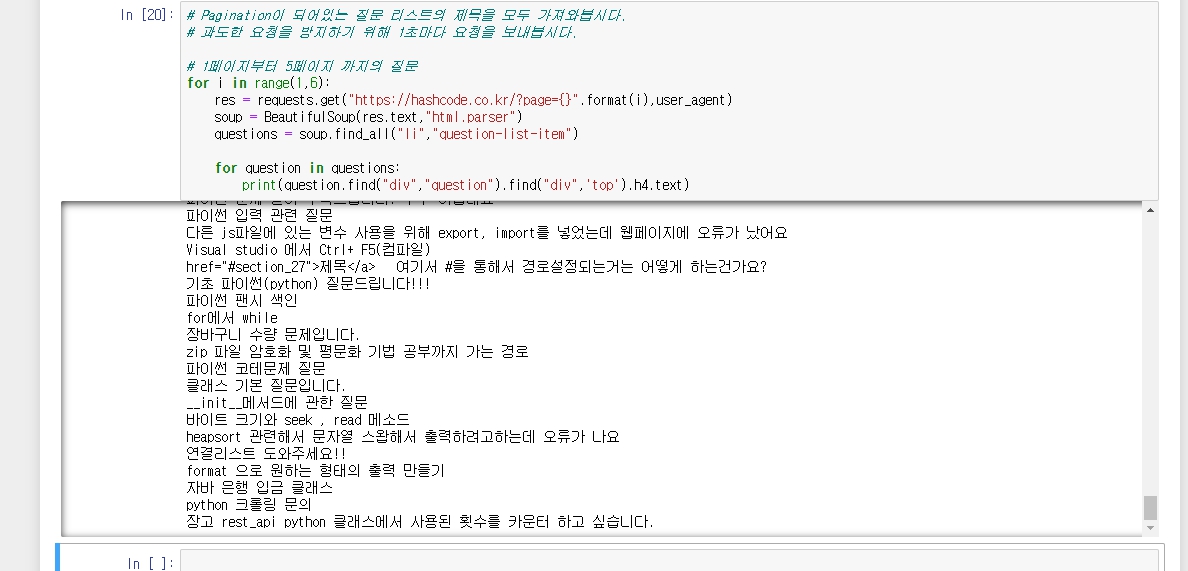
아까의 코드를 활용하여 각 페이지를 순회하면서, 페이지에 있는 class=question-list-item을 갖는 li 목록을 얻고, 각각의 li 내에 있는 제목을 얻는다.
결과는 매순간 요청을 하게되어 바로 나오게 되지만, 이는 서버에 부하를 준다. 정상적인 이용이 아니기 때문.
시간의 유예를 주어야함. 각 요청과 요청 사이에 임의의 term을 두어야 함.
time.sleep(0.5)를 주어 각 페이지를 넘어갈 때 유예를 준다.
현대 웹은
javascript을 활용하여 동적으로 생성되기에 만만치 않음.
