학습 주제
우선순위 큐
학습 내용
설명
지금까지 (제 14 강과 제 15 강에서) 배운 큐들은, 먼저 들어간 원소가 먼저 나온다는 원칙, 즉 선입선출 (FIFO; first-in first-out) 원칙이 그대로 적용된 것들이었습니다. 그런데, 경우에 따라서는 이 원칙을 지키기보다는 원소들 사이의 우선순위 (priority) 관계에 따른 순서로 원소들이 꺼내어지는 응용이 필요하기도 합니다. 큐에 원소를 추가하는 연산은 다른 점이 없되, 큐에서 원소를 꺼내는 원칙은 원소들 사이의 우선순위에 따르는 자료구조로서 우선순위 큐 (priority queue) 라는 것을 소개합니다. 대표적인 응용 예를 들자면, 운영체제에서 CPU 스케줄러를 구현할 때, 현재 실행할 수 있는 작업들 중 가장 우선순위가 높은 것을 골라 실행하는 알고리즘같은 것을 들 수 있겠네요.
우선순위 큐를 구현하는 데에는 두 가지의 서로 다른 접근 방법을 생각할 수 있습니다. 단순한 얘기이지만, 아래와 같은 것들이겠네요.
큐에 원소를 넣을 때 (enqueue 할 때) 우선순위 순서대로 정렬해 두는 방법
큐에서 원소를 꺼낼 때 (dequeue 할 때) 우선순위가 가장 높은 것을 선택하는 방법
어느 쪽이 더 좋을 것이라고 생각하나요? 또한, 우선순위 큐를 구현하는 재료로서, 이미 배운 것들 중 선형 배열을 선택할 수도 있고 연결 리스트를 선택할 수도 있습니다. 어느 것을 선택하는 것이 더 유리할까요?
이 강의에서는 양방향 연결 리스트를 선택하여 우선순위 큐를 구현하기로 하고, 원소를 추가할 때 우선순위에 따른 알맞은 자리를 찾아서 정렬된 형태로 유지해 두고 꺼낼 때 한 쪽 끝에서 꺼낼 수 있도록 코드를 만들어봅니다. 이렇게 하면, 원소를 넣는 (enqueue) 연산의 복잡도는 O(n) 으로서 큐의 길이에 비례하고, 원소를 꺼내는 (dequeue) 연산의 복잡도는 O(1) 로서 상수 시간, 즉 데이터 원소의 개수에 무관한 시간이 걸립니다. 실제 코드를 보면서 (빈칸 채우기 연습문제입니다) 정말 그런지 확인해보시기 바랍니다.
그렇다면, 위에서 말한 다른 방법들 (선형 배열을 이용하거나, 아니면 큐에 원소를 넣을 때는 그냥 한쪽에서 순서대로 집어넣고 꺼낼 때 가장 높은 우선순위의 것을 고르는 방식을 적용하거나) 을 선택하면 각각 enqueue 와 dequeue 연산에서 얼마나 유리하거나 얼마나 불리할까요? 큰 차이는 아닐 수 있지만, (1) 알고리즘의 복잡도와 (2) 구현의 편의성 두 가지 측면에서 비교해보시기 바랍니다.
마지막으로, 우선순위 큐는 나중에 (제 23 강에서) 배울 예정이지만, 조금 다른 자료 구조를 이용하여 더욱 효율적으로 구현할 수 있습니다. 트리 (tree) 라고 불리는 자료 구조를 도입하여 가능해지는 일인데요, 다음 강의부터는 트리에 대해서 배워보도록 하겠습니다.
- 선입선출 원칙 대신, 데이터에 우선순위를 매기게 된다
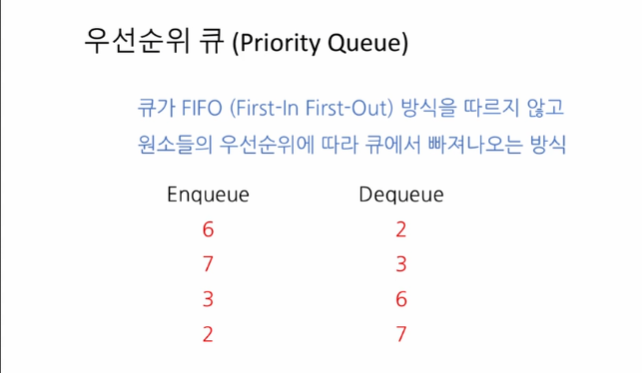
우선순위 큐의 활용은
운영체제의 CPU 스케줄러
구현하기 위해선?
두가지 방식이 있음

1번 방식이 조금 더 유리함.
무작위로로 enqueue를 하게 되면 dequeue시 배열의 길이에 비례하게 됨. (모든 데이터를 다 뒤져봐야함)
그러나 enqueue시 정렬를 하게 되면, 모든 데이터를 뒤질 필요는 없음. 매번 넣을 때마다 정렬하기 때문. (정렬된 데이터에 입력하게 됨)

시간적으론 연결 리스트가 유리함. enqueue 시에 중간에 데이터를 삽입하는 일이 비일 비재함.
선형 배열이면 뒤로 하나씩 다 미뤄야 하기 때문에 오래걸림.
연결 리스트는 중간에 링크를 끊고 좌 우로 연결하기 때문에 편함
그러나 공간 소요면에선 선형이 우수함.
보통은 시간적으로 유리한 알고리즘을 선택함


기존 양방향 연결 리스트를 사용
enqueue 시 우선순위에 적합한 위치에 도달할 때까지 계속 찾아나감.
curr = 처음 시작을 어디서할지?
while 조건 1. 끝을 만나지 않는 동안. 조건 2. 우선순위를 비교하는 조건
작은 수가 우선순위가 높다고 가정
insert after나 before 사용해서 (curr, newNode)
[주의]양방향 연결 리스트의 getAt() 메서드를 이용하지 않음.
정수변수를 사용해서 노드를 얻어내지 않음. 할 때마다 숫자를 세지 않게 하기 위해.
curr을 사용해서 노드를 짚어가며 이동
dequeue 시에는 가장 앞의 node를 꺼내면 됨.
마찬가지로 빈칸 채우기 문제.
다른점이라면 i 정수 변수를 이용하여 짚어가던 것과는 달리, 노드를 이동해가면서 확인함.
나의 풀이
def enqueue(self, x):
newNode = Node(x)
curr = self.queue.head
while curr.next.next and curr.next.data >= x:
curr = curr.next
self.queue.insertAfter(curr, newNode)
def dequeue(self):
return self.queue.popAt(self.queue.getLength())
def peek(self):
return self.queue.getAt(self.queue.getLength()).data어려웠던 점
insertBefore 메서드는 구현이 안되어 있었고, insertAfter로 구현해야 되는 상황.
dequeue의 pos 위치가 self.queue.getLength()로 우선순위가 높을 수록 뒤로 밀려나는 모양이었다. 이걸 안보고 풀으니 자꾸 헷갈렸다. curr 위치의 데이터를 참고해야하는지, curr.next 위치의 데이터를 참고해야하는지 헷갈렸다.
