학습 주제
윤리적으로 웹 스크래핑 크롤링 진행하기
학습 내용

두 단어가 혼용되고 있다.
웹 스크래핑?
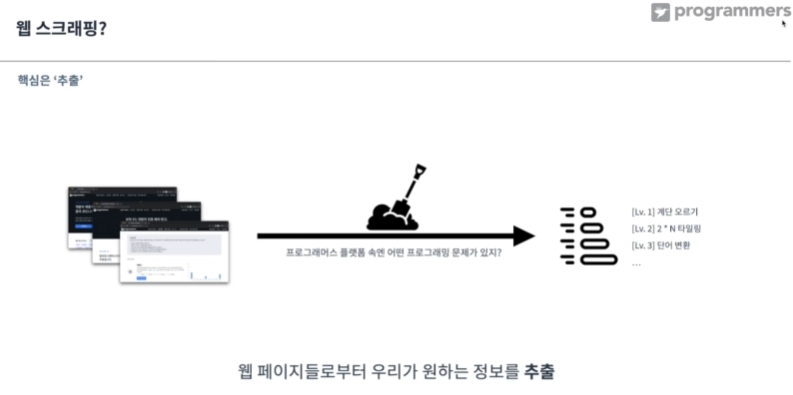
추출하면 일종의 문제 리스트(원하는 정보)들을 얻어 낼 수 있음.
웹 크롤링?
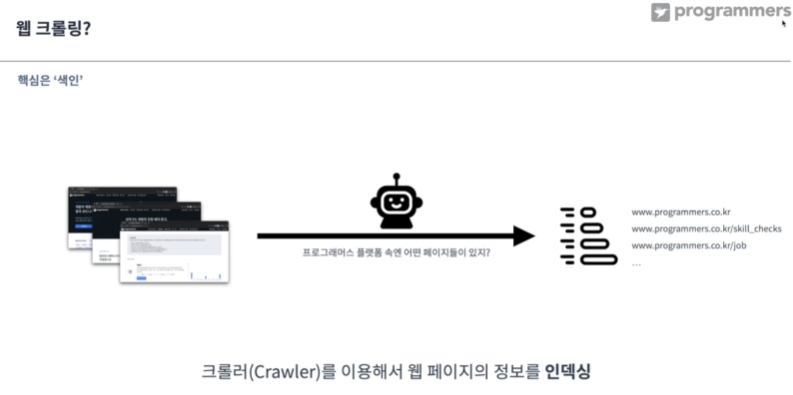
인덱싱에 중점을 둠. 크롤러=로봇이 주체.
검색엔진을 쓰는 사람들은 웹페이지 안에 뭐가 있는지 모름. -> 봇이 링크를 타고다니면서 훑음. -> 반복하면서 정보를 수집.

네이버, 구글은 자체적으로 크롤러가 웹 페이지를 돌아다님. 이번 강의는 웹 스크래핑에 가까움.
올바르게 HTTP 요청하기

-
상업적으로 크게 타격을 줄 경우 권리 침해가 될 수 있음.
-
디도스. 서버에 무차별적인 요청을 보내, 서버를 마비시키는 행위. 서버는 일정 시간마다 받을 수 있는 요청 수 가 정해져 있음.
-
웹 브라우징은 사람이 아닌, 로봇이 진행할 수 있다.

이를 막기 위해 로봇배제 프로토콜이 생김

모든 user-agaent에 대해 접근을 거부, disallow: 모든 정보에 대해서 거부


특정 에이전트를 불허용

웹 스크래핑을 할 때 원칙은 다음과 같습니다.
요청하고자 하는 서버에 과도한 부하를 주지 않는다.
가져온 정보를 사용할 때 저작권과 데이터베이스권에 위배되지 않는지 주의한다.
이 원칙들을 잘 지킨다면 건전한 사용자 에이전트가 될 수 있을 것입니다.
실제로 robots.txt 얻기
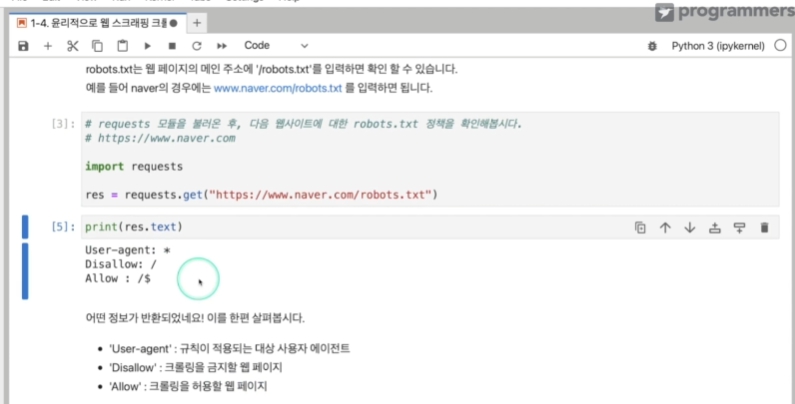
User-agent *
Disallow: /
Allow: /$
모든 user-agent에 대해, 모든 요청을 거부. 순수하게 /로 끝나는 웹페이지만 허용

반갑습니다 햄스터 좋아합니다