개요
IT-Hermes 프로젝트를 진행하는 과정에서 프론트 페이지에 검색기능을 도입하는 것을 세우고 작업을 진행했습니다. UI에서는 이런 느낌으로 주고 검색을 통해 데이터를 가져오는 API를 만드는 것이 목표였습니다.
진행과정
검색을 구현하는 것은 생각보다 어렵지 않은 편이었습니다.
다만... 많은 데이터를 가진 크롤링 테이블의 데이터를 검색해오는 과정이다보니...
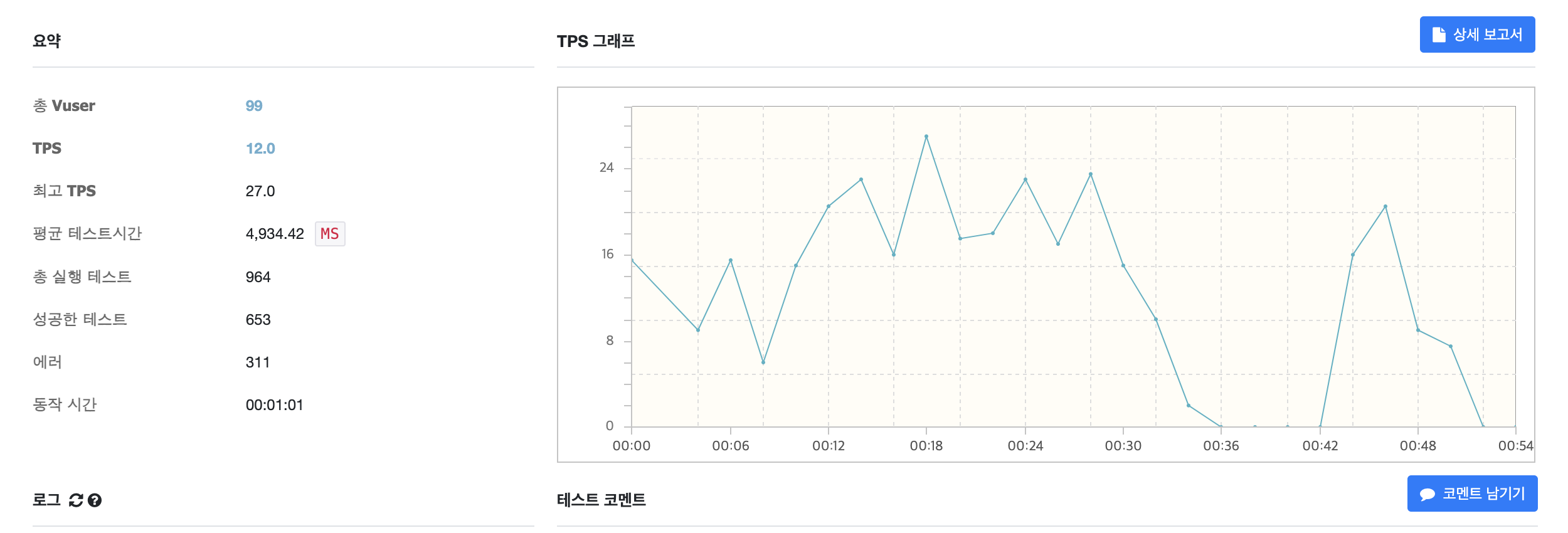
동시 접속이 100명이 넘을 시, 엄청나게 느린 처리속도와 함께 성공률 역시 66%를 보였습니다.
즉 많은 트래픽이 있을 시, 성능상 이슈를 발생시킨다는 점이 문제였습니다.
여러 해결방법?
처음에는 정말 간단하게 생각한점이 로컬캐시(EH Cache)나 글로벌캐시(Redis)를 통해 해결하면 되지 않을까? 라는 생각을 했었습니다. 하지만.. 많은 데이터를 가져올 때, 많은 사람들은 검색어가 다를 확률이 아주 높은 편이고, 캐시 데이터가 너무 많이 쌓여 공간이슈로 인해 서비스 운영에 사이드이펙트를 발생 시킬 가능성 역시 배재할 수 없었습니다.
Indexing?
가장 처음 시도한 방법은 인덱스를 통해 검색을 처리하는 것이었습니다. 색인을 통해 처리하면, 검색 트랜잭션 처리속도를 개선하는데 확실히 효과적이라 봤습니다. 하지만, 엄청난 단점이 2가지가 있어 포기했습니다.
- Like 연산 시, %위치에 따라 인덱스가 적용되지 않고 Full-scan이 될 확률이 높았습니다. 즉 검색을 할 경우, '%검색어%' 이 상황에서 full-scan을 한다는 점에서 어려움을 느꼈습니다.
- index를 쓸 때, 가장 중요한 것은 변경이 적은 경우 쓰는게 적합한데, 크롤링 데이터의 경우 15분에 한 번씩 최신 데이터를 넣어야하는 트랜잭션이 있습니다. 변경이 된다면, 인덱스의 B+트리에서도 데이터를 다시 정렬을 해야되기 때문에 스캐줄링에서 트랜잭션 처리속도(안그래도 느린데..)에 이슈를 발생시킬 수도 있겠다고 판단했습니다.
full-text-search?
MySQL 5.7부터 제공하는 기능입니다. 말 그래도 전문검색 시 쓰는 겁니다. 어떤 장점이 있을까요? 일반 인덱스는 각각의 칼럼에 데이터를 바탕으로 인덱스를 걸어주는 반면, Full Text 인덱스는 전문검색을 할 칼럼의 데이터 안에 있는 단어에 인덱싱 해주는 차이가 있습니다. 그래서 인덱스가 많아지게 될 확률이 높습니다.
다만 처리속도적인 측면에서는 인덱스를 단어 단위로 나누기 때문에 이점이 있습니다.
full-text-search를 어떻게 써야..?
하지만, FULLTEXT 인덱스 역시, 중요한게 있습니다. 우리가 검색을 할 때, 는, 은, 이,가, a, by, an 등등 검색을 할 조건에 단어를 안걸고 싶은 경우도 있을 겁니다. 이 때는 STOP WORDS를 사용하여 검색 조건에 넣고 싶지 않은 단어를 넣으면 됩니다.
또한 검색 방법은 대표적으로 2가지가 존재합니다. 자연어처리와 불리안처리가 있는데, 자연어처리는 완전 동일한 단어 검색이 목적일 때, Boolean 처리는 검색 단어를 포함한 경우 처리를 목표로 할 때 쓰면 좋습니다. 즉 예시를 보면 다음과 같습니다.
- (자연어처리) 안녕 이라고 치면, 무조건 '안녕'이라고 단어가 포함이 되있어야되!
- (불리안처리) 안녕 이라고 치면, '안녕하세요', '안녕하', 안녕이..' 이렇게 포함된 행도 검색하고 싶어!
물론 불리안처리가 처리속도적으로는 느린게 당연하지만, 상황에 맞게 사용하는 것이 적절하다고 봅니다.
또한 인덱스안에 속한 토큰을 나눌 때 N-Gram을 쓰는게 한국어를 쓸 때 유용하다고 하는데, 예시로 3Gram으로 하게 될 경우
- Hello world"라는 텍스트를 색인하면, "Hel", "ell", "llo", "lo ", "o w", " wo", "wor", "orl", "rld"
이런 식으로 단어를 3개로 분리해서 토큰을 처리합니다.
적용결과
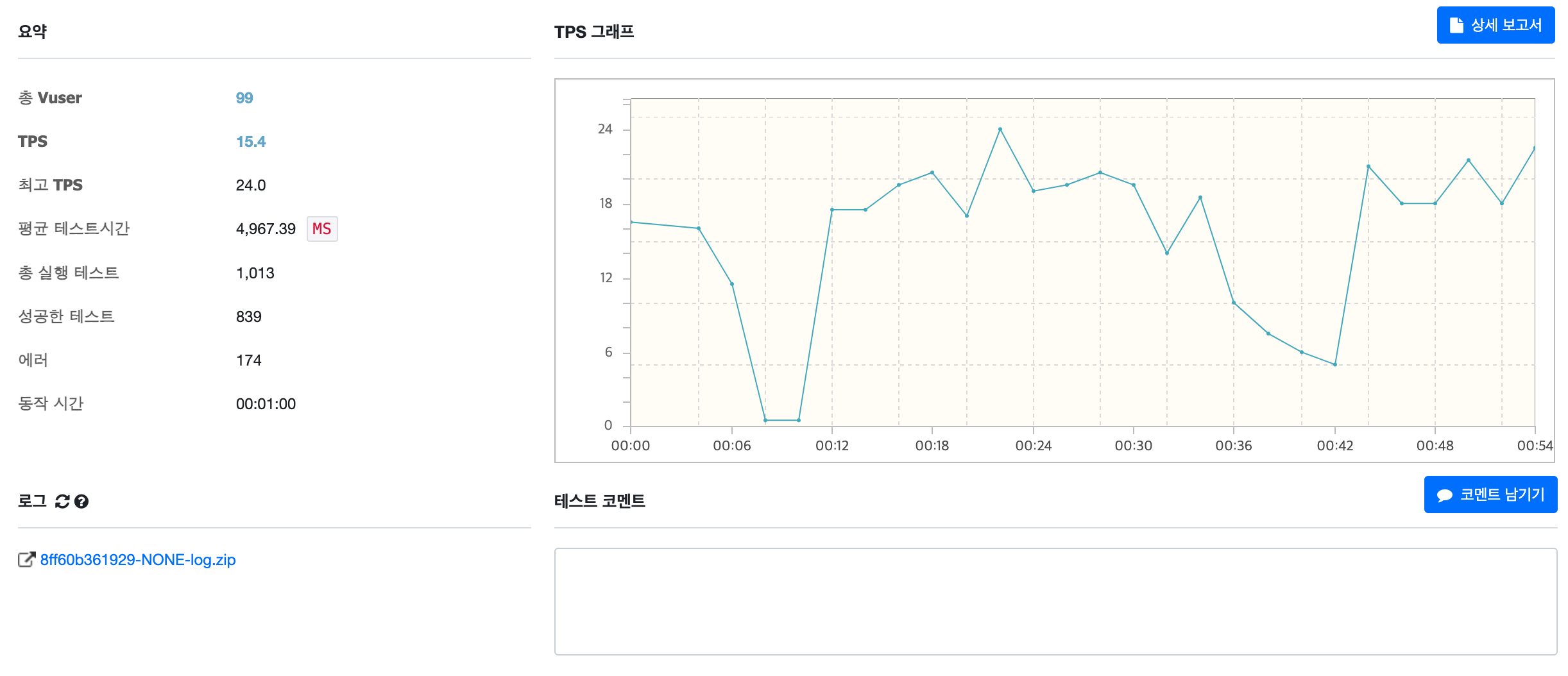
처리속도가 약 20% 높아졌습니다. 에러 역시도 많은 편이라 더 나은 방법을 찾아보았습니다.
Elastic Search?
엘라스틱 서치 역시 검색을 할 때 유용합니다. 엘라스틱 서치와 MySQL Full-text-search의 차이를 본다면, 엘라스틱서치는 토큰단위로 인덱스를 가지는 반면, Full-text-search는 여러 토큰이 하나의 인덱스에서 관리가 된다는 점이죠, 따라서 인덱스의 용량이 작기 때문에, 많은 데이터를 처리하는 과정에서는 처리속도 및 더 작은 용량을 차지하기 때문에, 이 두가지를 비교해 보았습니다.
Full Text Search vs Elastic Search
정리한 결과 다음과 같습니다. 또한 키바나와 같은 시각화 툴 역시 Elastic Search에서 쓸 수 있다는 점에서, 처리속도와 서비스 확장을 고려한다면 Elastic Search를 도입하는 것이 좋을거라 판단했습니다.
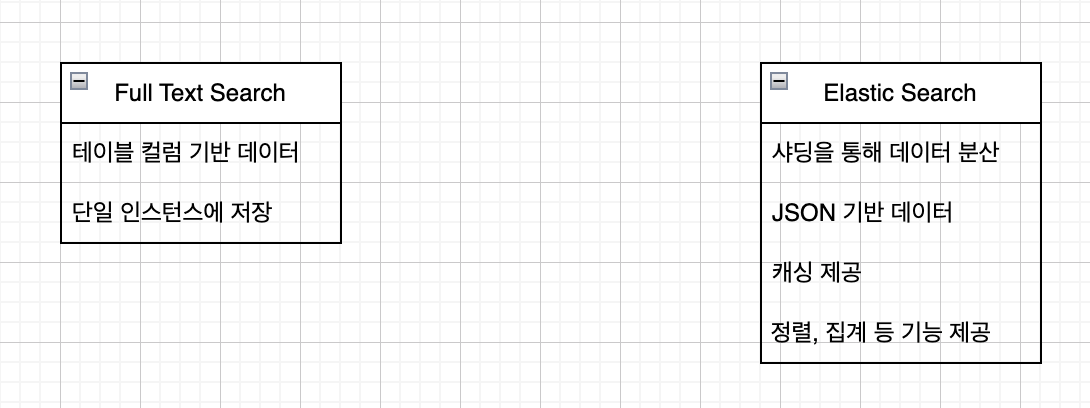
적용
적용하는 과정은 생각보다 오래걸리지 않았습니다. spring-data를 통해 jpa를 처리한 코드가 있어서 MySQL에 있는 데이터를 Elastic Search에 동기화 하는 부분까지 쉽게 구현할 수 있었던거 같네요..!
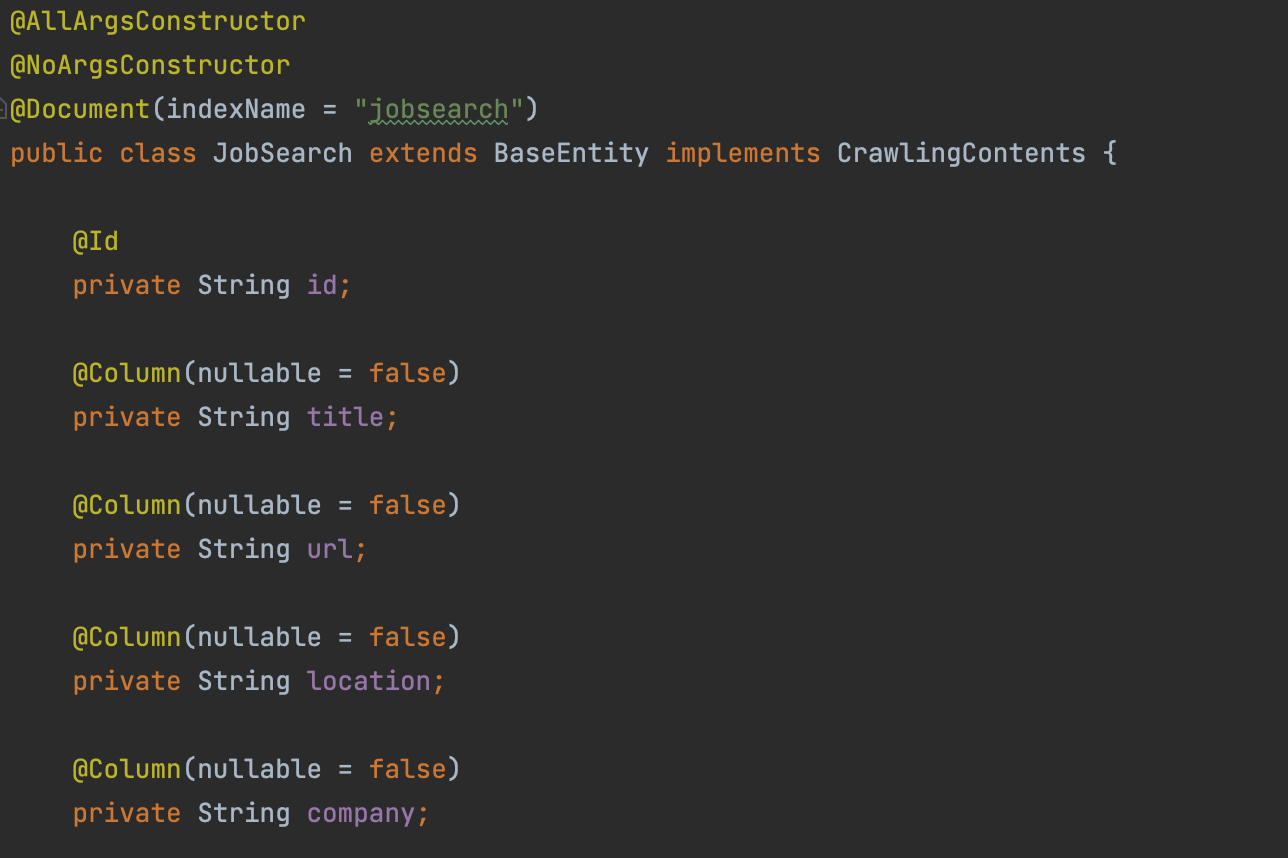

결과
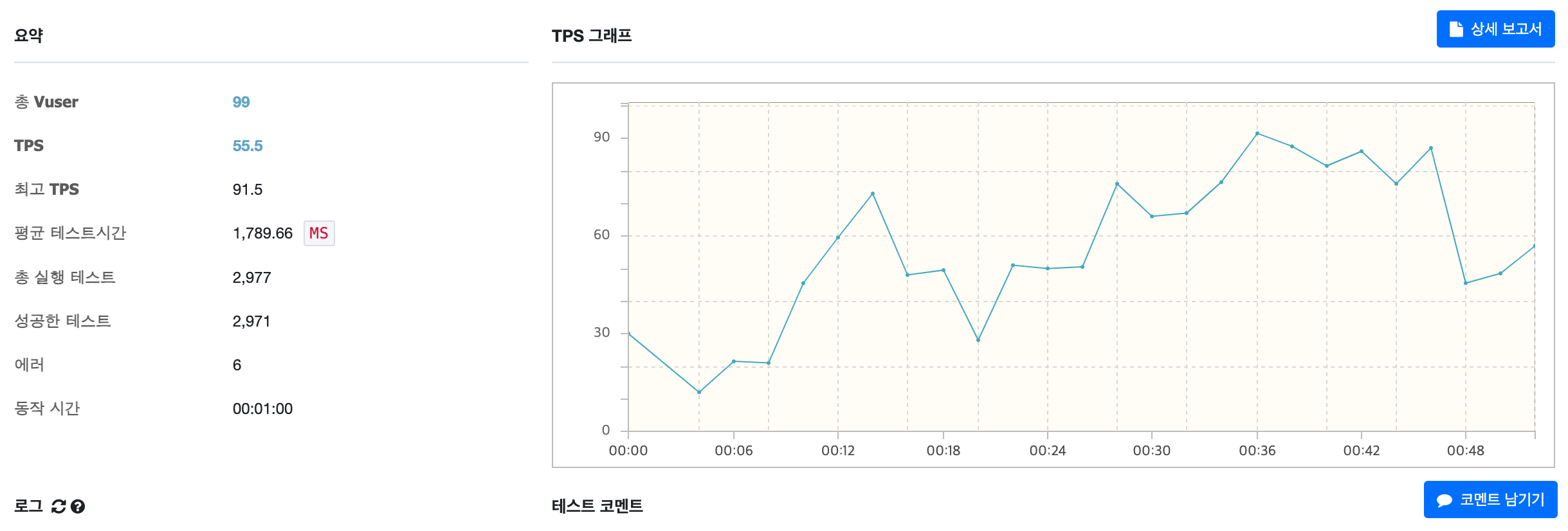
처리속도의 경우 기존에 비해 약 3~4배 정도 개선할 수 있었습니다... 다만 가져오는 데이터가 400개 이상 되다보니 TPS가 여전히 느린것을 알 수 있었습니다. 해당부분의 경우 가져오는 데이터를 충분히 줄인다면, 이슈를 해결 할 수 있다고 봤습니다.
주의할 점
엘라스틱 서치의 경우 처리속도상에 이점은 분명히 있던것 같았습니다. 하지만, 트랜잭션의 장점을 포기해야된다는 점이 큰 이슈였는데, 이 부분은 어느정도 감수해야 된다고 보여집니다. 롤백을 해야될 일이 많고, 이러한 이슈가 많게 된다면.. 엘라스틱서치에 대한 장점만 고려하면 알될 것 같습니다.. 결국 이 부분은 상황에 따라 대처하는게 맞을거라 보여집니다.
