기술면접에서 2번이나 DB 인덱스 관련해서
탈탈 털렸다정리 잘 하자..
1. Index?
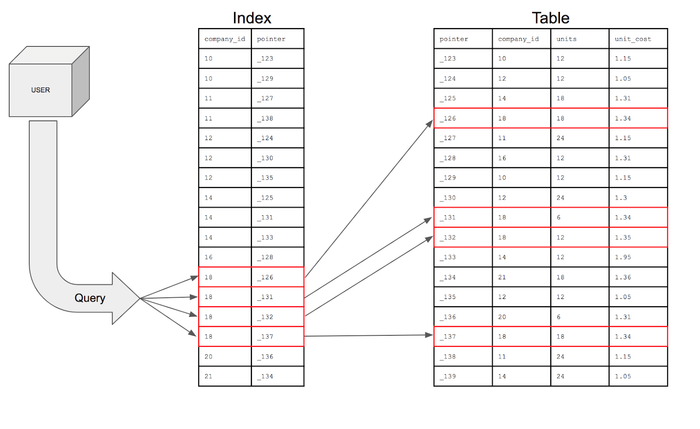
- 추가적인 쓰기 작업과 저장 공간을 활용하여 DB 테이블의 검색 속도를 향상시키기 위한 자료구조
- 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 도움
- 대략 분포도가 30% 미만일 경우 효과를 볼 수 있음
- 주의) 올바른 SQL을 작성하지 않으면 index를 타지 않는 경우가 발생한다
→ index가 있는 column에 function 적용, like, not in과 같은 쿼리문을 작성하였을 경우 등
Index의 장점
- 테이블 조회 속도와 그에 따른 성능 향상
- 전반적인 시스템 부하 줄일 수 있음
Index의 단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간 필요
- 인덱스를 관리하기 위해 추가 작업이 필요
- C(reate), U(pdate), D(elete)가 빈번한 속성에 인덱스를 걸게 되면 오히러 성능이 저하
2. MySQL에서 Index 실습 & 성능테스트
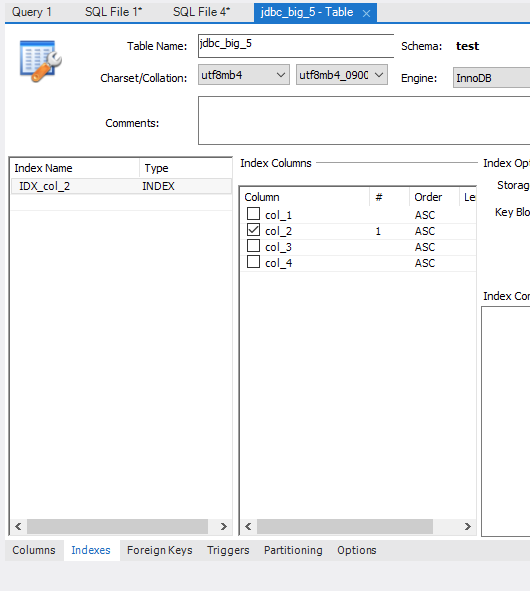
(1) Table-Alter Table-Indexes
- 인덱스를 새로 생성하고, 인덱스 이름, 인덱스가 적용될 칼럼(예시에서는 col_2)을 설정해줌
(2) 시간 비교
- 데이터가 180,000개 있는 데이터(데이터의 중복이 많아 완벽하게 인덱스의 성능을 측정하기에는 무리가 있지만 대략의 시간 측정)로 비교를 해본다
col_2=노수주인 칼럼을 출력하는 예시를 만들고 인덱스를 사용하기 전에는 12.243sec, 사용 후에는 5.375sec을 확인했다
select * from jdbc_big_5 where col_2='노수주'; -- 12.343 sec -> index 추가 후 5.375(3) 인덱스가 타지 않는 경우
-
와일드 카드 like문장에서 범위 전체를 지정시 (%가 앞쪽에 사용된 경우)
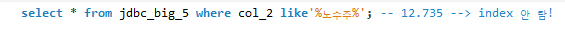
-
Not 또는 In 연산자 사용 → Not이나 In이 사용되었다고 모두 인덱스를 타지 않는 것이 아니라, Not에 사용된 값이 아닌 데이터의 비율이 높은 경우가 많기 때문에 인덱스를 타지 않는 경우가 많음

-
function을 사용한 경우
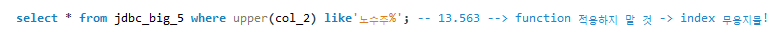
이 외에도 인덱스를 타지 않는 경우에는 인덱스 컬럼을 변경하는 경우, 복합 인덱스에서 첫 인덱스가 첫 조건으로 적용하지 않았을 경우 등이 있다
(4) FULL SCAN vs Index
인덱스를 설정하였다고 항상 인덱스를 타는 것은 아니다. DBMS가 판단하기에 Full Scan 더 효율적이라고 생각한다면 인덱스가 설정되어 있어도 Full Scan을 한다

- 위와 같은 예시에서 위에서 아래로 갈수록 성능의 향상이 있을 것이라고 예상했지만 그렇지 않아서 Execution Plan을 확인해 보았다
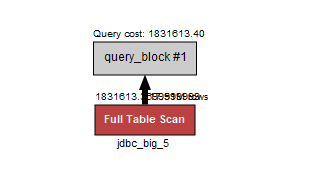
- 1번의 경우에
노%를 찾아야 할 때는 DBMS가 Full table scan이 유리하다고 판단했고 index가 지정되어 있음에도 full table scan을 진행
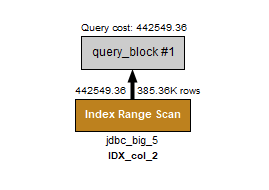
- 2번의 경우에
노수%을 찾아야 할 때 index를 탔고 위 1번보다 성능이 더 좋지 않았다
3. Index의 자료구조
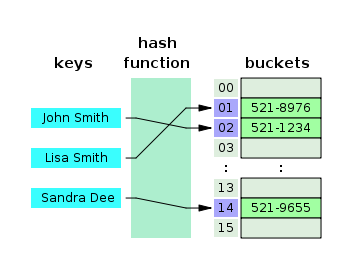
Hash Table
- Hash Table은 Key-Value 쌍으로 데이터를 저장하는 자료구조로 빠른 데이터 검색이 필요할 때 유용
- 해시 테이블은 내부에 버켓이라고 하는 배열에 존재하는데, 해시 함수를 통해 Key를 고유한 해시값으로 변환시켜 이를 버켓 배열의 인덱스로 사용하며 해당 인덱스에 Value를 저장한다
- DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데 그 이유는 해시가 등호(=)연산에만 특화되어 있기 때문이다
- 부등호 연산 (>,<)이 자주 사용되는 DB 검색을 위해서는 해시 테이블이 적합하지 않음
B+Tree
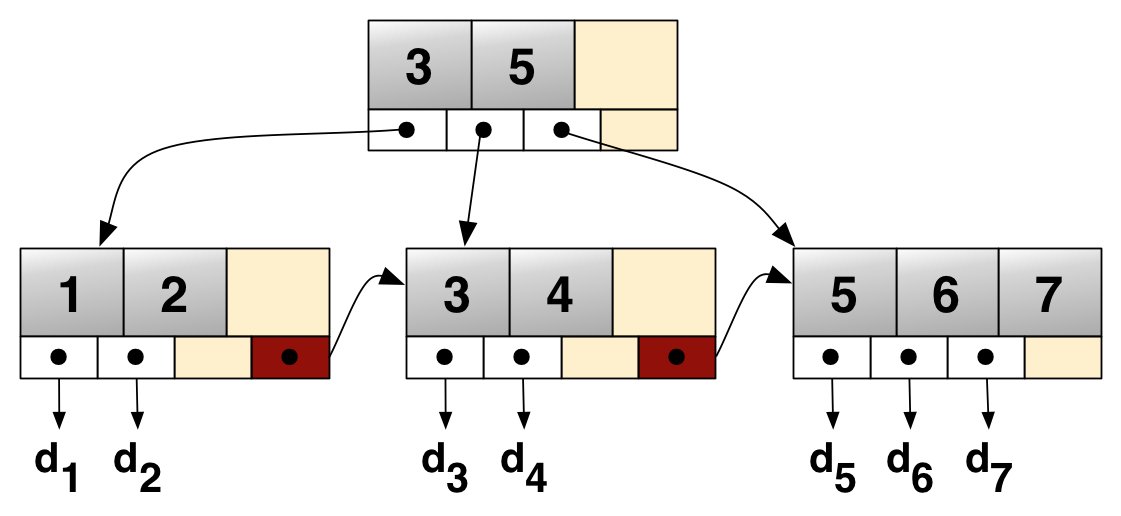
- B+Tree는 DB의 인덱스를 위해 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조
- 리프노드에만 인덱스와 함께 데이터를 가지고 있고, 나머지 노드들은 데이터를 위한 인덱스를 가짐
- 중간 브랜치 노드에 데이터가 없어서 B-Tree보다 메모리를 덜 차지하는만큼, 노드의 메모리에 더 많은 Key를 저장할 수 있음
- 리프노드들은 LinkedList로 연결되어 있다 → 부등호를 이용한 순차 검색 연산을 하는 경우, 많은 노드를 방문해야하는 B-Tree에 비해 말단 리프노드를 저장한 LinkedList를 한 번만 탐색하는 등 속도 이점
Reference
https://mangkyu.tistory.com/96
https://tecoble.techcourse.co.kr/post/2021-09-18-db-index/

백엔드 개발자 지망생에서 Test Engineer. 를 지나 AI Engineer를 향해 가는 Software Engineer (https://juyoungkimmy-kim.github.io/ 블로그 이주))