3차 sprint
인턴 마지막 주차에 시작된 3차 sprint
사실상 개발을 할 수 있는 시간은 약 1.5일
상황
- 오전에는 그동안 제대로 되지 않았던 업무 process에 대해서 쓴 소리를 들었고,
- 오후에는 인턴 채용 과정에서 탈락 통보를 받았고,
- 퇴근시간 즈음부터 3차 sprint를 시작해야 했다.
- 기획서 분석 > DB setting > mockserver & data > API doc 을 거쳐
- API 개발까지는 월요일 저녁 ~ 수요일 오전 scrum 미팅 직전까지의 시간까지
- pandas 활용해서
- 기능구현 되지 않으면 drop
로직
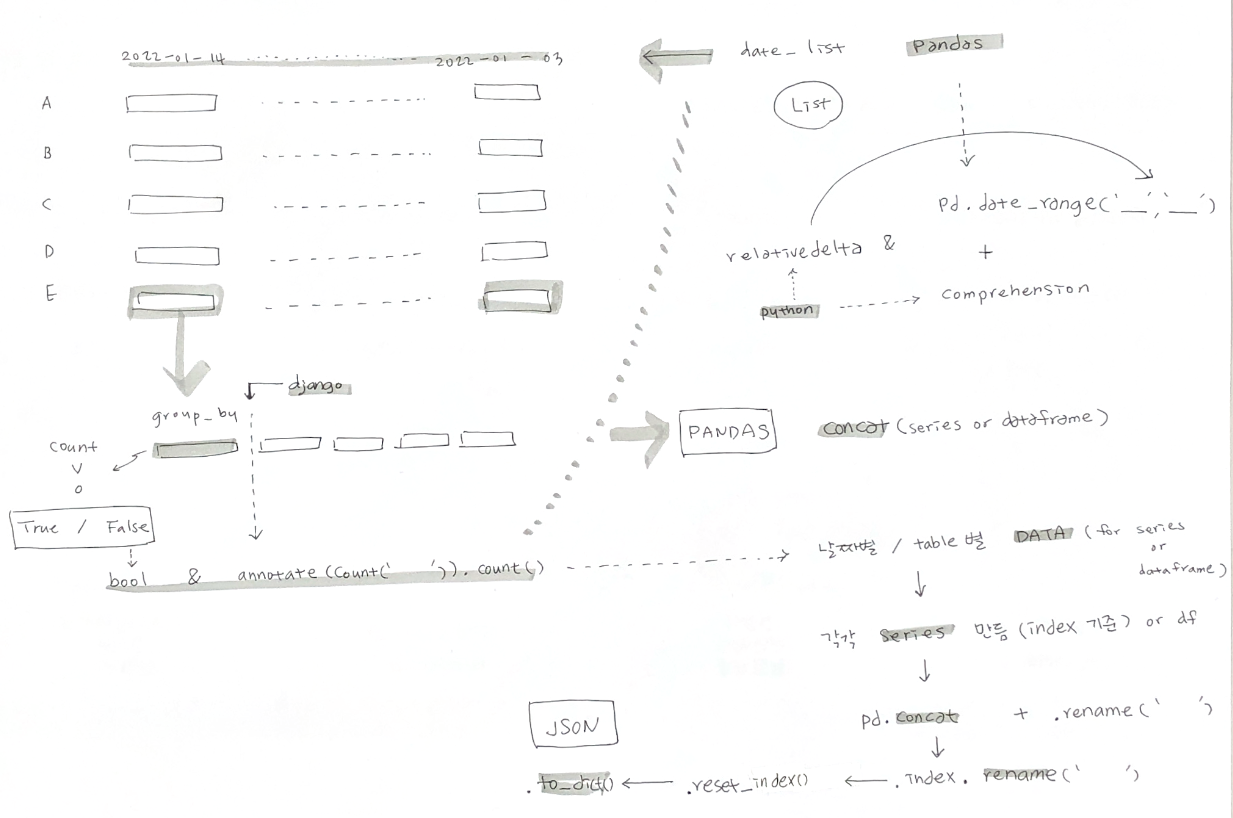
- 기능 : 자산별 영업일 기준 일별 데이터 존재여부 파악
- 영업일 데이터 구하기
->pandas-> Index - DB 별로 table을 돌면서 2에서 구한 일자에 데이터 유무 확인
->group_by,count->bool,annotate(Count()),count()-> list - 3의 list를 하나의 포맷으로 합치기 위한 전처리
->pandas->dataframe또는series로 변환 - 4의
series를 합친다
->pandas->concat - Json 형태로 변환하여 데이터 출력
->.to_dict(orient='records')
날짜 리스트를 구하고, comprehension으로 날짜를 하나씩 꺼내어 해당하는 db의 table의 날짜 컬럼에서 꺼낸 날짜의 모든 데이터를 group_by(annotate) 해서 count를 하고 0 이상이면 True를 반환하는 것이 첫 번째, 그렇게 다섯 번 돌고 합치면 되는 것
error 또는 궁금증
-
count
꼭 굳이 그렇게 많은 데이터(일자별로 2,000개 이상임)를 그룹해서 갯수를 센 다음에 0인지 아닌지 판단해야 하나? 예를 들어count를 쓰지 않고 존재 여부만 확인 할 수 있는? 바로 bool을 쓸 수 있다거나 뭐 그런 방법이 없을까 했었는데, 꼭count를 해야 함 -
Json
별짓 다해도 list에 담긴 dictionary 형태로 반환이 안되었는데, 해결책은index에 있었다.
dataframe과merge로 아무리 시도를 해도index기준으로merge까지는 했으나.index.rename과.reset_index()개념이 확실 하지 않아서 "이걸 해봐야 되나?"하는 생각을 했음에도 적용하지 못했고, 결국 선배님이 단 두 줄로 해결해주신.
-> Javascript의 이해가 필요하다고 생각했던 순간 & 내 부족함이 front를 고생하게 한다는 마음에 정말 오랜시간동안 인턴이 끝나고도 정말 괴로웠다(아니 지금 대낮에 술도 안마셨는데 이 때 생각만 하면 눈물날일?????). 이걸 해결하지 못하면 그대로 drop이었기 때문에 너무 미안했다.
2-1. .to_dict() + orient='records' + safe=False
result_df.index = result_df.index.rename('date')
#날짜리스트(=index)에 이름만 주면 될 일
result_df = result_df.reset_index()
#index를 reset 하면 될 일
result_dict = result_df.to_dict(orient='records')
return JsonResponse(result_dict, safe=False)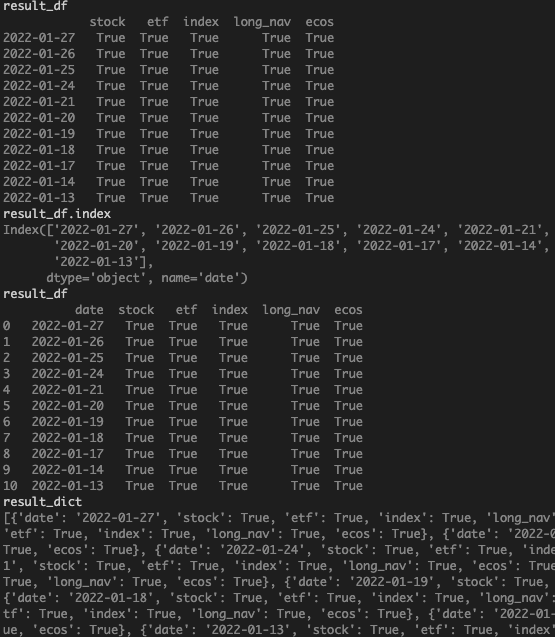
결론
수요일 새벽 드디어 PR을 올리고, scrum 미팅 때 merge,,,
- 어쨌든 데이터는 나왔고
- 디버깅 실컷 했고(이제 눈감고도 함...........?)
- Docker에서 새로운 error 흫 (애증의
.env)
- 추가로 공부할 것!!!
(concat,mergevsdataframe,series)
