Introduction
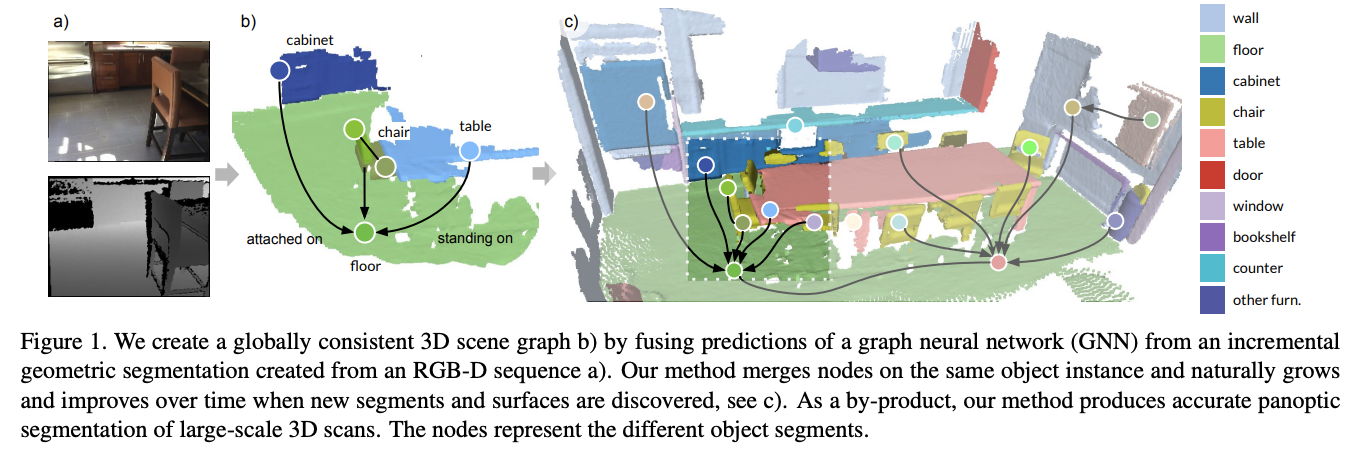
- Depth sensor의 이용, real-time dense SLAM 알고리즘의 발달 등과 함께 3D scene reconstruction은 geometric 정보뿐만 아니라 semantic 정보의 복원까지 그 중요성이 부각되었다.
- 그동안의 연구들은 완전한 3D scan을 얻기 위해 3D geometry를 사전 정보로 활용하였으며 실시간이 불가능하였다.
- 실시간 scene understanding에 있어 object의 모양이 시간에 따라 변하는 부분적이고 불완전한 scene의 복원과 global map에서 consistency를 유지하는 것은 어려운 문제이다.
- 본 연구에서는 incremental하게 3D mapping과 semantic scene graph를 동시에 만드는 real-time method를 제시한다.
Incremental 3D Scene Graph Framework
Scene Reconstruction with Property Building
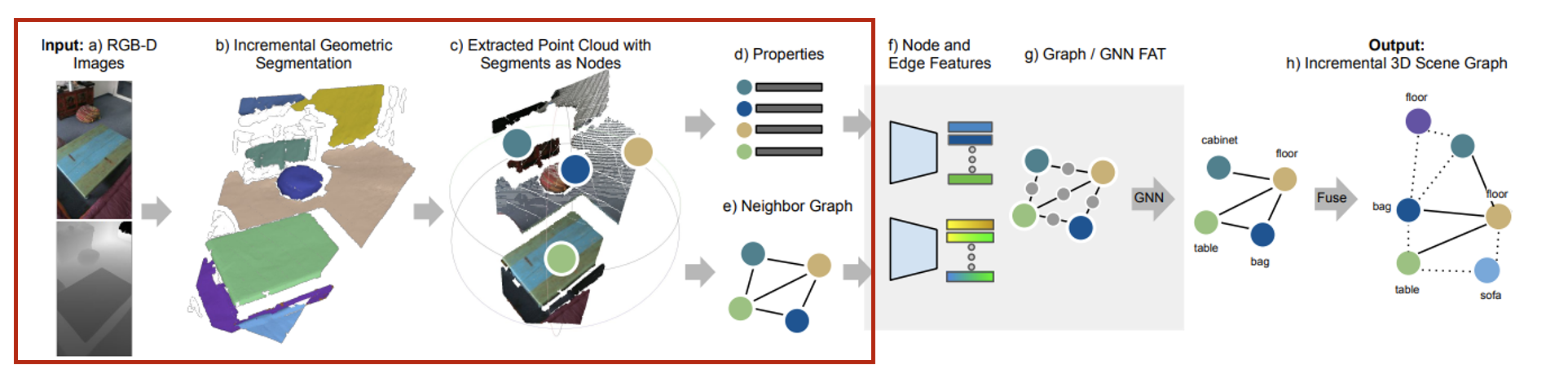
- Input으로는 RGB-D 이미지들이 camera poses와 함께 순차적으로 들어온다.
- Incremental한 방식으로 globally consistent segmentation map을 만들어 online property update와 neighbor graph와 함께 통합시킨다.
- Segmentation node: 매 frame마다 update되는 3D sementation map은 segments들의 집합 로 구성되어 있으며 각 segment들은 3D 좌표의 집합 와 color에 대한 정보를 담고있다.
- Segmentation Properties: Segment의 모양을 나타내기 위한 properties에는 position들의 표준편차, bbox의 size 등이 담겨있으며 이 또한 update 된다.
- Neighbor graph: 모든 segments의 bbox 간 거리를 계산하여 thereshold(0.5m)보다 작을 경우 edge로 연결한다.
Prediction with Graph Structure
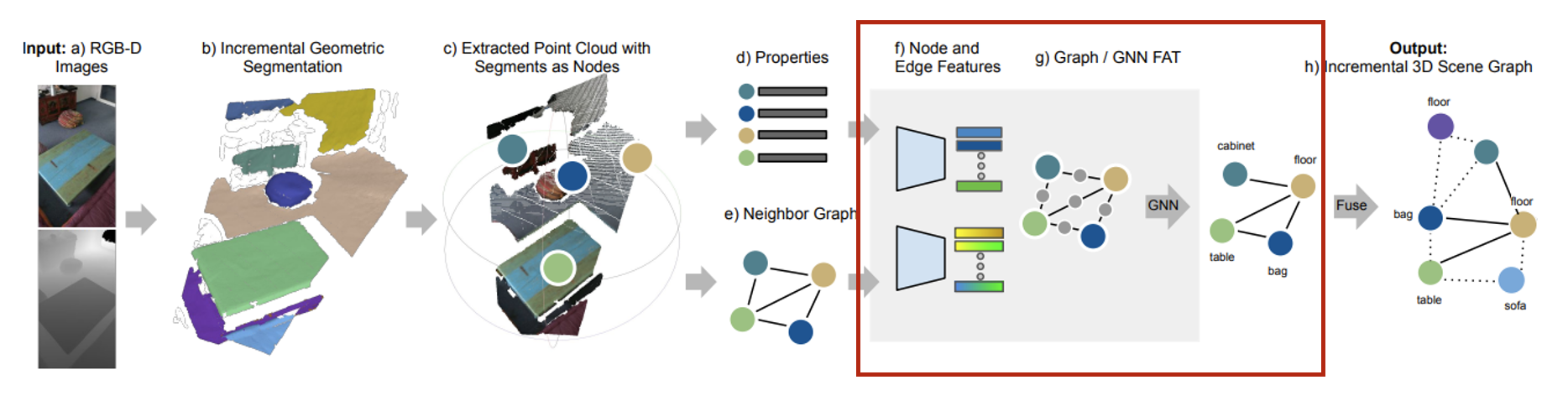
- Segments properties와 neighbor graph는 네트워크를 통과하여 segment label과 predicate를 예측한다.
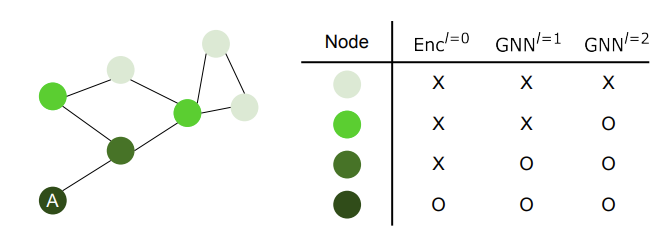
- Incremental segment reconstruction이기 때문에 최근 frame에서 update된 segement와 neighbor graph만을 네트워크에 넣어주며 현재 frame에서 관측되는 것들만 update된다.
- 최신 update를 확인하기 위해 segment size와 timestamp를 매 frame마다 저장하며 segment의 size가 10% 이상 변하거나 60frame 동안 update가 없을 경우 체크를 한다.
- 효율성을 위해 SPN에서 계산된 neighbor graph의 모든 features를 저장한 후 재사용한다.
Temporal Scene Graph Fusion
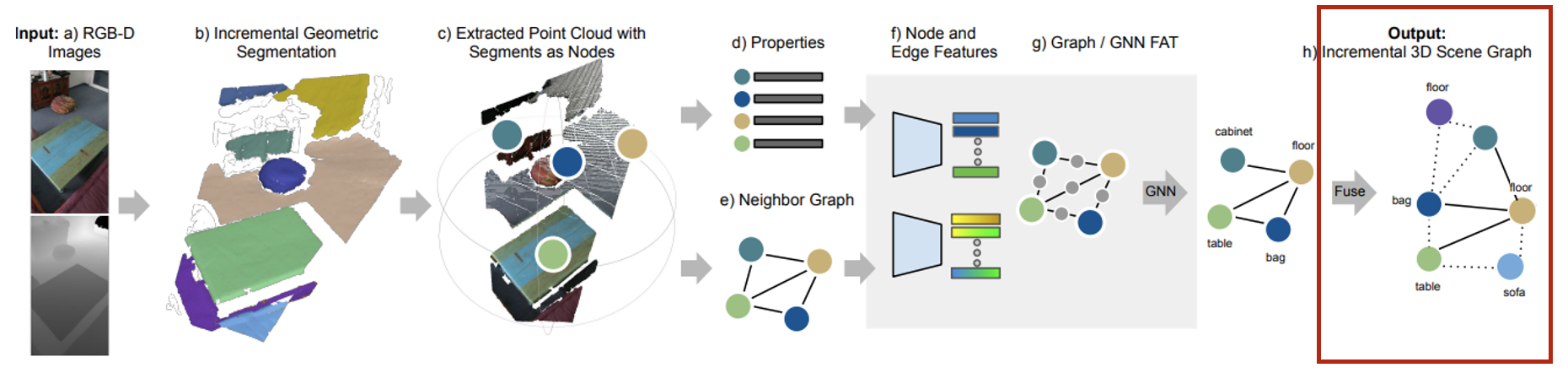
- 예측된 scene graph는 globally consistent semantic scene graphy에 fuse된다.
- 여러번 예측하기 때문에 서로 모순되는 결과가 나올 수 있는데 이는 running average approach를 활용하여 해결한다.
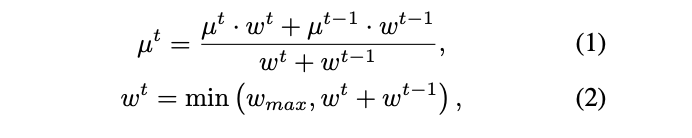
Scene Graph Prediction
-
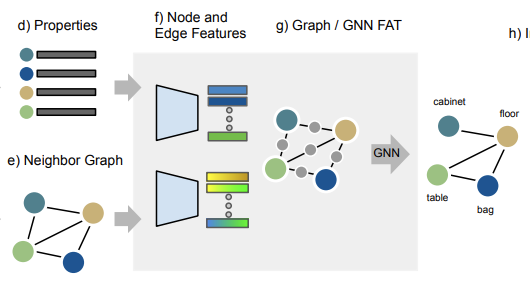
Node feature
Point cloud 가 PointNet을 거쳐 인코딩된 latent feature
Segment 내 포인트들의 위치의 표준편차
bounding box size의 log값
bounding box의 부피의 log값.
bounding box의 최대 길이의 log값. -
Edge feature
,
segment의 중심점
: paired segment properties를 latent space로 보내는 MLP -
GNN feature
노드와 엣지의 feature는 2개의 message passing layer를 거치는 GNN을 통과하여 neighborhood 정보를 포함시킨 강화된 feature를 뽑아낸다.
,
: 노드 의 이웃 노드들의 인덱스 집합
MLP
- feature-wise attention network
- Multi head를 사용하며 target node의 feature를 통해 attention을 학습한다.
- 를 차원으로 맵핑하는 단일 퍼셉트론
-
Class Prediction and Losses
2개의 MLP classifier를 통해 node class와 edge predicate를 예측하며 손실함수는 joint cross entropy loss 와 를 사용한다.
Data Generation
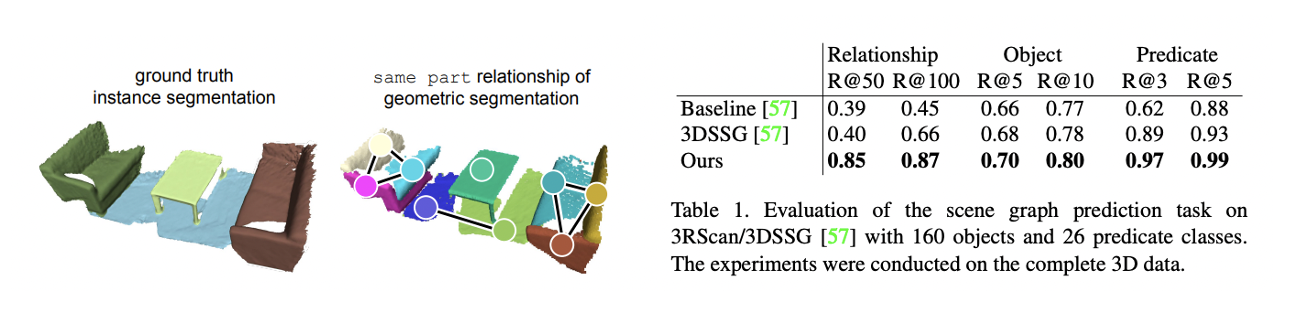
- Geometric한 방식의 segmentation을 할 때는 가장 가까운 GT와 매칭을 하며 IOU를 활용해 그 유효성을 검증한다.
- 본 연구에서는 dataset에 same part라는 relationship을 더해주어 over-segmented되는 것을 방지하였고 그 결과 다른 데이터셋보다 좋은 성능을 보였다.
