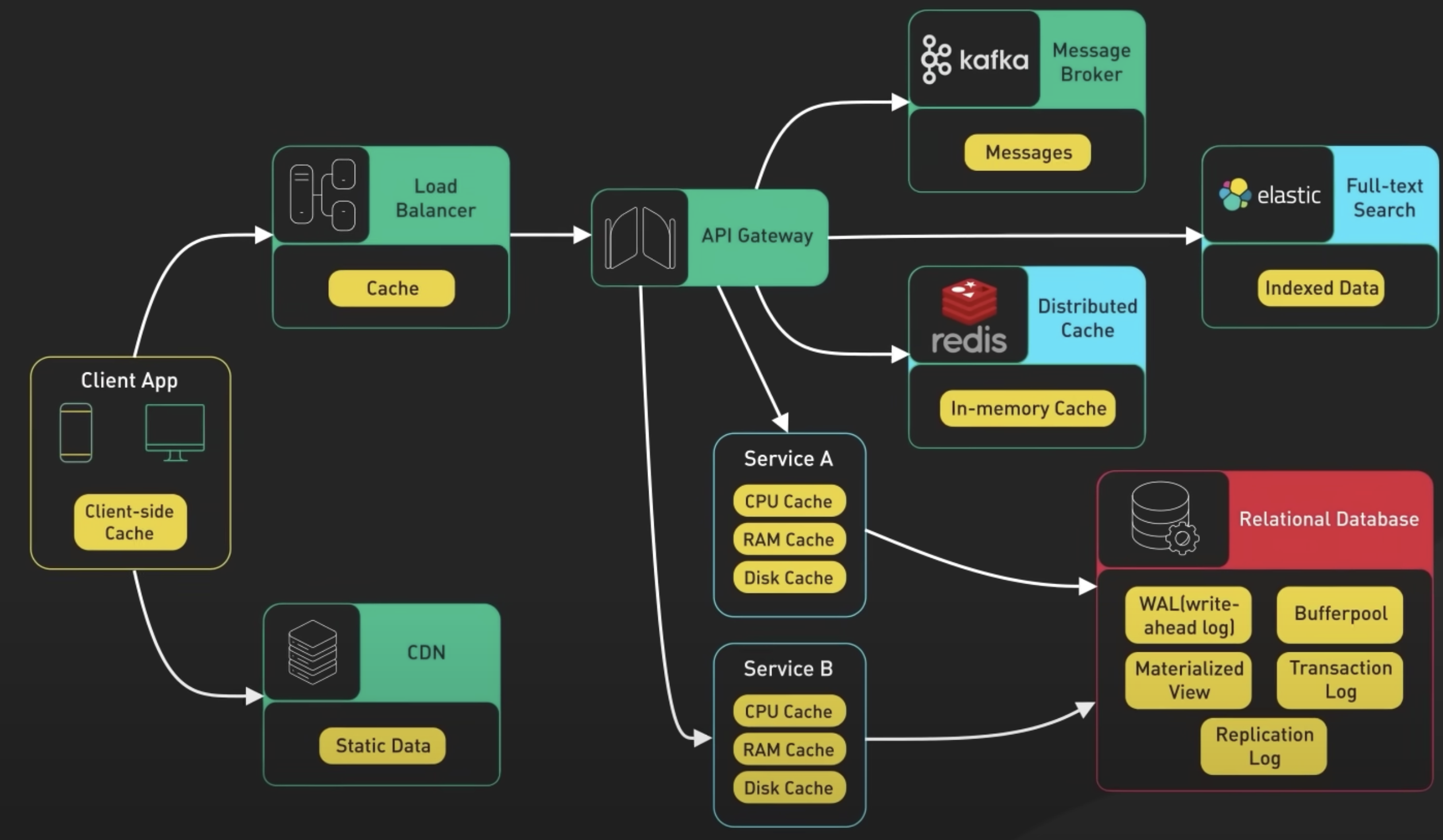
1. 하드웨어 계층
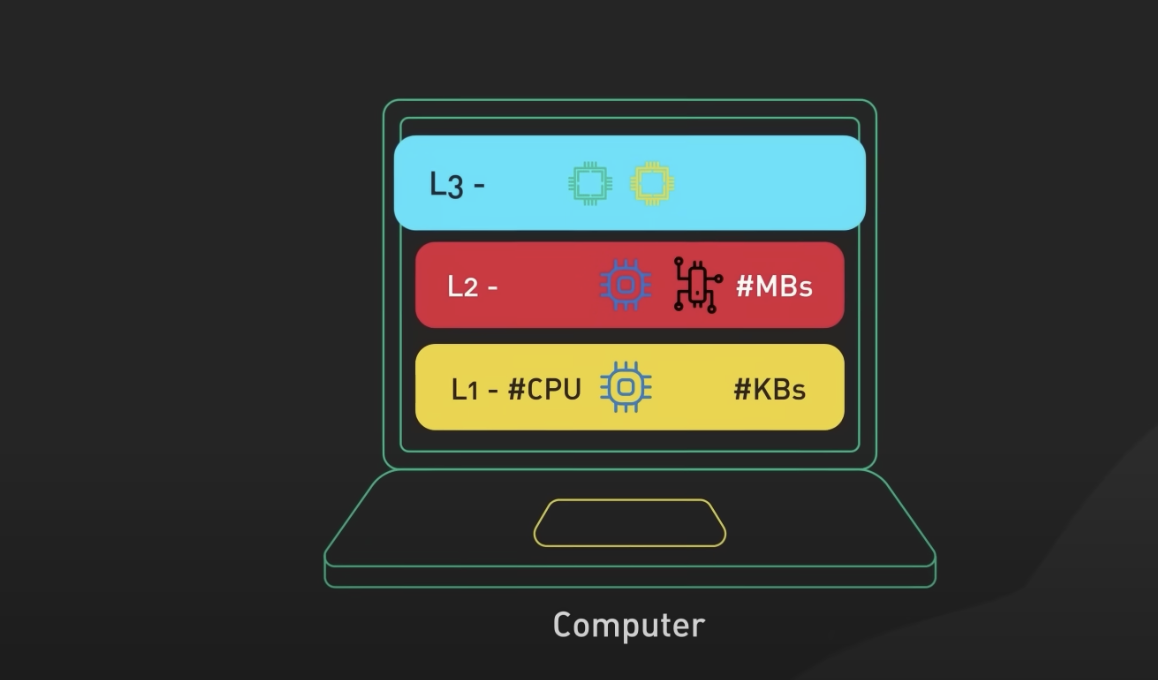
컴퓨터 하드웨어에서 L1, L2, L3 캐시는 프로세서(중앙 처리 장치)에 위치한 여러 수준의 캐시를 말합니다. 이들 캐시는 다른 용도와 크기를 가지며, 프로세서의 성능 향상에 기여합니다.
1) L1 Cache
- L1 캐시는 가장 빠르고 작은 용량의 캐시로, 프로세서에 가장 가까운 위치에 있습니다. 주로 명령어 캐시와 데이터 캐시로 구분됩니다. 명령어 캐시는 프로세서가 다음에 실행할 명령어들을 저장해 놓고, 데이터 캐시는 프로세서가 자주 액세스하는 데이터를 저장합니다. L1 캐시는 매우 빠른 액세스 시간을 제공하며, 프로세서의 실행 성능을 크게 향상시킵니다.
2) L2 Cache
- 보통 L1 캐시의 데이터를 지원하고 보충하는 역할을 합니다. L1 캐시에서 찾지 못한 데이터나 명령어를 L2 캐시에서 찾아내기도 합니다. L2 캐시의 크기와 속도는 프로세서 제조사와 모델에 따라 다르며, L1 캐시보다는 약간 느리지만 여전히 매우 빠릅니다.
3) L3 Cache
- L3 캐시는 더 크고 느린 캐시로, 여러 개의 코어(컴퓨터의 다수 프로세서)가 공유하는 공유 캐시입니다. 예를 들어, 멀티코어 프로세서에서 각 코어는 자체적인 L1, L2 캐시를 갖지만, 이들 코어가 공통으로 사용하는 L3 캐시도 존재합니다. L3 캐시는 주로 멀티코어 간 데이터 공유를 최적화하고 대량의 데이터를 캐싱하는데 사용됩니다. 따라서 멀티코어 프로세서 시스템에서 성능 향상을 가져올 수 있습니다.
4) Translation Lookaside Buffer(TLB)
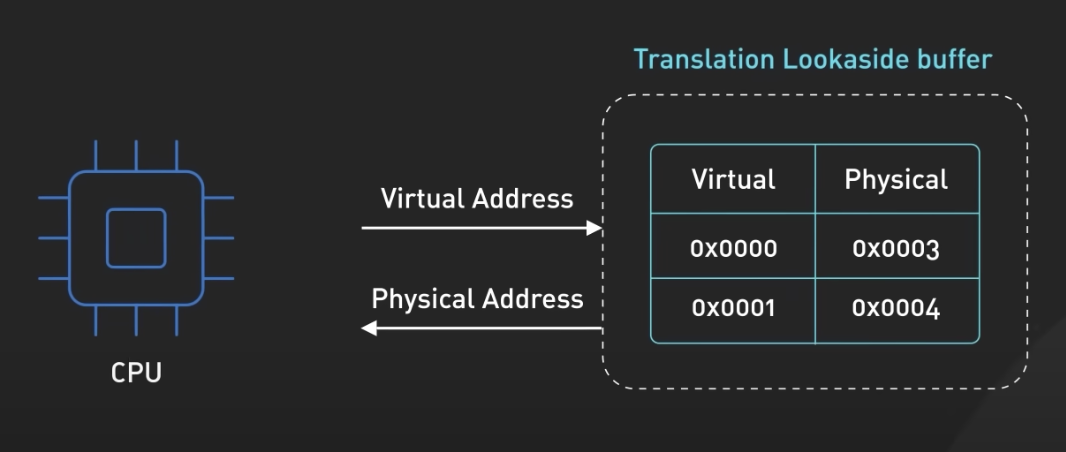
-
TLB는 주소 변환을 더 효율적으로 수행하기 위해 사용되는 하드웨어 캐시입니다. TLB는 가상 메모리 주소를 물리적 메모리 주소로 변환하는 데에 사용됩니다. 가상 메모리는 프로세스가 사용하는 메모리 주소이고, 물리적 메모리는 실제로 컴퓨터가 사용하는 메모리 주소입니다.
-
프로세스가 메모리에 접근할 때마다, 해당 가상 주소는 물리적 메모리 주소로 변환되어야 합니다. 이러한 주소 변환은 주로 페이지 테이블이라는 데이터 구조를 통해 이루어집니다. 페이지 테이블은 가상 주소와 물리 주소 간의 매핑 정보를 저장하는 테이블입니다.
-
TLB는 이러한 페이지 테이블을 캐싱하여, 매번 주소 변환 시마다 메모리에 접근하는 비용을 줄입니다. TLB는 최근에 접근한 주소 변환 결과를 저장하여 빠르게 접근할 수 있도록 합니다.
-
TLB는 일반적으로 프로세서 내부에 위치하며, 가상 주소가 주기억장치에 접근할 때마다 TLB를 먼저 확인하여 물리 주소를 얻어냅니다. TLB는 속도가 빠르기 때문에 이후의 메모리 접근이 빨라집니다.
2. OS 계층
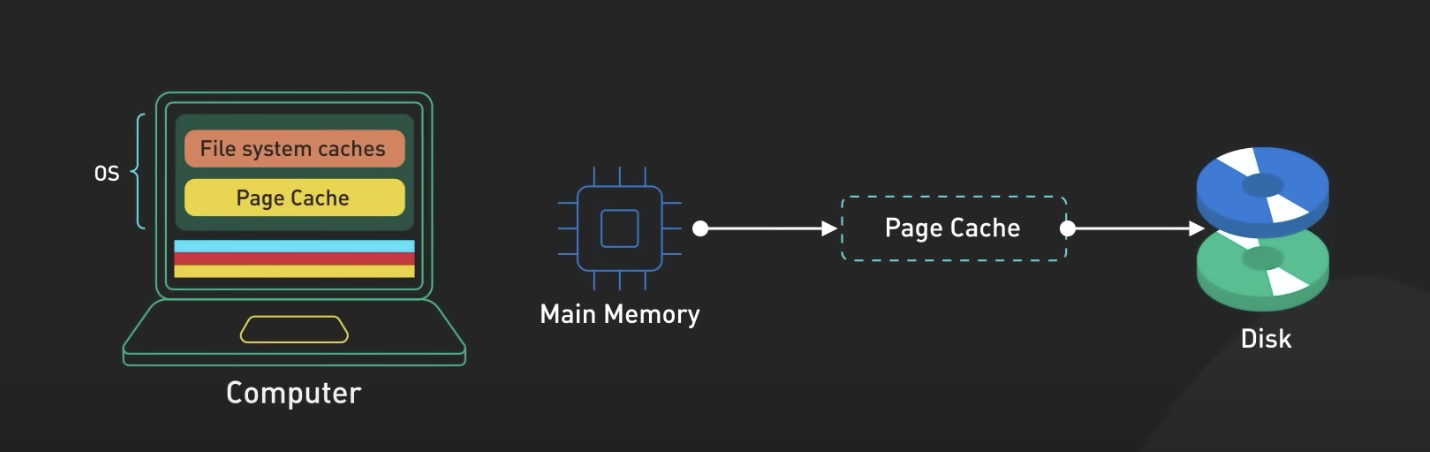
1) Page Cache
- Page cache는 운영 체제(OS)에서 디스크로부터 읽은 데이터를 메모리에 캐싱하여 빠른 액세스를 제공하는 메모리 캐시입니다. 이를 통해 파일 입출력 작업의 성능을 향상시키고 시스템의 전반적인 성능을 개선할 수 있습니다. Page cache는 파일 시스템의 일부로 동작하며, 디스크로부터 읽은 데이터 블록을 페이지 단위로 관리합니다.
(1) 읽기 요청
어플리케이션이 파일을 읽으려고 요청하면, 운영 체제는 해당 파일의 데이터 블록을 디스크에서 메모리로 가져옵니다. 이때 Page cache에 읽어온 데이터 블록을 저장합니다.
(2) 페이지 단위 관리
Page cache는 페이지 단위로 데이터를 관리합니다. 페이지의 크기는 운영 체제와 파일 시스템에 따라 다르지만 일반적으로 4KB 또는 8KB 크기를 가집니다. 디스크 블록 크기와 페이지 단위가 다른 이유는 페이지 단위로 데이터를 캐싱함으로써 더 효율적인 캐시 관리가 가능하기 때문입니다.
(3) 캐시된 데이터 활용
어플리케이션이 동일한 데이터를 다시 요청하면, 이전에 읽은 데이터가 Page cache에 캐싱되어 있으므로 디스크로부터 다시 읽지 않고 바로 메모리에서 데이터를 반환합니다. 이로 인해 빠른 액세스가 가능합니다.
(4) 쓰기 작업 관리
파일에 데이터를 쓰는 작업 역시 Page cache에 의해 관리됩니다. 어플리케이션이 데이터를 파일에 쓰면, 해당 데이터가 바로 디스크에 기록되는 것이 아니라 Page cache에 먼저 저장됩니다. 이후 운영 체제는 적절한 시기에 변경된 데이터를 디스크에 기록(Flush)합니다. 이러한 방식으로 디스크에 쓰기 작업의 횟수를 줄여서 I/O 성능을 향상시킵니다.
(5) 메모리 관리 및 데이터 정책
운영 체제는 메모리가 부족할 때, Page cache에서 데이터를 제거하여 새로운 데이터와 교체할 수 있습니다. 이 때 사용되는 데이터 정책에는 LRU(Least Recently Used) 등이 있으며, 페이지의 접근 패턴과 중요도 등을 고려하여 최적의 페이지를 유지하도록 합니다.
LRU는 "Least Recently Used"의 약어로, LRU 정책은 캐시에 여러 데이터가 존재할 때, 가장 오랫동안 접근되지 않은 데이터를 우선적으로 제거하는 방식입니다. 캐시의 용량이 한정되어 있을 때, 더 이상 데이터를 캐시에 저장할 공간이 없을 때 새로운 데이터를 캐시에 올리기 위해 기존 데이터를 제거해야하는데, 이때 LRU 정책을 사용하여 가장 오랫동안 접근되지 않은 데이터를 제거합니다.
2) Inode cache
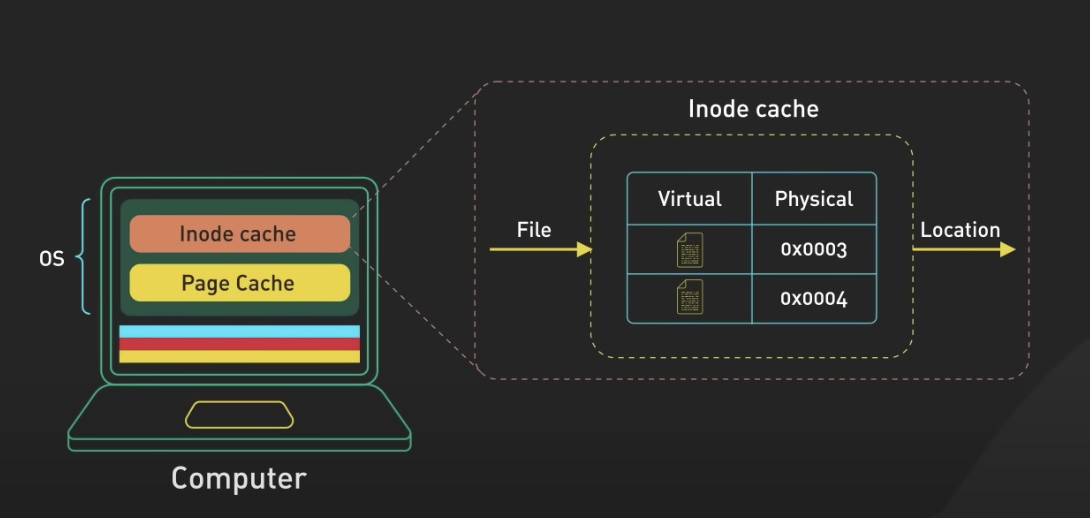
- Inode cache는 운영 체제에서 파일 시스템의 성능을 향상시키기 위해 사용되는 캐시입니다. Inode은 파일 시스템에서 파일과 디렉터리의 메타데이터를 저장하는 데이터 구조로, 파일의 이름, 크기, 소유자, 권한 등의 정보를 포함합니다.
(1) Inode 정보 로드 시
파일 시스템에 접근하여 파일이나 디렉터리를 찾거나 생성할 때, 해당 파일 또는 디렉터리의 Inode 정보를 얻어야 합니다. 이 때 운영 체제는 Inode cache를 확인합니다.
(2) Inode cache 체크
Inode cache는 메모리에 위치하며, 최근에 접근된 파일의 Inode 정보를 캐싱합니다. 어플리케이션이 파일을 열거나 다룰 때마다 해당 파일의 Inode 정보를 캐시에서 확인합니다.
(3) 캐시 미스
Inode cache에 원하는 Inode 정보가 없는 경우, 이를 "캐시 미스"라고 합니다. 이 경우 운영 체제는 디스크에서 해당 Inode 정보를 읽어와 캐시에 저장합니다. 그리고 다음에 같은 파일을 접근할 때는 캐시에서 직접 읽어오므로 디스크 액세스를 피할 수 있습니다.
(4) 캐시 유효성 관리
Inode cache는 메모리에 저장되므로, 운영 체제는 적절한 시기에 Inode cache를 갱신하고 메모리 용량을 효과적으로 사용하기 위해 캐시 유효성을 관리합니다. 캐시가 오래되거나 더 이상 필요하지 않은 Inode 정보는 메모리에서 해제되어 다른 데이터를 저장할 수 있게 됩니다.
OS 계층 캐싱 정리
Page Cache는 파일의 실제 데이터를 메모리에 캐싱하고, Inode Cache는 파일 시스템의 메타데이터를 메모리에 캐싱합니다. 이 두 가지 캐시 메커니즘은 모두 파일 시스템 성능 향상에 기여하지만, 각각 다른 캐시 대상과 목적을 가지고 있습니다.
3. 어플리케이션 계층
1) Client-Side Cache
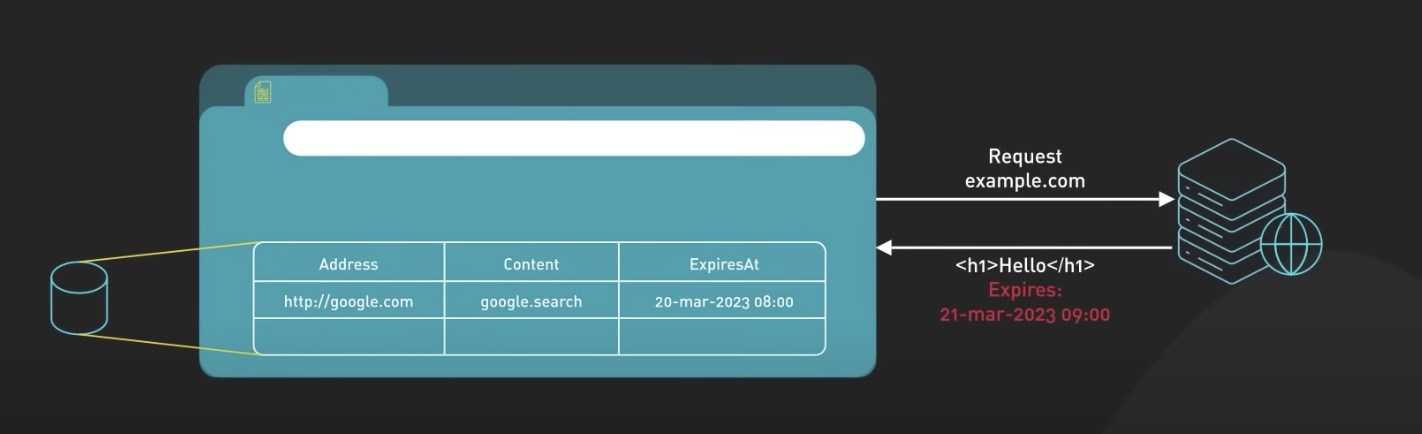
- Client-Side Cache는 웹 브라우저에서 사용자의 장치(클라이언트)에 웹 페이지의 리소스를 저장하여, 이후 같은 페이지를 방문할 때 서버로부터 리소스를 다시 요청하지 않고 빠르게 렌더링할 수 있는 기술입니다.
브라우저 캐시(Browser Cache)
브라우저 캐시는 웹 페이지의 정적 리소스(예: HTML, CSS, JavaScript, 이미지 파일 등)를 저장하는 메모리나 디스크 공간입니다. 이러한 리소스는 웹 페이지에 접근할 때 서버로부터 다시 다운로드되지 않고, 브라우저 캐시에서 로드됩니다.
브라우저 캐시는 웹 페이지의 헤더에 지정된 캐시 제어 정책을 따라 동작합니다. 캐시 제어 정책은 웹 서버가 응답 헤더에 포함시키며, 해당 리소스를 얼마나 오래 캐싱할지, 캐시를 사용할 수 있는 시간 등을 지정합니다.
브라우저 캐시는 사용자가 브라우저를 종료하거나 캐시를 지우는 등의 동작을 수행하지 않는 한, 반복적인 방문 시 웹 페이지 로딩 속도를 크게 향상시킵니다.
2) CDN

- CDN(Contents Delivery Network)은 전 세계에 분산된 서버 네트워크를 사용하여 콘텐츠를 효율적으로 전송하는 기술입니다. 이를 통해 사용자가 웹 페이지를 더 빠르게 로드하고, 콘텐츠에 빠르게 접근할 수 있도록 지원합니다. CDN은 주로 정적인 콘텐츠(이미지, CSS, JavaScript 파일 등)를 캐싱하여 처리하는데, 이를 통해 웹 사이트의 성능을 개선하고 서버의 부하를 분산시킵니다.
(1) 원본 서버
원본 서버는 웹 사이트의 콘텐츠를 호스팅하는 서버입니다. 사용자가 웹 페이지에 접근하면, 브라우저는 원본 서버에 콘텐츠를 요청합니다.
(2) CDN 서버
CDN은 원본 서버와 분산된 여러 개의 서버를 가지고 있습니다. 이러한 서버들은 전 세계 여러 지역에 위치하며, 사용자에게 가장 가까운 서버로 콘텐츠를 제공할 수 있도록 합니다.
CDN 서버는 원본 서버로부터 콘텐츠를 복제하여 저장합니다. 이렇게 저장된 콘텐츠를 Edge Cache라고 합니다.
(3) 사용자 요청 시
사용자가 웹 페이지에 접근하면, 브라우저는 DNS(Domain Name System)를 통해 CDN 서버의 주소를 찾습니다.
사용자의 위치와 가장 가까운 CDN 서버로부터 콘텐츠를 제공받기 위해 CDN 서버에 요청을 보냅니다.
(4) CDN 서버 응답
CDN 서버는 Edge Cache에 저장된 콘텐츠를 확인합니다. 해당 콘텐츠가 Edge Cache에 존재한다면, CDN 서버는 콘텐츠를 바로 사용자에게 전송합니다. 이렇게 함으로써 원본 서버로부터 콘텐츠를 다시 다운로드할 필요가 없어집니다.
만약 해당 콘텐츠가 Edge Cache에 존재하지 않는다면, CDN 서버는 원본 서버로부터 콘텐츠를 다운로드하여 Edge Cache에 저장합니다. 그리고 사용자에게 해당 콘텐츠를 전송합니다.
이러한 흐름을 통해 CDN은 웹 사이트의 성능을 향상시키고, 전세계 사용자에게 빠른 콘텐츠 전송을 지원합니다.
3) Load Balancer
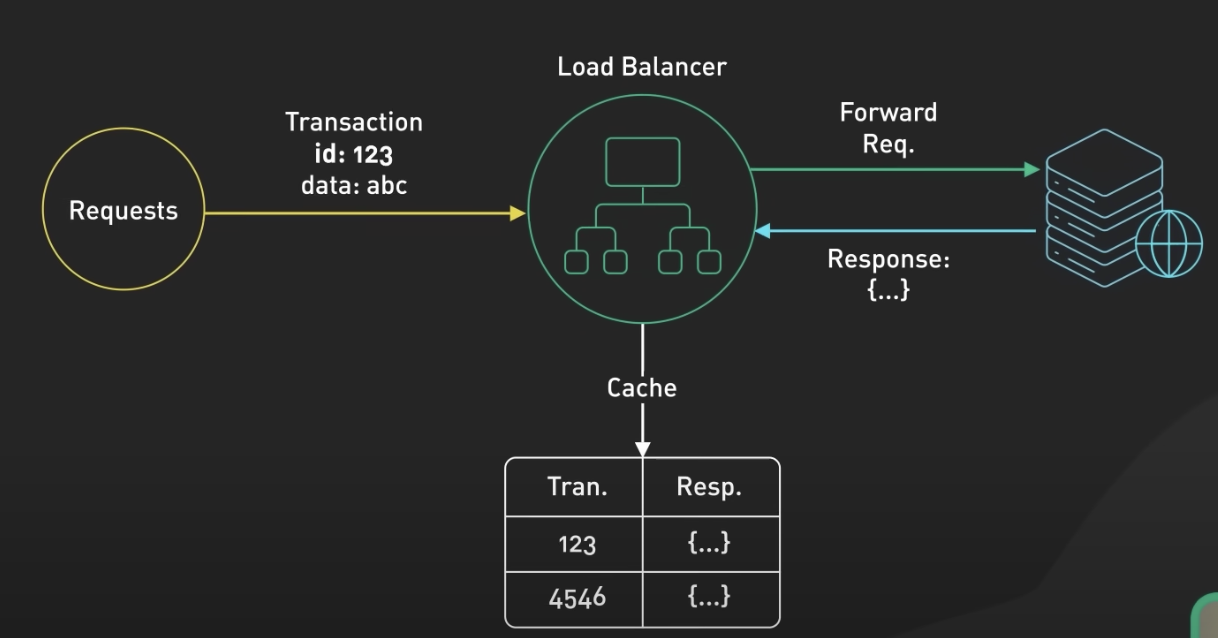
- 로드 밸런서는 클라이언트 요청을 받으면, 해당 요청에 대한 캐시를 확인합니다. 캐시에 해당 요청에 대한 응답이 존재하면, 로드 밸런서는 웹 서버로 요청을 전달하지 않고 캐시된 응답을 클라이언트에게 바로 전송합니다. 이렇게 함으로써 웹 서버에 대한 부하를 줄이고 빠른 응답을 제공합니다.
4) Kafka Broker
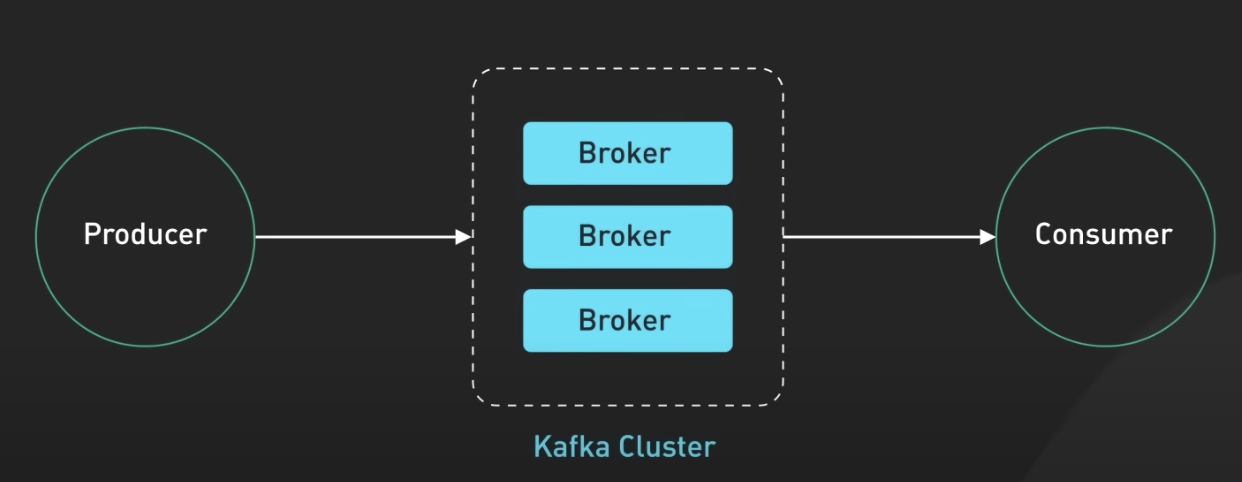
브로커는 디스크에 있는 모든 메시지를 메모리에 캐시하지 않습니다. 대신 최근에 생성된 메시지나 클라이언트로부터 빈번하게 요청되는 메시지들을 메모리에 캐싱합니다.
이렇게 메모리에 캐시된 메시지들은 디스크보다 훨씬 빠른 액세스 속도를 가지기 때문에, 컨슈머가 해당 메시지를 요청했을 때 브로커는 메모리에서 빠르게 읽어서 제공할 수 있습니다.
5) Distributed cache
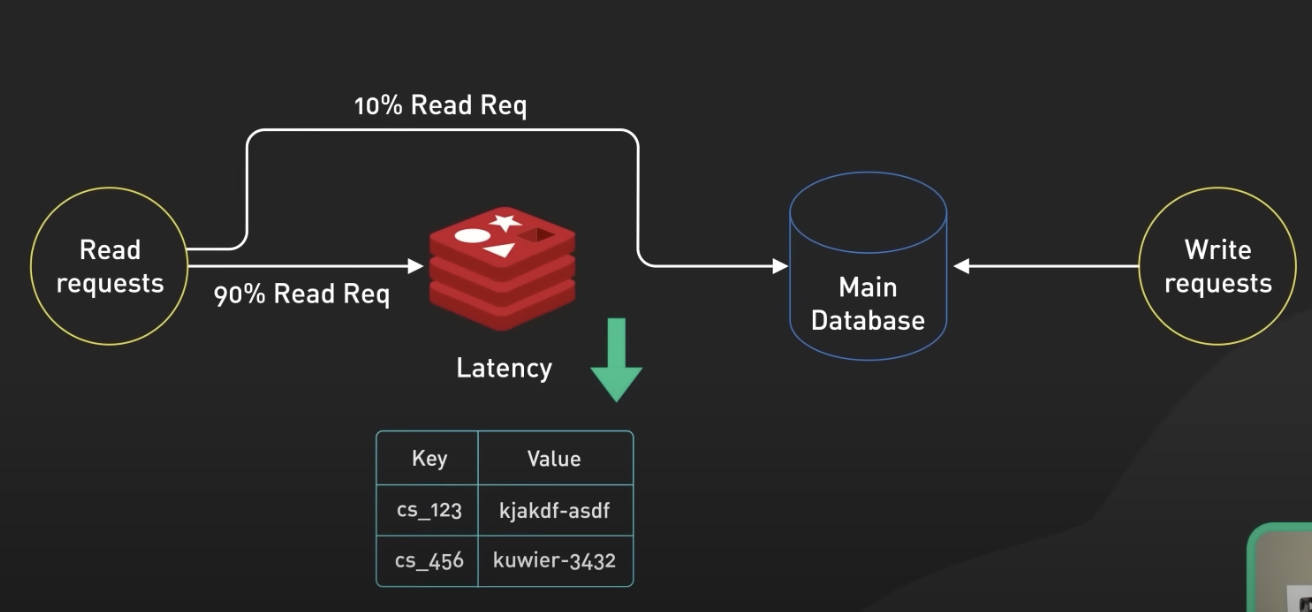
(1) 캐시 데이터 저장
애플리케이션에서 캐시하고자 하는 데이터를 Redis에 저장합니다. 이때 Redis는 "Key-Value" 형태로 데이터를 저장합니다. 데이터를 가져오기 쉽도록 적절한 Key를 정하고, 이를 Redis에 저장합니다.
(2) 캐시 데이터 조회
데이터를 요청하는 클라이언트는 먼저 Redis에 해당 데이터가 캐시되어 있는지 확인합니다. 만약 캐시에 데이터가 있다면, Redis에서 바로 데이터를 반환합니다.
(3) 캐시 데이터 갱신
데이터가 변경되거나 만료되는 경우, Redis에 저장된 캐시 데이터를 갱신합니다. 데이터 갱신은 필요에 따라 주기적으로 또는 이벤트 기반으로 수행할 수 있습니다.
(4) 데이터 만료
Redis는 데이터의 TTL(Time-To-Live)을 설정할 수 있습니다. 데이터를 캐싱할 때 TTL을 지정하면, 데이터가 일정 시간 후에 자동으로 만료됩니다. 만료된 데이터는 Redis에서 자동으로 제거됩니다.
(5) 분산 환경 지원
Redis는 단일 노드로 동작하는 것뿐만 아니라 분산 환경을 지원합니다. 여러 개의 Redis 노드를 클러스터로 구성하여 데이터를 분산 저장할 수 있습니다. 이를 통해 더 높은 확장성과 성능을 제공할 수 있습니다.
Redis 클러스터는 데이터의 고가용성을 보장하기 위해 마스터 노드와 해당 마스터 노드에 속하는 슬레이브 노드를 관리합니다. 마스터 노드에 저장된 데이터는 해당 마스터 노드의 모든 슬레이브 노드로 복제되어 데이터의 가용성을 확보합니다.
따라서, Redis 클러스터에서 마스터 노드에 장애가 발생하면 해당 마스터 노드의 슬레이브 노드 중 하나가 새로운 마스터로 승격됩니다. 이 새로운 마스터 노드는 기존 마스터 노드의 데이터를 가지고 있으며, 장애가 발생하기 전까지의 데이터를 복제하여 가지고 있기 때문에 데이터의 손실 없이 작동할 수 있습니다.
따라서 장애가 발생하더라도 데이터를 보존하고 새로운 마스터 노드로 자동 승격함으로써 시스템이 계속해서 안정적으로 동작할 수 있습니다.
4. 데이터베이스
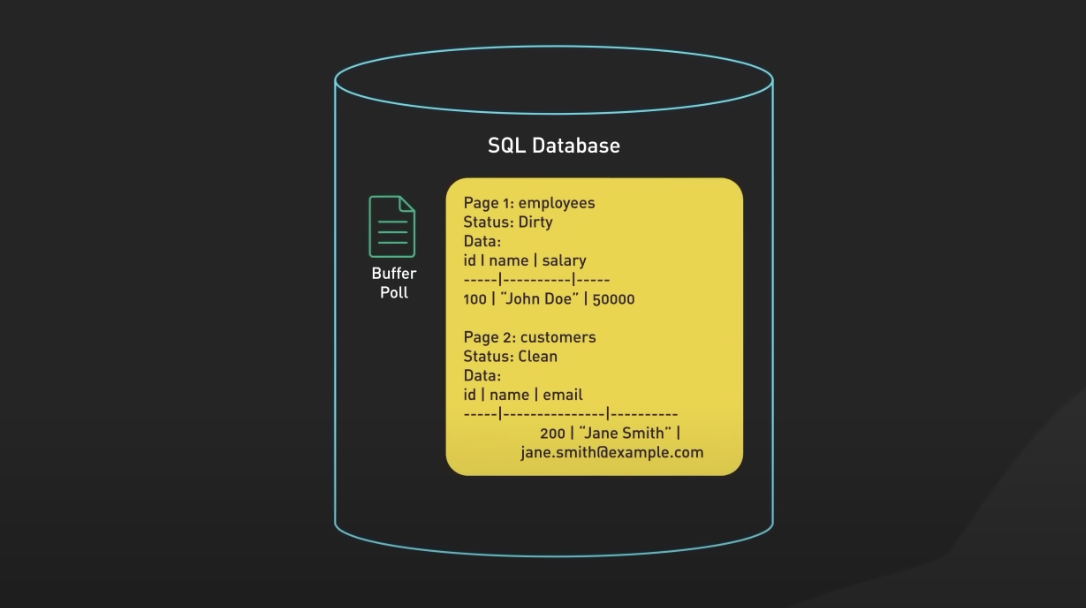
-
Buffer Pool은 데이터베이스에서 캐싱 기능을 제공하는 중요한 요소입니다. 데이터베이스 시스템은 디스크와 같은 느린 저장소보다 빠른 메모리에 데이터를 보관하여 데이터 액세스 성능을 향상시키는데 사용됩니다.
-
Buffer Pool은 데이터베이스의 주 메모리 영역으로서, 일정 크기의 메모리를 할당 받습니다. 이 메모리 영역은 디스크로부터 읽은 데이터를 임시로 저장하는 역할을 합니다. 데이터베이스는 액세스가 빈번한 데이터나 쿼리 결과를 메모리에 캐시하고, 캐시된 데이터를 효율적으로 활용하여 디스크 I/O를 최소화합니다. Buffer Pool은 LRU (Least Recently Used) 또는 다른 대안적인 캐시 알고리즘을 사용하여 메모리에서 가장 최근에 사용되지 않은 데이터를 제거하고 새로운 데이터를 적재합니다.
-
결론적으로, 데이터베이스는 빈번하게 요청되는 데이터나 인덱스를 Buffer Pool에 캐시하여 쿼리의 응답 시간을 크게 단축시킵니다. 또한, Buffer Pool은 동시성 제어를 위한 잠금과 같은 메모리에서 수행되는 작업을 통해 디스크 I/O를 줄여 시스템의 처리량을 향상시킵니다.
참고) https://blog.bytebytego.com/p/ep54-cache-systems-every-developer

좋은 글 감사합니다. 자주 올게요 :)