1. Sequential I/O

Sequential I/O는 디스크에 연속적으로 데이터를 쓰고 읽는 방식을 의미합니다. 여기서 디스크의 입출력(I/O) 작업은 디스크에 데이터를 저장하거나 읽어오는 작업을 말합니다.
1) 데이터 쓰기(Write)
일반적인 데이터베이스 시스템은 임의적으로 데이터를 저장하거나 업데이트하는 작업을 수행합니다. 이는 하드 디스크에서 데이터를 찾는 데 추가적인 시간이 소요되므로 상대적으로 느립니다. 반면 Kafka는 데이터를 순차적으로(시간 순서대로) 디스크에 기록합니다.
예를 들어, A, B, C, D, E라는 다섯 개의 메시지가 Kafka에 순차적으로 도착한다고 가정해 보겠습니다. Kafka는 이 메시지를 디스크에 순차적으로 기록합니다. 따라서 저장되는 순서는 A, B, C, D, E가 됩니다.
반면 데이터베이스 시스템은 동일한 메시지를 임의적으로 저장할 수 있습니다. 예를 들어 A, B, D, C, E 순으로 저장될 수 있습니다. 이렇게 되면 디스크에서 데이터를 찾는 작업이 더 복잡해지고 느려질 수 있습니다.
2) 데이터 읽기(Read)
Kafka의 Sequential I/O는 데이터를 디스크에서 연속적으로 읽을 수 있도록 합니다. 따라서 데이터를 읽는 과정에서 디스크 헤더를 이동할 필요가 없어지며, 데이터를 빠르게 읽을 수 있습니다.
예를 들어, 위에서 저장된 데이터를 순차적으로 읽는다고 가정해 보겠습니다. Kafka는 A부터 E까지 순차적으로 데이터를 읽습니다. 이 경우 디스크 헤더는 한 번만 이동하면 되므로 빠르게 데이터를 읽을 수 있습니다.
[디스크 헤더 이동 최소화]
Sequential I/O를 사용하면 디스크 헤더의 이동 횟수를 최소화할 수 있습니다. 디스크 헤더의 이동은 I/O 작업에서 시간 소요가 가장 많이 발생하는 부분 중 하나입니다. 순차적으로 데이터를 읽거나 쓰면 디스크 헤더는 한 번 이동한 후에 연속된 데이터 블록을 순차적으로 처리할 수 있으므로 효율적입니다.
그러나 데이터베이스 시스템은 데이터를 임의적으로 저장했기 때문에 A부터 E까지 순차적으로 읽는 것이 아니라, 필요한 데이터를 찾기 위해 여러 번 디스크 헤더를 이동해야 합니다. 이로 인해 데이터 읽기 속도가 느려질 수 있습니다.
3) Sequential Access vs. Random Access (순차 접근 대 랜덤 접근)

Sequential Access: 데이터를 순서대로 연속적으로 접근합니다. 이전 데이터 블록을 모두 읽은 후에 다음 데이터 블록으로 이동합니다. 따라서 순차 접근은 연속적인 데이터에 대해 빠르고 효율적인 방식입니다.
Random Access: 데이터에 랜덤하게 접근합니다. 즉, 데이터를 읽기 위해 데이터의 물리적인 위치를 직접 지정하여 해당 위치로 이동합니다. 랜덤 접근은 순차 접근보다 느릴 수 있습니다. 하지만 특정 데이터에 직접 접근해야 할 때 유용합니다.
Sequential Access의 장점:
- 데이터를 순차적으로 읽거나 쓸 때 높은 효율을 보여줍니다.
- 디스크 헤더의 이동 횟수를 최소화하여 성능을 향상시킵니다.
- 대용량 데이터를 처리할 때 빠른 데이터 접근 속도를 제공합니다.
- 데이터 스트리밍과 로그 처리 시스템 등의 용도에 적합합니다.
Sequential Access의 단점:
- 특정 데이터에 빠르게 접근해야 하는 경우에는 랜덤 접근보다 느릴 수 있습니다.
- 데이터가 연속적으로 저장되지 않는 경우(간격이 크거나 분산된 경우)에는 효율이 감소할 수 있습니다.
요약하면, Kafka는 데이터 스트리밍 플랫폼으로, 대량의 데이터를 실시간으로 처리하고 전송할 때 Sequential I/O를 통해 높은 처리량(high throughput)을 달성할 수 있습니다.
2. ZERO COPY

KAFKA의 메시지는 다양한 Target으로 Consume됩니다. 이 과정에서 데이터는 디스크에서부터 어떻게 쓰고, 읽고 네트워크로 전송되는지 알아보겠습니다.
1) ZERO COPY를 적용하지 않을 경우
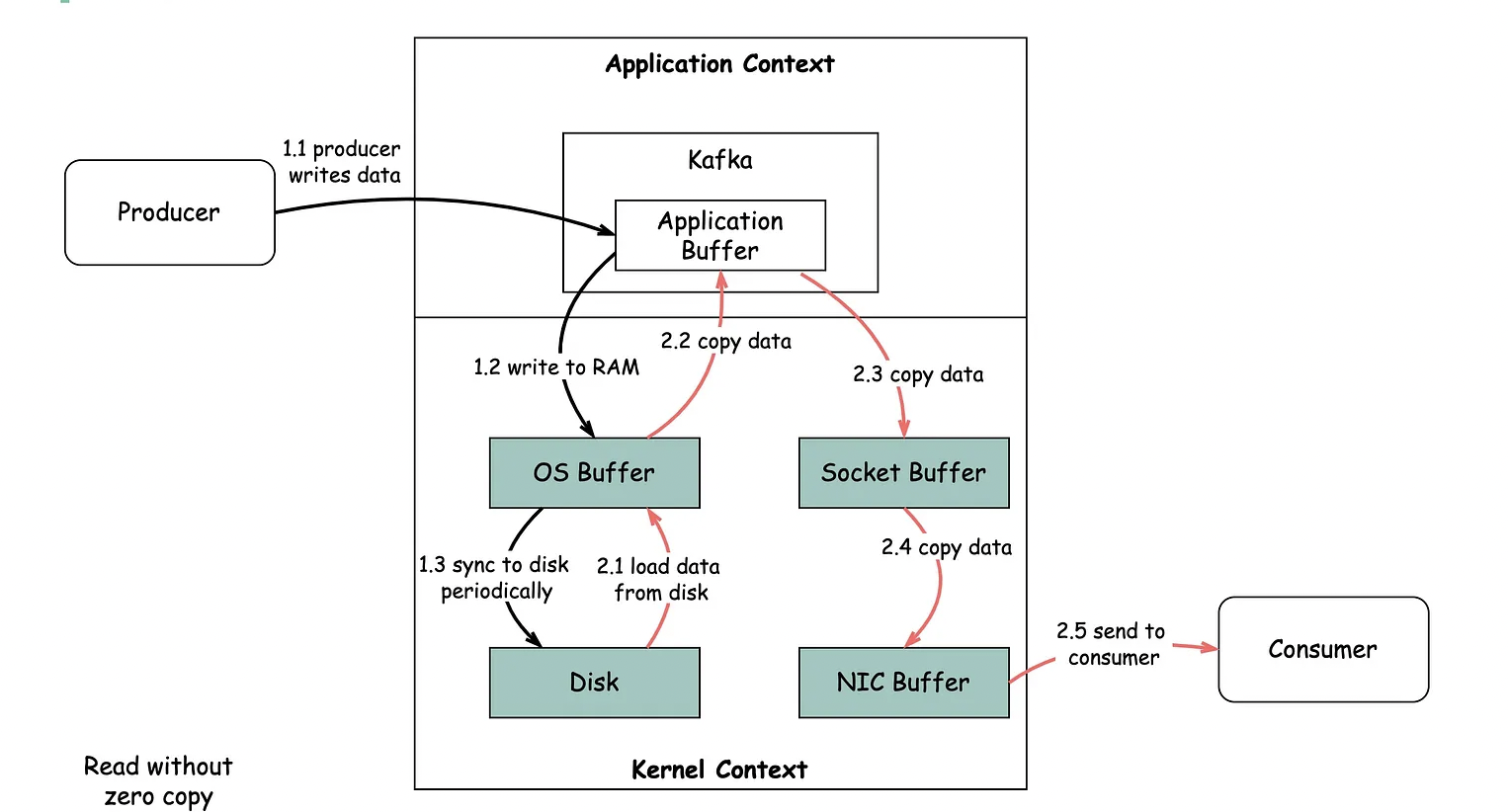
(1) OS Buffer
OS 버퍼는 운영체제가 데이터를 임시로 보유하고 관리하는 메모리 영역입니다. 이 단계에서도 데이터는 여전히 메모리 상에 존재하며, 디스크에는 아직 기록되지 않았습니다.
(2) 디스크로의 Flush
브로커의 OS 버퍼는 주기적으로 혹은 설정된 기준에 따라 디스크로 Flush(기록) 됩니다. 이때 OS 버퍼의 데이터가 디스크의 영구 저장소에 기록되게 됩니다.
(3) 디스크에서 OS Buffer로 데이터 로드
디스크에 저장된 데이터는 운영체제(OS)의 Buffer로 로드됩니다. 이 단계에서 디스크에서 OS Buffer로 데이터를 복사하는 작업이 수행됩니다.
(4) OS Buffer에서 Application Buffer로 데이터 복사
OS Buffer에서 애플리케이션 Buffer(애플리케이션 메모리)로 복사합니다. 이는 데이터를 애플리케이션 메모리로 가져와서 애플리케이션에서 처리할 수 있도록 하는 작업입니다.
(5) Application Buffer에서 Socket Buffer로 데이터 복사
Kafka 브로커로부터 읽은 데이터를 네트워크 소켓을 통해 송신하기 위해 Socket Buffer로 데이터를 복사합니다. 이는 데이터를 네트워크 소켓에 전송할 준비를 하는 작업입니다.
(6) Socket Buffer에서 NIC Buffer로 데이터 복사
Socket Buffer에 있는 데이터를 네트워크 인터페이스 컨트롤러(NIC)의 Buffer로 복사합니다. 이 단계에서는 데이터를 네트워크로 전송하기 위한 준비를 하는 작업입니다.
(7) NIC Buffer에서 컨슈머로 데이터 전송
NIC Buffer에 있는 데이터는 네트워크 인터페이스를 통해 컨슈머로 전송됩니다. 이를 통해 컨슈머는 데이터를 수신하고 처리할 수 있게 됩니다.
위의 과정을 통해 디스크에 저장된 데이터를 읽어와서 애플리케이션 메모리로 가져오고, 이후 네트워크를 통해 데이터를 송수신하게 됩니다. 이러한 단계에서 데이터가 여러 번 복사되기 때문에 Zero-copy 기술을 사용하면 데이터를 효율적으로 처리하고 전송 속도를 향상시킬 수 있습니다. Zero-copy는 중간 단계의 데이터 복사를 최소화하여 빠른 데이터 처리를 지원하는 기술입니다.
2) ZERO COPY를 적용할 경우
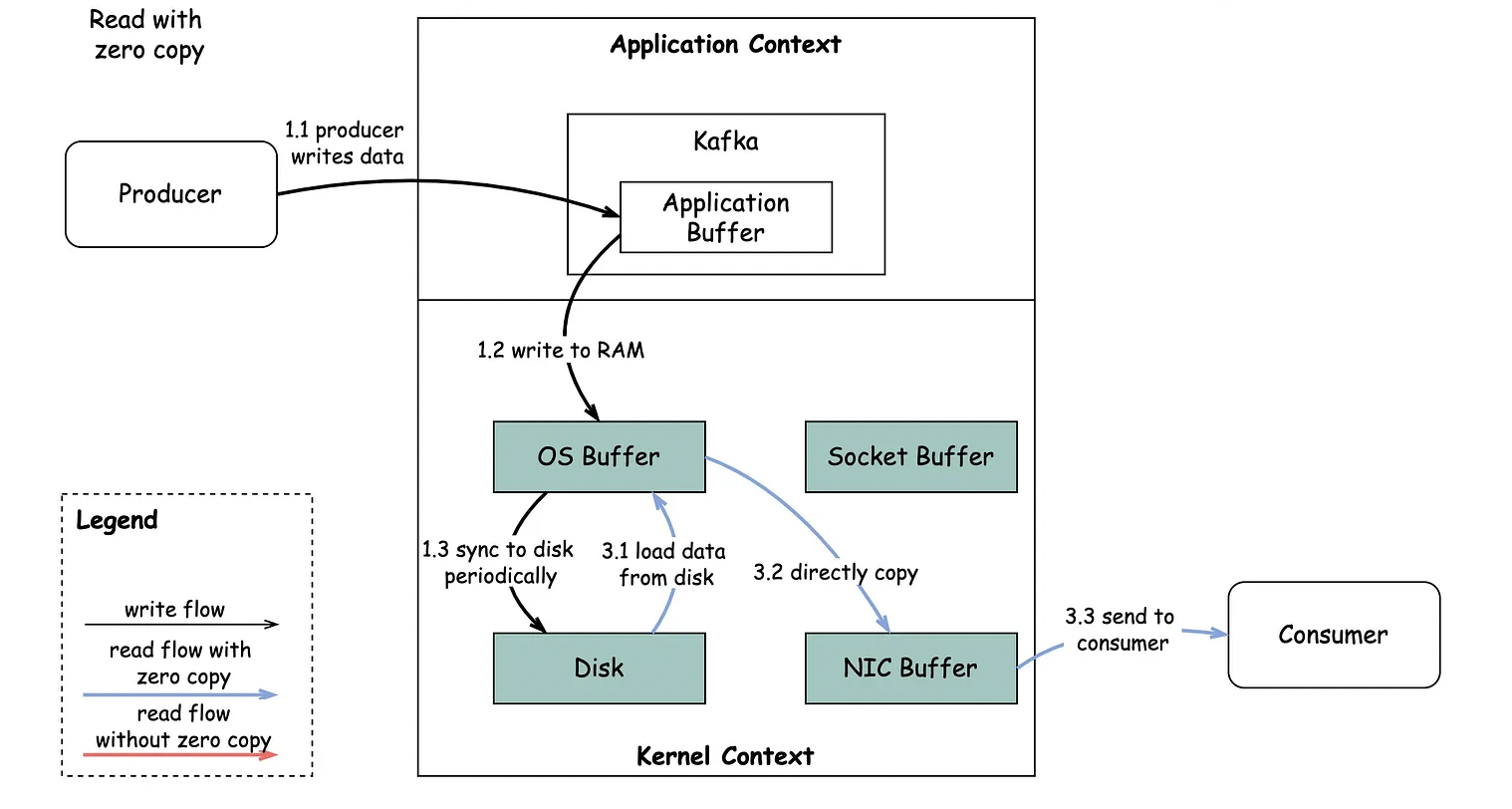
(1) 디스크에서 OS Buffer로 데이터 로드
디스크에 저장된 데이터는 운영체제(OS)의 Buffer로 로드됩니다. 이 단계에서 디스크에서 OS Buffer로 데이터를 복사하는 작업이 수행됩니다.
(2) OS Buffer에서 NIC Buffer로 직접 데이터 복사
"sendfile" 시스템 호출을 통해 데이터를 바로 NIC(Network Interface Card) Buffer로 복사하는 방식입니다. Zero-copy를 적용할 때, "sendfile" 시스템 호출을 사용하여 디스크에서 NIC Buffer로 데이터를 직접 복사하는 것이 특징입니다.
이를 통해 디스크에 저장된 데이터를 커널을 거치지 않고 직접 NIC Buffer로 전송할 수 있습니다. 이러한 방식은 데이터의 중간 복사 단계를 제거하여 데이터 전송 속도를 향상시키는데 기여합니다.
DMA (Direct Memory Access)는 Zero-copy 기술과 관련된 중요한 개념입니다. DMA는 하드웨어 기능으로서, 주변 장치들이 시스템 메모리에 직접 데이터를 전송할 수 있는 기능을 의미합니다. DMA를 사용하면 CPU가 직접 데이터 전송을 처리하지 않고, 주변 장치(예: 네트워크 컨트롤러, 디스크 컨트롤러 등)가 직접 시스템 메모리에 데이터를 쓰거나 읽을 수 있습니다. 이는 데이터를 메모리에 복사하는 오버헤드를 줄여주고, CPU의 부담을 줄여 더 높은 처리량과 성능을 달성하는데 도움이 됩니다. 따라서 DMA는 Zero-copy 기술의 핵심 요소 중 하나이며, 두 기술을 함께 사용하여 데이터 전송의 효율성과 성능을 극대화합니다. Kafka와 같은 데이터 스트리밍 시스템에서도 DMA와 Zero-copy를 활용하여 높은 처리량과 성능을 달성하는데 기여합니다.
요약하면, Zero-copy를 적용할 경우 데이터를 디스크에서 OS Buffer로 로드하고, sendfile 시스템 호출을 통해 바로 NIC Buffer로 복사하여 컨슈머로 데이터를 전송합니다. 이는 중간의 데이터 복사를 피하고 빠른 데이터 처리를 가능케 합니다.
