Recent CNNs
ResNet
기존 딥러닝의 문제점

- Gradient Vanishing 문제 발생
- Layer가 깊어지면 Backpropagation 과정에서 Gradient을 계산할때 Chain-rule에 의해서 편미분한 미분값들의 곱을 사용
- 이때 미분값들의 크기가 0보다 작으므로, layer가 Deep 해질수록 신호의 전달 감소.
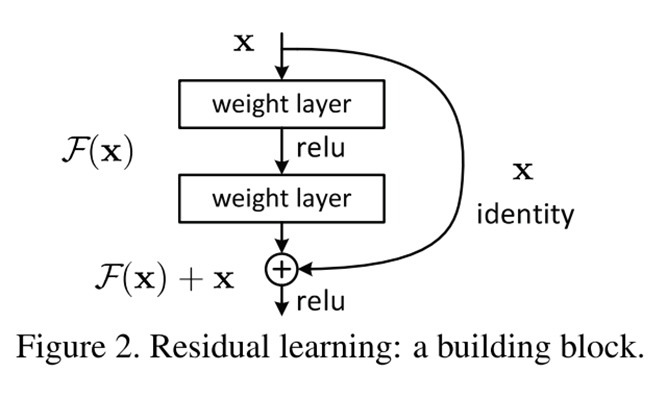
Residual Learning
- 입력의 크기를 거의 그대로 만들어주기 위해서 새로운 장치를 도임 (Shortcut connection)
- shortcut을 도입하여 Backpropagation 과정에서 Gradient를 계산해도 1이상의 값이 포함되어 신호의 전달 감소 해결.
Lightweight Networks
- 2017년도부터 구글에서 Mobile을 위한 경량화 합성곱 신경망 모델을 만들기 위해 노력함.
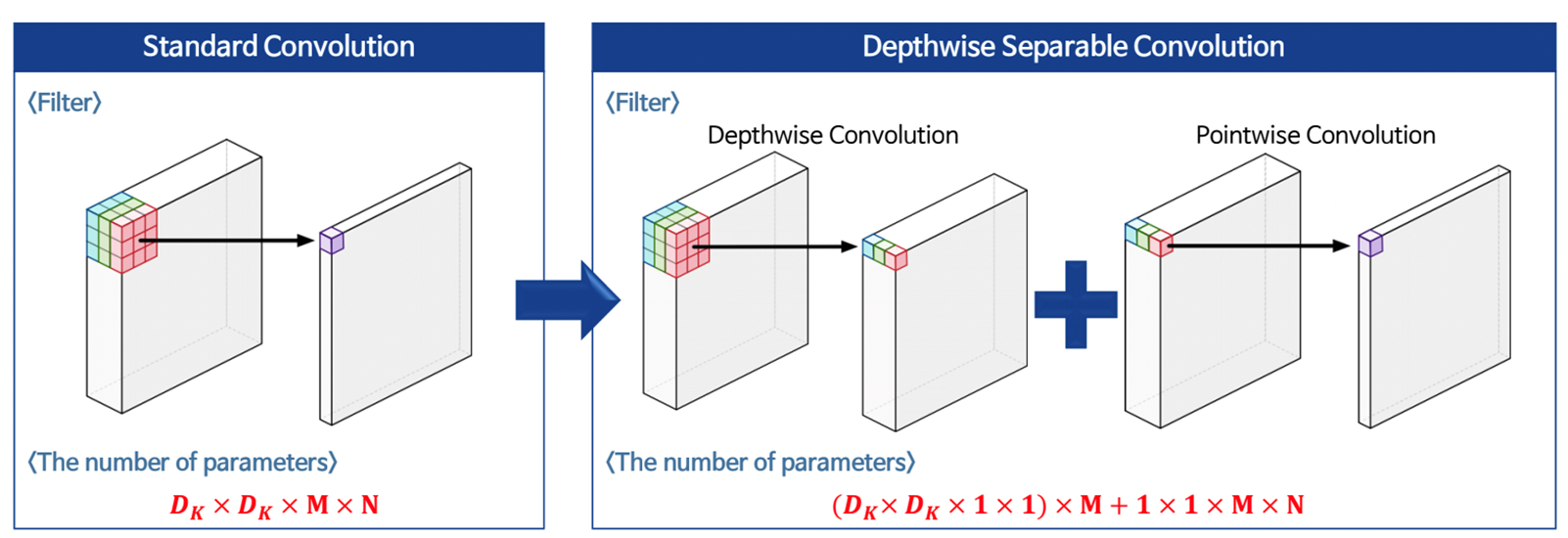
- 기존 Convolution의 경우 으로 필터 사이즈와 input 채널, output 채널의 곱으로 나타냄
- Depthwise Separable Convolution의 경우 Depthwise Convolution과 Pointwise Convolution으로 나누어 계산
- Depthwise Convoution의 경우 각 채널별로 filter를 이용해 Convolution, Pointwise Convolution의 경우 채널끼리 연산
MobileNet
- Depthwise Separable Convolution을 기존의 ResNet의 BottleNeck 구조를 대신하여 대체
- 성능을 거의 유지하면서도 파라미터 수를 기하급수적으로 줄임
- 효율 = 저장공간(memory) + FLOPs(연산량)

- ReLU를 ReLU6로 대체하여 성능 향상
- signal 측면에서 과도한 scale의 증폭은 악영향을 끼침
- 비슷한 scale 레벨에서 학습을 하는 것이 성능 측면에서 좋음

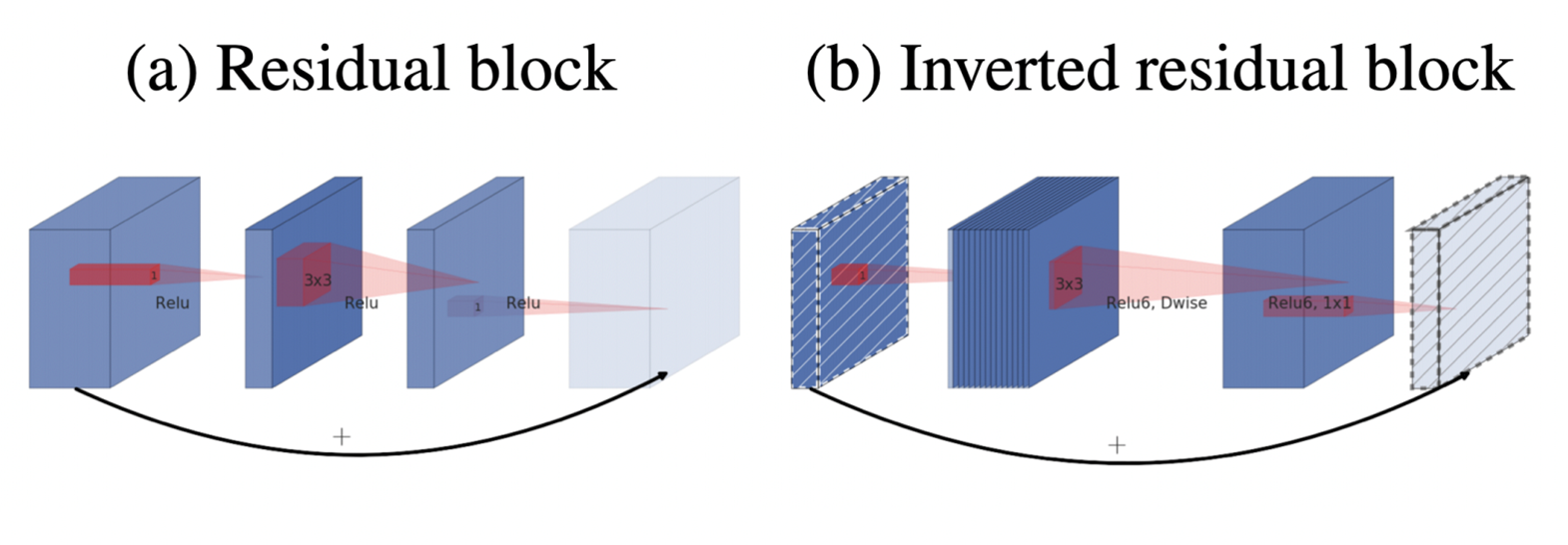
- Residual의 shortcut의 위치를 바꿔주어서 성능 향상 (Inverted Residual)
- 채널 수를 줄였다 늘리는 형태에서 늘렸다 줄이는 형태로 변환

EfficientNet
- 모델의 경량화를 Width(각 layer의 채널 수), Depth(층의 개수), resolution(입력 이미지의 크기)를 비교하여 상관관계를 분석.
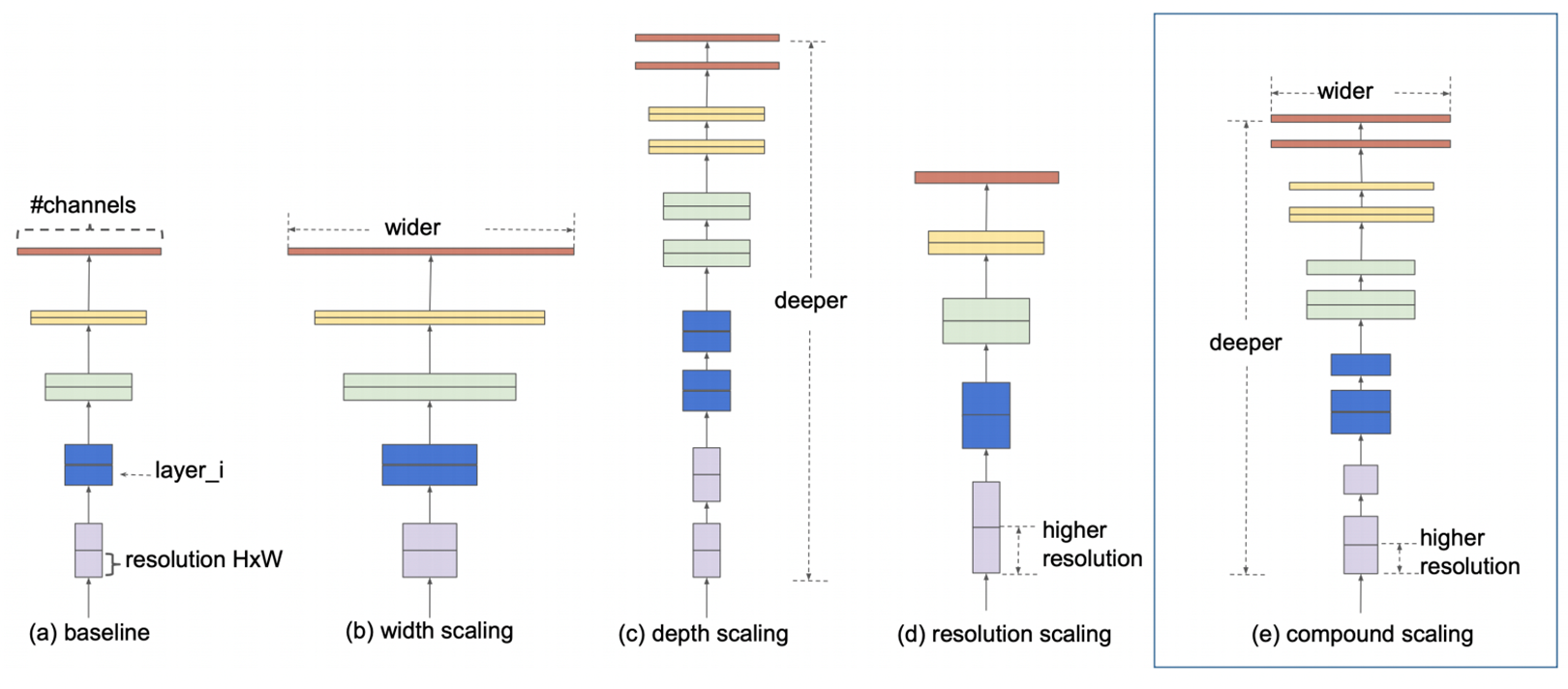
- 실험적으로 Width, Depth, Resolution에 곱해주는 값이 일정할지 어떻게 크기를 조절할지 명시
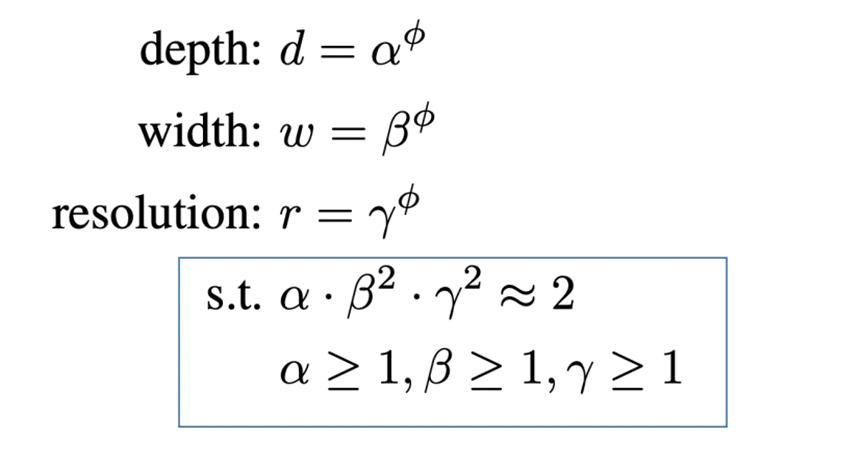
Conclusion
- Trade-off가 있다!
- 파라미터 수가 많다 => 성능 , 연산속도 , 저장공간 차지
- 파라미터 수가 적다 => 성능 , 연산속도 , 저장공간 차지

Sometimes You gotta run before you can walk.