머신러닝 모델은 일반적으로 회귀와 분류에 따라 다른 평가 지표를 사용한다. 회귀의 경우 MAE, MSE, RMSE 등을 사용하지만, 분류의 경우는 다르다. 오늘은 분류 모델의 평가 지표에 대해 알아보겠다.
Confusion Matrix
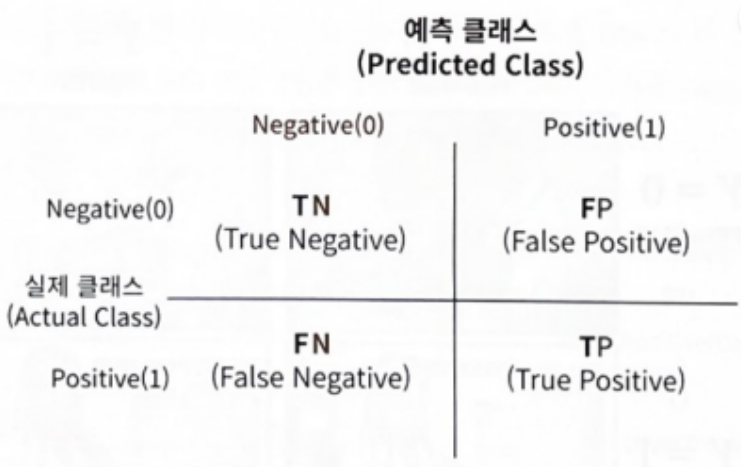
분류 모델의 성능을 평가하는 기본적인 방법은 원하는 대상 A를 제대로 예측한 경우와 그렇지 못한 경우가 얼마나 있는지 세어보는 것이다. 이를 확인하기 위해 만들어진 것을 Confusion Matrix, 혼동 행렬이라 부른다. Confusion Matrix 를 그림으로 나타내면 다음과 같다.
# Confusion Matrix 코드
from sklearn.metrics import confusion_matrix
pred = lr_clf.predict(x_test)
confusion_matrix(y_test, pred)Confusion Matrix 결과
TN FP
FN TP 순으로 출력
TN : True Negative
( T : 예측 클래스와 실제 클래스 값이 같음
N : 예측값이 Negative)
뒤에 나오는 값을 우리가 만든 모델이 예측한 값을 나타내며, 앞에 나오는 값은 예측한 값이 실제 값과 같은 지를 나타낸다.
-
어떤 값을 1로, 어떤 값을 0으로 설정?
일반적으로, Positive (1) 는 우리가 관심있어 하는 매우 적은 소수의 집단을 뜻한다. 그렇지 않은 경우를 Negative (0) 로 설정하는 경우가 많다.
예를 들어, 사기 행위를 Positive (1) , 정상 행위를 Negative (0) 으로 설정하는 것이다. -
Accuracy (정확도)
-
예측 결과가 동일한 데이터 수 / 전체 예측 데이터 수
-
분류 모델이 얼마나 정확하게 분류했는지 평가하는 지표
정확도를 Confusion Matrix에서의 수식으로 나타내면 다음과 같다.
# 정확도 코드 from sklearn.metrics import accuracy_score pred = lr_clf.predict(x_test) accuracy_score(y_test, pred)그런데, 정확도가 높다고 해당 모델이 좋은 모델이라 할 수 있을까? 정답은 "아니오"다.
만약, 99개의 label 0, 1개의 label 1이 존재한다면, 무조건 0으로 예측 결과를 반환하는 모델도 정확도가 99%이다. 이는, 정확한 지표라 할 수 없다.
즉, accuracy는 불균형한 label 분포에서 판단할 경우, 적합한 평가 지표가 아니다. 따라서, 이를 극복하기 위해 여러 분류 지표와 함께 모델의 성능을 평가해야 한다. -
-
Recall (재현율)
-
실제 Positive 중, 모델의 예측과 실제값이 Positive로 일치한 데이터 비율
-
Sensitivity (민감도) 라고도 불림.
-
만약 어떠한 병에 실제로 걸렸을 때, 기기가 그 병에 걸렸다고 분류하는 경우를 뜻함
재현율을 Confusion Matrix에서의 수식으로 나타내면 다음과 같다.
# Recall 코드 from sklearn.metrics import recall_score pred = lr_clf.predict(x_test) recall_score(y_test, pred) -
-
Precision (정밀도)
-
예측을 Positive로 한 대상 중, 예측과 실제 값이 Positive로 일치한 데이터 비율
-
기기가 병에 걸렸다고 분류한 사람 중, 실제 그 병에 걸린 사람의 비율
정밀도를 Confusion Matrix에서의 수식으로 나타내면 다음과 같다.
# Precision 코드 from sklearn.metrics import precision_score pred = lr_clf.predict(x_test) precision_score(y_test, pred) -
-
언제 Recall, 언제 Precision? Confusion Matrix 수식 참고
- Recall 이 중요 지표인 경우 : 실제 Positive 데이터를 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 (recall은 FN을 낮추는데 초점이므로)
- ex) 당뇨병 판단 모델 실제 positive인 당뇨병 환자를 negative로 잘못 판단하면, 심각한 문제를 초래함
- ex) 금융 사기 적발 모델 실제 금융거래 사기인 positive를 negative로 잘못 판단하면 심각한 문제를 초래함
-
Precision 이 중요 지표인 경우 : 실제 Negative 데이터를 Positive로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 (precision은 FP를 낮추는데 초점이므로)
- ex) 스팸메일 여부 판단 모델 실제 positive인 스팸 메일을 negative인 일반 메일로 분류하더라도 사용자가 불편함을 느끼는 정도지만, 실제 negative인 일반 메일을 positive인 스팸 메일로 분류할 경우 중요한 메일을 받지 못하게 됨
-
Recall 은 실제 Positive 중, Positive로 예측하여 맞춘 비율이므로, 실제 positve 데이터를 Negative로 잘못 판단하면 심각한 문제를 초래하는 것은 맞음
그런데, 왜 Precision 은 실제 Negative를 Positive로 잘못 판단하면 심각할 때 중요한 수치인지? 이는 특이도 (Specificity)를 나타내는게 아닌지?
실제 Negative를 Positive로 잘못 판단하는 것을 의미하는 FP가 Precision을 구하는 식에 들어가 있음. Negative 데이터를 Positive로 잘못 판단하면 큰일나는 경우, 해당 상황을 방지하려면 FP를 줄여야함. 즉, FP가 작아져야 하고, 이는 Precision의 상승을 뜻함. 따라서, Precision이 상대적으로 중요함.
반대로, Positive를 Negative로 잘못 판단하는 것을 의미하는 FN이 Recall을 구하는 식에 들어가 있음. 따라서, 이 상황에서는 Recall이 상대적으로 중요함.
- Recall 이 중요 지표인 경우 : 실제 Positive 데이터를 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 (recall은 FN을 낮추는데 초점이므로)
-
Recall & Precision trade-off
-
Recall 과 Precision 은 서로 trade-off 관계에 있음
-
threshold 설정으로 recall 혹은 precision 값을 조정해줄 수 있음
-
그러나, recall와 precision은 trade-off 관계에 있기 때문에, 섣불리 threshold를 조정하는 것은 위험할 수 있음
threshold 조정을 통해 recall, precision 값을 조정하는 코드는 다음과 같다.
-
-
label 예측값을 바로 뽑는 것이 아닌, 해당 label로 예측할 확률을 뽑아냄
lr_clf = LogisticRegression(solver = 'liblinear')
lr_clf.fit(x_train, y_train)
# test 데이터 중 X 데이터만 사용
pred_proba = lr_clf.predict_proba(x_test)
print(pred_proba[:3])첫번째 컬럼이 0, 두번째 컬럼이 1로 예측할 확률
[[0.44935226 0.55064774]
[0.86335512 0.13664488]
[0.86429644 0.13570356]]
default threshold : 0.5 확률이 0.5보다 큰 값으로 label 선정
위에서 뽑은 label 별 확률값을 이용 ( Binarizer 확인 )
from sklearn.preprocessing import Binarizer
# Binarizer의 threshold 설정값. 분류 결정 임계값
custom_threshold = 0.5 # 우선, default 값을 사용해 확인 진행
# predict_proba() 반환값의 두번째 칼럼
# 즉, Positive 클래스 칼럼 하나만 추출해 Binarizer를 적용
pred_proba_1 = pred_proba[:,1].reshape(-1,1)
binarizer = Binarizer(threshold = custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
print(confusion_matrix(y_test, custom_predict))threshold = 0.5 ( default ) 기존 predict( ) 로 계산된 지표값과 동일함
오차 행렬
TN FP
FN TP
[[108 10]
[14 47]]
정확도: 0.8659, 정밀도: 0.8246, 재현율: 0.7705
threshold = 0.4로 낮춤
# Binarizer의 threshold 설정값을 0.4로 설정
from sklearn.preprocessing import Binarizer
custom_threshold = 0.4
pred_proba_1 = pred_proba[:,1].reshape(-1,1)
binarizer = Binarizer(threshold = custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
print(counfision_matrix((y_test, custom_predict))threshold = 0.4
오차 행렬
TN FP
FN TP
[[97 21]
[11 50]]
정확도: 0.8212, 정밀도: 0.7042, 재현율: 0.8197
-
threshold를 낮추니 Recall 상승 , Precision 감소
-
threshold는 positive 예측값을 결정하는 확률의 기준 ,
-
확률이 0.5가 아닌 0.4부터 positive로 예측을 더 너그럽게 해줌
-
따라서, positive로 예측하는 것이 많아지고, negative로 예측하는 것이 줄어듦
FP 증가, FN 감소
Recall 증가, Precision 감소 -
어떤 threshold 를 써야할지 결정하는 방법?
모든 threshold 에 대해 하나씩 바꿔가면서 수치를 비교해야 한다.
데이터의 특성, 목적마다 어떤 수치를 중요하게 봐야 하는지 달라진다.
Recall & Precision 은 trade-off 관계에 있기 때문에, 특정 수치만 높이는 threshold 로 설정해서는 안 된다.
-
-
Recall을 100% 만드는 방법
-
모든 환자를 positive로 예측
-
recall = TP / ( TP + FN ) 전체 환자 1000명을 모두 positive로 예측한다면, 실제 positive인 환자가 30명이라 하면, FN = 0, TP = 30
-
따라서, recall = 30 / ( 30 + 0 ) = 100%
-
-
Preicsion을 100% 만드는 방법
-
확실한 경우에만 positive로 예측하고, 나머지를 모두 negative로 예측
-
precision = TP / ( TP + FP ) 전체 환자 중 정말 확실한 환자 1명만 positive로 예측
-
따라서, precision = 1 / ( 1 + 0 ) = 100%
-
-
F1 score
-
Recall, Precision을 결합한 지표
-
Recall, Precision이 어느 한쪽으로 치우치지 않는 수치일 때 높음
-
ex) A : recall = 0.9, precision = 0.1 F1 = 0.18
B : recall = 0.5, precision = 0.5 F1 = 0.5 -
F1 score의 수식은 다음과 같다.
# F1 score 코드 from sklearn.metrics import f1_score pred = lr_clf.predict(x_test) f1_score(y_test, pred) -
-
ROC CURVE
-
Binary Classification에 성능 측정에서 중요하게 사용되는 지표
-
X축 : FPR , Y축 : TPR
-
TPR = TP / ( TP + FN ) Recall
-
FPR = FP / ( FP + TN ) = 1 - specificity (특이도) = 1 - TN / ( TN + FP )
-
-
FPR을 0으로 만드려면, threshold를 1로 설정 ( 모두 Negative로 예측하여 FP = 0 이 되도록)
-
FPR을 1로 만드려면, threshold를 0으로 설정 ( 모두 Positive로 예측하여 TN = 0 이 되도록)
-
threshold를 1부터 0까지 변화시키면서, FPR 값의 변화에 따른 TPR 값을 구한 것
-
ROC CURVE를 시각화하는 코드는 다음과 같다.
-
def roc_curve_plot(y_test, pred_proba_c1):
# threshold에 따른 FPR, TPR 값 반환
fprs, tprs, threholds = roc_curve(y_test, pred_proba_c1)
# ROC곡선 그래프 그림
plt.plot(fprs, tprs, label = 'ROC')
# 가운데 대각선 직선을 그림
plt.plot([0,1], [0,1], 'k--', label = 'Random')
# FPR X축의 scale을 0.1 단위로 변경, X, Y축 이름 설정
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0,1); plt.ylim(0,1)
plt.xlabel('FPR (1 - Sensitivity)')
plt.ylabel('TPR (Recall)')
plt.title('ROC CURVE')
plt.legend()
lr_clf.train(x_train, y_train)
pred_proba = lr_clf.predict_proba(x_test)
roc_curve_plot(y_test, pred_proba[:,1]) 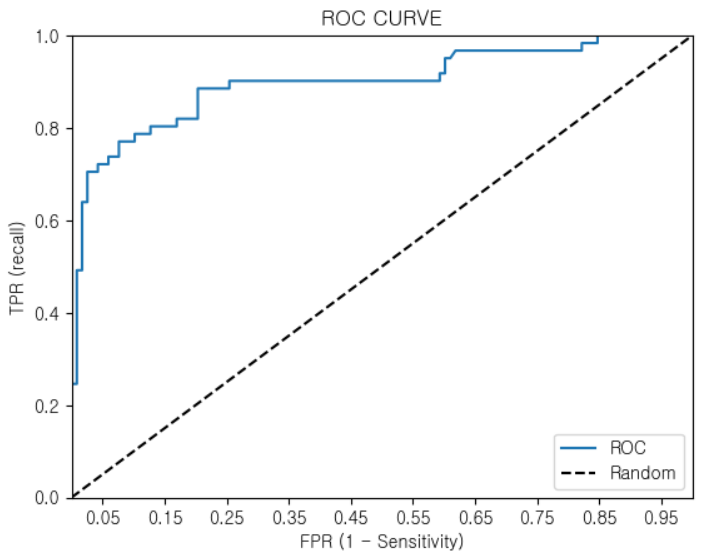
- 가운데 직선 : 동전을 무작위로 던져 앞/뒤를 맞추는 랜덤 수준의 이진 분류의 ROC CURVE ( AUC = 0.5 )
- ROC CURVE가 좌측 상단에 붙을수록 성능이 좋음
ROC CURVE의 밑면적을 AUC 라 한다. AUC는 성능 평가에 있어 수치적인 기준이 될 수 있는 값으로, 1에 가까울수록 좋은 모델이라 할 수 있다. ( ROC CURVE는 정확한 수치의 값을 제공하지 못하므로 AUC를 사용하면 객관적인 수치 확인 가능) AUC를 구하는 코드는 다음과 같다.
- Recall, Precision 등을 구하는 것과 다르게, predict_proba 를 사용한다.
from sklearn.metrics import roc_auc_score
pred_proba = lr_clf.predict_proba(x_test)[:,1]
roc_score = roc_auc_score(y_test, pred_proba)