
🚩 요약
아파치 스파크를 이용하여 머신러닝을 분산 처리할 때의 성능 요인을 분석하고 효율적인 분산 처리를 위한 실행 환경을 제시. 고려해야 하는 성능 요인으로 🟠 클러스터의 성능, 🟢 데이터의 규모, 🔵스파크 엔진의 속성으로 구분. 그리고 하둡 클러스터에서 동작하는 스파크 MLlib을 이용하여 회귀분석을 수행할 때 노드의 구성과 스파트 Executor의 설정을 변화하면서 성능을 측정. 실험 결과 최적의 Executor 개수는 데이터의 블록 수에 영향을 받으나, 클러스터 규모에 따라 최댓값, 최소값은 각각 코어의 수, 워커 노드의 수로 제한됨을 실증
🚩 서론
(생략)
🚩 아파치 스파크
아파치 스파크 성능과 관련한 연구는 A. Garate-Escamilla, A. Hassani, and E. Andres, “Big data scalability based on Spark Machine Learning Libraries,” In Proc. the 3rd International Conference on Big Data Research, Cergy-Pontoise, France, Nov. 2019, pp. 166-171 가 있었고, 랜덤 포레스트 알고리즘과 로지스틱 회귀분석 알고리즘을 캐시와 코어수를 변화하면서 성능을 비교, R. Myung, H. Yu, and S. Choi, “Performance Optimization Strategies for Fully Utilizing Apache Spark,” KIPS Trans. Computer and Communication Systems, vol. 7, no. 1, Jan. 2018, pp. 9-18. 에서는 스파크 내 파티셔닝 최적화 기법을 제시. But 하나의 가상 머신 또는 제한된 클러스터를 이용하였으므로 규모 확장성을 검증하는데에는 한계가 있음.
🚩 스파크의 분산 성능 요인
🟥 하드웨어
하드웨어는 워커 노드의 수, 코어의 수, 메모리 용량, 네트워크의 속도 등이 있음. 클러스터의 규모를 의미하는 워커 노드의 수는 노드 간 병렬화 수준을 결정하는 요소이며, 코어의 개수는 노드 내 병렬화 수준을 결정하는 요소. 이때 네트워크 속도는 노드의 수가 많아질수록 전체 처리 시간에 영향을 미침. 메모리 용량은 인-메모리 스파크를 이용한 머신러닝의 분산 처리 성능 요인. 메모리 용량은 인-메모리 처리를 수행하는 Executor의 성능에 직접적인 영향을 미치며 태스크 수행과정에서 메모리 용량이 부족한 경우 디스크 I/O가 추가로 발행하는 특징이 있음.
🟨 소프트웨어
소프트웨어 측면에서 사용자가 설정 가능한 분산 성능 요인은 Executor의 수(spark.executor.instances), Executor 메모리(spark.executor.memory) 및 코어 수(spark.executor.cores). Executor 메모리 및 코어 수는 하나의 Executor가 사용하는 메모리 용량 및 코어의 수를 의미함. 이때 Executor의 수는 응용 프로그램 실행 시 병렬 처리의 수준을 결정할 수 있으며, 메모리 용량 및 코어의 수는 하나의 노드에 한정되므로 하드웨어 사양에 의존적인 특징이 있음.
🟩 머신러닝
머신러닝과 같은 알고리즘은 저장소에서 데이터를 읽은 후에 이를 반복해서 계산하는 특징이 있는데 데이터의 I/O도 성능의 주요 요소가 됨. 하둡 분산 파일 시스템(HDFS)에서는 데이터의 배치 처리를 위해 블록 단위로 저장하고 이를 중복 계수(replication factor)에 따라 여러 노드에 나누어 저장. 분산 저장소를 활용하는 경우 데이터의 지역성(Data Locality)이 스파크의 처리 성능에 영향을 미침. 즉 데이터가 저장된 노드에서 연산 처리를 수행하는 것이 불필요한 네트워크 I/O를 줄일 수 있음.
🟦 정리
위 요인들을 종합해서 보면 분석 대상의 데이터 크기에 따라 최적화된 클러스터의 설정이 계산 가능. 데이터가 저장된 블록 개수를 B라고 하면 Executor의 개수(E) 는 B와 동일하게 설정할 때 데이터 접근을 동시에 이용할 수 있으므로 분산 처리가 최대화될 것으로 생각할 수 있음. 하지만 니는 데이터 지역성과 관련이 있는데 Executor가 특정 노드에 집중되는 경우 노드의 처리 부하가 발행하는 문제가 있음. 또한 클러스터 규모가 기 설정되어 있는 경우 최적의 E는 B와 코어 개수(C)에 영향을 받는다. E는 C를 Executor당 코어 수로 나눈 값이 동시 수행의 최대값으로 설정할 수 있는데 만일 B가 노드의 수(N)보다 작은 경우에는 불필요한 병렬화로 인한 네트워크 I/O가 발행할 수 있음. 최적의 클러스터 설정은 하드웨어, 소프트웨어, 데이터 측면에서의 변수들이 서로 영향을 미치므로 실험을 통해 변수들 간 관계를 검증하고자 함.
🚩 성능평가
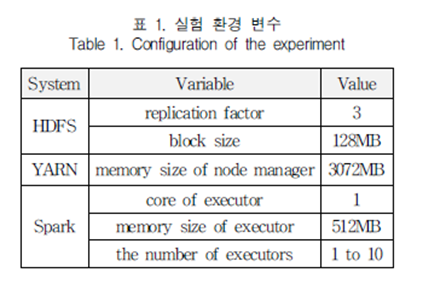
A. 실험 환경
분산 클러스터는 2코어 인텔 팬티엄 프로세서, 4GB 메모리와 500GB 하드디스크를 장착한 9대의 PC를 클러스터로 구성. 이 중 1대의 노드를 마스터 노드로 구성하고, 워커 노드는 분산 성능을 측정하기 위해 1대부터 8대까지 가변적으로 구성
분산 클러스터에서 머신러닝을 수행할 때 결정하는 주요 요인인 노드의 개수와 분산 노드 각각에서 job을 처리하는 프로세스 단위인 Executor의 개수가 변화할 때 발생하는 성능 변화를 분석. 데이터 셋 규모에 따른 비교를 위해 2GB, 1GB, 500MB로 구성했으며 각각의 데이터셋 블록 개수는 18개, 9개, 5개로 HDFS에 저장, LinearRegression 이용. 사전에 생성한 libsvm 포맷의 데이터를 로드하고 학습하는데까지 소요되는 시간을 측정. 성능 측정은 데이터셋에 대해 워커 노드 개수 및 Executor 개수를 달리하면서 5회씩 실행 후 평균 실행 시간을 측정
B. 실험 결과
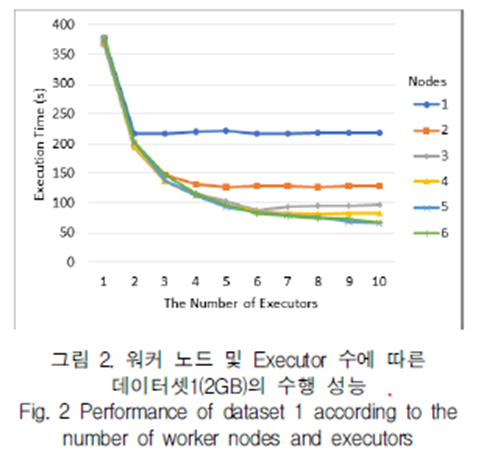
1. 워커 노드 및 Executor 수에 따른 데이터셋1(2GB)의 수행 성능
이 데이터셋은 18개의 데이터 블록을 가지고 있으므로 클러스터 규모를 6개의 노드로 확장하여도 코어 수가 12에 제한됨에 따라 블록수가 코어 수보다 항상 큰 특성이 있다. 처리 시간은 Executor수가 노드수와 같을 때까지 빠른 폭으로 감소하며 코어수와 올일해질때까지 지속적으로 감소하지만 코어수 보다 증가하면 시간이 소폭 증가함이 확인됨. 예를 들어 노드 수가 3개인 경우 Executor와 코어 수가 동일 할 때가 적정해 보임. 본 실험에서는 노드 수 6, Executor 10일 때 가장 높은 성능을 보였으나 5,10일 때와 큰 차이가 없음. 대신 노드 수가 6일때 Executor가 12까지 증가한다면 추가적인 성능 향상이 있을 것으로 기대
2. 워커 노드 및 Executor 수에 따른 데이터셋2(1GB)의 수행 성능
데이터 블록이 9개 일 때의 결과. 그림 2랑 비슷한 결과를 보임. 다만 노드 수가 5일 때 성능의 변화는 크지 않았는데 Executor와 블록수가 동일한 9일 때보다 10일 때 성능이 오히려 하락.즉 적정 Executor의 최대값은 코어 수보다 블록 수가 더 영향을 미친다는 것을 추정 가능

3. 워커 노드 및 Executor 수에 따른 데이터셋3(500MB)의 수행 성능
5개의 데이터 블록. 노드 수가 2일때 Executor가 4를 초가하면 오히려 성능이 떨어지는데, 이는 코어 수보다 많은 Executor로 인해 발생하는 Context 스위치 비용이 분산으로 인한 네트워크보다 더 높 아서 발생한 것으로 판단. 노드 수가 6인 경우는 노드 수가 블록 수 보다 많은 경우로서 Executor를 블록 수와 동일하게 설정할 때보다 노드 수와 블록 수를 동일하게 설정하였을 때 더 높은 성능을 보임.

4. 워커 노드 및 Executor 수에 따른 데이터셋(500MB)의 로딩시간 및 학습시간 비교
그림 5는 500MB 데이터셋에 대해 로딩시간 및 학습 시간을 나누어 표기한 그림이다. 노드 수가 2일 때 Executor 개수 2~4인 구간과 노드 수가 3일 때 Executor 개수가 3~6개인 구간에서 보는 바와 같이 Executor가 코어 수 만큼 증가하여도 로딩 시간에는 큰 차이는 없으나 학습시간이 줄어듦. 데이터셋 대비 클러스터의 규모가 매우 큰 경우 데이터 지역성으로 인한 네트워크 I/O가 예측하기 어려운 수준으로 증가한다고 함.
5. 정리
실험 결과를 정리해보면 머신러닝과 같이 CPU 자원을 많이 사용하는 응용 프로그램을 스파크에서 실행하는 경우 적정 Executor수는 클러스터의 노드 수와 코어 수(Executor당 코어가 1인 경우)이하 범위 내에서 데이터 블록의 개수만큼 지정하는 것이 효과적임을 확인 할 수 있음.
🚩 결론
스파크에서 병렬 분산 처리의 단위가 되는 Executor는 데이터셋의 블록 개수에 영향을 받는데, 클러스터 규모보다 데이터셋의 개수가 더 큰 경우에는 태스크 전환, 네트워크 I/O에 따른 오버헤드를 줄이기 위해 클러스터 전체 코어의 수를 넘지 않도록 제한하는 것이 필요. 클러스터의 규모가 충분히 큰 경우에는 노드의 개수만큼 Executor를 설정함으로써 병렬성을 최대화하는 것이 효과적. 또한 분석할 데이터셋의 크기가 고정된 경우에는 해당 데이터셋의 규모에 맞게 클러스터의 규모를 역으로 산정 가능.
