
다른 곳에서 자주 언급되는 여러 정보는 제외하고 논문에서 주장하는 바만 정리해서 적어봤음.
🚩Abstract
Wikipedia의 corpus(자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합)의 텍스트 features를 추출하기 위한 Apache Spark의 SQL APIs와 RDD의 런타임을 비교 측정
🚩Background
- Part of Speech Tagging: 큰 텍스트 데이터 셋에서 텍스트 features를 줄이기 위해 단어 빈도를 줄이는 작업
- HDFS cluster를 빅데이터 클러스터를 위한 데이터 셋 저장 layer 및 데이터 셋 검색에 사용
- Apache YARN(Yet Another Resource Negotiator): HDFS 스토리지 환경 위에서 배치 작업을 수행하기 위한 리소스 매니저로 활용
- Apache Spark: corpus에서 텍스트 feature를 추출하기 위한 주된 계산 엔진으로 사용
🚩Experiment
Apache HDFS를 빅데이터 클러스터가 데이터 셋을 저장 및 검색하기 위한 스토리지 layer로 사용한다. Apache Yarn은 배치 작업 수행을 위한 하드웨어 리소스 관리자로 역할하며 Apache Spark는 데이터 셋으로 부터 두가지 feature를 추출하기 위한 메인 데이터 프로세싱 엔진으로 사용(RDD & SparkSQL APIs)
A. Big Data Cluster
10개의 서버를 사용했으며, 그 중 9개는 data file을 저장하기 위한 HDFS 워커노드이고, 하나는 클러스터 전체의 data blocks를 추적하기 위핸 Master Name Node로 사용. Apache Yarn 클러스터도 하나의 마스터 리소스 매니저 노드를 가지고 있음. 이는 HDFS Name Node라 불리는 똑같은 마스터 노드에서 돌아감. 다른 노드들은 Node Manager daemon server를 실행하여 리소스 관리자에 대해 각 노드에서 사용 가능한 리소스를 정의한다. 클러스터 마스터에 작업을 submit(spark-submit 명령인듯?)하면 프로그램의 분산 실행을 조정하기 위한 마스터 에플리케이션 컨테이너가 생성된다고 함
사용된 하드웨어 스팩... 넘사벽이네요 ;
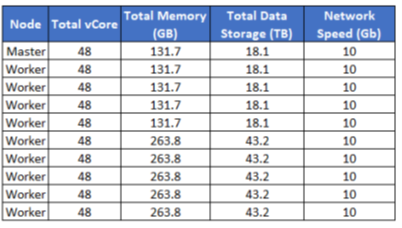
B. Dataset
Wikipedia는 text analysis와 NLP modeling tasks에 풍부한 데이터 소스. Wikipedia article에 대한 아카이브 파일은 https://dumps.wikimedia.org/dewiktionary/latest/ 에서 가져왔고, 실험을 위해 XML을 사용했다고 함.
C. Part of Speech(POS) Tags
POST tagging은 document내 단어의 정의 및 context를 기반으로 명사/동사와 같은 문법적 역할을 설명하는 레이블이 있는 문서와 단어를 분류하는 프로세스. 단어의 POS는 텍스트 분류 또는 감정 분석과 같은 NLP작업에서 매우 유용하다고 함
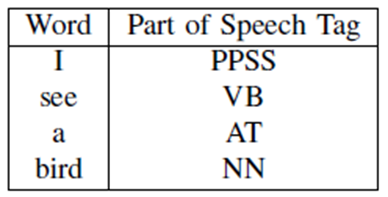
아래는 문장의 각 단어에 대해 제안된 태그 예시를 보여준다.
(PPSS = pronoun; NP =proper noun; VB =verb; UH = interjection; IN =preposition; AT =article; NN = noun)
이 실험에서는 POS tagging 기능을 위해 Natural Language Toolkit(NLTK)라는 파이썬 라이브러리를 사용함
D. Stem Word Frequency
Information Retrieval system에서 형태소 분석은 주어진 단어를 어근 또는 어간 형태로 줄이는 프로세스.
아래 단어는 모두 비슷한 느낌?을 내는 단어다. -ING, -ED, -ION, -IONS와 같은 접미사를 제거하면 CONNECT를 root 형태로 볼 수 있다.
article에서 stop words를 제거하고, 각 단어를 root form으로 줄이기 위해 형태소 분석 알고리즘을 수행함. 형태소 변환은 처리해야하는 단어의 수를 줄여주고, 통계적으로 의미있는 결과물을 줌. 단어 형태소 분석에 일반적으로 사용되는 알고리즘은 M. F. Porter, “An algorithm for suffix stripping,” Program, 1980. 에 의해 제안되었다.
이 단계에서 파이썬 라이브러리인 NLTK를 사용해 일치하는 stop words를 찾고 제거함. 또한 aricle에서 각 단어의 stem form(root form이지 싶네요. 아까 위에 connect)을 추출하는 형태소 분석 알고리즘을 제공해준다고 함. 본 실험에서는 Spark의 RDD 및 SparkSQL APIs를 사용하여, 모든 article에서 stem word가 등장한 횟수를 찾기 위해 aggregation 작업을 수행

🚩Run Time Evaluation
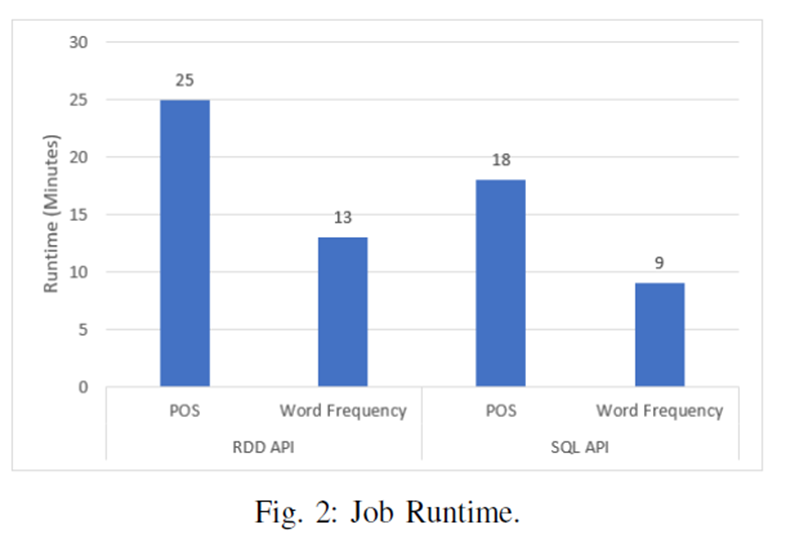
첫번째 실험은 Wikipedia archived file의 모든 기사에서 POS tages와 stem word의 빈도를 추출함. 아래 그림은 feature engineering tasks를 수행한 RDD 및 SparkSQL APIs runtime을 보여줌
그림에서 보다시피 POS 추출시 RDD와 비교해보면 SparkSQL APIs 런타임이 28% 감소함. 게다가 RDD API와 비교하여 stem word 빈도 추출 런타임은 SparkSQL APIs는 30% 감소함
두 API 성능의 상당한 차이는 SparkSQL 엔진이 제공할 수 있는 최적화에 attribute 될수 있다. RDD API는 사용자가 정의한 대로 작업을 실행하며, 작업 실행에 대한 최적화를 수행하지 않는다. 반면에 SparkSQL API는 devlarative paradigm(선언전 패러다임)에서 데이터 접근을 제공한다. 예를 들어 사용자가 수행해야 하는 데이터 변환을 정의하고, SparkSQL 엔진이 계산 수행 방법을 결정한다.
SQL쿼리가 실행되면, Spark 엔진은 SQL 쿼리와 syntax tree에 대한 초기 실행 계획을 빌드한다. 그러고 나서 실행될 효율적인 물리적 계획을 구성하기 위해 여러 쿼리 최적화가 진행된다. SparkSQL 엔진의 Catalyst Optimizer는 RDD에서 작업을 매핑하고 줄이기 위해 SparkSQL API 요청을 변환하는 역할을 한다.
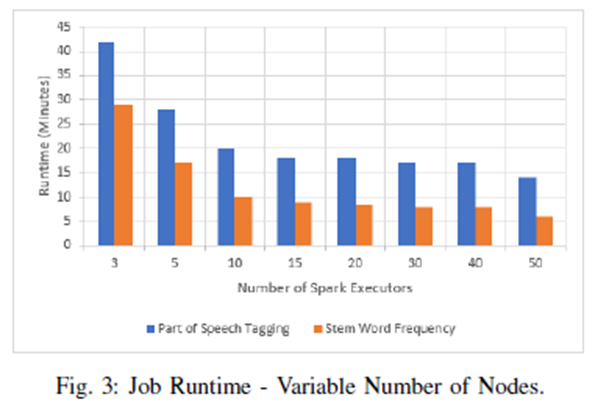
두번째 실험은 배치 작업을 하기 위해 다양한 Spark executor 수를 사용했다. 아래 그림은 3개일 때와 50개의 Spark executor를 사용 했을 때 인데, POS tages와 stem word 빈도를 추출 할 때의 그림이며 각각 67%, 80% 감소함.
노드 수를 늘릴 때, SparkSQL API는 여전히 RDD API를 능가한다. 3개 대신 50개의 executor 사용이 더 높은 작업의 병렬화에 기인. 독집적인 article의 POS 및 stem word의 빈도가 distubuted 될 수 있고, stem word에 대해 최종 집계 계층만 필요하기 때문에 런타임이 크게 감소한거임. (사실 무슨 말인지 이해가 힘듬 ㅠ, 아래 원문)The large reduction in runtime when using fifty executors instead of three is attributed to higher parallelization of the jobs since the POS and stem word frequency of independent articles can be distributed and only a final layer of aggregation is needed for stem word frequencies.
🚩Conclusion
인터넷에서 생성되는 텍스트 데이터의 급격한 증가는 새로운 데이터 처리 요구 사항의 필요성을 야기. 방대한 양의 데이터를 처리하기 위해 빅데이터 플랫폼을 개발하고 유지하는데 리소스를 전념함. 또한 자연어 콘텐츠의 증가로 인해 원시 텍스트 데이터에서 가치 있는 기능을 추출 할 수 있는 많은 NLP 모델링 기술이 등장. 그러나 이러한 feature 엔지니어링 기술의 효율성을 위해 새로운 tool set과 빅데이터 처리 접근 방식이 필요함.
본 실험에서는 빅데이터 처리 환경을 구축 및 개발하고, Apache Spark 플랫폼에서 두 데이터 변환 API의 성능을 비교하기 위해 실증분석을 수행. Apache Spark 엔진에서 SparkSQL API를 사용하면 장기 실행 배치 작업에서의 시간 복잡성을 크게 개선 할 수 있음을 증명함.
또한 대규모 데이터 세트에 대한 이 접근 방식을 따르면 공유 하드웨어 및 데이터 처리 환경을 활용하면서 비용을 절감할 수도 있다.
