bs4는 "Beautiful Soup 4"의 줄임말로, Python 프로그래밍 언어를 위한 웹 스크래핑 라이브러리입니다. 웹 스크래핑은 웹 페이지의 HTML 구조를 분석하고 데이터를 추출하는 작업을 의미합니다. Beautiful Soup는 HTML과 XML 문서를 파싱하고 데이터를 추출하는 데 사용되며, 웹 크롤링 및 데이터 마이닝과 같은 작업을 수행하는 데 편리한 도구입니다.
Beautiful Soup은 다른 파서 라이브러리(예: lxml)를 내부적으로 사용하여 HTML 문서를 파싱하고, 파싱된 문서를 탐색하고 조작할 수 있는 API를 제공합니다. 이를 통해 웹 페이지에서 원하는 데이터를 쉽게 가져올 수 있습니다. 예를 들어, 웹 사이트에서 특정 요소를 선택하거나 태그 이름, 클래스, ID 등과 일치하는 요소를 찾을 수 있습니다.
Beautiful Soup는 파이썬으로 웹 스크래핑을 진행하는 데 매우 유용한 도구이며, 데이터 수집, 웹 사이트 모니터링, 자동화된 작업 등에 활용될 수 있습니다.
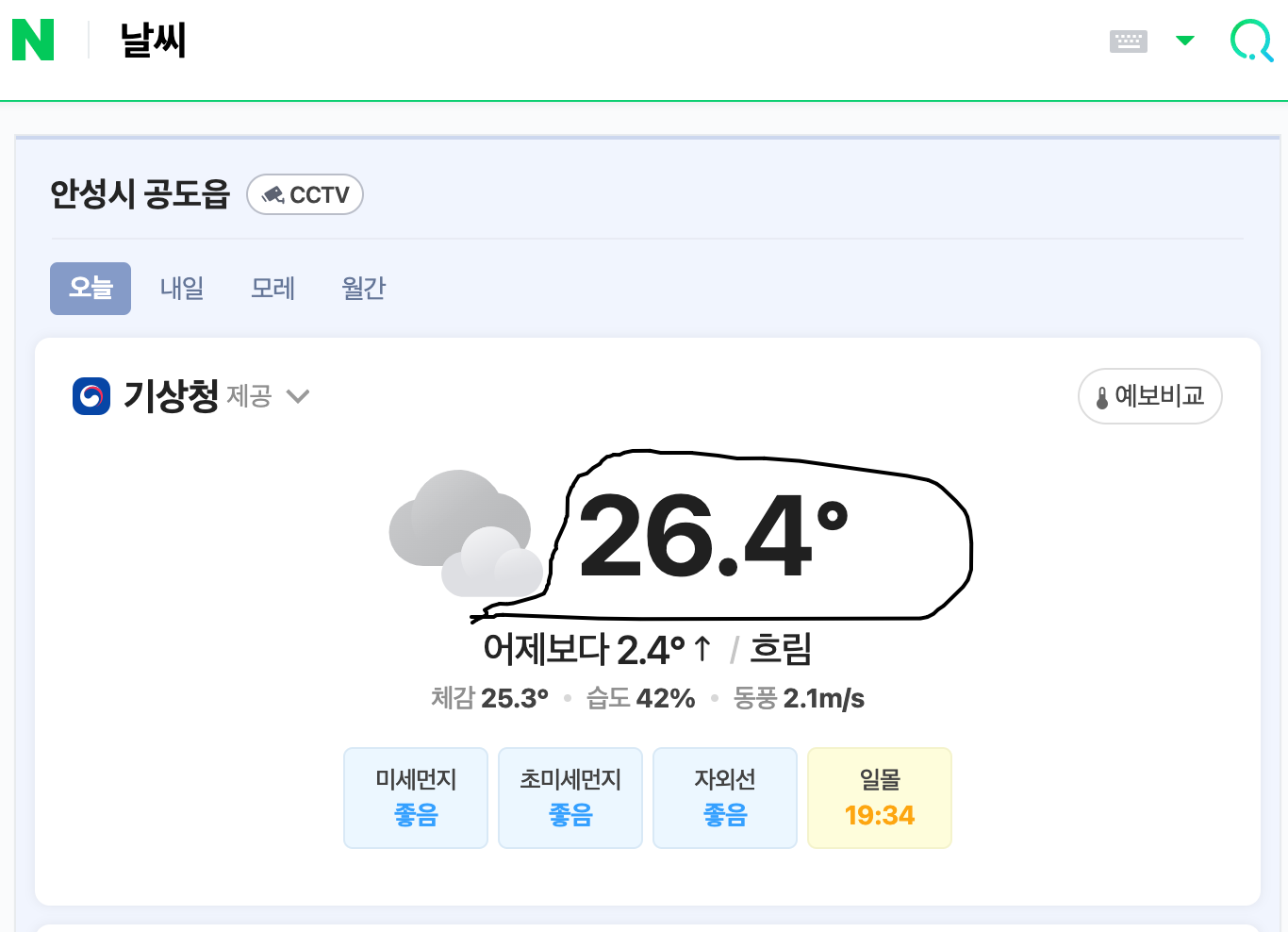
네이버 날씨 페이지에서 현재 온도를 추출하는 예시입니다.
우리가 가지고 오고 싶은 부분 온도

import requests
from bs4 import BeautifulSoup
# 웹 페이지 가져오기
html = requests.get('https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%EB%82%A0%EC%94%A8')
# BeautifulSoup 객체 생성
soup = BeautifulSoup(html.text, 'html.parser')
# 온도 추출
temp = soup.find('div',{'class':'temperature_text'}).text.strip()
print(temp)결과

먼저, requests 라이브러리를 사용하여 https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%EB%82%A0%EC%94%A8 URL로 GET 요청을 보냅니다. 이를 통해 해당 URL의 HTML 내용을 가져옵니다.
그런 다음, BeautifulSoup 객체를 생성합니다. BeautifulSoup 생성자에는 두 개의 인자를 전달합니다. 첫 번째 인자는 HTML 내용이 담긴 html.text입니다. 두 번째 인자로는 'html.parser'를 사용하여 HTML 문서를 파싱하도록 지정합니다.
다음으로, find() 메서드를 사용하여 웹 페이지에서
마지막으로, 추출된 온도 값을 출력합니다.
즉, 이 예시는 네이버 날씨 페이지에서 BeautifulSoup를 사용하여 현재 온도를 추출하는 과정을 보여줍니다.
