
1. 기본 정규형과 정규화 과정
1.1. 정규화 (normalization)
정규화는 함수 종속성을 이용해 릴레이션을 연관성이 있는 속성들로만 구성되도록 분해하여 이상 현상이 발생하지 않는 바람직한 릴레이션으로 만들어 가는 과정입니다. 그러므로 정규화를 통해 릴레이션은 무손실 분해(non-loss decomposition)되어야 합니다.
릴레이션은 의미적으로 동등한 릴레이션들로 분해되어야 하고 분해로 인한 정보의 손실이 발생하면 안됩니다 또한 분해된 릴레이션들을 자연 조인(join)하면 분해 전의 릴레이션으로 복원할 수 있어야 합니다.
1.2. 정규형 (NF; Normal Form)
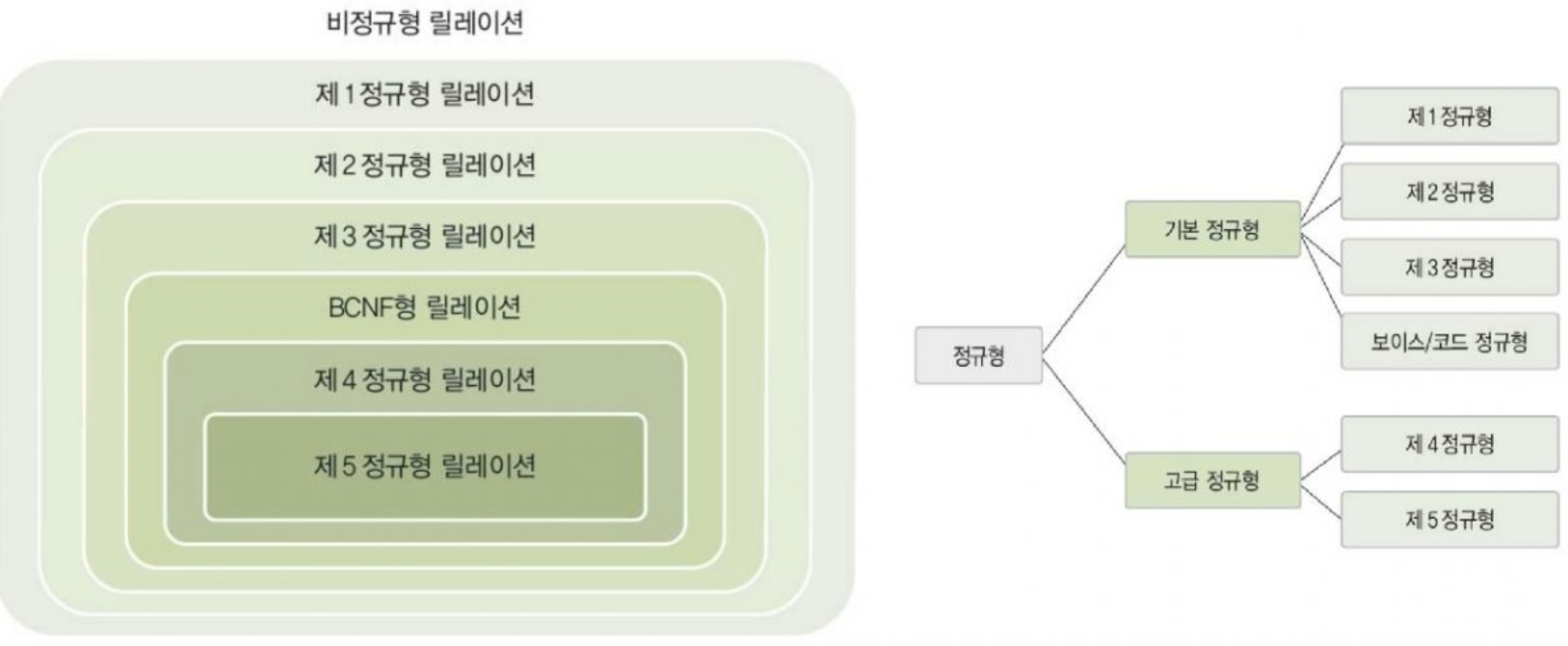
정규형은 릴레이션이 정규화된 정도를 나타내며 6가지로 분류할 수 있습니다. 각 정규형마다 다른 제약조건이 존재하고 정규형의 차수가 높아질수록 요구되는 제약조건이 엄격해고 그에 따른 데이터 중복이 줄어 들어 이상 현상이 발생하지 않는 바람직한 릴레이션이 됩니다. 이런 이유로 무조건 적으로 높은 차수의 정규형을 적용하기 보다는 릴레이션의 특성을 고려하여 적합한 정규형을 선택해야 합니다.
1.2.1. 제 1 정규형(1NF; First Normal Form)
릴레이션의 속한 모든 속성의 도메인이 원자값(더는 분해되지 않는 값)으로만 구성되어 있으면 제 1정규형에 속합니다. 제 1정규형을 만족해야 관계 데이터베이스의 릴레이션이 될 자격이 있습니다.
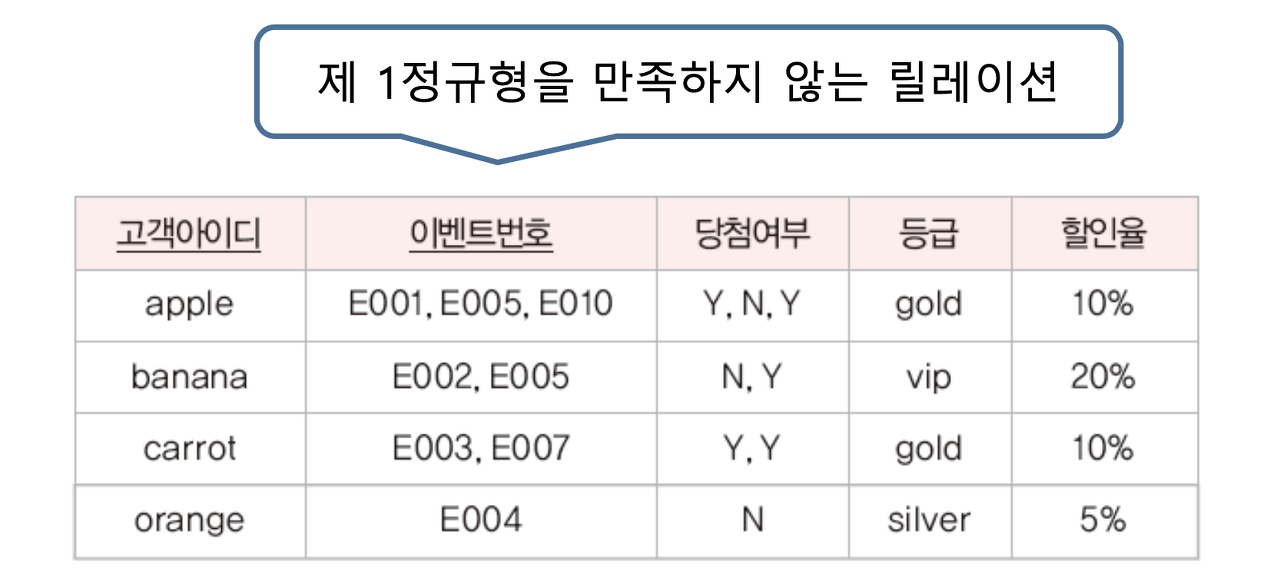
위의 예시는 다중값을 가지고 있는 속성으로 인하여 제 1정규형을 만족하지 못한 릴레이션입니다. 이런 경우 다중값을 각각의 튜플로 변환하여 제 1정규형을 만족시킬 수 있습니다. 하지만 데이터 중복으로 인하여 삽입, 갱신, 삭제 이상이 발생할 수 있습니다.
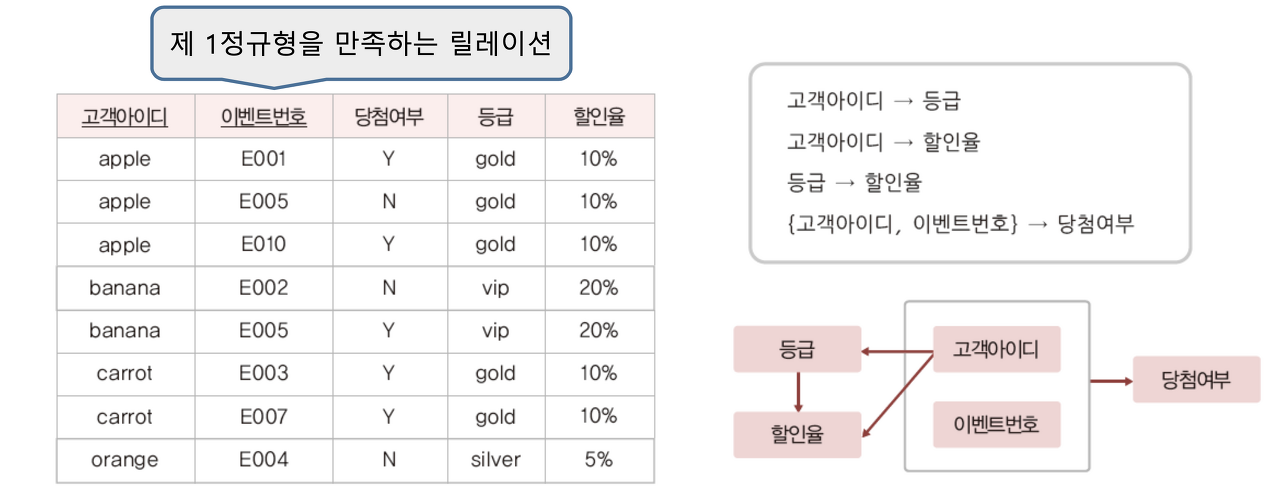
이벤트참여 릴레이션의 함수 종속 다이어그램을 통해 종속 관계를 파악하고 이행적 함수 종속 관계까지 파악할 수 있습니다. 파악된 종속 관계를 살펴보면 기본키에 완전 함수 종속되지 못한 등급과 할인율 때문에 이상 현상이 발생하게 됩니다. 이 문제를 해결 하기 위해 부분 함수 종속을 제거되도록 릴레이션을 분해해야 하는데 이 방법을 제 2정규형이라고 합니다.
1.2.3. 제 2 정규형(2NF; Second Normal Form)
릴레이션이 제 1정규형에 속하면서 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속되면 제 2정규형을 만족합니다.
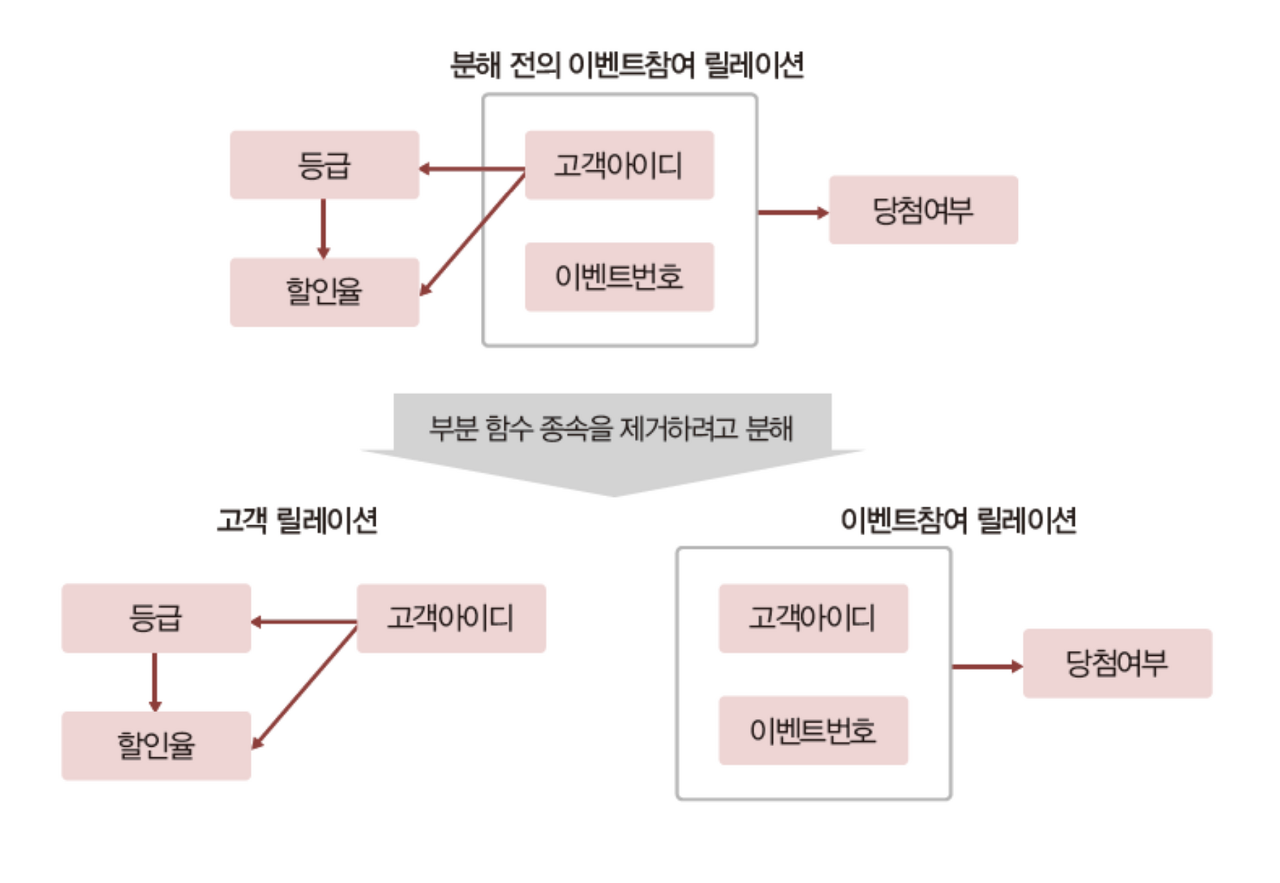
이처럼 이벤트참여 릴레이션을 고객 릴레이션과 이벤트참여 릴레이션으로 분해하여 관리한다면 제 2정규형을 만족할 수 있습니다. 하지만 제 2정규형을 만족하더라도 이상 현상이 발생할 수 있습니다.
만약 고객 릴레이션에서 등급에 따른 할인율을 변경한다면 데이터 불일치로 갱신 이상이 발생할 수 있고 하나의 튜플을 삭제하더라도 필요한 정보까지 삭제되는 삭제 이상, 마지막으로 불필요한 정보까지 삽입해야하는 삽입 이상이 발생할 수 있습니다. 이러한 이상 현상이 발생하는 이유는 이행적 함수 종속 때문입니다. 즉, 등급과 할인율의 관계로 인하여 이행적 함수 종속이 발생하기 때문에 이상 현상이 발생하게 되고 이행적 함수 종속이 제거 되도록 릴레이션을 분해하는 방법을 제 3정규형이라고 합니다.
1.2.3. 제 3 정규형(3NF; Third Normal Form)
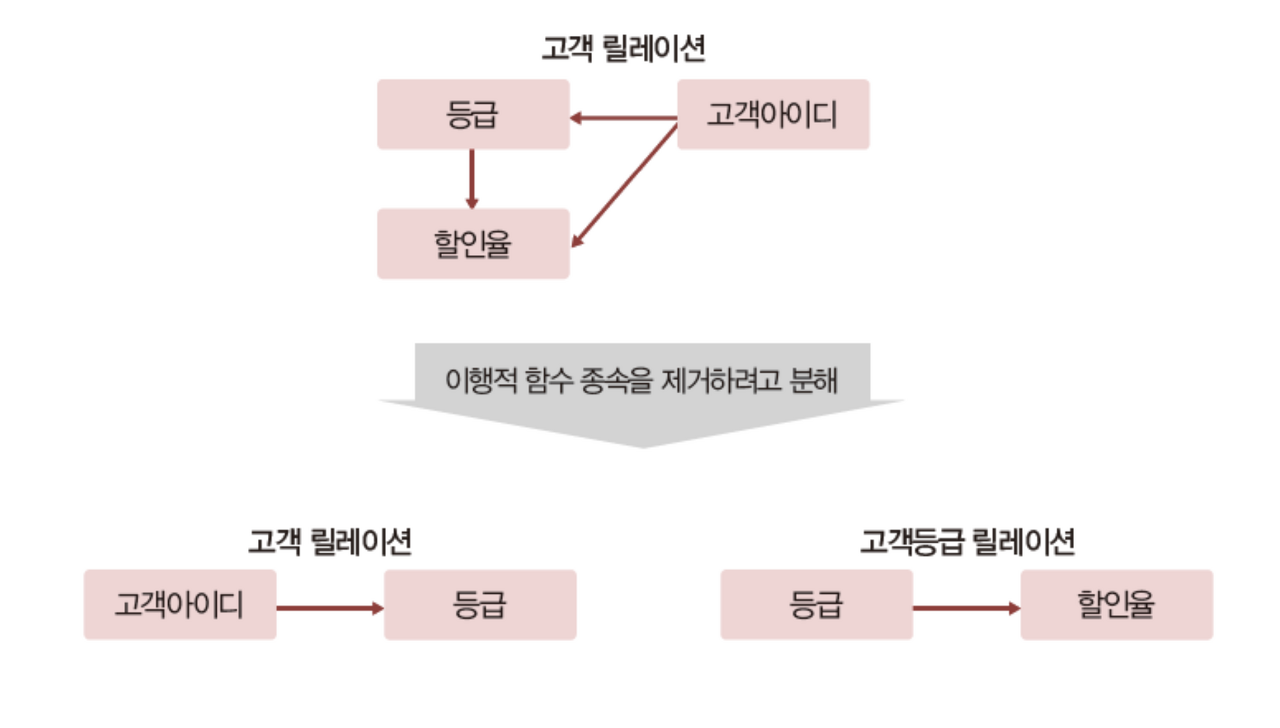
위처럼 이행적 함수 종속이 속한 릴레이션을 분해하여 제 3정규형을 만족시킬 수 있습니다.
1.2.4. 보이스 코드 정규형(BCNF; Boyce Codd Normal Form)

제 3정규형을 만족하며 모든 결정자가 후보키 집합에 속해 있다면 보이스 코드 정규형을 만족합니다. 즉, 후보키가 아닌 속성이 결정자가 되면 안됩니다.
위의 그림은 릴레이션의 원자성, 부분 함수 종속 제거, 이행 함수 종속이 제거 되어 제 3정규형을 만족하고 있습니다. 하지만 새로운 데이터를 추가하려면 불필요한 데이터를 삽입해야 하는 삽입 이상과 1번 학생이 A과목을 포기하게 되어 해당 튜플을 삭제한다면 철수 교수가 A과목을 담당하고 있다는 필요한 정보도 삭제되는 삭제 이상, 담당 교수의 과목이 변경된다면 중복된 데이터를 갱신할 때 일어나는 갱신 이상이 발생할 수 있습니다.
이러한 원인은 담당 교수가 과목을 결정하게 되고 결정자인 담당 교수는 후보키로 사용되고 있지 않기 때문입니다. 위의 릴레이션에서 후보키는 (학생번호, 과목) 또는 (학생번호, 담당교수)가 되고 담당 교수는 후보키가 될 수 없음에도 과목을 결정하는 결정자가 되기 때문입니다.
이러한 이상 현상을 해결하기 위해 모든 결정자가 후보키가 되도록 릴레이션을 분해하게 된다면 보이스 코드 정규형을 만족하게 됩니다.
제 4정규형, 제 5정규형은 현업에서 거의 사용되지 않기 때문에 보이스 코드 정규형까지만 알아보겠습니다.
2. 역정규화(denormalization)
정규화 단계가 진행될수록 중복이 감소하고 이상 현상도 감소합니다. 정규화가 진전될수록 무결성 제약조건을 시행하기 위해 필요한 코드의 양도 감소하게 됩니다.
정규화는 올바른 데이터베이스를 설계하는데 매우 중요한 요소이지만 성능상의 관점에서만 놓고 보면 정규형을 만족하는 릴레이션 스키마가 최적인 것은 아닙니다. 한 정규형에서 다음 정규형으로 진행될 때마다 하나의 릴레이션이 최소한 두 개의 릴레이션으로 분해됩니다.
분해되기 전에는 릴레이션을 대상으로 질의를 할 때 조인이 필요 없지만 분해된 릴레이션을 대상으로 질의를 할 때는 같은 정보를 얻기 위해 보다 많은 릴레이션에 접근 즉, 조인의 필요성이 증가합니다.
상황에 따라 데이터베이스 설계자는 데이터베이스 일부분을 역정규화하여 데이터 중복 및 이상 현상을 대가로 성능을 만족시키기도 합니다. 많은 데이터베이스 활용에서는 검색 질의의 비율이 갱신 질의의 비율보다 훨씬 높으므로 검색 수행 속도를 높이기 위해 두 개 이상의 릴레이션들을 합쳐서 하나의 릴레이션으로 만드는 작업을 역정규화라고 합니다.
