
서버를 운영하다 보면, 갑작스런 이용자의 증가, 사업 확장 등의 이유로 더 많은 서버 용량과 성능이 필요하게 된다.
이번 글에서는 서버를 확장하기 위한 두가지 방법인 스케일 업(Scale-up)과 스케일 아웃(Scale-out) 에 대해 알아볼 것이다.
스케일 업(Scale-up)
스케일 업은 쉽게 말하면 기존의 서버를 보다 높은 사양으로 업그레이드하는 것을 말한다.
하드웨어적 예 - 성능이나 용량 증강을 목적으로 하나의 서버에 디스크를 추가하거나 CPU, 메모리를 업그레이드시키는 것을 뜻한다.
소프트웨어적 예 - AWS의 EC2인스턴스 사양을 micro->small, small->medium등으로 높이는 것을 뜻한다.
이처럼 하나의 서버의 능력을 증강하기 때문에 수직 스케일링이라고도 한다.
스케일 아웃(Scale-out)
스케일 아웃은 장비를 추가해서 확장하는 방식을 말한다.
기존 서버만으로 용량이나 성능의 한계에 도달했을 때, 비슷한 사양의 서버를 추가로 연결해 처리할 수 있는 데이터 용량이 증가할 뿐만 아니라 기존 서버의 부하를 분담해 성능 향상의 효과를 기대할 수 있다. 클라우드 서비스에서는 자원 사용량을 모니터링하여 자동으로 서버를 증설 하는 Auto Scaling 기능도 있다.
서버를 추가로 확장하기 때문에 수평 스케일링이라고도 한다.
스케일 업 과 스케일 아웃의 장단점 비교
스케일 업
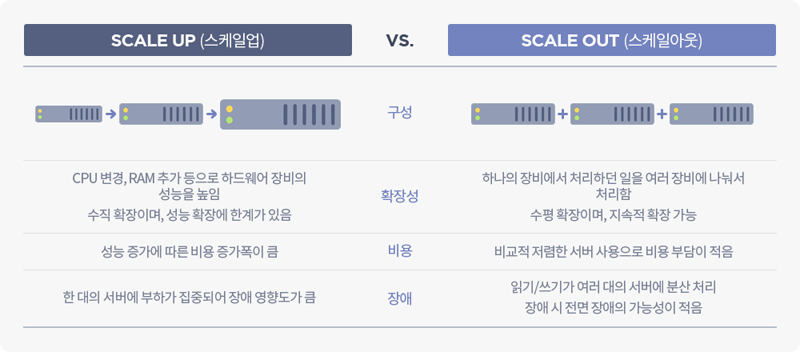
스케일 업 아키텍처에서는 추가적인 네트워크 연결 없이 용량을 증강할 수 있다. 스케일 아웃보다 관리 비용이나 운영 이슈가 적고, 사양만 올리면 되는 것이기 때문에 비교적 쉽다.
다만 성능 향상에 한계가 있으며, 성능 향상에 따른 비용 부담이 크고, 서버 한 대가 부담하는 양이 많아서 서버에 문제가 생기면 큰 타격을 입게 된다.
스케일 업 시스템을 구축한 상황에서는 향후 확장 가능성에 대비해 서버를 현재 필요한 만큼보다 더 많은 용량이나 성능을 확보하는 경우가 많다.
그러나 이런 경우 예상했던 정도와 요구되는 정도가 다르거나, 확장의 필요성이 없어졌을 경우 추가로 확보해놓은 만큼의 손해가 발생하게 된다.
스케일 아웃
스케일 아웃 아키텍처의 가장 큰 장점 중 하나는 확장의 유연성이다.
스케일 아웃 방식으로 시스템을 구축한 상황에서는 서버를 필요한 만큼만 도입하고, 장기적인 용량 증가를 예측할 필요 없이 그때 그때 필요한 만큼 서버를 추가해 용량과 성능을 확장할 수 있다.
다만 스케일 아우도 장점만 있는 것은 아니다. 무엇보다 여러 노드를 연결해 병렬 컴퓨팅 환경을 구성하고 유지하려면 아키텍처에 대한 높은 이해도가 요구된다. 서버의 수가 늘어날수록 관리가 힘들어지느 부분이 있고, 아키텍처의 설계 단계에서부터 고려되어야 할 필요가 있기 때문이다.
여러 노드에 부하를 균등하게 분산시키기 위해 로드 밸런싱(Load Balancing)이 필수적이고, 노드를 확장할수록 문제 발생의 잠재 원인 또한 추가한 만큼 늘어나게 된다.
로드 밸런싱(Load Balancing)
인터넷의 발달로 인해 데이터 통신이 활발해졌고, 이는 트래픽의 폭발적인 증가로 이어졌다.
그 결과 아무리 성능이 뛰어난 서버라고 해도 단 한대의 서버로는 모든 트래픽을 감당해내기 어려워졌다. 이에 기업들은 위에 소개된 스케일 아웃(scale-out) 방식을 통해 여러 대의 서버에 동일한 데이터를 저장해 수많은 트래픽을 효과적으로 분산 처리한다.
그런데 단순히 다수의 서버를 구축해 운영한다고 해서 모든 클라이언트의 요청에 일관성 있게 응답할 수 있을까? 쏟아지는 트래픽을 여러 대의 서버로 분산시켜주는 기술이 없다면 한 곳의 서버에 모든 트래픽이 몰리는 상황이 발생할 것이다. 이때 필요한 기술이 로드 밸런싱이다.
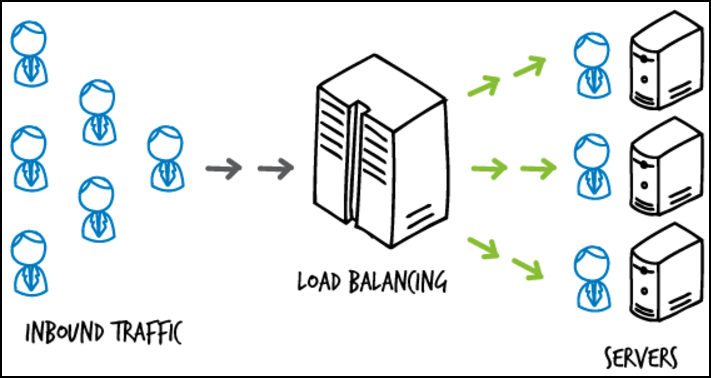
로드 밸런싱이란 말 그대로 서버가 처리해야할 업무, 요청을 여러 대의 서버로 나누어 처리하는 것을 의미한다. 한 대의 서버로 부하가 집중되지 않도록 트래픽을 관리해 각각의 서버가 최적의 업무효율을 낼 수 있도록 하는 것이 목적이다.
로드 밸런싱 기법(알고리즘)
로드 밸런싱 기법은 여러가지가 있다. 서버의 능력을 고려하여 분배해야 하기 때문에 서버의 상황에 맞춰 적절한 방법을 선택해야 한다.
라운드로빈 방식(Round Robin Method)
서버에 들어온 요청을 순서대로 돌아가며 배정하는 방식이다.
클라이언트의 요청을 순서대로 분배하기 때문에 여러 대의 서버가 동일한 스펙을 갖고 있고, 서버와의 연결이 오래 지속되지 않는 경우 활용하기 적합하다.
가중 라운드로빈 방식(Weighted Round Robin Method)
각각의 서버마다 가중치를 매기고 가중치가 높은 서버에 클라이언트 요청을 우선적으로 배분한다. 주로 서버의 트래픽 처리 능력이 서로 다른 경우 사용되는 부하 분산 방식이다.
예를 들어 A라는 서버가 5라는 가중치를 갖고 B라는 서버가 2라는 가중치를 갖는다면, 로드밸런서는 라운드로빈 방식으로 A서버에 5개, B서버에 2개의 요청을 전달한다.
IP 해시 방식(IP Hash Method)
클라이언트의 IP주소를 특정 서버로 매핑하여 요청을 처리하는 방식이다. 사용자의 IP를 해싱(임의의 길이를 지닌 데이터를 고정된 길이의 데이터로 매핑하는 것)하여 업무 또는 요청을 분배하기 때문에 사용자가 항상 동일한 서버로 연결되는 것을 보장한다.
최소 연결 방식(Least Connection Method)
요처이 들어온 시점에서 가장 적은 연결 상태를 보이는 서버에 우선적으로 트래픽을 배분한다. 자주 연결이 길어지거나, 서버에 분배된 트래픽들이 일정하지 않은 경우에 적합한 방식이다.
최소 응답 시간 방식(Least Response Time Method)
서버의 현재 연결 상태와 응답시간(서버에 요청을 보내고 최초 응답을 받을 때까지 소요되는 시간)을 모두 고려하여 트래픽을 배분한다. 가장 적은 연결 상태와 짧은 응답 시간을 보이는 서버에 우선적으로 업무를 배분한다.
L4 로드 밸런싱과 L7 로드 밸런싱
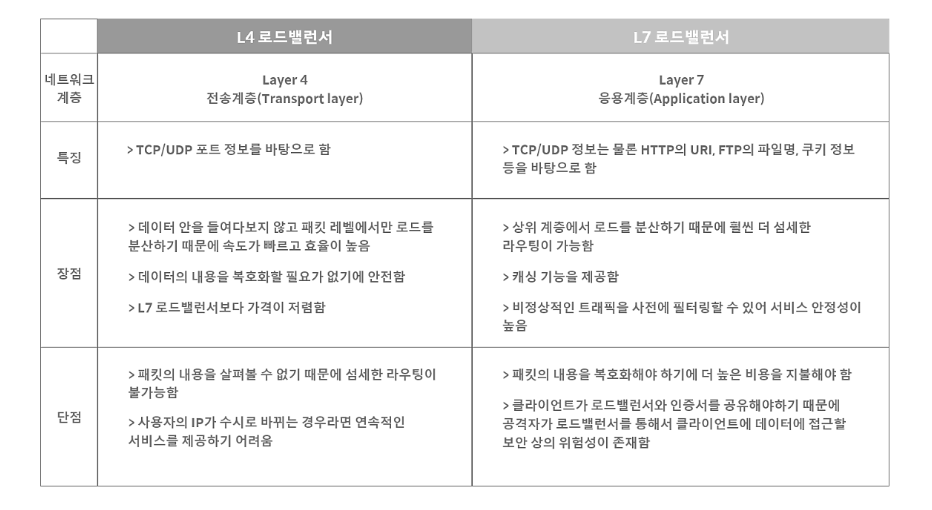
로드 밸런싱에는 L4 로드 밸런싱과 L7 로드 밸런싱이 가장 많이 활용된다.
L4 로드 밸런서는 네트워크 계층(IP, IPX)이나 전송 계층(TCP, UDP)의 정보(IP주소, 포트번호, MAC주소, 전송 프로토콜)를 바탕으로 업무를 분산한다.
L7 로드 밸런서는 애플리케이션 계층(HTTP, FTP, SMTP)에서 로드를 분산하기 때문에 HTTP 헤더, 쿠키 등과 같은 사용자의 요청을 기준으로 특정 서버에 트래픽을 분산하는 것이 가능하다. 쉽게 말해 패킷의 내용을 확인하고 그 내용에 따라 로드를 특정 서버에 분배하는 것이 가능한 것이다. URL에 따라 부하를 분산시키거나, HTTP 헤더의 쿠키 값에 따라 부하를 분산하는 등 클라이언트의 요청을 보다 세분화해 서버에 전달할 수 있다.
또한 L7 로드 밸런서의 경우 특정한 패턴을 지닌 바이러스를 감지해 네트워크를 보호할 수 있으며, DoS/DDoS와 같은 비정상적인 트래픽을 필터링할 수 있어 네트워크 보안 분야에서도 활용되고 있다.

유익한 정보 너무 감사합니다.