오늘의 글: LG AI연구원의 EXAONE
틸다(Tilda)
_1cc17cd81.jpg)
틸다는 LG AI 연구원의 초거대 AI 'EXAONE'으로 구현한 AI 아티스트로 EXAONE 은 틸다의 두뇌 역할을 수행한다. 예를 들어 틸다에게 텍스트를 제시하면 EXAONE 이 사람처럼 다각도로 생각해 세상에 없는 새로운 이미지를 생성해준다. 이는 패션 산업의 근본인 디자인에서 부터 AI 가 적극적으로 참여하는 흔치 않은 사례이다.
그간 초거대 AI는 주로 언어 모델을 기반으로 소설이나 에세이 등 텍스트로 된 콘텐츠를 창작해 왔다. 그러나 틸다는 비전 모델을 통해 멀티모달로 초거대 AI의 창작 범위를 보다 확대하고 이를 패션 분야에 실제로 활용한 첫 사례라는 점에서 큰 의미를 갖는다.
LG 에서는 AI 개발자들을 위해 틸다의 성격과 가치관을 만드는 과정을 '틸다북'이라는 2권의 책에 담았다.
EXAONE
AI는 어떻게 봄을 그렸을까
사람의 시각을 모방하는 비전 AI 는 연구 초기에 이미지를 인식하는 분야에 초첨이 맞춰져 있었다. (도로에 있는 신호등, 차등을 구분하고 인식하는 것과 같은 기능) 그런데 OpenAI는 지난해 수억 장의 이미지-텍스트 데이터 pair를 학습한 뒤 언어로 부터 이미지를 생성하는 사례를 소개했다. (text2image) 이가 DALL-E 라고 불리는 AI 모델의 등장이고, 비전 AI가 인식이 아닌 생성에 초첨을 맞춘 것이다.
VAE(Variational Autoencoder): 잘 정돈된 잠재공간
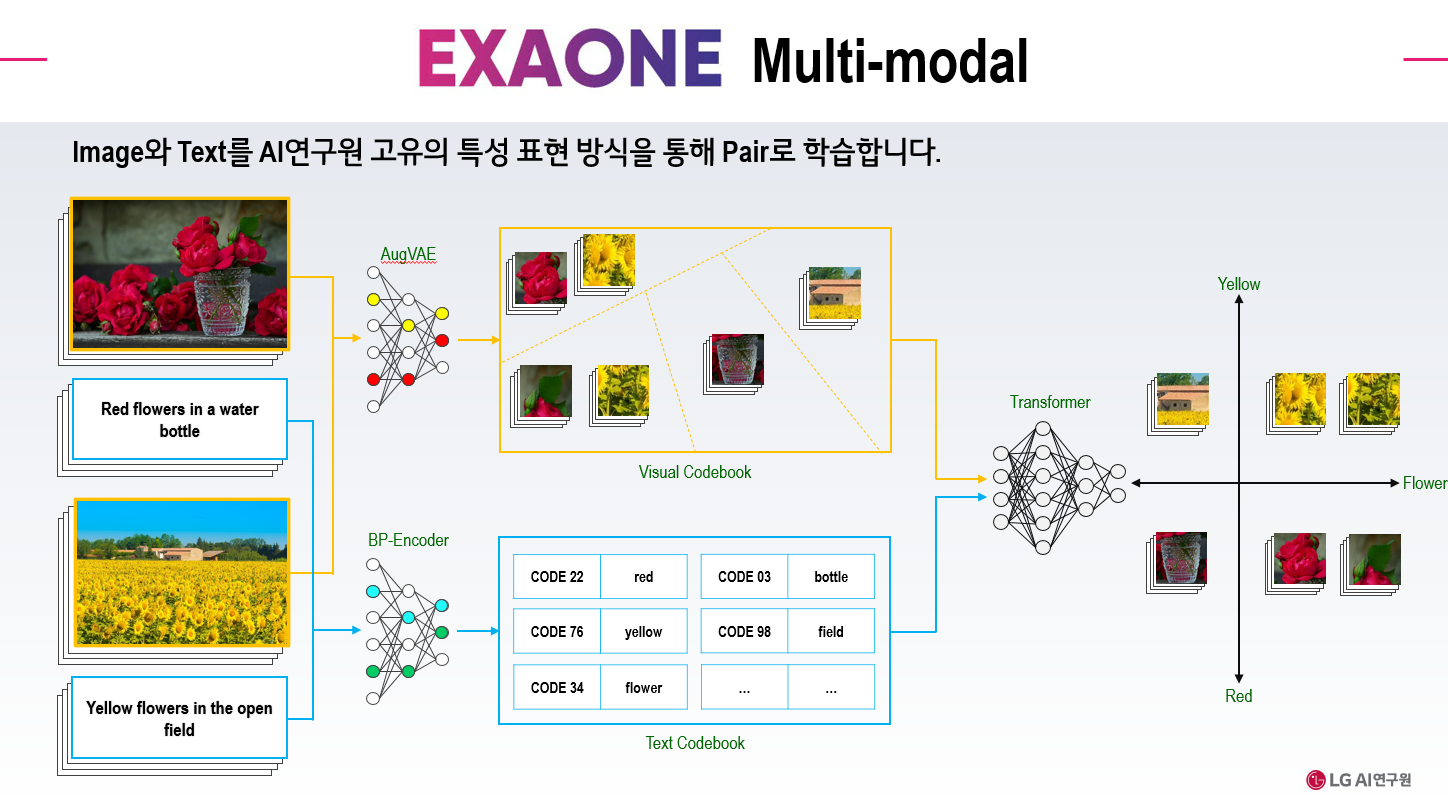
EXAONE 멀티모달 모델에서 학습을 담당하는 것이 AugVAE(feature-augmented Variational AutoEncoder) 이다.
DALLE-E 가 다양한 다양한 이미지를 생성할 수 있었던 비결을 VQ-VAE(Vector Quantized Variational Autoencoder) 덕분이며, LG AI 연구원의 AugVAE 는 이를 더 강화시킨 모델이다.
Autoencoder 란?
입력데이터를 압축시켜 압축시킨 데이터로 축소한 후 다시 확장하여 결과 데이터를 입력 데이터와 동일하도록 만드는 일종의 딥 뉴럴 네트워크 모델
- Encoder: 압축시키는 부분
- Decoder: 확장시키는 부분
출처: https://mc.ai/auto-encoder-in-biology/
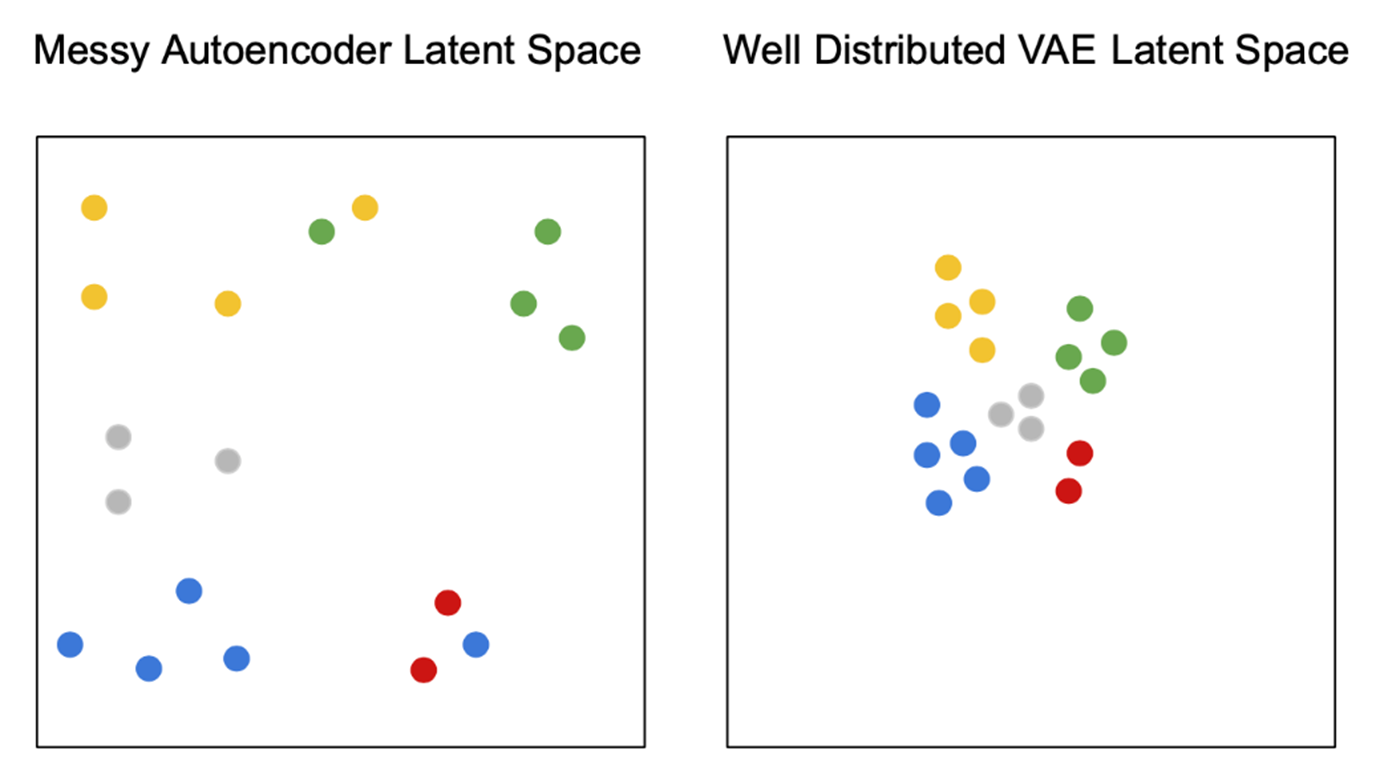
VAE(Variational Autoencoder) 는 Autoencoder 중 학습 이미지를 변환한 잠재공간을 '잘 정돈되게 배치한' Autoencoder 를 말한다. Autoencoder 와 VAE 의 차이는 '같은 색으로 표현된 포인트들을 특징에 따라 정돈해 잠재 공간 상에 배치했는가' 이다.
VQ(Vector Quantized)
잠재 공간 상의 벡터들이 각각 실제 이미지의 어떤 부분과 매칭하는지 정리해 놓은 리스트를 뜻한다. 이 때, 실제 리스트는 사람이 구분가능한 이미지 단위가 아닐 수 있다.
AugVAE 의 기술적 차별점은 VQ를 어떻게 배치하는지에 있다. AugVAE 는 이미 압축 과정의 중간단계에 여러차례에 걸쳐 배치했다. 이를 통해 AugVAE 는 이미지의 패턴을 크기에 상관 ㅇ벗이 잘 구분해 기억한다.
BP-Encoder(Byte Pair Encoder)
연속되는 문자가 등장하면 그것을 다른 문자로 대체하는 식으로 데이터를 압축하는 알고리즘이다. 이를 통해 이미지 설명을 의미 단위로 정리해 이미지 벡터와 마찬가지로 코드북을 만든다.
Transformer
언어와 이미지의 결합을 학습하는 모델이다. 어떤 텍스트에 어떻게 이미지 요소를 결합하면 되는지 학습하게 된다.
용어
멀티모달 AI: 시각, 청각, 감각등의 다양한 모달리티(modality)를 동시에 받아들이고 사고하는 AI 모델.
AI 가 텍스트를 기반으로 콘텐츠를 만드는 것에서 벗어나 이미지, 영상, 생체신호 등을 토대로 새로운 결과물을 내놓을 수 있게 됨.
왜 골랐나?
AI 에 특히 Vision 관련해서 관심이 많다.
독학을 하는 입장에서 저런 멋진 Model을 보면 관심이 갈 수 밖에 었다.
그래서?
AI 관련 공부를 하면서 가장 많이 느끼는 것은 논문 분석 능력이 필요하다는 것이다.
LG 의 EXAONE 을 실컷 구경하고 왜 논문 이야기인가 싶을 수 있지만, Model 전체를 아무 바탕없이 만드는 것은 특히 독학의 입장에서 굉장히 어렵다는 것을 느낀다.
LG 연구원의 글에서도 바탕이 되는 VQ-VAE 를 발전시켰다는 것을 알 수 있다. 이렇듯 Model 의 성능을 높이기 위해서는 관련 논문을 분석해 필요한 부분을 바탕으로 하는 것이 가장 효과적이라 생각한다.
논문을 찾고 분석하는 능력을 기르자
참고한 글
> 멈출 줄 모르는 AI 아티스트 틸다의 거침없는 질주 at 뉴욕페스티벌
> AI는 어떻게 봄을 그렸을까
> [ML] 데이터를 복구하는 Auto Encoder?
