✏️학습 정리
4. Convolutional Neural Networks
- Convolution
-
두 개의 함수를 잘 섞어주는 것
-
2D Convolution
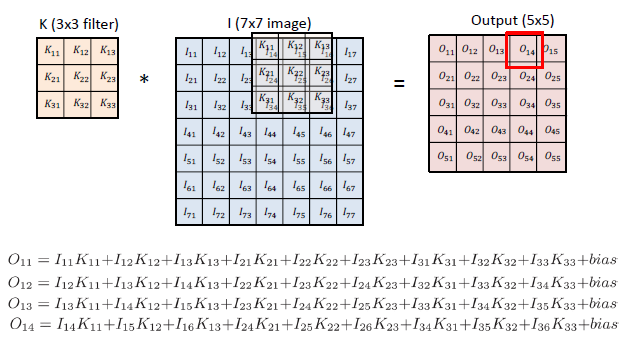
-
RGB Convolution
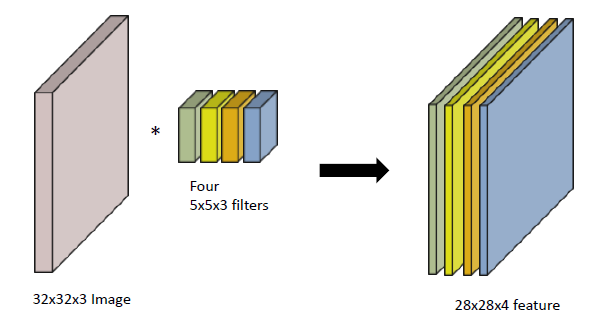
-
- CNN
- convolution layer, pooling layer, fully connected layer로 구성
- stride
-
convolution 필터를 얼마나 자주 찍을 것인가. (dense or sparse)
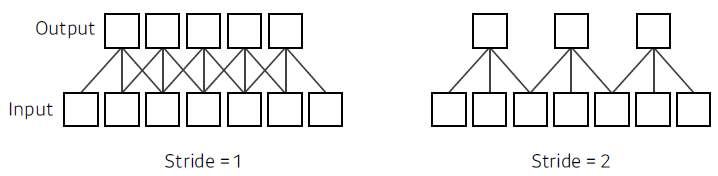
-
- padding
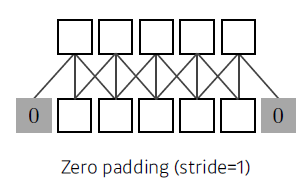
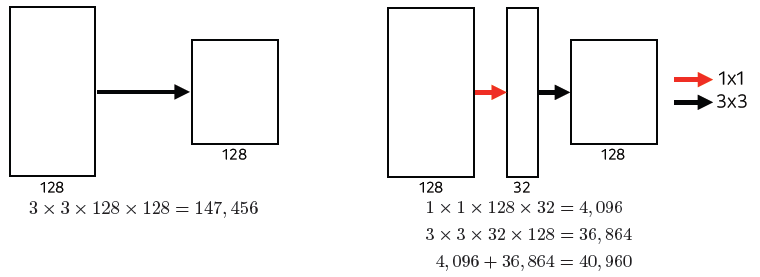
- 1x1 Convolution (why?)
-
차원 축소
-
깊이는 깊어지고, parameter의 수는 줄이고
-
5. Modern Convolutional Neural Networks
-
AlexNet
- 5개의 convolutional layer와 3개의 dense layer로 구성
- 핵심 아이디어
- ReLU 사용
- 2 GPU 사용
- Local response normalization, Overlapping pooling
- Data augmentation
- Dropout
- ReLU
- 선형 모델의 특성 보존
- optimize하기 쉽다
- 좋은 generalization
- vanishing gradient 문제를 극복
-
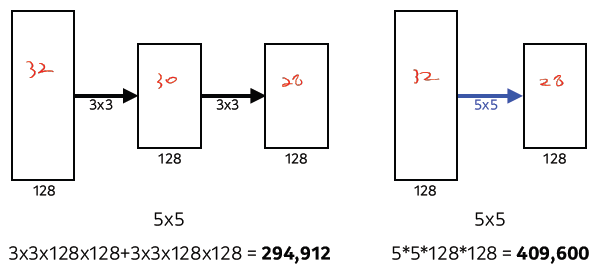
VGGNet
- 깊게 만들고, 필터 사이즈를 3x3으로 고정 (stride 1)
- fully connected layer를 1x1 convolution으로 구현
- Dropout (p=0.5)
- 왜 3x3 filter로 고정?
-
깊게 쌓고, 필터 크기 줄인다. (parameter 수 줄임)
-
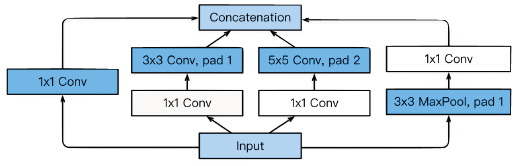
- GoogleNet
- 중간에 1x1 convolution을 잘 활용해보자
- 22개의 layers
- Inception Block
-
1x1 convolution을 활용하여 channel-wise 차원 축소
-
parameter의 수를 줄인다.
-
-
ResNet
-
기존에는 neural network가 깊어지면 train하기 어려웠다.

—> 더 깊게 쌓았는데 error가 더 커짐
-
identity map을 추가 (skip connection)
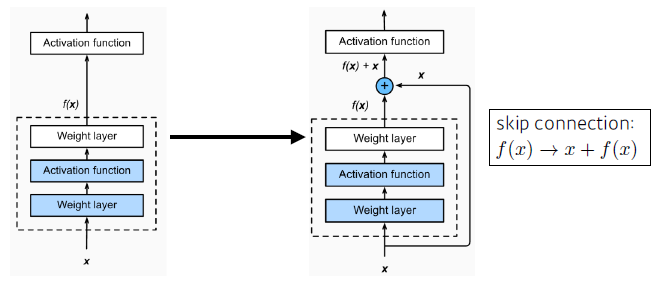
—> activation 이후에 적용
-
bottleneck architecture
- 1x1 convolution을 사용하여 parameter 수 줄이고, 채널 조절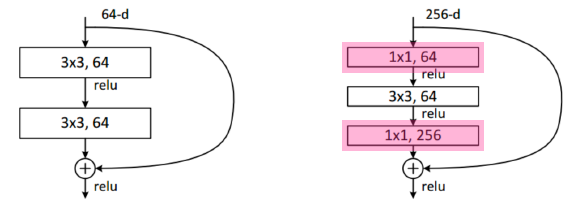
-
parameter의 사이즈가 감소할 동안, 성능은 증가했다.
-
-
DenseNet
-
addition 대신에 concatenation 사용
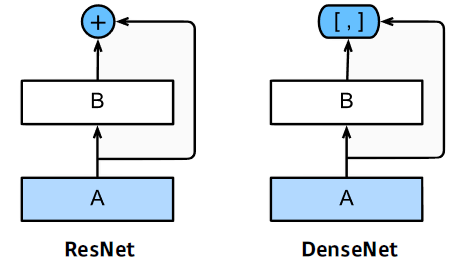
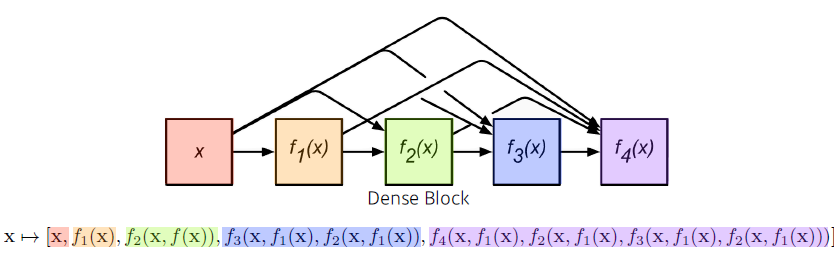
—> 채널이 기하급수적으로 커진다.
-
중간 중간 채널을 줄이자! (1x1 convolution 사용)

—> Dense > Transition > Dense ....
-
6. Computer Vision Applications
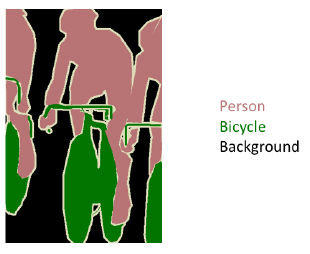
- Semantic Segmentation
-
이미지를 조각으로 나누는 방식 (영역별로)
-
- Fully Convolutional Network
-
convolutionalization

-
fully convolutional network
- input 이미지에 상관없이 돌아간다!
- 보통 output이 줄어들기 때문에, 줄어든 output 크기를 늘려야한다. —> Deconvolution
-
Deconvolution (conv transpose)
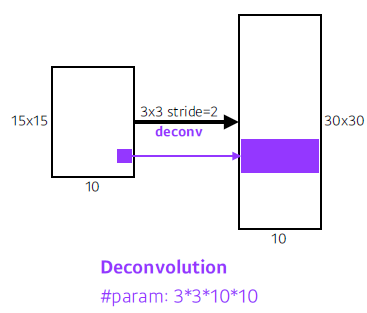
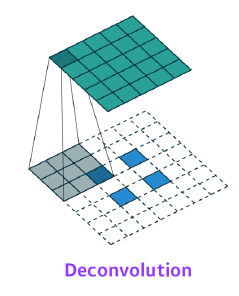
—> 빈공간 모두 padding
-
- Detection
-
R-CNN
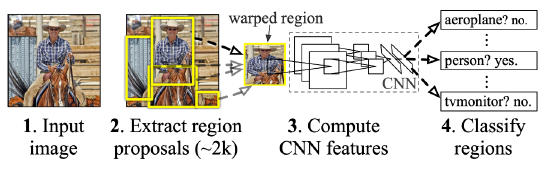
-
SPPNet
- CNN 한 번 실행 —> feature map에서 영역을 뜯어서 R-CNN
-
Fast R-CNN
-
먼저 박스 2000개(예시)를 뽑는다.
-
CNN 한 번 실행
-
그 이후는 SPPNet과 동일
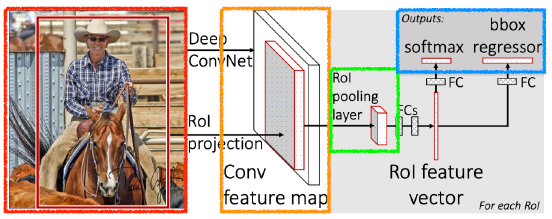
-
-
Faster R-CNN
- bounding box 뽑는 것도 학습시키자. (Region Proposal Network)
-
YOLO
-
매우 빠르게 object detection 수행
-
class 찾는 것과 bounding box 찾는 것을 동시에 수행
-
방법
- 이미지를 SxS grid로 나눈다.
- 각 cell에서 bounding box 예측
- 각 cell에서 class 확률 예측
- 두 개를 통합하여 최종 bounding box 예측
-
-
7. Recurrent Neural Networks
- Sequential Model
-
Naive sequence model
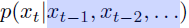
-
Autoregressive model
- 과거 반영 개수 지정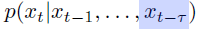
-
Markov model
- 바로 직전 과거만 사용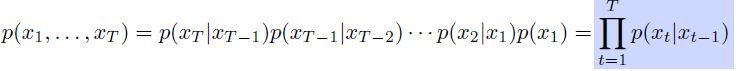
-
Latent autoregressive model

-
- RNN
-
구조
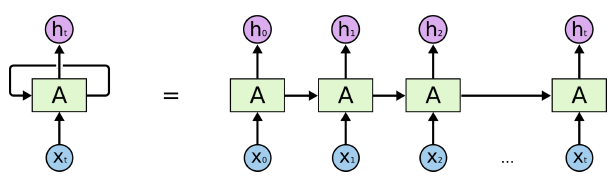
-
Long-term depencencies (멀수록 반영되는 값이 작아진다.)
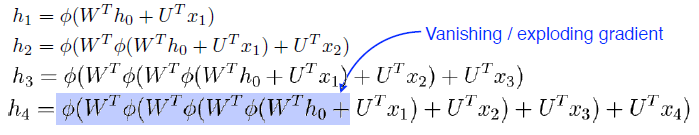
-
-
Long Short Term Memory (LSTM)
-
구조
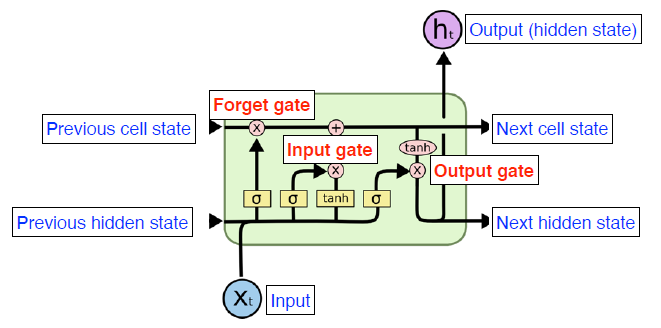
-
Forget Gate
- 어떤 정보를 버릴 것인지 정한다.
-
Input Gate
- 어떤 정보를 추가할 지, 어떤 정보를 보낼지 정한다.
-
Output Gate
- update된 cell state를 이용하여 output을 도출
-
-
Gated Recurrent Unit (GRU)
-
구조
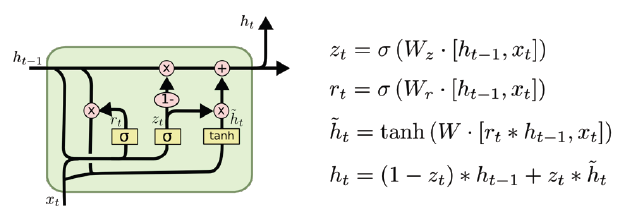
-
간단한 구조 (reset gate와 update gate만 존재)
-
reset gate는 forget gate와 유사
-
cell state가 없고, hidden state만 존재
-
8. Transformer
- Transformer (Attention is All You Need)
-
전적으로 attention에 기반한 첫 sequence 변환 모델
-
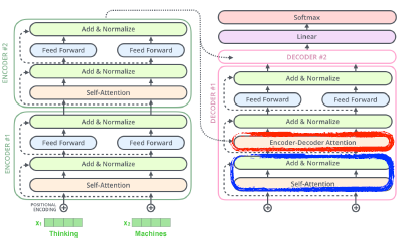
큰 구조
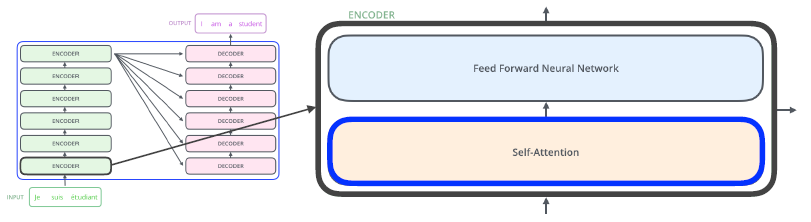
—> encoder와 decoder에 있는 self-attention이 transformer의 핵심이다.
-
입력이 고정되어도 옆에 있는 다른 입력들이 달라지면 출력이 바뀔 수 있다. (flexible)
—> but) NxN attention matrix를 만든다 —> 너무 크면 못 만든다.. (메모리 용량 초과)
-
- Self-Attention
-
예시
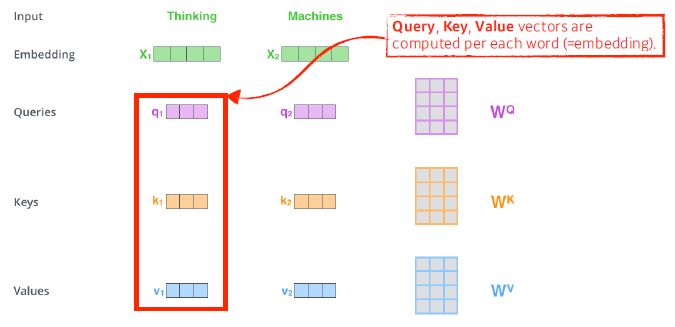
—> 각 단어들 embedding vector(Q, K, V)로 변환
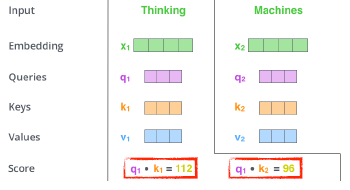
—> score: 유사도 측정 vector
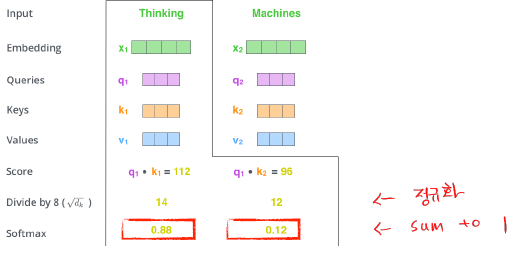
—> d_k: key vector의 차원
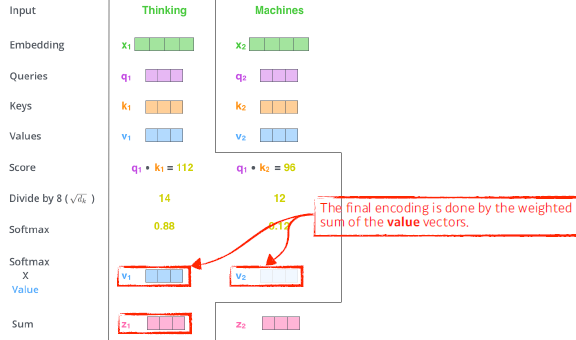
-
행렬로 한번에 계산 가능
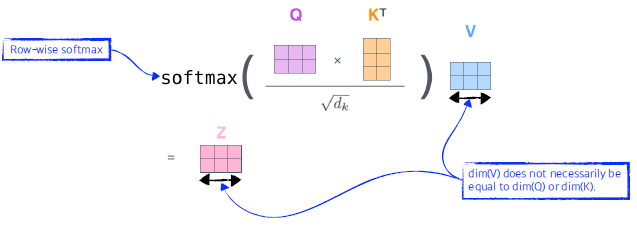
-
Multi-headed attention (MHA)
-
Q, K, V vector를 여러개 생성
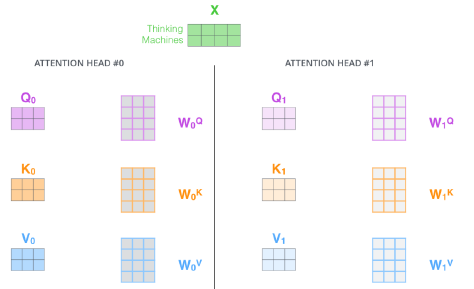
-
attention head들을 concat하고 크기를 맞춰주기 위해 weight matrix를 곱해준다.

-
-
Positional Encoding
-
bias 느낌
-
self-attention을 보면 위치와 무관하게 동일한 단어는 같은 값을 가진다.
-
original embedding에 추가해준다.
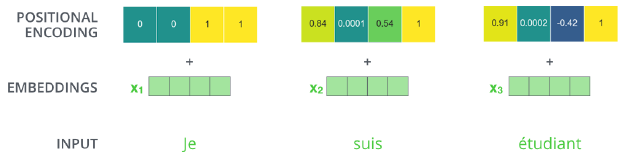
-
-
-
Decoder
-
encoder의 K, V vector 사용 (encoder-decoder attention layer)
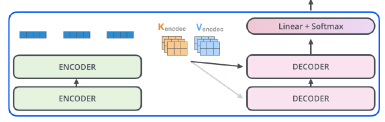
-
decoder의 self-attention layer에서는 이전에 나온 output sequence만 사용 가능 (masking 사용)
-
-
기타 활용 예시
- Vision Transformer
- 이미지 분류에 transformer 사용
- DALL-E
- Vision Transformer
-
Reference
