HTTP
- Hypertext Transfer Protocol : 링크(하이퍼링크)통해 독자가 한 문서에서 다른 문서로 즉시 접근할 수 있는 텍스트이다
- 서버와 클라이언트가 인터넷 상에서 데이터를 주고 받기 위한 프로토콜
- 클라이언트가 HTTP 요청(Request)메세지를 보내면 서버는 HTTP 응답(Respond)메세지를 보내며 서로 통신
HTTP 메세지
- 클라이언트가 웹 서버에게 사용자 요청의 목적/종류를 알리는 수단이다.
따라서 HTTP 요청 메세지를 보내기 위해서는 요청 URL과 요청 매서드를 적어주어야 한다.
요청 매서드
- GET : 정보를 요청하기 위해 사용(일반적으로 많이 씀)
- POST : 정보를 입력하기 위해 사용(아이디 입력 등)
- PUT : 정보를 업데이트 하기 위해 사용
- DELETE : 정보를 삭제하기 위해 사용
- 그외의 매서드: HEAD , OPTIONS , CONNECT , TRACE
URL
- Uniform Resource Locator : HTTP와는 독립된 체계로 자원의 위치를 알려주기 위한 프로토콜
파라미터
- URL파라미터란
웹 서버에 저장된 프로그램을 웹 브라우저로 전달하는 것이며 URL 중에서 물음표?이후 문자열을 뜻합니다. [파라미터 명]=[파라미터 값]이 한 세트로 작동하고, 파라미터가 여러 개 일 때는 마찬가지로 위에 빨갛게 마킹해 둔 것처럼&로 이어줍니다.
참고 : https://www.beusable.net/blog/?p=3798
모듈 설치
> pip install urllib , requests urllib , requests
- 파이썬에서 웹 클라이언트(HTTP 요청 등)를 개발하기 위해사용하는 라이브러리 (웹 크롤링 시 가장 많이 사용하는 라이브러리)
- requests에 대한 설명할 예정
1) 요청하기
import requests
url = "https://www.google.com/"
res = requests.get(url)2) 응답상태
- requests.status_code로 확인한다. 정상적으로 가져오면 200 , 아니면 404를 반환
- res.raise_for_status() : 정상적으로 가져오면 정상적으로 다음 코드가 작성되고 그렇지 않다면 그 다음 동작이 실행되지 않고 자동으로 중지된다.
import requests
url = "https://www.google.com/"
res = requests.get(url)
res.raise_for_statuse()
3) 응답 내용 확인
- content : 디코딩 하지 않은, 바이너리 형식의 데이터를 그대로 읽어온다.
url = "https://www.google.com/"
res = requests.get(url)
res.content- text : UTF-8로 인코딩된 코드를 문자열로 읽어온다.(해당 url의 HTML 정보를 가져옴)
url = "https://www.google.com/"
res = requests.get(url)
res.text- cookies : cook정보 확인
- headers : headers 정보 확인
- encoding : 데이터 인코딩 확인
등등
웹 상의 html을 보기 위해서 주소창 앞에 view-source: 입력하거나
크롬에서 F12 누르고 element 정보를 보면 된다.
BeautifulSoup
pip install bs4
import requests
from bs4 import BeautifulSoup
url = "https://www.google.com/"
res = requests.get(url)
res.raise_for_status
html = res.text
soup = BeautifulSoup(html , "html.parser") # BeaurifulSoup 객체 생성 후 html과 어떤 parser를 사용할지 작성
soup = BeautifulSoup(html , "lxml")
# 우리가 가져온 html 문서를 lxml parser를 통해 BeautifulSoup 객체에 집어 넣어준다. - parsing : 어떠한 웹 페이지 내에서 내가 원하는 데이터를 추출하여 원하는 정보로 가공하는 것을 말한다.
인터프린터 구성 요소 중 하나로 입력받은 자료구조를 빌드하고 문법을 검사하는 역할(즉 정보를 분석하고 가공하는 것) - parser : 컴파일러나 , 인터프리터에서 읽은 것의 문장 구조를 알아내는 parsing(구문분석)을 수행하는 프로그램
- parser 종류
1) html.parser : 일반적이 html파일
2) lxml : 아주 빠른 속도로 처리
3) xml
BeautifulSoup 제공함수
soup.prettify() : html의 구조를 파악하기 쉽게 바꿔준다.
특정 태그안의 정보를 가져오기
soup.title : title태그의 정보 가져온다.
soup.head
soup.p
soup.a
태그이름과 태그 안의 string 가져오기
soup.tage.name
soup.tage.string.find_all()
- 태그이름에 해당하는 모든 태그들을 가져오기 때문에 여러개 존재하는 경우 bs4객체를 리스트 형태로 저장하기 때문에 for문을 통해 각각의 객체에 접근해서 객체의 매서드를 호출할 수 있게 된다.
- 태그 이름과 속성 값으로 추출한다.
# 테그이름을 만족하는 모든 element를 리스트 형태로 저장한다.
# (리스트 접근 가능)
soup.find_all('태그이름')
soup.select('태그이름')
soup.find_all("a" , attrs = {"class":"title"})
# a 태그의 속성이 class = "title" 인 모든 element를 가져온다.
# 만약 동일한 속성을 가지는 element가 여러개 존재하는 경우 리스트 형태로 접근이 가능하다.
soup.find_all("a" , attrs = {"class":"title"})[2]여기서 find_all과 select는 동일한 동작을 수행한다.
추출한 element의 text 추출하기
a = soup.find_all("a" , attrs = {"class":"title"})
a.get_text()크롤링 예제
HOLLYS의 매장검색에서 매장에 대한 정보를 크롤링을 해보자 (우선 1페이지 부터)
from bs4 import BeautifulSoup
import requests
import pprint
import pandas as pd
# 1page에 대한 지역, 매장명, 주소 크롤링
url = "https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store="
res = requests.get(url)
res.raise_for_status
html = res.text
soup = BeautifulSoup(html , "lxml")
tbody_tag = soup.find("tbody")
areas = []
store_ids = []
store_address = []
for tr_tag in tbody_tag.find_all("tr"):
areas.append(tr_tag.find("td" , attrs = {"class" : "noline center_t"}).get_text())
store_ids.append(tr_tag.a.get_text())
store_address.append(tr_tag.find_all("a")[1].get_text())
df = pd.DataFrame({
"지역" : areas,
"매장명 " : store_ids,
"주소" : store_address
})
df전체 페이지에 대한 정보 크롤링 하기
#1~54page에 대한 지역 , 매장명 , 주소 추출
from bs4 import BeautifulSoup
import requests
import pprint
import pandas as pd
areas = []
store_ids = []
store_address = []
for page in range(1,54):
url = "https://www.hollys.co.kr/store/korea/korStore2.do?pageNo={}&sido=&gugun=&store=".format(page)
res = requests.get(url)
res.raise_for_status
html = res.text
soup = BeautifulSoup(html , "lxml")
tbody_tag = soup.find("tbody")
for tr_tag in tbody_tag.find_all("tr"):
areas.append(tr_tag.find("td" , attrs = {"class" : "noline center_t"}).get_text())
store_ids.append(tr_tag.a.get_text())
store_address.append(tr_tag.find_all("a")[1].get_text())
df = pd.DataFrame({
"지역" : areas,
"매장명 " : store_ids,
"주소" : store_address
})
df크롤링 결과

네이버 금융 크롤링
- 네이버 금융에서 삼성 전자 가격,이름,종목코드,거래량 정보 추출
- url : https://finance.naver.com/item/main.naver?code=005930
from bs4 import BeautifulSoup
import requests
URL = "https://finance.naver.com/item/main.naver?code=005930"
req = requests.get(URL)
html = req.text
bs4 = BeautifulSoup(html , "html.parser")
div_today = bs4.find("div" , attrs={"class": "today"}) # bs4.elment.tag 객체 반환
em = div_today.find("em" , attrs={"class":"no_down"})
price = em.find("span" , {"class" : "blind"}).text # 삼성전자 가격정보 획득
print("가격 : ", price)
company = bs4.find("div" , {"class" : "wrap_company"})
name = company.h2.text
print("이름 : " , name)
code = company.find("div" , {"class" : "description"}).span.text
print("종목코드 : " , code)
table = bs4.find("table" , {"class" : "no_info"})
tds = table.find_all("td")
amount = tds[2].find("span" , {"class": "blind"}).text
print("거래량 : " , amount)
dic = {
"price" : price,
"name" :name,
"code" :code,
"amount" : amount
}
dic위의 코드를 함수화(url의 code매개변수만 바꾸면 다른 종목의 데이터 정보 반환하는 함수)
from bs4 import BeautifulSoup
import requests
def crawl(code):
URL = f"https://finance.naver.com/item/main.naver?code={code}"
req = requests.get(URL)
html = req.text
bs4 = BeautifulSoup(html , "html.parser")
div_today = bs4.find("div" , attrs={"class": "today"}) # bs4.elment.tag 객체 반환
em = div_today.find("em" , attrs={"class":"no_down"})
price = em.find("span" , {"class" : "blind"}).text # 삼성전자 가격정보 획득
print("가격 : ", price)
company = bs4.find("div" , {"class" : "wrap_company"})
name = company.h2.text
print("이름 : " , name)
code = company.find("div" , {"class" : "description"}).span.text
print("종목코드 : " , code)
table = bs4.find("table" , {"class" : "no_info"})
tds = table.find_all("td")
amount = tds[2].find("span" , {"class": "blind"}).text
print("거래량 : " , amount)
dic = {
"price" : price,
"name" :name,
"code" :code,
"amount" : amount
}
return dic위의 함수를 이용하여 데이터 프레임으로 저장
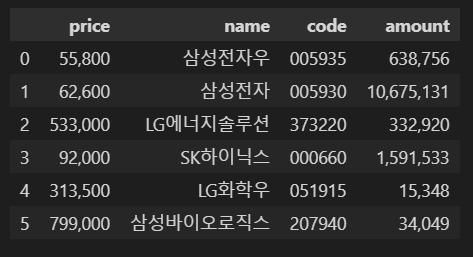
import pandas as pd
codes = ["005935" ,"005930" ,"373220" ,"000660" ,"051915" ,"207940"]
result = []
for code in codes:
result.append(crawl(code))
df = pd.DataFrame(result)
df