개요
- vLLM은 HF transformers 대비 최대 24배 높은 처리량을 보여줌
- UC 버클리에서 개발되었으며, 매우 간단한 커맨드로 사용 가능한 오픈 소스 라이브러리
- vLLM의 핵심 기술은 트랜스포머의 KV cache를 paging을 통해 메모리 효율적으로 저장해 연산 병목을 완화하는 paged-attention
성능
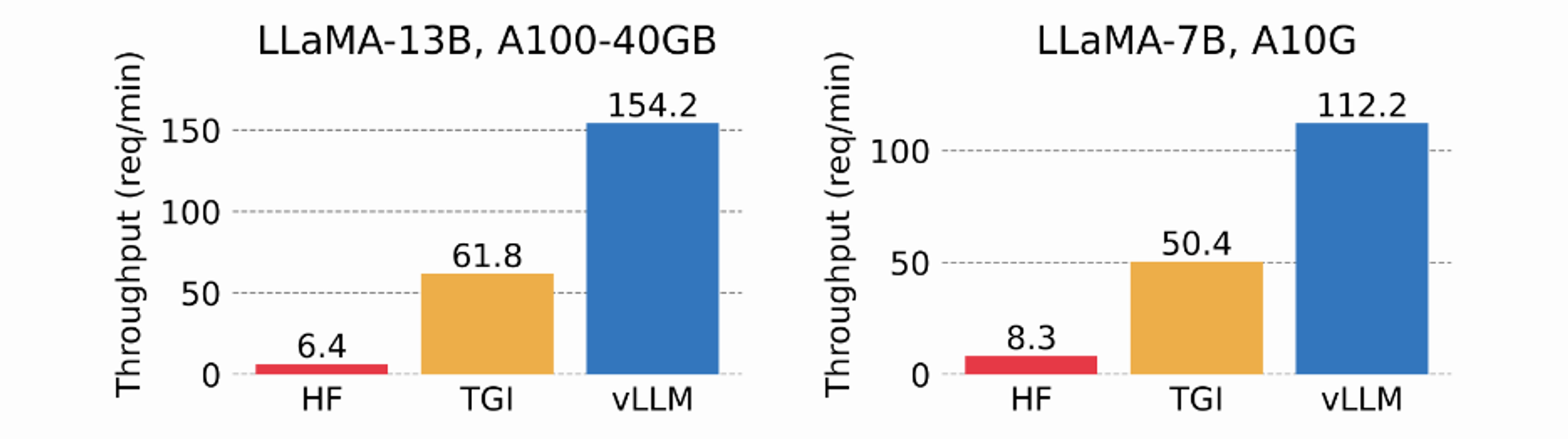
- 단일 output completion 작업에서의 성능 비교
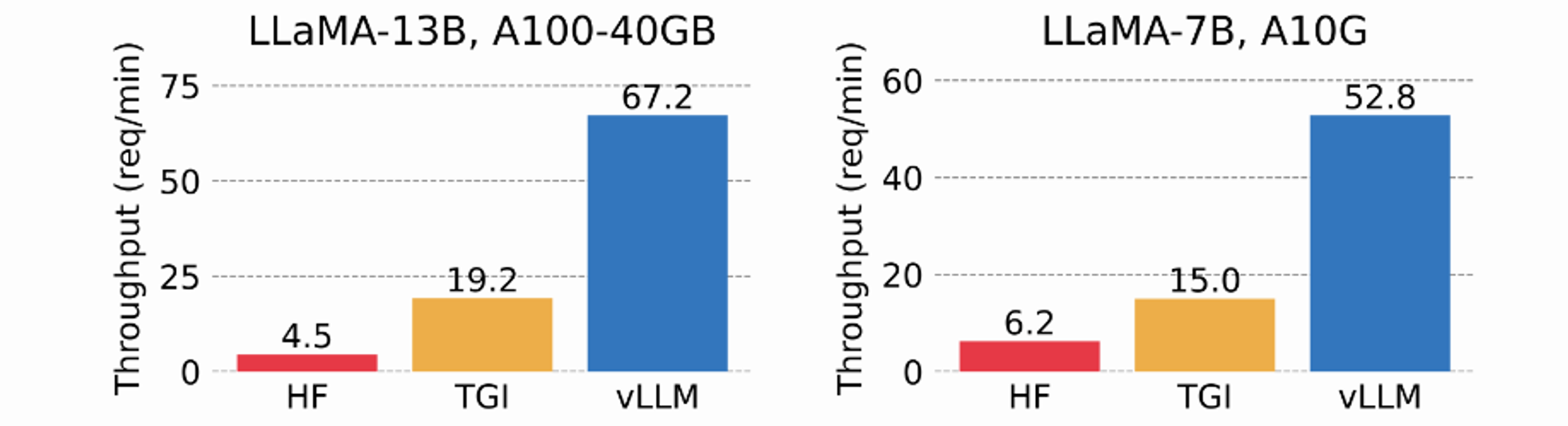
- 3개 병렬 output completion 작업에서의 성능 비교
- 실제 LLaMA3 8B를 통해 추론했을 때, task와 sequence length에 따라 다르지만 초당 4천 토큰 추론까지 가능한 모습을 보였음 (H100 80GB 1장 기준)
PagedAttention?
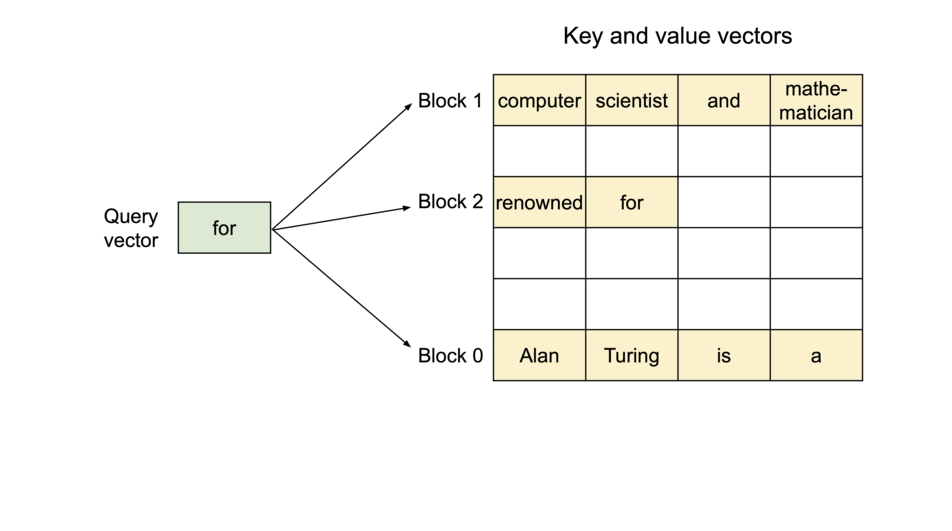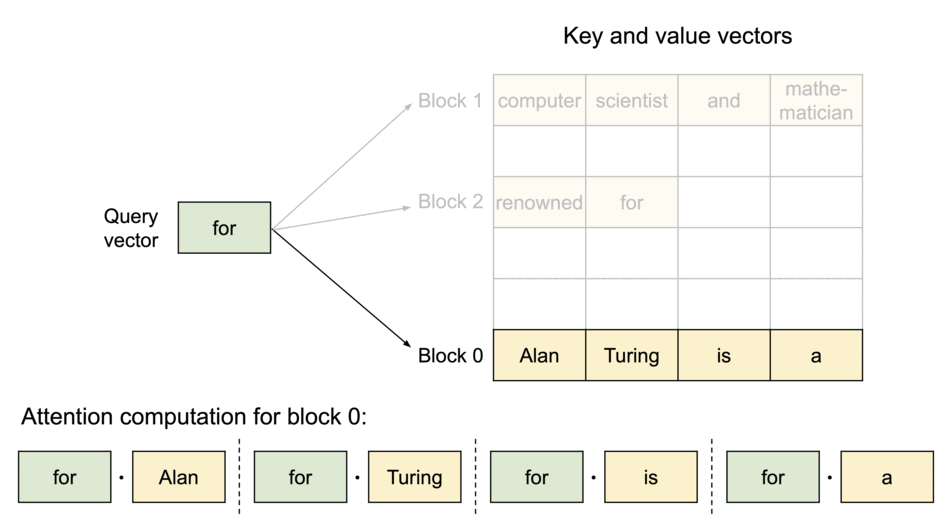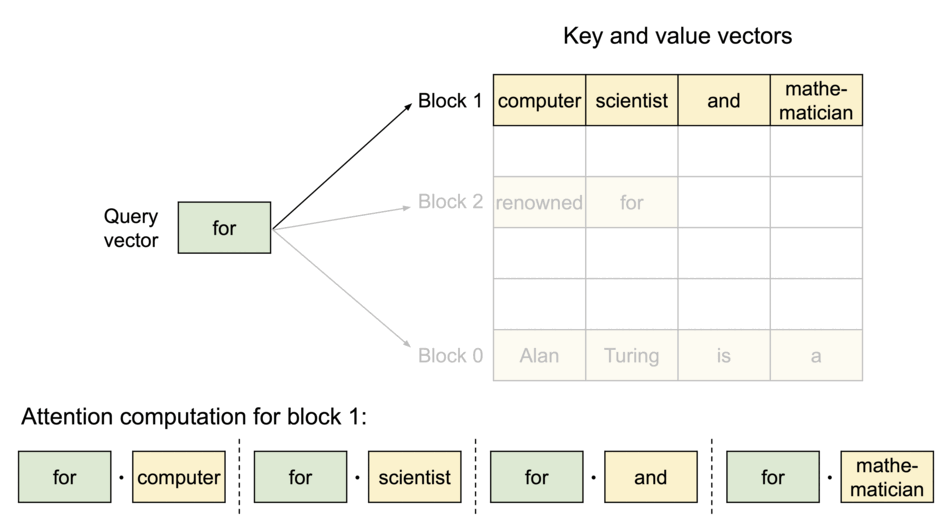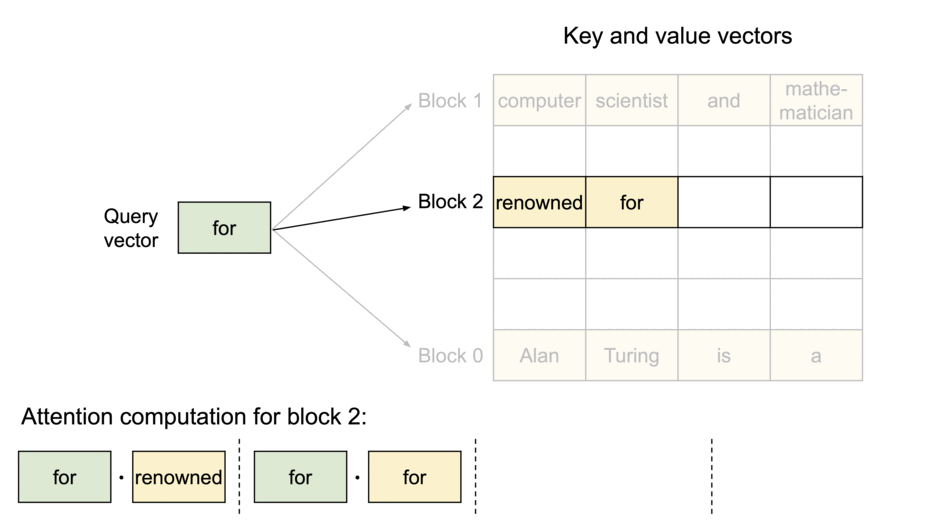
- LLM의 성능 제한은 memory bottleneck이 원인
- Auto-regressive decoding 프로세스에서 LLM에 입력되는 모든 토큰은 attention의 key-value 텐서를 생성하고, 이는 다음 토큰을 생성하기 위해 VRAM에 저장됨 (a.k.a., KV cache)
- KV cache의 특징으로는
- Large: 단적으로 LLaMA-13B를 예로 들었을 때 단일 시퀀스에 대해 최대 1.7GB를 차지함
- Dynamic: 시퀀스 길이에 따라 크기가 달라지며, 가변적이고 예측이 힘듬. 기존 시스템은 fragmentation과 over-reservation으로 인해 60~80%의 메모리를 낭비
- 해당 문제를 해결하기 위해 OS의 가상 메모리와 페이징을 활용한 PagedAttention을 도입
- 기존의 attention 알고리즘과 달리 연속적인 key-value를 비연속적인 메모리 공간에 저장
- 각 시퀀스의 KV cache를 블록으로 분할하고, 각 블록은 고정 개수의 토큰에 대한 KV를 포함
- Attention 연산 시 PagedAttention 커널은 이 블록을 효율적으로 식별 및 호출
- 각 블록은 연속적일 필요가 없기 때문에, 보다 유연한 관리가 가능
- 블록 = 페이지, 토큰 = 바이트, 시퀀스 = 프로세스라고 생각하면 편함
- 시퀀스의 인접한 logical 블록은 테이블을 통해 인접하지 않은 physical 블록에 맵핑
- Physical 블록은 새 토큰이 생성될 때 필요에 따라 할당
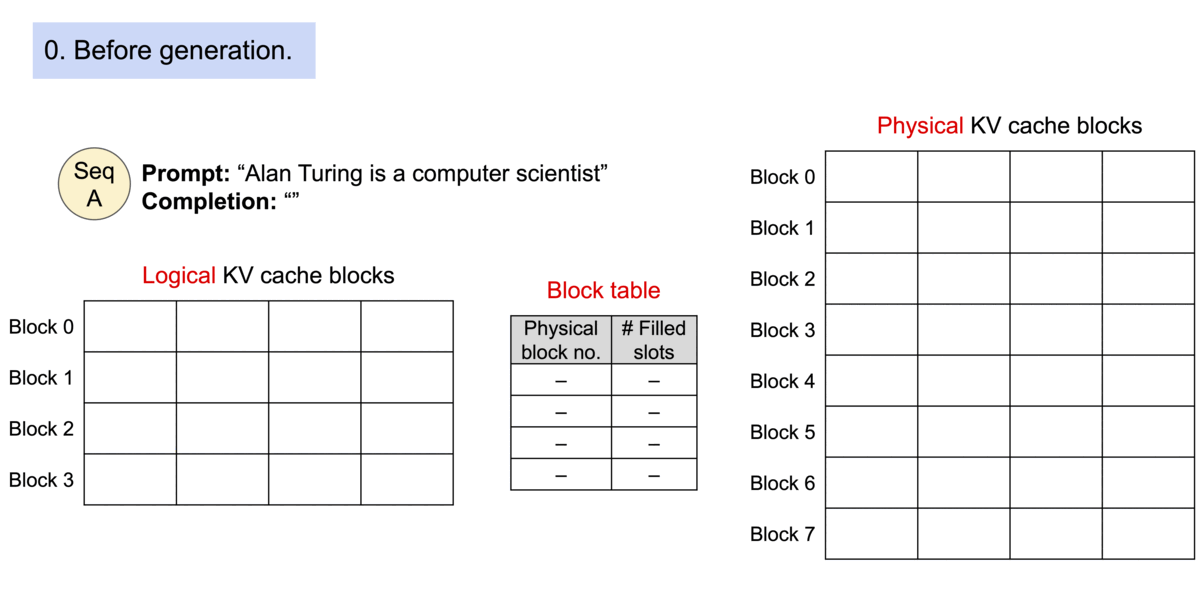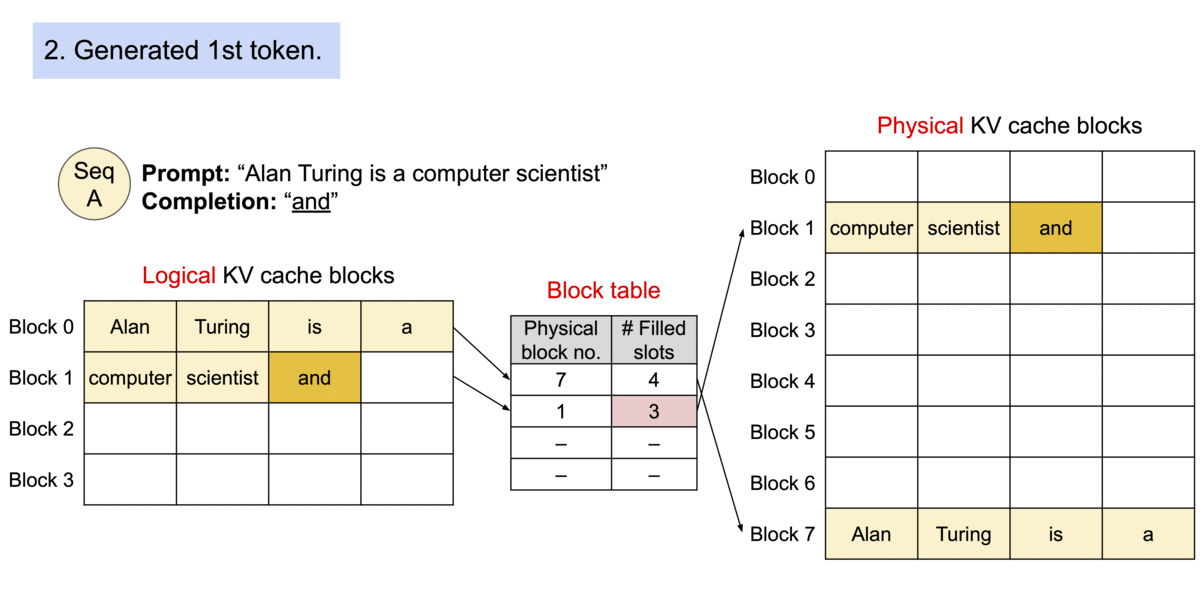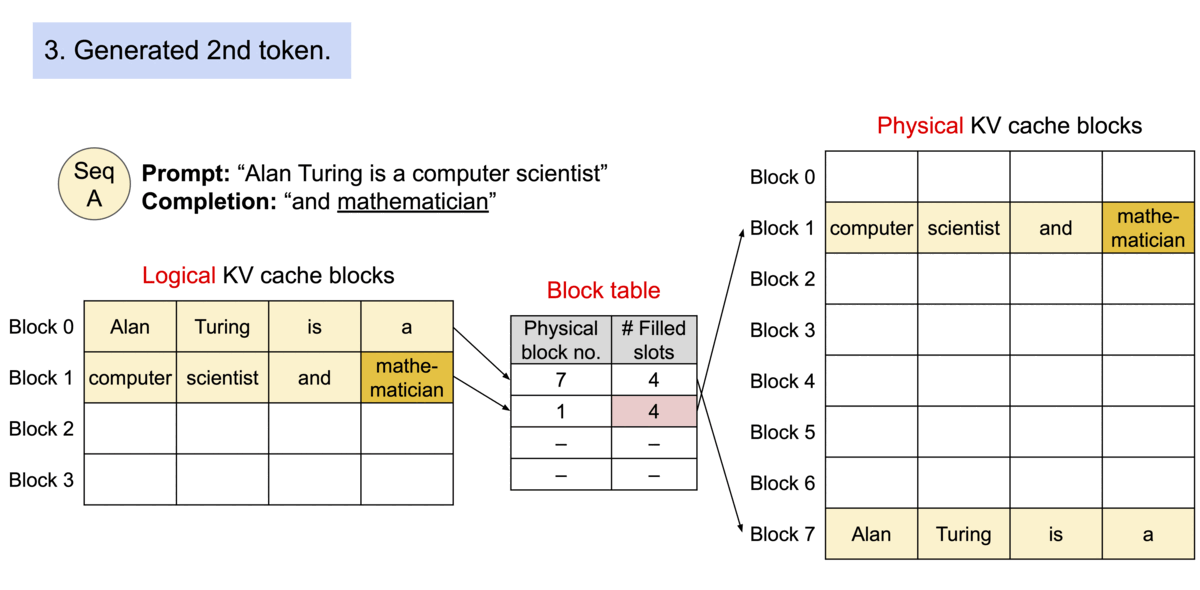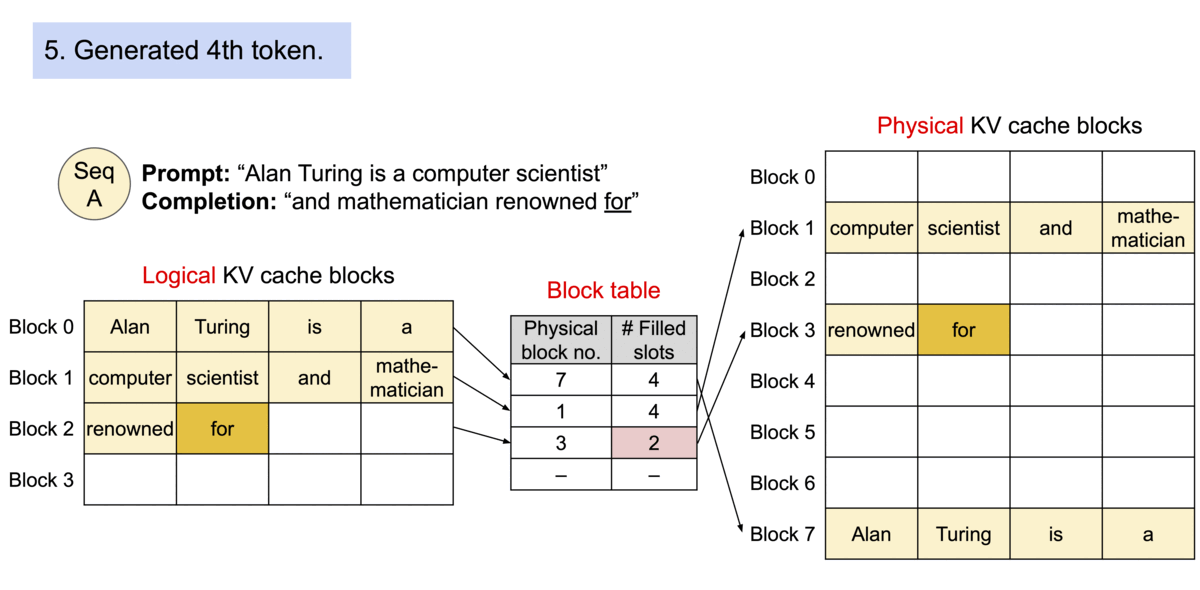
- PagedAttention의 메모리 낭비는 시퀀스의 마지막 블록에서만 발생
- 실제 메모리 낭비는 4% 미만으로, 거의 최적에 가까운 메모리 사용량을 제공
- 이러한 메모리 효율성 향상은 시스템에서 더 많은 시퀀스를 일괄 처리하고, GPU 활용도를 높여 위 성능 결과처럼 처리량을 크게 증가시킬 수 있도록 함
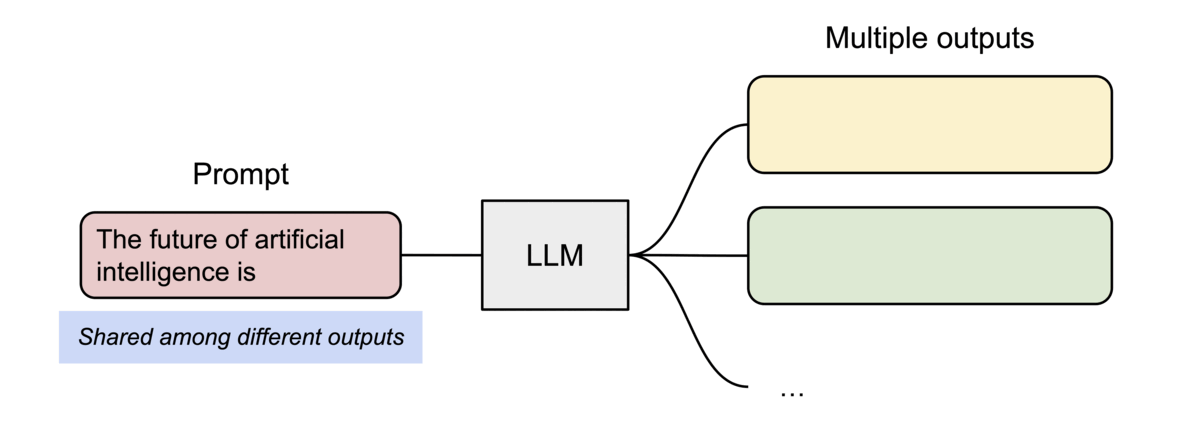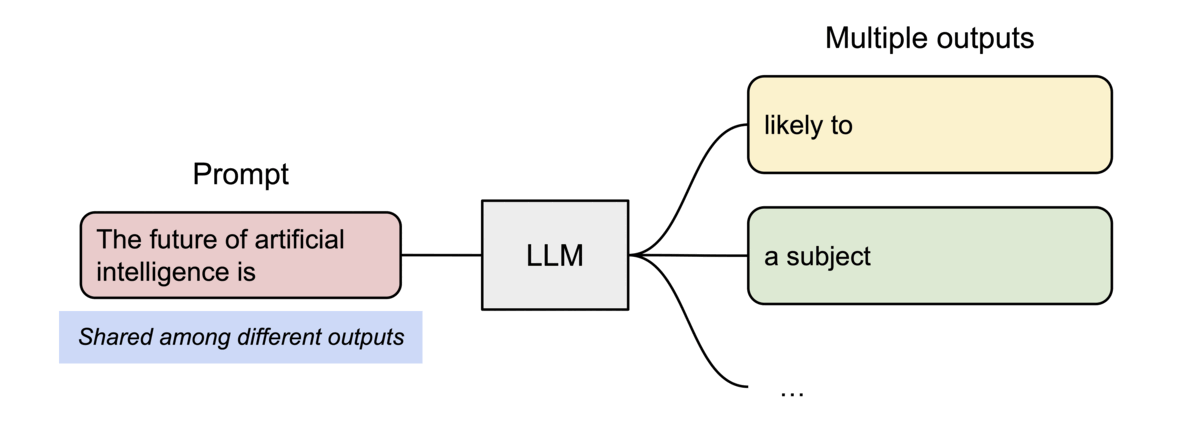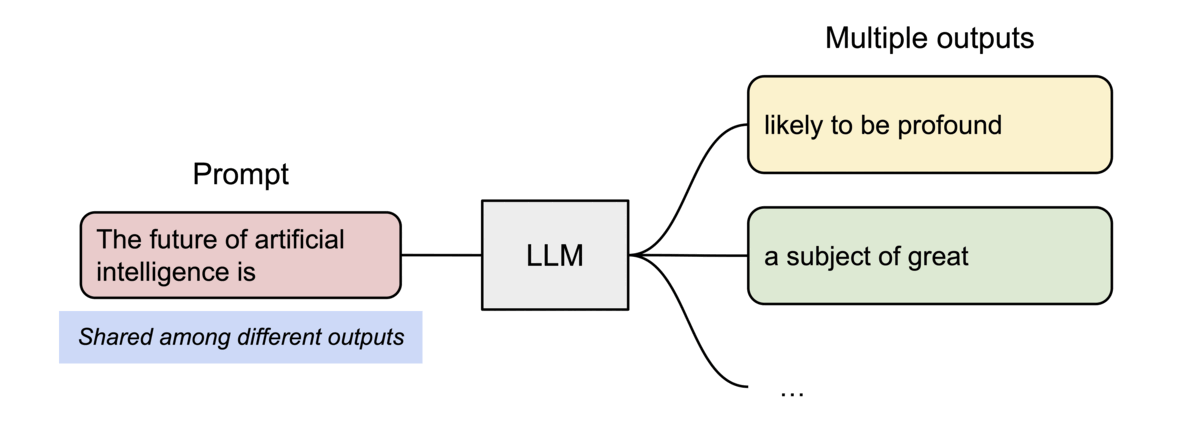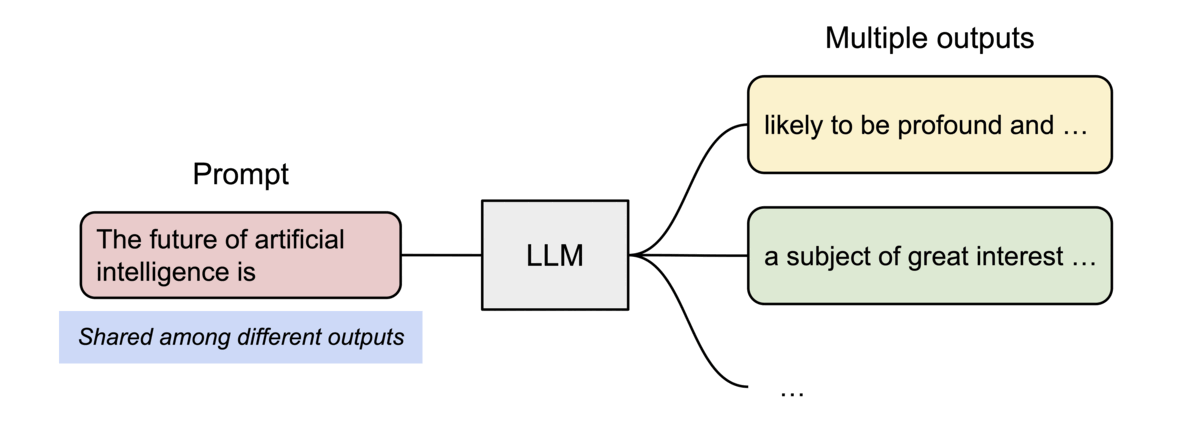
- 또 다른 장점은 효율적 메모리 공유
- 예를 들어, 병렬 샘플링에서는 동일 프롬프트에서 여러 출력 시퀀스를 생성할 수 있는데, 이 경우 프롬프트에 대한 연산과 메모리를 출력 시퀀스 간에 공유할 수 있음
- 블록 테이블을 통해 공유를 지원하는데, 프로세스가 physical 페이지를 공유하는 방식과 유사하게 PagedAttention의 서로 다른 시퀀스는 logical 블록을 동일한 physical 블록에 맵핑하는 방식으로 공유 가능
- 안전한 공유를 보장하기 위해 physical 블록의 참조 횟수를 추적하고 copy-on-write 메커니즘을 구현함
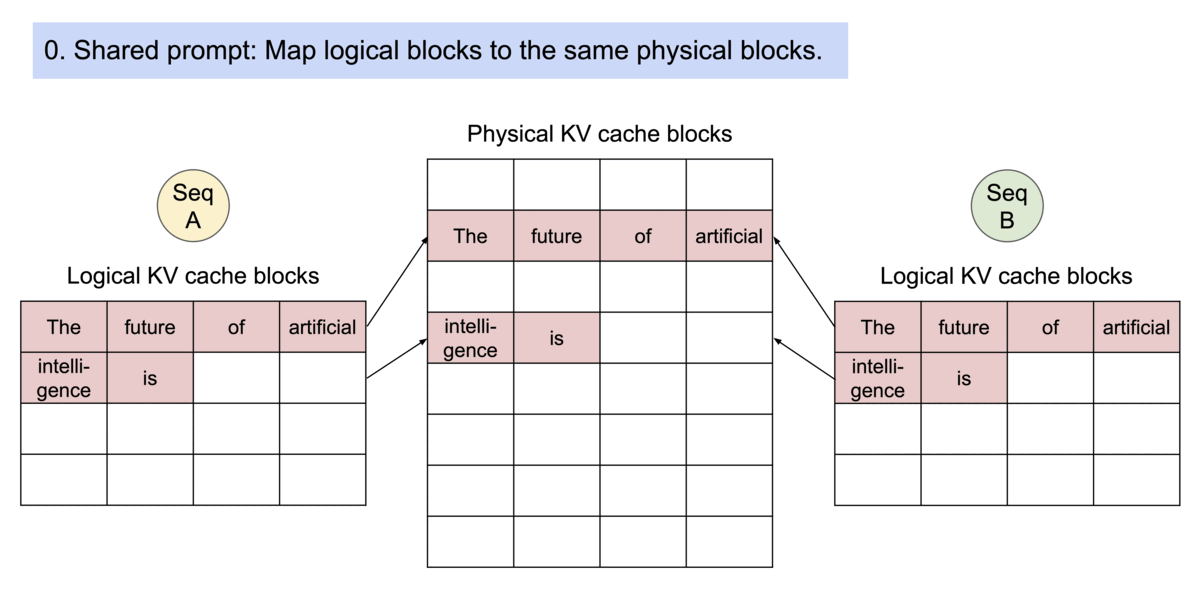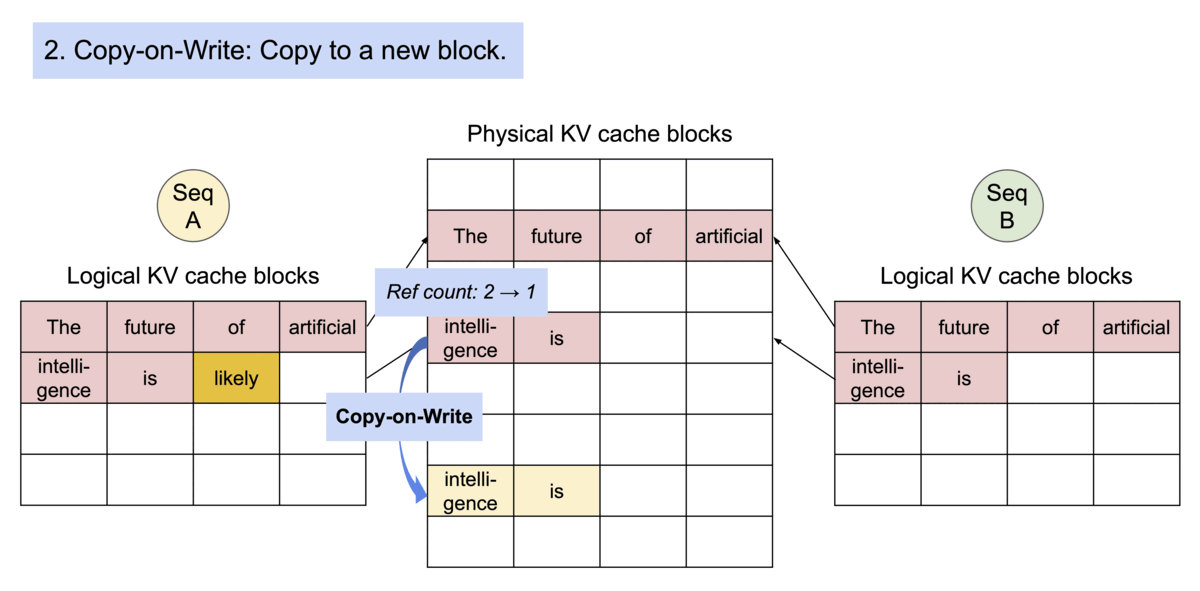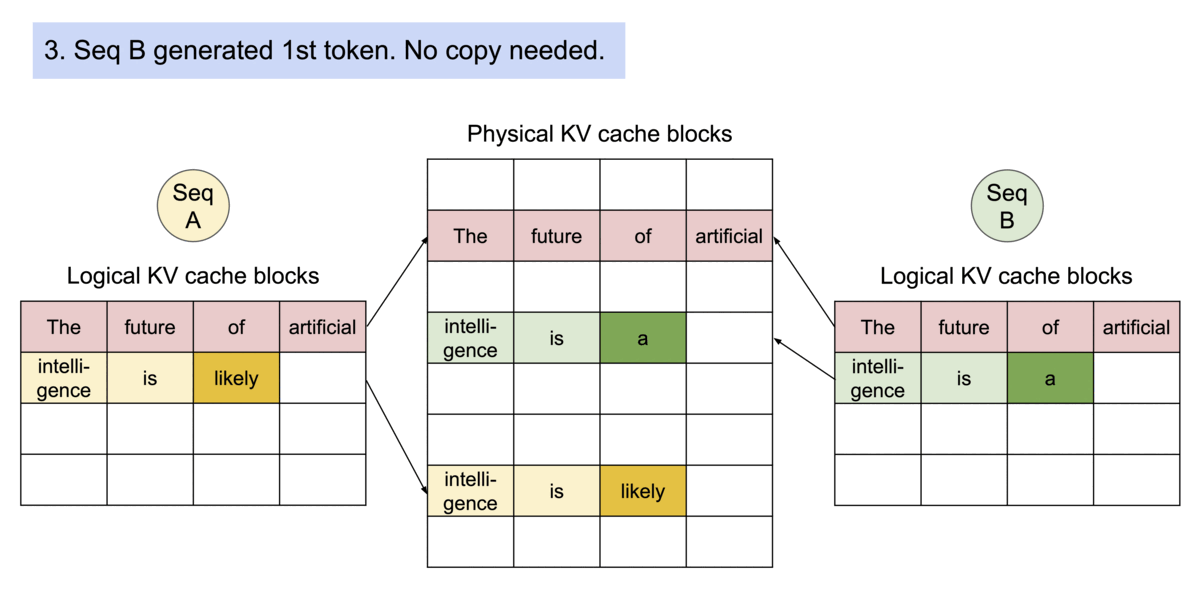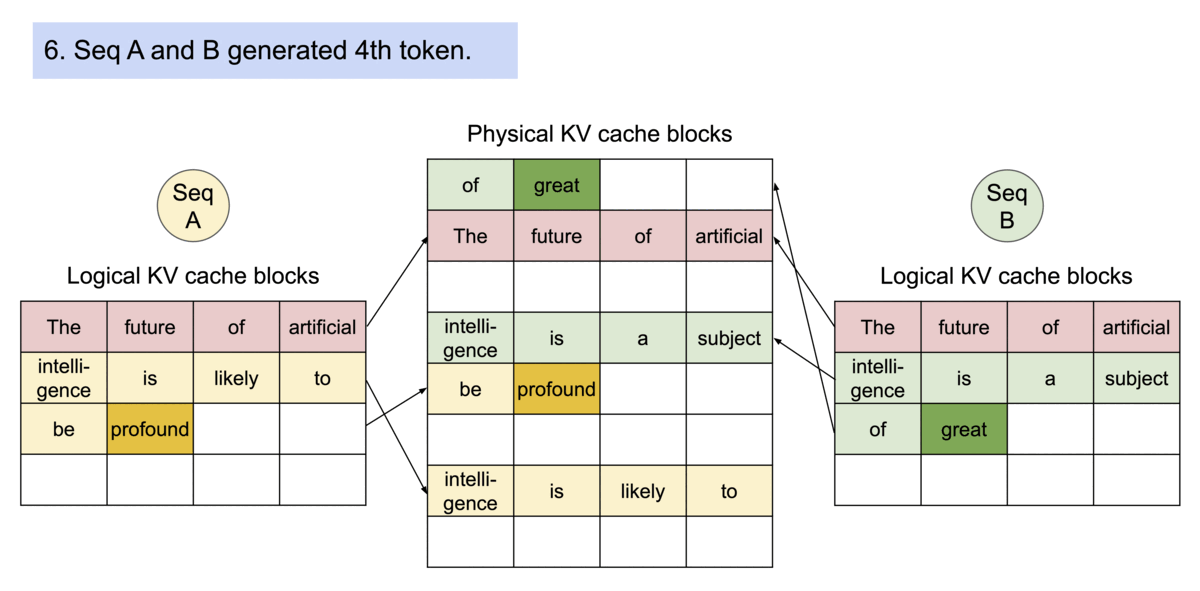
- 이러한 메모리 공유는 병렬 샘플링 및 beam search 등 복잡한 샘플링 알고리즘의 메모리 오버헤드를 크게 줄임
- 최대 55%까지 감소시킬 수 있으며, 다시 말해 throughput이 최대 2.2배 향상된다는 의미

J의 틀에 몸을 녹여 맞추는 P