@king.star.hazardous.log
로그인
@king.star.hazardous.log
로그인
시리즈
Inference Optimization
오름차순
1.
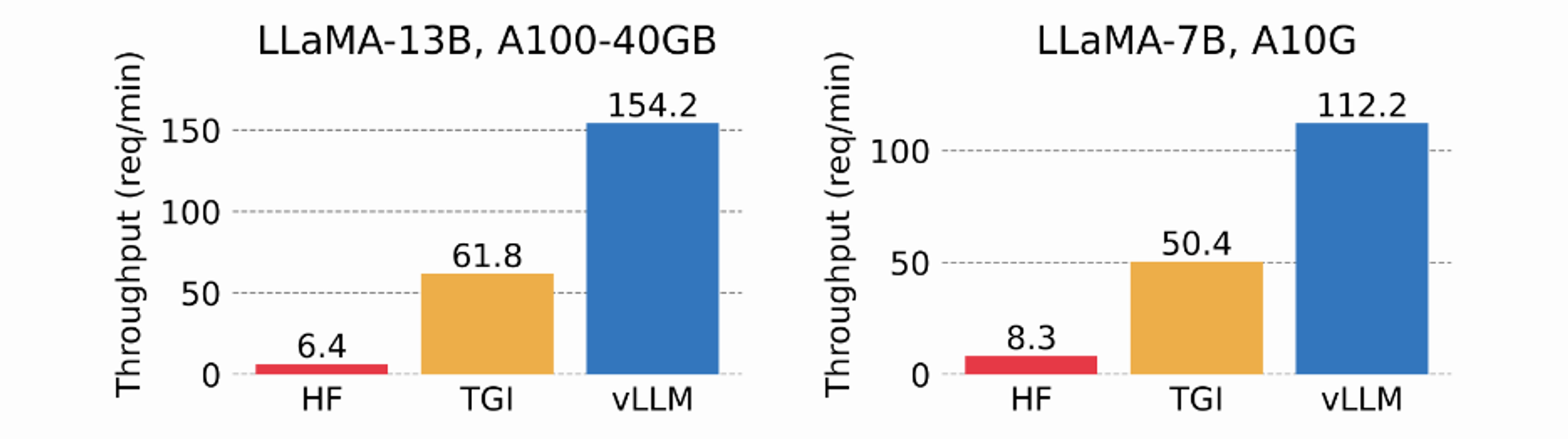
vLLM은 왜 빠른가?: Paged-Attention
'딸깍' 하나로 GPU 효율과 추론 속도를 모두 개선? vLLM의 PagedAttention 살펴보기
2024년 8월 29일