
🤷♀️ SQL 중심적인 개발의 문제점
현대적인 애플리케이션을 개발할 때는 대부분 객체지향 언어(Java, Scala..)를 사용하고 아직까지 가장 많이 사용되는 데이터베이스는 관계형 DB(Oracle, Mysql, ...)이다.
- 정리하자면, 객체를 관계형 DB에 관리해야 한다는 말과 같다. 객체지향 애플리케이션이라도 데이터베이스는 SQL만 알아들을 수 있기 때문에 막상 코드를 보면 SQL 중심의 코드인 경우가 많다.
SQL에 의존적인 개발 - 반복적인 CRUD
테이블이 10개면 10개 다 아래의 과정을 거쳐야 하기 때문에 코드가 반복적이고 지루한 작업을 해야한다. 그 과정에서 객체 중심의 모델은 점점 데이터 중심의 모델로 변해간다.
예를 들어, 회원 관리 기능을 개발하는 경우를 생각해보자.
1) 자바에서 사용할 회원 객체를 만든다.
public class Member {
private Srring memberId;
private String name;
...
}2) 회원 객체를 데이터베이스에 관리하기 위한 DAO 객체를 만들어 준다.
public class MemberDAO {
public void save(Member member){ ... }
public Member find(String memberId) { ... }
}3) SQL을 작성해서 관리 기능 개발을 완료한다.
// 등록
INSERT INTO MEMBER(MEMBER_ID, NAME) VALUES(?,?)
// 조회
SELECT MEMBER_ID, NAME FROM MEMBER WHERE MEMBER_ID =?🤷♀️ MemberDAO와 애플리케이션의 기능 개발을 완료한 상태에서 회원의 연락처도 같이 저장해달라는 요구사항이 추가되면 어떻게 될까?
- 회원 테이블에 TEL컬럼을 추가하기 위해 회원 객체에 tel 필드를 추가한다.
private class Member {
private String memberId;
private String name;
// 연락처 추가
private String tel;
...
}- 하지만 이 상태로 회원 조회를 하면 모든 연락처 값이 nulll로 출력된다. 조회 SQL에도 컬럼을 추가해줘야 하기 때문에 SQL을 수정해야 한다
INSERT INTO MEMBER(MEMBER_ID, NAME, TEL) VALUES(?,?,?)
SELECT MEMBER_ID, NAME, TEL FROM MEMBER WHERE MEMBER_ID =?계속 똑같은 작업을 반복해야 하기 때문에 코드가 지루해진다. 하지만 관계형 DB를 사용하는 상황에서 SQL에 의존적인 개발은 피할 수 없다.
🤷♀️ 패러다임의 불일치 (객체 VS 관계형 DB)
- 객체지향 언어 - 추상화, 상속, 다형성, 캡슐화, 정보 은닉
- 관계형 데이터베이스 - 데이터 중심으로 구조화 (객체지향에서 이야기하는 개념 없음)
👉 지향하는 목적이 다르기 때문에 표현 방법도 다르다.
상속
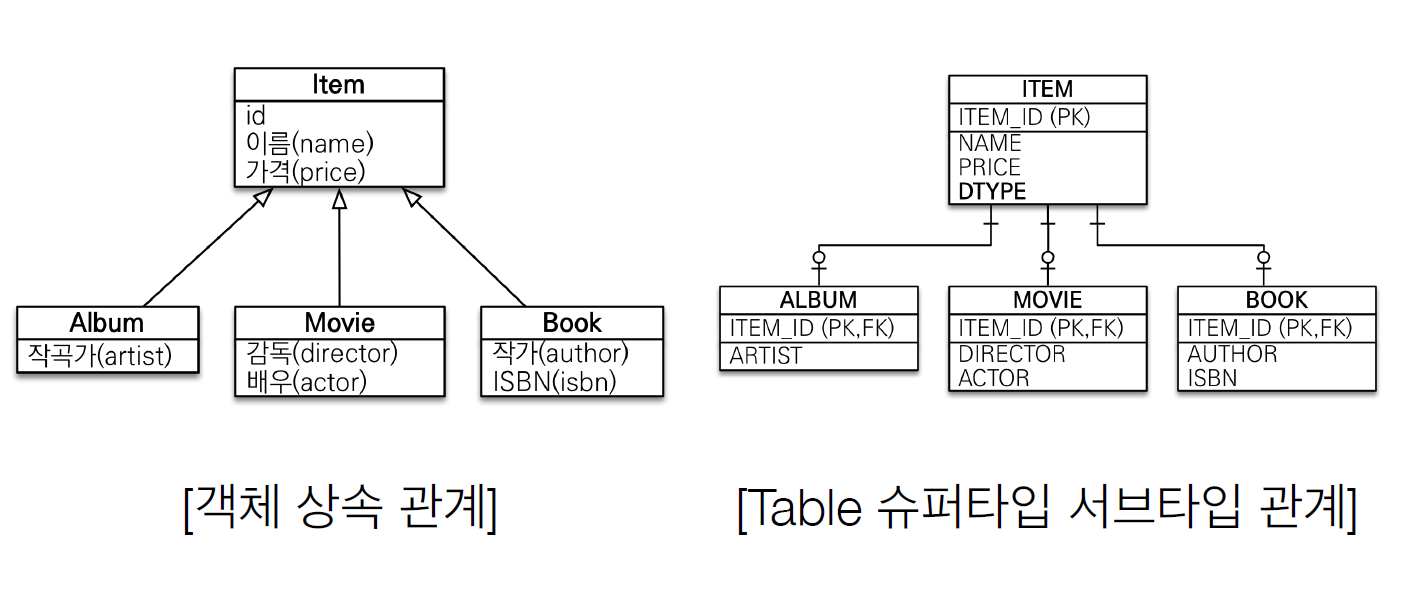
객체는 상속이라는 기능이 있지만 테이블에는 상속관계가 없다. 각각의 객체를 저장하려면 객체를 분해해서 두 가지 SQL을 만들어야 한다.
INSERT INTO ITEM...
INSERT INTO ALBUM...조회를 하려면 ITEM과 ALUBM 테이블을 조인해서 조회한 결과로 Album 객체를 생성해야 한다. 이런 것들이 모두 패러다임의 불일치를 해결하기 위한 작업이다.
연관관계
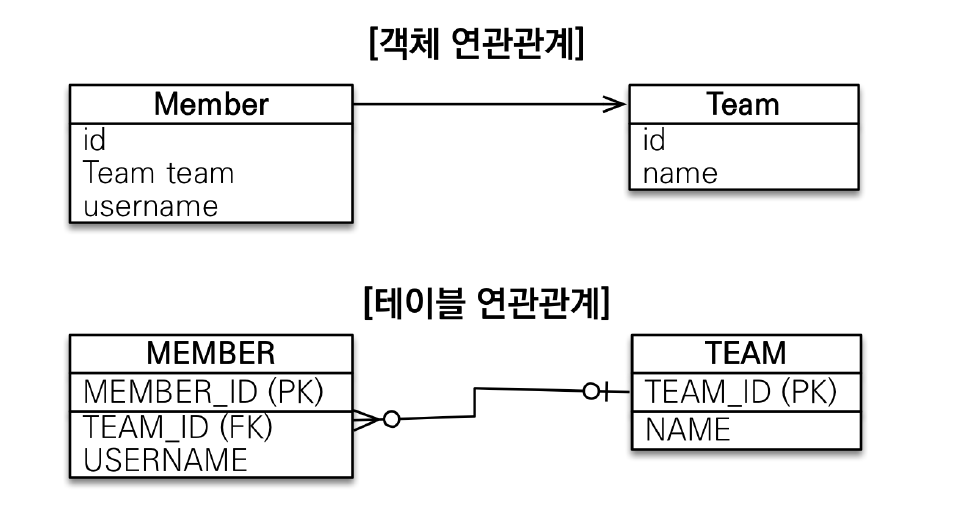
- 객체는 참조를 사용한다.
member.getTeam() - 테이블은 외래키를 사용한다.
JOIN ON M.TEAM_ID - T.TEAM_ID
객체는 Member에서 Team으로 갈 수 있지만 Team에서 Member로 갈 수 없다. (참조가 없기 때문!) 하지만 테이블은 TEAM_ID(PK)를 이용해서 TEAM_ID(FK)를 조인할 수 있다.
이렇게 연관관계에서도 객체와 테이블은 큰 차이가 있다.
모델링을 통해 객체와 테이블의 차이를 확실히 알 수 있다.
🙁 객체를 테이블에 맞춰 모델링
class Member {
String id; //MEMBER_ID 컬럼 사용
Long teamId; //TEAM_ID FK 컬럼 사용 //**
String username;//USERNAME 컬럼 사용
}
class Team {
Long id; //TEAM_ID PK 사용
String name; //NAME 컬럼 사용
}이렇게 테이블에 맞춰 컬럼을 그대로 가져와 클래스를 만들면 저장과 조회할 때는 편리하게 느껴진다. 하지만 외래키의 값을 그대로 보관하는 건 객체지향적이지 않다. 객체는 연관된 객체의 참조를 보관해야 참조를 통해 연관된 객체를 찾을 수 있다.
Team team = member.getTeam();🙂 객체지향 모델링
객체지향 모델링을 하려면 객체에는 teamId가 아닌 Team을 보관해야 한다.
class Member {
String id; //MEMBER_ID 컬럼 사용
Team team; //참조로 연관관계를 맺는다. //**
String username;//USERNAME 컬럼 사용
Team getTeam() {
return team;
}
}
class Team {
Long id; //TEAM_ID PK 사용
String name; //NAME 컬럼 사용
}하지만 이렇게 객체지향 모델링을 하면 저장이나 조회가 쉽지 않다. 테이블은 참조가 필요 없고, 객체는 외래 키가 필요 없기 때문에 개발자가 중간에서 변환을 해줘야 한다.
객체 그래프 탐색
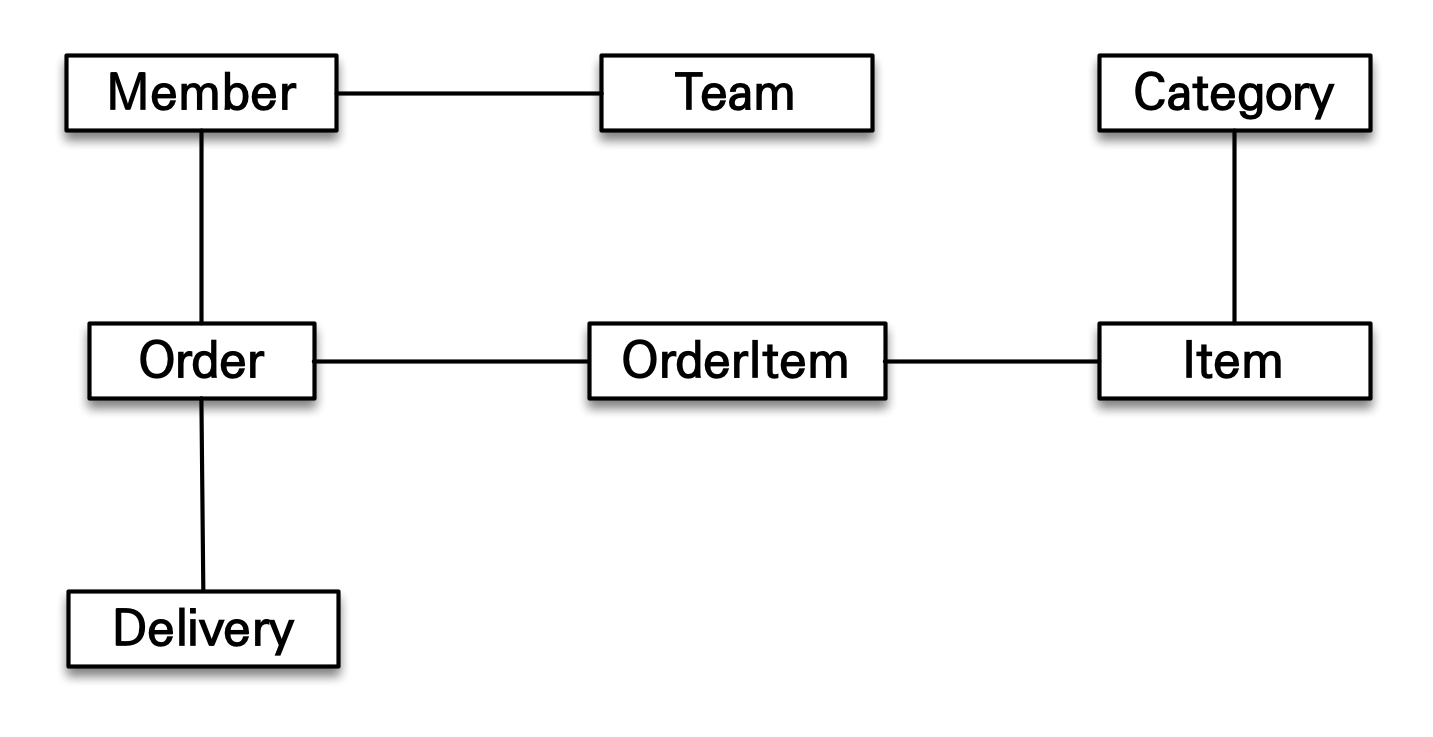
회원이 소속된 팀을 조회할 때 참조를 사용해서 연관된 팀을 찾는 것처럼 객체는 마음껏 객체 그래프를 탐색할 수 있어야 한다.
Team team = member.getTeam();만약 회원이 주문한 상품을 찾으려면
member.getOrder().getOrderItem()이런 식으로 자유롭게 탐색할 수 있어야 한다.
하지만, SQL을 직접 다루게 되면 실행하는 SQL에 따라 탐색 범위가 결정된다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID위의 SQL을 실행해서 회원과 팀에 대한 데이터만 조회했다면 member.getTeam();은 성공하지만 member.getOrder()은 데이터가 없어 탐색이 불가능해 null일 것이다.
그리고 계층형 구조에서 service쪽 코드만 보고서는 어디까지 탐색이 가능한지 확인할 수 없기 때문에 탐색 범위를 알아보려면 데이터 접근 계층인 DAO를 열어 SQL을 직접 확인해야 한다. 엔티티가 SQL에 종속되기 때문에 발생하는 문제인데 결론적으로 이런 부분 때문에 진정한 의미의 계층 분할이 어렵다.
🔑 자바 컬렉션에 저장하고 조회한다면 부모 타입으로 조회하고 다형성을 활용하면 되기 때문에 훨씬 간결하다.
list.add(album);
Album album = list.get(albumId);
Item item = list.get(albumId);객체를 자바 컬렉션에 저장하듯이 DB에 저장할 수 있는 방법은 없을까?
👉 SQL중심의 개발과 패러다임의 불일치 문제를 해결하기 위한 노력의 결과물이 바로 JPA이다.
참고 )
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 김영한님 강의
자바 ORM 표준 JPA 프로그래밍 (김영한)
