실습 💻
1. 단변량 분석 종합 실습 📌
결과 사진은 캡쳐하기도 귀찮고...
그냥 분석하면서 생각한 부분을 적는걸로.
이변량부터 재밌을듯 합니다.
카시트 판매량 분석
💡 문제 정의
카시트 판매량 하락
💡 가설 수립
내 가설
평균 소득이 높으면 부자동네, 여유로우니 애기들을 낳을 여건이 됨.
카시트 판매량이 높을거임 + 비싼 카시트를 살 수 있음=구매력이 있는 지역
즉, 여기서 카시트 판매량이 높은지, 또 판매하는 카시트의 가격이 높은지를 같이 봐야함
내 가설과 다르다면?
'Age'를 통해 지역별 연령대가 어떤지 봐야함
연령대가 10대 or 40대 이후 (=가임 가능한 부부가 아닌) 라면 구매력이 낮은게 말이됨 . 또, 인구수가 적을 수도 있음. (고령층이 많은 동네)
판매량이 낮다면 경쟁사 물건이 우리꺼에 비해 가격이 낮은지도 체크
Income
지역별 소득은 특별히 눈에 띄게 잘 버는 지역은 없다.
25%이하를 못 번다고 설정할 시, 못 버는 지역은 히스토그램으로 보니 꽤 있다.
따라서 판매량이 낮아질 수는 있다. 때에 따라 0이 나올 가능성도 있다.
차가 없는 집이 있을 수도 있기 때문에.
어느 지역이 잘 벌고 어느지역이 못 버는지 알 수 있는 변수가 있나?
안타깝게도 지역이 표시된 변수가 없아서 groupby 등을 쓸 수가 없다.
Price
mean보다 median이 살짝 높은데 전반적으로 가격이 살짝 높은편인듯?
타회사가 가격이 낮으면 안 팔릴 수도 있겠다....
유독 가격이 낮은 지역도 있는데 이건 특가인가?
유독 높은건 지역은 또 뭐지? Income과 겹치나?
인덱스 별로 다른 지역이라고 봐야 하는가? ㅠ
CompPrice
경쟁사 제품의 가격은
오히려 자사 제품보다 좀 높다
가격 경쟁력은 우리가 있는 편
다만 우리 제품은 max값이 더 높은 경향이 있어서
이건 왜 그렇게 비싼지 살펴봐야한다.
지역별로 가격을 너무 다르게 잡은 것이 아닌지?
그게 경쟁사와 교차되는 지역이면 경쟁사 제품을 살듯하다
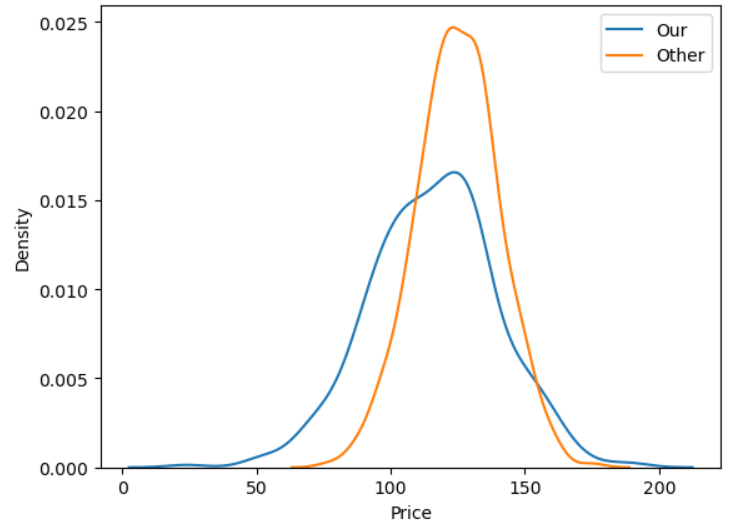
타사가 가격통일 자체는 잘 되어 있다.
Population
딱히 정규분포도 따르지 않고 굉장히 골고루 있다.
= 대도시가 아닌 지역이 많다. = 구매력 하락 가능성 있음
인구수가 적은 지역도 상당한데 고령층이 많은 시골지역일수도 있겠다. = 구매력 하락, 이런 곳에선 회사 빼는게 이득일듯
Age
지역 인구의 평균 연령.... 균등분포가 뜬다...;;;
이거 걍 데이터를 그렇게 모아놓은건가? (표본제어)
게다가 평균;;; 이게 ⭐지역별 평균 나이인가 지역별 구매자의 평균 나이인가?
25~80세 까지 있는데
애를 50세부터 못낳는다고 가정하면 (좋게봐줘도 45로 가정하면)
평균 연령이 높은 지역이 월등히 많다.... 이쯤되면 자식이 2n살임.
그러니 평균이 올라가지...
= 애 없음 = 카시트 필요 없음 (but, 자식의 자식이면 혹시 또 모른다.)
구매 주 연령층은 평균 내더라도 30,40대에 몰려있음
Advertising
오....0에 몰린게 엄청 많다.
그래서 다른광고 예산이 어떻게 집행되어 있는지 잘 모른다.
따라서 data.loc[data['Advertising']>0]으로 빼서 보고 분포 살피기.
광고예산 만달러 미만과 이상의 두 부류로 나뉘는 양상을 보이는데,
(박스플롯은 딱히 효과없는 상황)
그렇게 되는 원인이 있나?
Urban
도심지역이 확실히 많다!
보통은 차가 있을테니, 또 도심지역에는 젊은 사람들이 오려 할테니.
출생률이 올라갈 가능성이 있고, 그러면 카시트 판매량이 늘 가능성이 있다.
물론...우리나라는 오히려 반대다...ㅋㅋㅋ 일하느라 애를 안 낳으니까!
또, 경기가 어려워서 결혼을 안 할수도 있다!!!
이게 미국에도 통용되나?를 생각해야한다.
but, 인프라(=대중교통)이 잘 되어 있어서 오히려 구매를 안 하게 되나?도 생각해야함.
US
주로 국내(미국)가 많다.
그러나 해외 35%로 균형잡힌 회사 비율...?
혹시 해외에서 판매하는건 싸거나 비쌀까?
2. 이변량 분석 (숫자>숫자) 📌
X:숫자 > Y:숫자
두 숫자형 변수의 관계는 산점도로 알아보고 얼마나 직선에 모이는지 봐야한다. (공분산, 상관계수)
직선의 관계를 수치화 > 상관계수 (-1~1, -1와 1에 가까울수록 강한관계)
상관계수가 유의미한지 검정 > 상관분석
scipy.stats 모듈 : 가설검정 등 다양한 통계 함수들 제공

빨강 : 상관계수 (r)
파랑 : p-value (상관계수가 의미가 있는지 판단하는 숫자)
< 0.05 면 통계량이 의미있다. = 관계 있다.
X의 모든 구간에서 그러한 의미가 있는지 확인해야함
구간을 다르게 바꿔보는것도 중요!!! (구간끼리 평균 비교)
구간에 따라 차이가 있다면 X축의 비즈니스 관점을 생각
(ex. 그러한 양상이 되도록 영향을 미친 문화?법령?지역의 무언가?)
확인이 된다면 숫자를 범주로 바꿔서 anova등을 실행해서 가설 검정이 가능
++
그래프를 처음 보았을때는 상관관계가 안보이는데 pearsonr 을 출력했을때 상관관계가 있는 것으로 결과가 나온다면 이후에 구간을 잘라서 분석하는 방향도 좋다.
3. 이변량 분석 (범주>숫자) 📌
X:범주 > Y:숫자
💡 범주가 2개: 두 평균의 차이 비교 (T-test: abs(2)이상)
: 통계량이 유의미한것은 차이가 있다고 해석
t-통계량이 유의미한지는 p-value 보고 판단
전수조사: 전체(모집단) 조사
표본조사: 일부 무작위 조사
⭐ 표본은 왜 뽑지? 모집단을 추정하기 위해서.
표본 평균은 왜 뽑지? 모평균을 추정하기 위해서.
표본평균: 모 평균에 대한 추정치
표본평균과 모평균은 오차가 존재: 표준 오차(SE)
sns.barplot : 범주별 평균값을 비교
두 평균의 차이가 크고, 신뢰구간은 겹치지 않을 때: 대립가설이 맞다.
(빨강 : 신뢰구간)
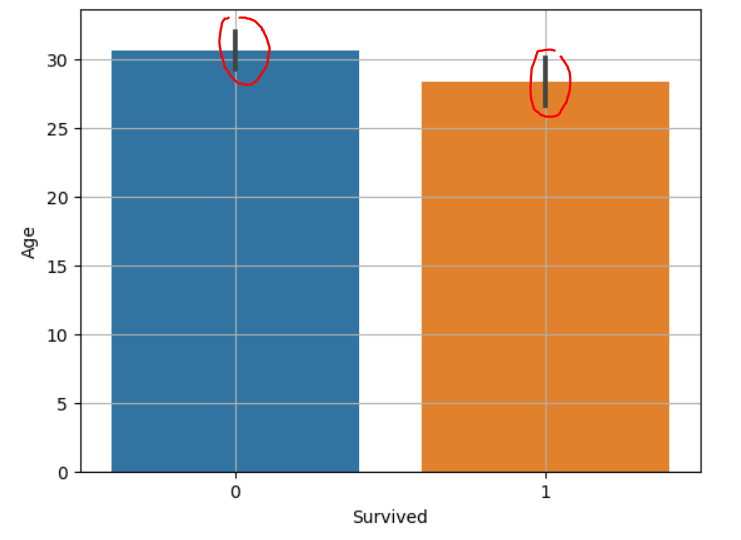
가로로 표현하면 아래와 같다.
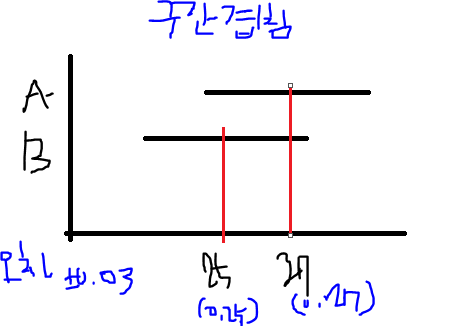
이 경우 대립가설이 틀렸다!
95% 신뢰구간: 모집단의 평균이 그 안에 속할 확률 95%
신뢰구간이 겹치지 않는다. : 평균의 차이가 크다.
💡 범주가 3개 이상: 전체 평균과 각 범주의 평균비교 (anova)
전체 평균과 그룹평균의 차이(분산), 그룹 내 차이(분산)
분산: 평균으로부터 다른 데이터들이 얼마나 떨어져 있는지 나타내는 값
F 통계량 = (전체 평균-각 집단 평균)/(각 집단의 평균-개별값)
통계량이 크면? 차이가 크다.확연하게 집단 간 구분이 된다.
근데 통계량이 진짜 큰건지 어떻게 알음? 분포를 보면 된다!
값이 대략 2~3 이상이면 차이가 있다고 판단
⭐ 요약
중점: 평균 비교
시각화: sns.barplot
수치화: 범주 2개 t-test / 범주 3개 이상 anova
++
대략적인 해석 기준
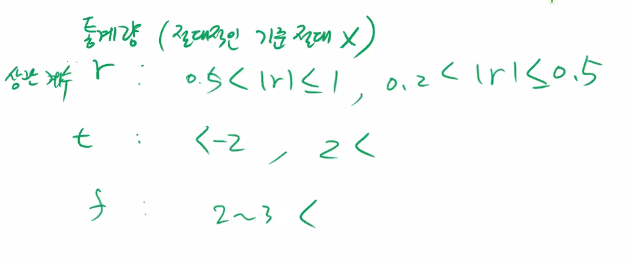
4. 이변량 분석 종합 실습 📌
카시트 판매량 분석
💡 문제 정의
카시트 판매량 하락
📎 y는 해결해야 할 대상, 초기 정의한 문제가 바뀌면 y도 바뀐다.
💡 가설 수립 (고객사가 했다고 가정)
가설
판매량 하락의 원인이 무엇일까?
수입이 부족, 광고 안 함, 필요가 없음 (연령대), 경쟁사가 더 좋음 등등의 data의 cols 들
이건 동적 변수 생성...귀찮아서 코드하나 짜둠
def make_data(data,var,df_lst):
unique = data[var].unique()
for name in unique:
print(name)
globals()[name] = data.loc[data[var]==name, target]
df_lst.append(globals()[name])
lst = []
make_data(data,'ShelveLoc',lst)
spst.f_oneway(*lst)💡 가설 수정
📎 가설: 타사 가격은 자사 판매량에 영향을 준다.
CompsPrice
경쟁사 탓을 하긴 좀 어려울듯
경쟁사는 경쟁사대로 우리 회사는 우리 회사대로....
경쟁사 가격이 이러할때 자사 판매량이 얼마이다 인데...
골고루 분포되어있넵...ㅎ
이건 가설이 잘못되어서 원하는 결과를 못 얻은거!
그렇다면?가설을 새로 세운다.
New 가설 : 가격경쟁력은 자사 판매량에 영향을 준다.
['가격경쟁력']이란 feature를 새로 생성!
가격경쟁력 = 타사 가격 - 자사 가격으로 정의
Income
지역 평균 소득이 높은 지역의 사람들이 비교적 낮은 사람들과 구매량이 큰 차이가 없는 이유는 아이의 수는 비슷하니 구매량은 큰 차이가 없고 판매된 제품의 가격이 차이가 있을 수도 있다.
5. 이변량 분석 (범주>범주) 📌
교차표 만들기 (normalize = 'columns','index','all')
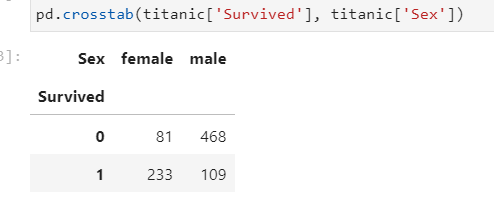
mosaic plot:
from statsmodels.graphics.mosaicplot import mosaic
mosaic(titanic, ['X','Y'])
plt.axhline(1- titanic['Survived'].mean(), color = 'r')
plt.show()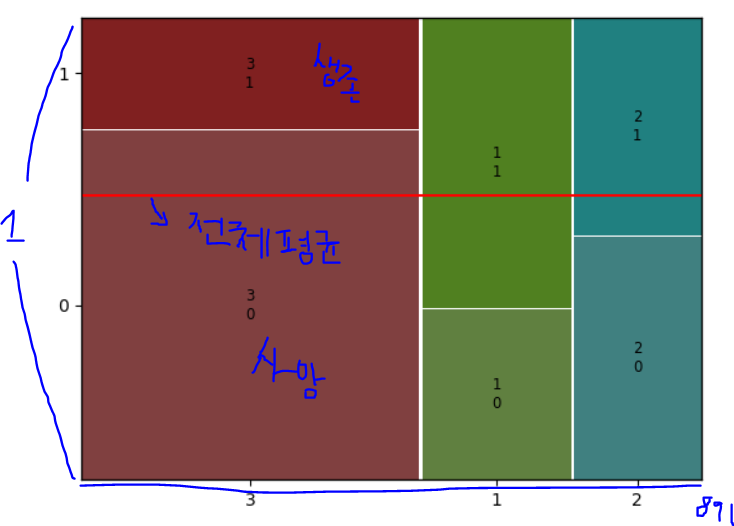
1에서 뺐으니 사망자가 어느정도인지 알 수 있음
카이제곱 검정
기대빈도: 귀무가설이 참이기를 바라는 숫자
-
카이 제곱 통계량은
- 클수록 기대빈도로부터 실제 값에 차이가 크다는 의미.
- 계산식으로 볼 때, 범주의 수가 늘어날 수록 값은 커지게 되어 있음.
- 보통, 자유도의 2~3배 보다 크면, 차이가 있다고 본다.
-
범주형 변수의 자유도 : 범주의 수 - 1
-
카이제곱검정에서는
- x 변수의 자유도 × y 변수의 자유도
- 예 : Pclass --> Survived
- Pclass : 범주가 3개, Survived : 2개
- (3-1) * (2-1) = 2
- 그러므로, 2의 2 ~ 3배인 4 ~ 6 보다 카이제곱 통계량이 크면, 차이가 있다고 볼수 있음.
spst.chi2_contingency(교차표)
1) 카이제곱 통계량: 자유도 2배보다 큰가? 클수록 관련
2) p-value
3) 자유도 (3-1)*(2-1)=2
4) 기대빈도
자유도 3 : Pclass.unique() 3개라서
자유도 2 : Survived.unique() 2개라서
++
원래 엄밀하게 하려면 계산하여 구한 카이제곱 통계량과 카이제곱 분포표에서 유의수준이 0.05(이건 꼭 0.05가 아니여도 됩니다)이고, 자유도가 n인 부분을 찾아 비교하여 카이제곱 통계량이 더 크다면 귀무가설 기각(귀무가설을 받아드릴 수 없다.) 카이제곱 통계량이 더 작다면 귀무가설을 기각할 수 없다(귀무가설을 받아드린다.)라고 생각
6. 이변량 분석 (숫자>범주) 📌
kde 그래프 (예측치로 0이하도 나옴, 신경 안 써도 됨)
target 클래스가 크로스 되는 순간(겹치는)은 전체 평균
특정구간이 전체평균보다 높은지 낮은지 판별
kde 할 때 common_norm = False (각각의 면적을 1로 만듦)
hue = '열 이름'
plt.figure(figsize = (8,10))
plt.subplot(2,1,1)
sns.kdeplot(x='Age', data = titanic, hue ='Survived', common_norm = False)
plt.subplot(2,1,2)
sns.kdeplot(x='Age', data = titanic, hue ='Survived', multiple = 'fill')
plt.axhline(titanic['Survived'].mean(), color = 'r') plt.show()미봉책
1) X를 범주로 변환 가능하면 변환해서 카이제곱검정 가능
2) Y를 숫자로 변환 가능하면 상관분석 가능
3) 로지스틱 회귀 > 회귀계수 p-value 구해서 판단
7. 이변량 분석 종합 실습 2 📌
이건 내가 따로....해보는걸로...체력 딸려서 실습시간에 푹 쉬었다....
