ENERGY-BASED GENERATIVE ADVERSARIAL NETWORKS
Authors
Junbo Zhao, Michael Mathieu and Yann LeCun
Department of Computer Science, New York University
Facebook Artificial Intelligence Research
본 논문은 2017년 ICLR에서 New York University, Facebook AI Research팀에서 발표한 논문입니다.
Abstract
해당 논문에서는 Energy를 기반으로 한 GAN(EBGAN)을 제시합니다. EBGAN의 discriminator는 energy function으로 구성되어 있으며, energy function은 data maniford와 인접한 영역에서는 낮은 energy 값, 그렇지 않은 영역에서는 높은 energy 값을 갖습니다.
Probabilistric GANs와 유사하게 generator는 낮은 engergy를 갖는 sample들을 생성하도록 학습되고, discriminator는 생성된 sample이 높은 energy를 갖도록 학습합니다.
Discriminator(energy function)는 다양한 구조로 구축할 수 있으며, loss function은 binary classifier의 loss function을 사용합니다.
위 설명들을 바탕으로, auto-encoder 구조를 사용한 EBGAN framework에서, discriminator 대신 energy function을 통해 reconstruction error를 측정한 예시를 보입니다
Intro
ENERGY-BASED MODEL
Energy-based model의 핵심은 input space의 각 data들을 single scalar(energy)로 매핑하는 function을 구축하는 것입니다.
학습은 데이터 기반으로 이루어지며, 데이터와 유사하면 낮은 energy를 갖으며 그렇지 않을 경우에는, 높은 energy를 갖는 energy surface를 형성하도록 진행됩니다.
지도학습 관점에서는 training set의 각 데이터 X에 pair한 energy Y를 갖으며 이때 옳은 경우에는 Y가 낮은 값을 갖고, 옳지 않은 경우에는 높은 값을 갖도록 데이터를 구성하빈다.
비지도학습 관점으로 살펴보면 Training set의 X data manifold인 경우 낮은 energy를 갖도록 합니다.
GENERATIVE ADVERSARIAL NETWORKS
GAN은 2014년 Goodfellow가 발표한 프레임워크이며 이미지 생성에서 큰 개선을 이루었습니다.
GAN의 Basic idea는 discriminator와 generator를 학습시키는 것으로, discriminator는 real sample과 generator가 생성한 fake sample을 구별하도록 학습합니다. Genrator는 random 값으로 입력받아 fake sample을 생성하도록 학습하며 discriminator가 생성한 fake sample르 real sample과 구별하지 못하도록 학습합니다.
Game theory관점에서 generator와 discriminator가 Nash equilibrium을 달성하면, GAN이 수렴했다고 여깁니다.
Nash equilibrium
Nash equilibrium은 게임 이론에서, 경쟁자 대응에 따라 최선의 선택을 하면 서로가 자신의 선택을 바꾸지 않는 균형상태를 의미합니다.
ENERGY-BASED GENERATIVE ADVERSARIAL NETWORKS
해당 논문에서는 discriminator 대신 energy function(contrast function)을 사용하는 것을 제안합니다. Energy function은 기존 GAN과 다르게 확률 값을 사용하지 않으며 discriminator의 역할을 함으로써 generator의 학습을 위한 cost function으로도 사용할 수 있습니다.
Discriminator는 데이터 분포에 위치한 경우 낮은 energy 값을 갖고, 데이터 분포가 아닌 영역에서는 높은 energy값을 갖도록 합니다.
반대로 generator는 생성한 sample을 discriminator가 낮은 energy 값을 갖도록 학습이 가능한 함수로 여길 수 있습니다.
Energy function은 확률을 사용하지 않는다고 언급하고 있는데, 이는 Gibbs distribution을 통해 energy들을 확률로 치환할 수 있기에, 확률값을 직접 사용하는 것보다 discriminator의 구조를 선택하는데 있어 더 유연한 선택이 가능하다고 주장하고 있습니다.
Gibbs distribution
Gibbs distribution은 Boltzmann distribution의 일반화된 형태로 다변수 시스템의 상태에 대한 분포를 설명하는데 사용됩니다.
다시말하면, 여러가지 변수가 함께 작용하는 복잡한 시스템이 있는 경우, 이 시스템의 각 변수가 특정 상태에 있을 확률을 알고 싶을때 Gibbs distribution을 사용할 수 있습니다.
모든 변수 중 하나를 선택한 후, 선택한 변수를 제외한 다른 변수의 상태를 고정하고 그 선택한 변수의 확률을 계산하는데, 조건부 확률과 관련이 있습니다. 이 과정을 반복하여, 전체 다변수의 확률 분포를 구축하는 방법입니다.
저자들의 Main contribution은 아래와 같습니다.
- Genrative adversarial training을 위해 energy-based formulation을 사용합니다
- 간단한 hinge loss 증명을 통해 제안하는 system이 수렴하면, EBGAN의 generator가 data distribution을 따르는 points를 생성함을 보입니다.
- EBGAN framework의 discriminator을 auto-encoder 구조로 구성하여, energy가 reconstruction error를 의미하도록 하였습니다.
THE EBGAN MODEL
Notation을 먼저 정의합니다.
는 dataset의 확률밀도를 의미합니다.
Genrator 는 정규분포 의 분포 를 따르는 random vector 로부터 image 를 생성하도록 학습하며, discriminator는 real 혹은 generated image를 입력받아 energy value 를 추론합니다.
또한, simplicity를 위해 D는 non-negative value를 생성함을 가정합니다.
OBJECTIVE FUNCTIONAL
저자들은 loss function으로 margin loss를 사용하였지만, 이 외에도 다양한 loss를 사용해도 된다고 언급합니다.
GAN과 마찬가지로, 두 loss를 사용하는데 하나는 D를 학습하기 위함이고, 다른 loss는 G를 학습하기 위해 사용됩니다.
양수의 값을 갖는 margin 과 data sample , 생성된 sample 를 통해 discriminator loss 와 generator loss 는 아래와 같이 정의됩니다.
는 을 의미합니다.
를 최소화함은 의 두번째 항을 최대화 함을 의미하는데, 같은 최소를 갖지만 인 경우 0이 아닌 기울기를 갖습니다.
에서 margin 을 사용함으로써 학습 초기에는 생성한 fake sample 에 대한 engergy 값 역시 높은 값을 갖기에, 를 통해 초기에는 0의 값을 얻게 되며, 따라서 학습 초기의 는 를 먼저 최소화 하도록 진행됩니다. 이를 통해 안정적인 학습을 가능하게 하는 것 같습니다.
USING AUTO-ENCODERS
저자들은 실험에서 discriminator의 구조를 auto-encoder의 구조를 따르도록 설계하였는데, 정확히는 를 따릅니다.
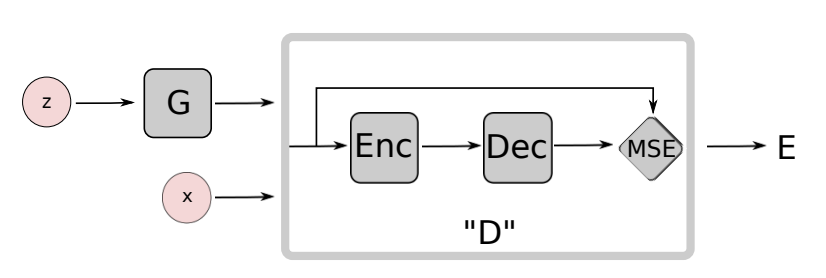
EBGAN의 구조는 위와 같으며 단순히 임의로 auto-encoder 구조로 구성한 것이 아니라, 개념적인 의미를 녹여내어, binary logistic network를 사용하는 것 보다 매력적이라고 주장합니다.
첫번째로는, 단순히 0,1 single bit의 target 정보로 모델을 학습하는 것에 비해, reconstruction-based 출력 결과를 사용함으로써 discriminator 입장에서 더 다양한 target을 사용할 수 있게 됩니다.
Binary logistic loss를 사용한다면, 두 개의 target만 얻을 수 있고, minibatch내에서 서로 다른 sample들에 해당하는 gradients가 직교하지 않을 가능성이 더 큽니다.
Parameter 업데이트는 각 sample의 gradient에 기반하는데, gradient가 직교한다는 것은 다른 sample의 gradient가 서로 독립적인 방향으로 향한다는 의미입니다. 즉, 각 sample의 gradient는 다른 sample의 gradient에 영향을 덜 주며, parameter 업데이트 관점에서, 서로 충돌하지 않는 것이 더 안정적인 학습을 할 수 있습니다.
따라서 binary logistic loss보다 reconsturction loss를 사용하는 것이 minibatch 내에 다양한 gradient의 방향을 생성하므로 효율적으로 볼 수 있습니다.
두번째로, auto-encoder는 전통적으로 energy-based model을 표현하는데 사용되어왔다고 주장하고 있습니다. 입력 sample을 압축하여 다시 복원하는 과정에서 저차원으로 표현되는 공간의 point들을 energy로 여기는 것이 아닌가 싶습니다.
저자들은 regularization terms을 추가하여 autor-encoder가 추가의 supervision이나 negative sample이 없더라도 energy의 manifold를 학습하도록 하였습니다. EBGAN이 real sample만을 reconstruction하도록 학습을 하여도, discriminator는 스스로 data manifold를 찾을 수 있다라는 의미입니다.
또다른 주목할만한 점은, negative sample를 generator 학습에 사용하지 않는 경우, discriminator를 binary logistic loss로 학습하는 것은 의미가 없게 된다는 점입니다.
CONNECTION TO THE REGULARIZED AUTO-ENCODERS
Auto-encoder를 학습할 때 흔하게 발생하는 문제는, 모델을 Identity function으로만 학습할 수 있다는 점인데, 이는 모든 데이터를 zero energy로 할당해버리는 문제가 있습니다.
이 문제를 해결하기 위해서는, 모델이 data manifold 이외의 point에는 더 높은 energy를 부여하도록 해야합니다.
이전 연구들에서 이론적, 실험적으로 이 issue를 해결하기 위해 latent representation에 regularizing을 적용하였습니다.
EBGAN 프레임워크는
- Regularizer(generater)는 수작업이 아닌 완전한 학습이 가능하며,
- Adversarial 학습 패러다임을 통해 contrastive sample을 생성하는 것과, energy function을 학습하는 것이 가능하기에 더 유연하다고 주장하고 있습니다
REPELLING REGULARIZER
저자들은 repelling regularizer를 제안하는데, 이 방법을 통해 모델이 한가지(Identitiy)혹은 오직 몇개의 modes로만 데이터를 생성하는 것을 방지할 수 있다고 주장하고 있습니다.
Repelling regularizer를 사용하기 위해서는 representation level에서 사용되는 Pulling-away Term(PT)이 필요합니다.
를 와 같이 정의하며 encoder output layer로 부터 얻은 sample represntation의 batch를 의미합니다.
PT는 와 같습니다
PT는 mini batch에서 적용되며, sample representation의 pair를 직교화하려 합니다. PT의 식을 보면 consine similarity가 사용되는데, Euclidean disatance대신 consine similarity를 사용한 이유는 최소값을 유지하며, scale에 불변하도록 하기 위함(0~1사이 값으로 출력)입니다.
PT는 generator loss에만 사용이되고 discriminator loss에는 사용되지 않습니다.
이후는 실험 결과로, GAN과 비교해서 EBGAN에 PT까지 적용한 모델이 가장 좋은 성능을 보이는 것을 다루고 있습니다.

좋은글감사합니다!