
Emerging Properties in Self-Supervised Vision Transformers
본 논문은 2021년 ICCV에 Facebook AI Research팀에서 발표한 논문입니다.

해당 논문에서는 Self-distillation with no labels ->DINO 라는 학습 방법을 제시 합니다.
위 그림은 Dino를 적용한 ViT 모델의 attention map으로 각 Image에서 feature를 정교하게 추출하는 모습을 보이고 있습니다.
Intro
연구의 시작은 SSL(Self-Supervised Learning)을 ViT에 적용해보면 어떨까 라는 질문에서 시작되었다고 말하고 있습니다.
Transformer는 NLP뿐만 아니라 Vision 분야에서도 CNN을 대체하는 네트워크로 많이 사용되고 있지만, 연산량도 더 높고 학습을 위해서도 더 많은 데이터가 필요할 뿐만 아니라 학습 후 추출된 feature에 대해서도 명확한 특성을 알기 쉽지 않습니다.
때문에 저자들은 NLP분야에서 SOTA를 달성한 BERT나 GPT모델이 Self-supervised pretraining 기법을 사용한 것을 동기 삼아 ViT모델에 SSL을 적용하였습니다.
Knowledge distillation
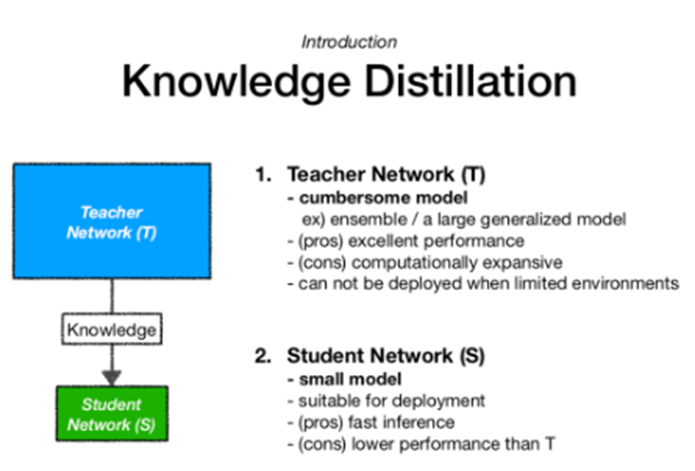
DINO(self distillation with no labels)에 적용되는 Knowledge distillation은 모델 경량화와 관련된 개념으로 큰 모델(Teacher network)을 사용하여 작은 모델(Student network)에서도 teacher network와 비슷한 성능을 낼 수 있도록 하는 목적을 갖고 있습니다.
SSL with Knowledge Distillation : DINO
논문에서는 제안하는 framework를 DINO라고 칭하고 있습니다. DINO는 일반적인 knowledge-distillation 구조와는 다르게 Teacher network의 output을 student model의 output이 직접적으로 예측하는 간소화된 구조를 띄고 있습니다.
즉 DINO framework는 SSL과 knowledge-distillation 방법론을 띄고 있습니다.
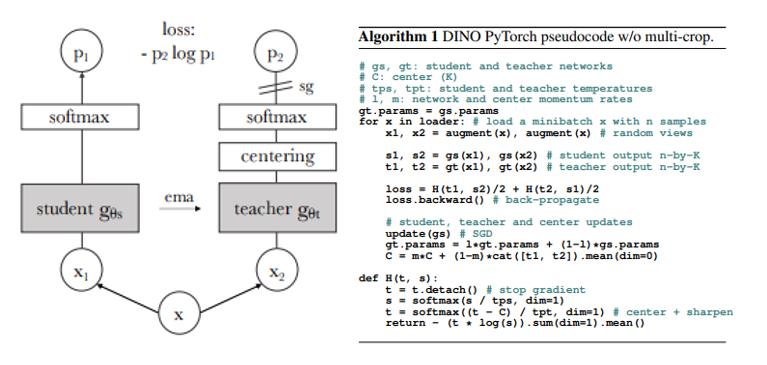
전체적인 DINO framework의 illustration과 pytorch pseudo code 입니다.
Key idea는 cross entropy,multi crop strategy,momentum teacher,centering,sharpening 입니다.
전체적인 흐름에 대해 살펴 보면, 같은 네트워크 구조를 갖는 model student와 teacher를 구성하고 teacher의 gradient는 동결하여 학습하지 않습니다.
하나의 sample x에 대해서 서로 다른 augmentation기법을 적용한 x1,x2를 각각 생성 후 student와 teacher에 통과시키고 두 모델의 softmax 확률 값을 cross entropy loss로 최적화 하는 흐름입니다.
Multi-crop strategy

Augmentation에서 사용되는 multi crop의 경우 global view와 local view로 나눠집니다. Global view는 sample의 원래 크기에서 50% 이상의 크기로 crop후 resize, local view는 50%이하로 crop해서 resize하는 방법입니다. Global view 같은 경우 2개의 sample을 만들고, local view는 여러개의 sample을 생성하였다고 합니다.
생성한 각 data를 teacher network에서는 global view만 사용하고 student network는 모든 view를 사용합니다.
Momentum teacher
일반적인 knowledge distllation과는 다르게 DINO에서 Teacher network는 student에 비해 이전에 학습된 parameter를 사용하고 있지 않습니다. Student network를 먼저 생성하여 같은 구조의 모델을 사용하되 teacher network의 gradient는 동결시킨 후, student의 parameter를 EMA(Exponential moving average) 기법을 적용하여 parameter update을 진행합니다. EMA는 가중치를 주어서, 과거의 정보도 영향력을 행사하도록 고려한 방법입니다.
Update 방법은 입니다. 는 hyper parameter로 저자들은 0.996~1이 되도록 cosine schedule을 사용하였습니다.
이런 방식으로 teacher model의 parameter를 업데이트 하면 결국 학습 단계에서 봤던 student model들의 parameter의 평균이 되는 것과 유사한데, 이는 모델 앙상블의 효과를 갖을 수 있습니다.
Avoiding collapse
DINO에서는 여느 SSL 연구들과 마찬가지로 발생할 수 있는 collapse가 존재하는데 여러 SSL 연구에서는 contrastive loss, clustering constraints, predictor or batch normalization과 같은 방법들을 사용하였습니다.
DINO에서는 centering과 sharpening을 적용해서 학습에서 생길 수 있는 문제점을 보완하고 있습니다. Sharpening은 network의 output 확률 분포를 조절 하는 방법으로 temperature 라는 hyper parameter로 model의 출력값을 나눈 후 softmax를 취하는 방법입니다.
Temperature는 1보다 작은 값을 사용할 때, 0에 가까울 수록 더욱 돋보이는 확률 값으로 분포가 변화됩니다.
- Sharpening :
: temperature of student
: temperature of teacher
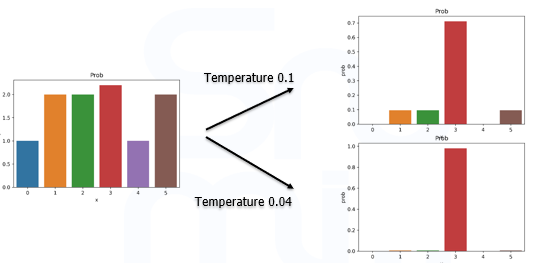
Student model에서 temperature는 0.1, teacher model에서의 temperature는 0.04를 사용하였습니다.
Centering은 로 teacher model output에 라는 bias term을 추가한 효과를 냅니다. 의 초기값은 첫번째 batch의 output 평균 값으로 이후에는 m(hyper parameter)이라는 0보다 큰 비율로 업데이트를 합니다.
Centering은 모델의 출력이 하나의 차원으로만 직결되는 상화을 막을 수 있지만, 반대로 출력값의 분포가 uniform distribution을 따르도록 하는 문제점을 야기합니다.
Sharpening은 centering과 반대의 효과를 주기에, 두 기법을 모두 사용하여 학습함으로써 적절한 벨런스를 유지할 수 있었다고 말합니다.
Results
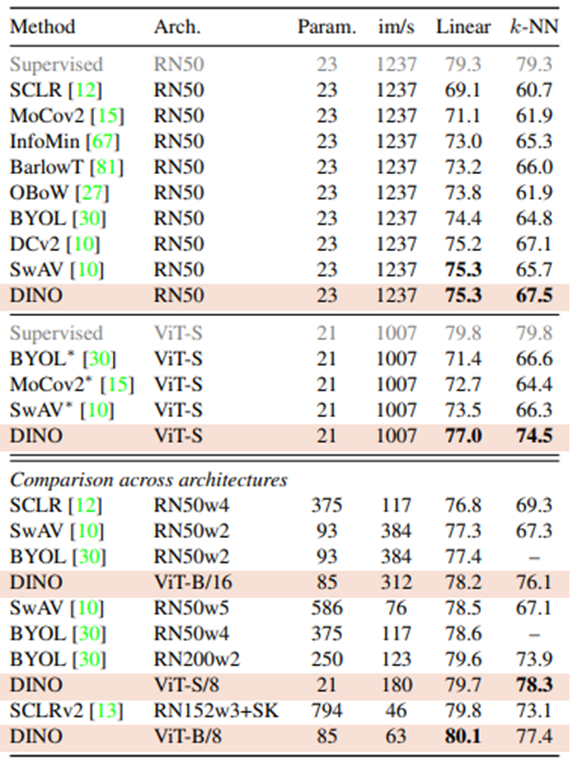
결과 평가를 위해 같은 네트워크에서 DINO기법을 적용해보고, 여러 모델에 여러기 법을 합쳐서 학습한 결과를 비교합니다. Resnet-50을 ViT와 비교하는데, 파라미터수, 연산 시간, Imagenet의 성능이 유사하기때문에 비교 모델로 선정했다고 합니다. Resnet-50에 DINO 기법을 적용한 것이 가장 좋은 성능을 기록했으며, ViT에서도 DINO를 사용한 성능이 가장 높음을 보이고 있습니다.

일반적인 학습 방법보다도 DINO framwork에서의 feature extraction이 더 정교함을 보이고 있습니다.
BERT 계열의 모델에서 SSL이 key point가 될 수 있었던 것처럼 ViT에서도 SSL의 효과를 볼 수 있었습니다.
